List
List 자료구조는 단순 연결 리스트(Singly Linked List) 형태로 구현된 데이터 구조입니다.
리스트는 원소를 순서대로 저장하며, 삽입, 삭제, 조회 등 다양한 연산을 지원합니다.
Redis에서는 List 자료구조를 활용하여, 큐(Queue) 또는 스택(Stack) 구조로 데이터를 처리할 수 있습니다.
List는 배열이 아니며 데이터가 많다면 리스트를 사용하지 않는 것이 좋음
특징
- 순서가 있는 데이터 저장
- 양방향 접근 : 양방향 큐(DeQueue) 기능을 제공
- 중복 원소 허용
- 다양한 연산
장점
- 빠른 삽입과 삭제: 리스트의 양 끝에서 원소를 빠르게 삽입하고 삭제할 수 있습니다.
- 고성능: Redis는 싱글 스레드로 동작하기 때문에, 리스트에 대한 연산이 매우 빠르게 처리됩니다.
- 다양한 응용: 큐, 스택, 또는 일반적인 리스트로 활용 가능.
단점
- 메모리 사용: 리스트의 크기가 커지면 메모리 사용량이 많아질 수 있습니다.
- 순차 접근: 중간에 있는 원소에 접근하려면 리스트를 순차적으로 조회해야 하므로 인덱스로 직접 접근하는 것이 불가능합니다.
명령어
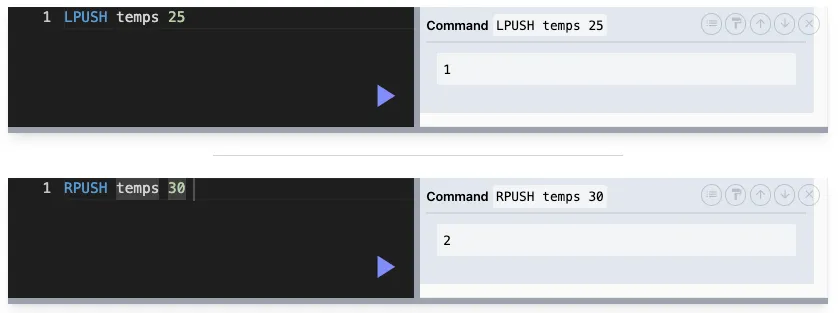
LPUSH / RPUSH : 좌우에 값 추가
LPUSH key value
RPUSH key value
리스트 개수를 반환
LLEN : 리스트 길이 조회
LLEN key

LINDEX : 해당 인덱스 값 조회
LINDEX key index
인덱스는 0부터 시작

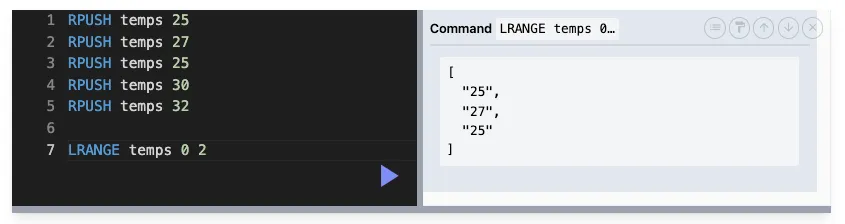
LRANGE : 범위 조회
LRANGE key start end
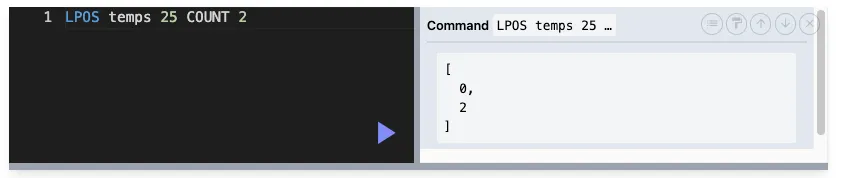
LPOS : 검색 (인덱스를 알려줌)
LPOS key value [RANK][COUNT] [MAXLEN]
RANK : 무시 (순서) → RANK 2 : 처음으로 등장하는 값은 무시하고 두번째 값을 조회합니다
COUNT : 배열을 반환 → COUNT 2 : 등장하는 2개를 찾아라
MAXLEN : 최대 길이


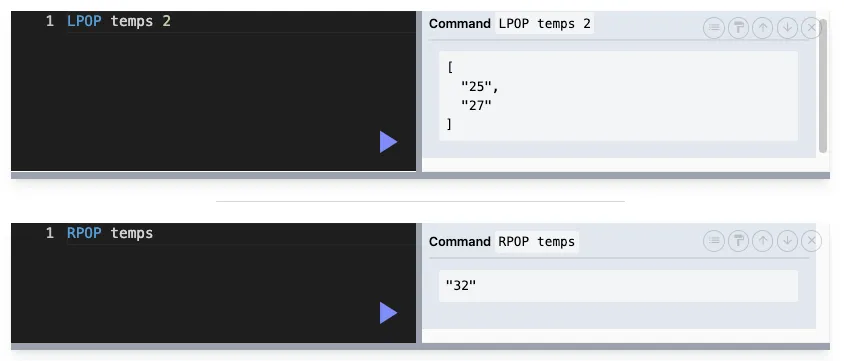
LPOP / RPOP : 조회하고 삭제
LPOP key [COUNT]
RPOP key [COUNT]
COUNT : pop할 개수
마지막으로 POP한 값을 반환
LSET : 값 변환
LSET key index value
index의 값을 value로 변환

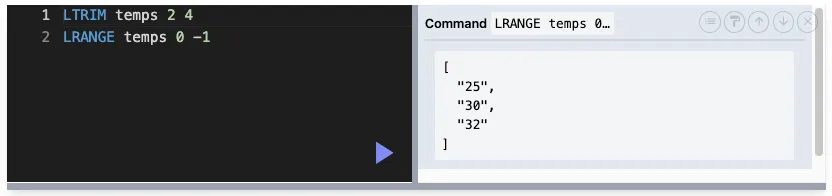
LTRIM : 범위를 제외한 나머지 삭제
LTRIM key start end
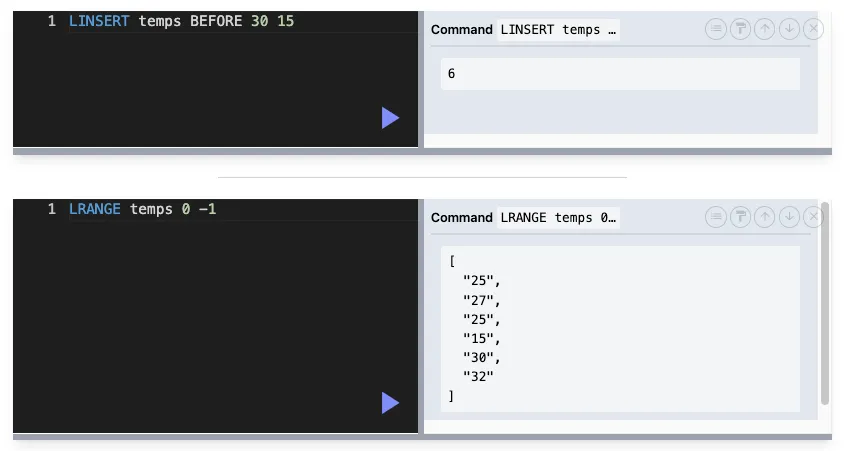
LINSERT : 새 항목 추가
LINSERT key where value1 value2
where : BEFROE || AFTER → value1 이전 or 이후에 넣을 지?
value1의 이전 혹은 이후에 value2를 삽입
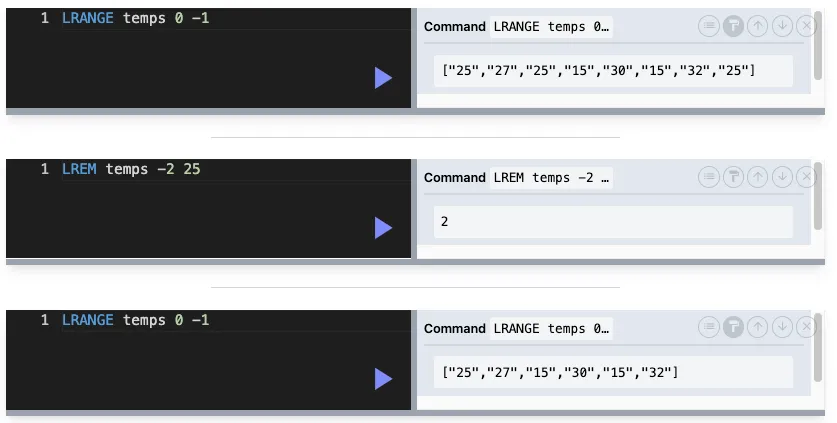
LREM : 삭제
LREM key count value
value를 count만큼 삭제.
count가 양수 → 왼쪽부터 시작
count 0 → 모두 삭제
count가 음수 → 오른쪽부터 시작
HyperLogLog
HyperLogLog는 대규모 데이터 집합에 대해 고유 원소의 개수(즉, 집합의 cardinality)를 추정하는 데 사용되는 데이터 구조입니다.
정확한 개수가 아니라 근사치를 계산하며, 매우 적은 메모리로도 효율적인 계산을 수행할 수 있다는 장점이 있습니다.
정보) Logging과는 전혀 관련없다
특징
- 요소를 실제로 저장하지 않음 → 약 12KB
- 중복 허용 X
- 정확한 개수가 아닌 근사치 → 0.81%의 오차율
사용 사례
대규모 데이터의 고유 원소 수를 빠르게 추정해야 하는 상황에 적합.
ex) 웹 페이지의 고유 방문자 수 추정 → 단순히 방문자 수 or 조회 수를 확인하는 것뿐인데 따로 DB에 저장하는 것은 굳이????? 라는 이유 때문.
ex) 대규모 이벤트 스트림의 고유 이벤트 수 추정
명령어
PFADD : 추가
PFADD key value1 value2 …

PFCOUNT
PFCOUNT key

