Redis Core? Redis Modules
Redis Core는 Redis의 핵심 기능을 담당하는 부분으로 메모리 기반의 키-값 저장소를 의미합니다.
Redis Modules는 Redis Core의 기본 기능을 확장하기 위해 개발된 모듈 시스템으로, Redis Core가 제공하는 기본 데이터 타입 이외에 다른 특화된 기능을 제공합니다.
[모듈을 사용하지 못하는 경우]
Amazon ElastiCache for Redis
Google Cloud Memorystore for Redis
같은 Redis 관리형 서비스는 Redis 모듈을 사용하지 못한다.
[모듈의 종류]
모듈은 독립적인 C/C++ 기반 프로그램으로 Redis 서버가 시작할 때 해당 모듈을 가져와서 Redis 내부에 포함시키는 방식!
But, 모듈을 Redis Core에 포함시킬 때는 보통 Redis Stack을 사용합니다.
RediSearch
Redis에서 텍스트 검색 기능을 제공합니다. 예를 들어, 관계형 데이터베이스에서처럼 복잡한 쿼리를 Redis에서도 실행할 수 있게 해줍니다.
⭐️ Query와 Search는 다릅니다.
- Query는 언제나 정확한 결과를 얻어내도록 하지만,
- Search는 가장 근접한 것을 결과로 가져옵니다.
명령어
FT.CREATE : 인덱스 생성
기존에 존재하는 INDEX를 생성하려고 하면 에러가 발생합니다

FT.CREATE
idx:cars : 생성할 인덱스의 이름
ON HASH || JSON : 어떤 데이터 구조를 인덱싱할지 정의하는 옵션 → HASH, JSON( RediJSON사용시)만 가능
PREFIX 1 cars# : 인덱스 Key 개수와 인덱스 할 Key의 이름
SCHEMA : 속성 정의
name TEXT : 필드 정의 → 필드의 이름과 데이터 타입
// 데이터 타입 정의
TEXT: 문자열 검색용.
TAG: 정확한 값 검색용 (문자열).
NUMERIC: 숫자, 범위 검색, 정렬용.
GEO: 지리적 위치, 위도/경도 기반 검색용.
BOOLEAN: true/false 값 저장.
DATE: 날짜 및 시간 값 저장, 날짜 범위 검색용.
'
'
'FT.SEARCH : 인덱스 검색
FT.SEARCH
<index_name> : 검색을 실행할 인덱스의 이름.
query : 검색할 쿼리 문자열. 이 쿼리는 검색할 키워드나 조건을 정의합니다.
// 쿼리 타입 정리
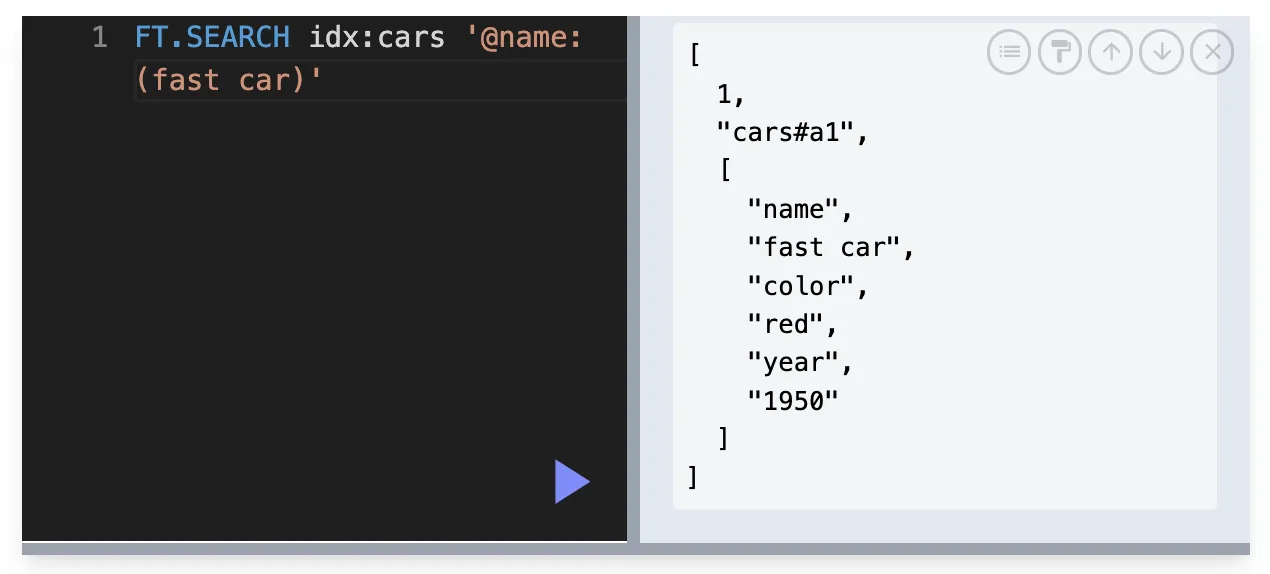
@필드이름:(검색어) → **TEXT** 검색에서 구문 검색에 사용하며
정확한 구문을 찾는데 사용
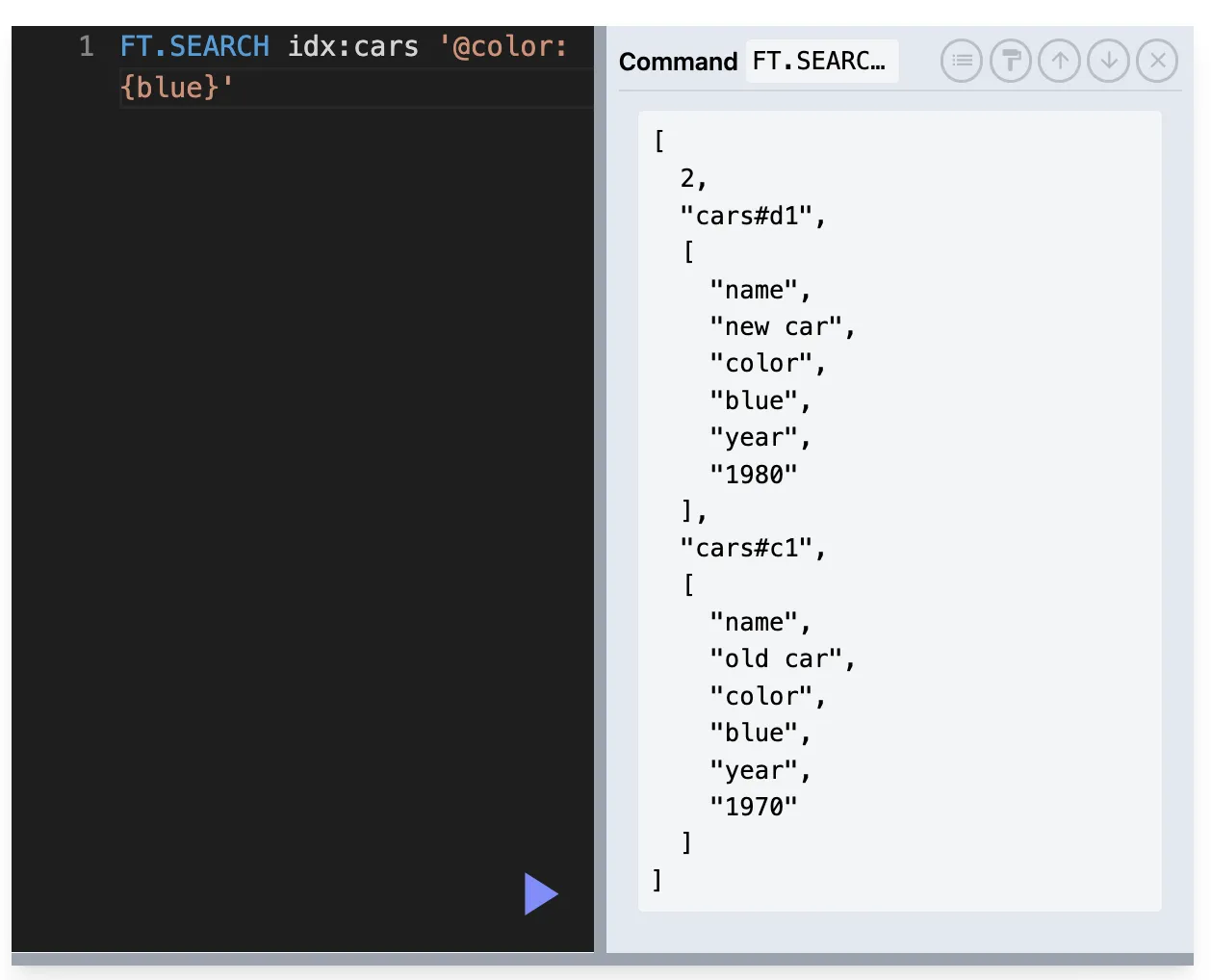
@필드이름:{검색어} → **TAG** 필드에서 정확한 값 일치를 검색하는 데 사용
@color{blue} - color가 blue인 TAG 검색
-@color:{blue} - color가 blue가 아닌 TAG 검색
@color:{light\blue} - color가 light blue인 TAG 검색
// @color:{light blue} - color가 light && blue 라는 뜻
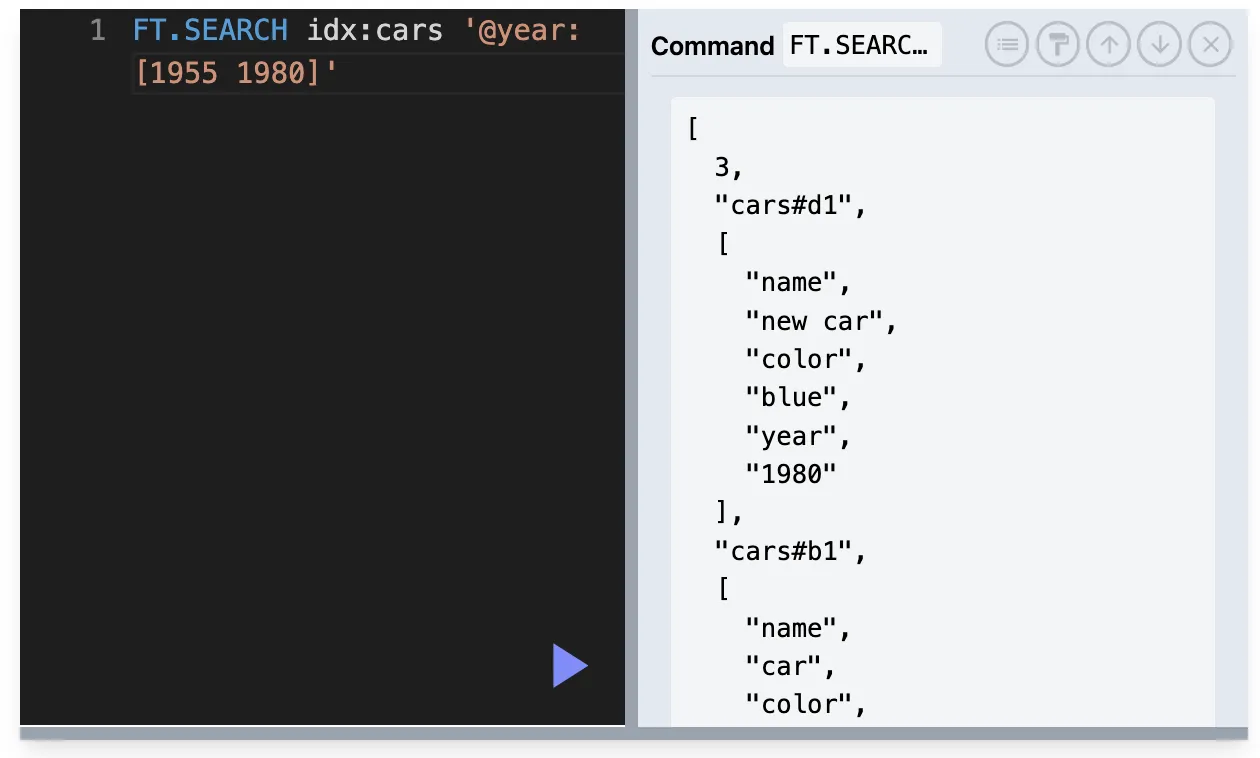
@필드이름:[검색어] → 수치 범위 검색을 위해 사용.options : 선택적 옵션으로, 검색 결과를 제한하거나 정렬하거나 필터링하는 데 사용됩니다.
// 옵션 정리
LIMIT: 검색 결과의 시작 위치와 반환할 항목 수를 설정.
SORTBY: 결과를 특정 필드를 기준으로 정렬.
FILTER: 필드 값을 기준으로 범위 검색.
RETURN: 검색된 항목에서 반환할 필드를 지정.
EXPLAIN: 검색 쿼리의 실행 계획을 설명.
HIGHLIGHT: 검색 결과에서 일치하는 부분을 강조.
WITHSORTKEY: 정렬 키와 함께 검색 결과 반환.
NOCONTENT: 검색 결과에서 내용 제외하고 메타데이터만 반환.
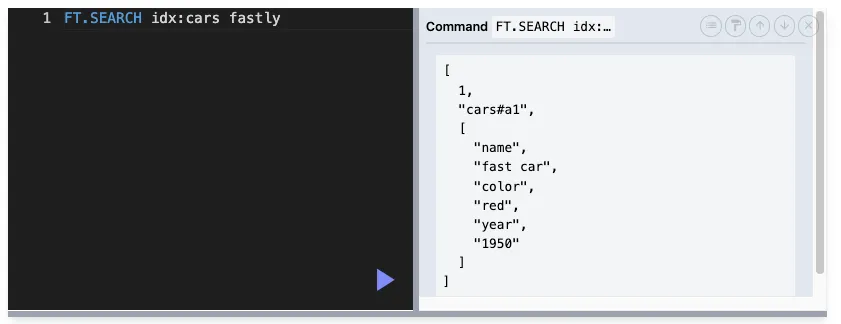
INKEYS: 특정 키 범위 내에서만 검색 실행.RediSearch는 스테밍이라는 기법으로 텍스트를 처리함
- 스테밍 : 단어의 어근을 추출하는 과정 ex) running → run, fastly → fast
- a, the와 같은 단어는 불용어 처리
RediSearch는 TF-IDF 알고리즘을 사용합니다.
TF-IDF는 문서에서 특정 단어의 중요도를 측정하는 방법으로, 해당 단어가 문서 내에서 자주 등장하면서 전체 문서 집합에서는 드물게 나타날수록 높은 가중치를 부여하는 알고리즘입니다.
옵션이 많으니 공식문서를 참고!
FT.EXPLAINCLI - 쿼리가 Redisearch에서 어떻게 실행되는지에 대한 설명을 제공합니다. 이를 통해 실행 계획을 확인하고, 쿼리의 성능을 분석하거나 문제를 식별할 수 있습니다
FT.PROFILE - 쿼리의 실행 성능을 세부적으로 분석하고, 실행 시간과 리소스 소비에 대한 정확한 정보를 제공하는 도구입니다.
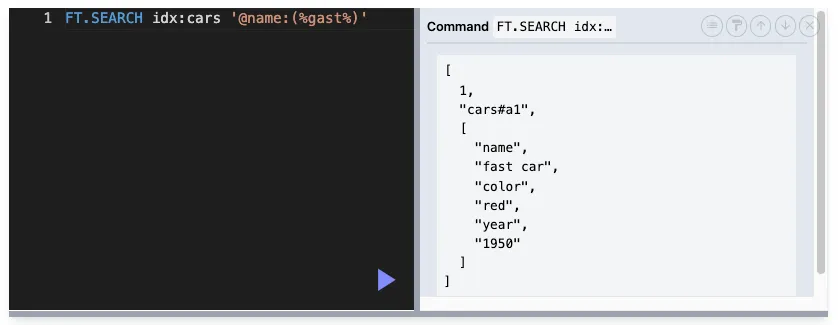
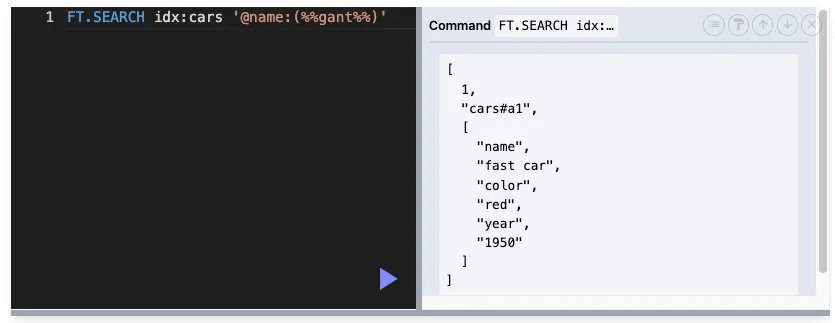
퍼지 검색
사용자가 정확한 단어를 입력하지 않아도 비슷한 단어나 철자가 유사한 단어를 검색할 수 있도록 해주는 기능입니다.
⭐️ Levenshtein 거리를 기반으로 철자 차이를 허용하는 방식
%를 사용해서 가능 → 와일드카드 X
%가 1개 → 단어가 1개 차이
%가 2개 → 단어가 2개 차이
‘
‘
사용자가 검색어를 입력하고 실행했을 때, 검색 결과를 보여줄 때 사용할 수 있다.
ex) dar → car로 검색
apple → appl로도 검색 가능
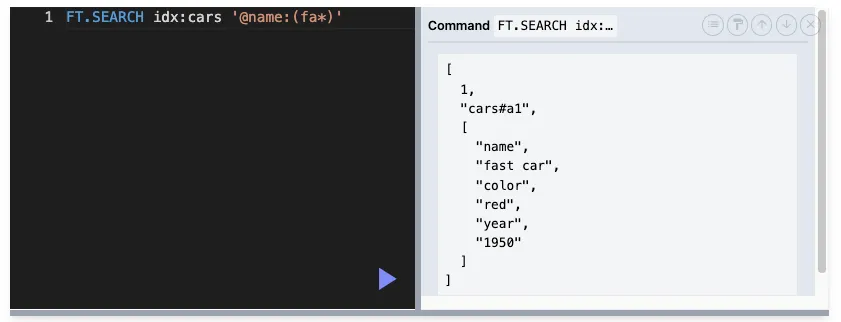
접두어 검색
검색어의 앞부분을 기반으로 문서를 검색하는 기법
최소 2개의 문자가 있어야 한다.
사용자가 검색창에 입력했을 때 자동완성을 보여줄 때 사용할 수 있다
ex) fa* → fast 포함
run → running, runner … 포함
Redis Streams
Redis Streams는 대용량 실시간 데이터 스트리밍을 처리할 수 있는 데이터 구조로, 이벤트 소싱 및 로그 처리에 유용합니다.
일종의 리스트와 정렬 집합이 섞인 데이터타입
컨슈머가 메세지를 받더라도 삭제되지않음.
명령어
XADD : 스트림에 메시지 추가
XADD streamName id key1 value1 key2 value2 …
streamName : 스트림 이름
id : ID 기본값은 *으로 자동 생성
key1 value1 : key, value 설정
'
'

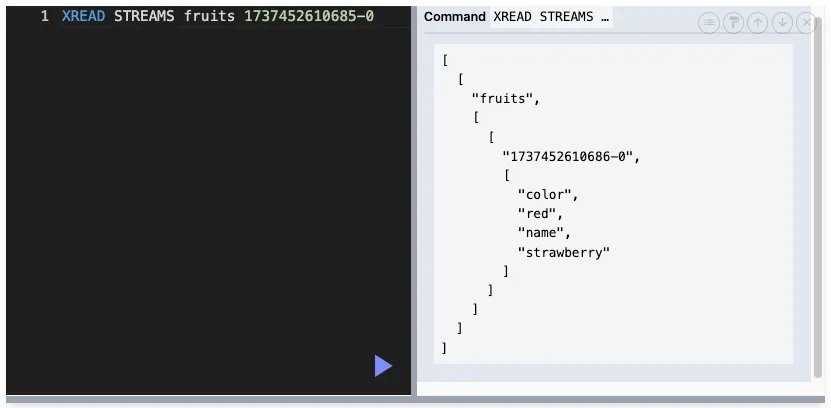
XREAD : 스트림에서 메세지 읽기
XREAD [COUNT count][BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
BLOCK : 새 메시지가 도착할 때까지 대기할 시간(밀리초 단위). 기본값은 0
예를 들어, 3000이라면 3초동안 새로운 메세지가 들어오지 않는지 대기한 뒤 응답을 반환
COUNT : 읽을 메세지의 최대 개수
STREAMS stream1 strema2 ... : 읽을 스트림 이름
id : 각 스트림에서 메시지의 시작 ID입니다. 이 ID 이후부터 메시지를 읽습니다.
예를 들어, 0 또는 >를 사용하여 읽을 시작점을 지정할 수 있습니다.
$ 기호를 넣으면 현재 시각 이후의 가장 최근에 추가된 메세지부터 1개만 읽어옴
> 기호를 넣으면 아직 처리되지 않은 메세지부터 조회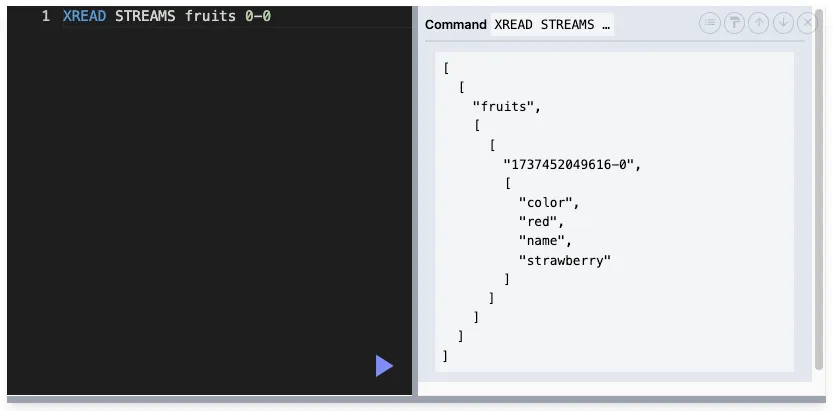
XRANGE : 범위 조회
XRANGE streamName start end [COUNT ]
stream_name: 조회할 스트림의 이름입니다.
start: 메시지 범위의 시작 ID입니다. ID는 타임스탬프와 시퀀스 번호로 구성된 형식(timestamp-sequence)입니다.
start를 포함하여 조회합니다.
0 : 스트림의 첫 번째 메시지부터 조회합니다.
> : 스트림의 최신 메시지부터 조회합니다.
- : ID 최소값
+ : ID 최대값
end: 메시지 범위의 끝 ID입니다. 이 값이 생략될 수 있습니다.
만약 끝 ID를 지정하지 않으면, 스트림에서 start ID부터 마지막까지 메시지를 가져옵니다.
COUNT : 가져올 메시지의 최대 개수를 지정합니다. 지정된 수만큼만 메시지를 가져옵니다.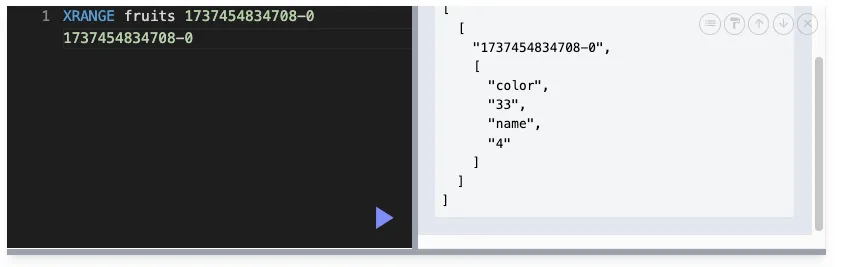
Consumer Group (컨슈머 그룹)
여러 개의 소비자(consumer)들이 동일한 스트림에 있는 메시지를 병렬로 처리할 수 있도록 도와주는 기능입니다.
기본적으로 Redis Streams는 생산자(producer)가 스트림에 데이터를 추가하고, 소비자들이 그 데이터를 처리하는 구조입니다. 하지만 여러 소비자가 동시에 동일한 스트림을 처리하는 경우, 각 소비자가 메시지를 중복 처리하거나 놓칠 수 있습니다. 이를 해결하기 위해 Comsumer Group을 사용합니다.
[명령어]
XGROUP CREATE : 컨슈머 그룹 생성
XGROUP CREATE streamNmae groupName 시작지점 MKSTREAM
streamName : Redis 스트림에서 데이터를 처리할 스트림을 지정
groupName : 컨슈머 그룹의 이름
시작 지점 : 메세지를 읽기 시작할 지점
$ : 최신 메세지부터 처리
MKSTREAM : 지정된 스트림이 존재하지 않을 경우 새로운 스트림을 자동으로 생성하는 역할
XGROUP CREATECONSUMER : 컨슈머 그룹에 컨슈머 추가
XGROUP CREATECONSUMER key groupName consumerName

XREADGROUP GROUP : 컨슈머 그룹을 사용해 메시지를 읽는 명령어
XREADGROUP GROUP groupName consumerName [COUNT ] STREAMS streamName start
GROUP groupName consumerName : 컨슈머 그룹의 이름을 지정
COUNT : 읽어올 메세지 개수
STREAMS streamName : 데이터를 읽을 스트림의 이름을 지정
start : 메시지를 읽기 시작할 지점을 지정
> : 처리되지 않은 메세지부터 시작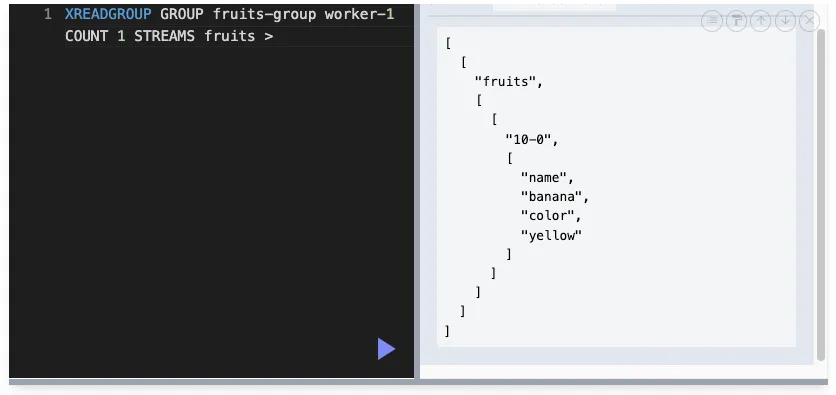
XACK : 메시지가 정상적으로 처리되었음을 알려주는 명령어
XACK streamName groupName messageID [messageID ...]
해당 명령어를 통해
- 중복 처리를 방지
- 복구 작업을 진행할 수 있다 →
XAUTOCLAIM명령어
[사용 사례]
- 메세지 큐
- 실시간 이벤트 처리 및 로그 기록
주의사항?
- Consumer가 메시지를 읽어도 소비되지않는다. 즉, Stream에 그대로 남아있다
- 메시지를 받은 이후 처리가 되었는지 확인(에러가 발생하지 않았는지?)해야한다. ACK를 이용하여.
