Abstract
- Chain-of-thought prompting은 다양한 자연어 추론 작업에서 뛰어난 성능을 보여주고 있음
- 하지만, 프롬프트에 제시된 예시보다 더 어려운 문제를 해결해야 하는 작업에서는 성능이 저하되는 경향
- 이러한 쉬운 문제에서 어려운 문제로의 어려움을 극복하기 위해, least-to-most prompting을 제안
- 핵심 아이디어는 복잡한 문제를 일련의 더 간단한 하위 문제로 나누고, 이를 순차적으로 해결하는 것
- 이전 하위 문제를 해결한 결과를 통해, 다음 하위 문제를 푸는 데 필요한 정보를 제공한다는 개념을 이용
실험
- symbolic manipulations, compositional generalization, 수학적 추론과 관련된 과제에서 least-to-most prompting이 프롬프트에서 제시된 것보다 더 어려운 문제에 일반화할 수 있음을 확인
- 특히 GPT-3의 code-davinci-002 모델을 least-to-most prompting과 함께 사용할 때, SCAN이라는 compositional generalization 벤치마크 데이터셋에서, 최소 99%의 정확도로 문제를 해결할 수 있음!
1 Introduction
-
인간 지능과 기계 학습의 차이점
- 인간은 새로운 과제를 소수의 예시만으로도 학습할 수 있지만, 기계 학습은 많은 양의 라벨링된 데이터가 필요함
- 인간은 자신의 예측이나 결정의 이유를 명확히 설명할 수 있지만, 기계 학습은 본질적으로 '블랙박스'임
- 인간은 본 적 없는 더 어려운 문제도 해결할 수 있지만, 기계 학습은 훈련과 테스트가 동일한 난이도에서 이루어짐
-
Chain-of-thought Prompting
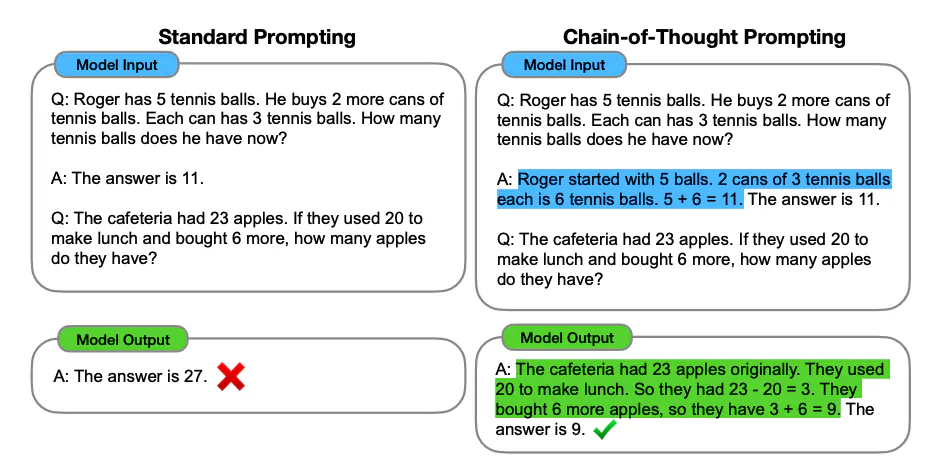
- 소수 예시를 활용해 인간과 machine 간의 차이를 줄이는 데 큰 진전을 이룸
- 하지만, 이 방법은 예시에서 나오지 않은 더 복잡하고 어려운 문제를 해결해야 하는 상황에서는, 성능이 저하되는 경향이 있음
- 특히, compositional generalization는 이러한 상황에서 중요한 개념임
compositional generalization란, 모델이 개별적으로 배운 개념들을 결합해 본 적 없는 새로운 조합을 이해하고 처리할 수 있는 능력을 의미합니다. 예를 들어, "walk twice and jump"라는 명령어를 본 모델이, "walk twice and turn left"라는 명령어도 정확히 처리할 수 있어야 하는데, 이때 이런 조합적인 일반화 능력이 필요합니다.
-
Least-to-most prompting
- 복잡한 문제를 더 쉬운 하위 문제로 나눈 다음, 이를 순차적으로 해결하는 방식: 2-stage로 이루어져있으며 먼저 복잡한 문제를 더 쉬운 하위 문제 목록으로 분해한 후, 이 하위 문제들을 순차적으로 해결
- 각 하위 문제는 이전 문제의 답을 기반으로 해결됨
- few-shot prompting으로 구현되며, 추가적인 모델의 학습이나 fine-tuning을 사용하지 않고 소수의 예시만으로 문제를 해결할 수 있음
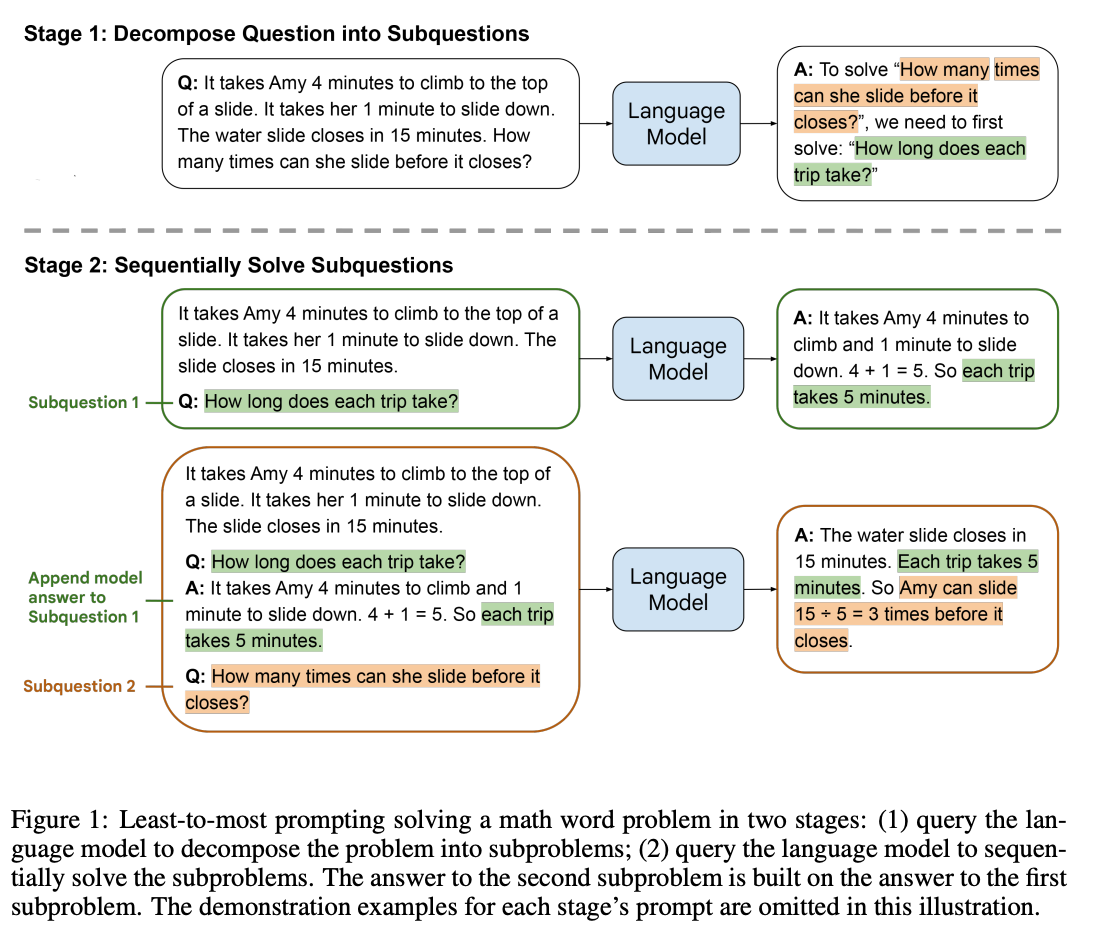
- Least-to-most prompting이라는 용어는 교육 심리학에서 차용된 것으로, 학생이 새로운 기술을 배우도록 돕기 위해 점진적인 단서 시퀀스를 사용하는 기법
2 LEAST-TO-MOST PROMPTING
- 분해 단계(Decomposition): 문제를 하위 문제로 나누는 단계
- 그림 1에서, 언어 모델은 먼저 원래 문제를 하위 문제들로 분해하도록 요청받음
- 모델에 전달받은 프롬프트는 복잡한 문제를 분해하는 예시들 (그림에없음)과 분해할 특정문제로 구성됨
- 모델은 원래 문제를 중간 문제인 "각 여행은 얼마나 걸리는가?"를 해결함으로써 해결
- 하위 문제 해결 단계(Subproblem solving): 하위 문제들을 순차적으로 해결하는 단계
- 분해 단계에서 나온 하위 문제들을 순차적으로 해결하도록 언어모델에 요청함
- 프롬프트는 하위 문제를 해결하는 방법을 보여주는 예시들 (그림에없음)과 첫번째 문제인 "각 여행은 얼마나 걸리는가?"로 구성된 프롬프트를 모델에 전달하는것부터 시작
- 모델의 답변을 받아서("... 각 여행은 5분이 걸립니다.")을 받아서 이전 프롬프트에 추가한 뒤, 다음 하위 문제(이 예시에서는 원래 문제)를 이어서 구성함
3 RESULTS
3.1 SYMBOLIC MANIPULATION
"Symbolic manipulation(기호 조작)"은 자연어 처리(NLP)에서 기호나 상징을 조작하거나 다루는 작업을 의미합니다. 이 태스크는 주로 기호적 데이터를 변형하거나 처리하는 작업을 포함하며, 언어적 기호(단어, 문자 등)의 패턴을 인식하고 변환하는 것이 핵심입니다.
자연어 처리에서 SYMBOLIC MANIPULATION과 관련된 대표적인 태스크로는 다음과 같은 것들이 있습니다:
- 문자열 변환(String manipulation): 예를 들어, 주어진 단어의 특정 문자나 부분을 추출하거나 변형하는 작업입니다. 마지막 글자 연결 작업(last-letter concatenation task)과 같은 것이 이에 속합니다.
- 식 처리(Mathematical expression handling): 자연어로 된 수식을 처리하거나 기호로 표현된 수식을 계산하는 작업입니다.
- 규칙 기반 변환(Rule-based transformations): 기호적 규칙에 따라 텍스트를 변환하는 작업입니다. 예를 들어, 문법적 규칙에 따라 문장을 변환하거나 리포매팅하는 작업이 있을 수 있습니다.
- 여기서는, 마지막 글자 연결 작업(last-letter-concatenation task)을 사용
- 입력은 단어 목록이고, 출력은 목록의 각 단어의 마지막 글자를 연결한 것
- 예를 들어, “thinking, machine”이라는 입력은 “ge”를 출력하는데, 이는 "thinking"의 마지막 글자가 "g"이고, "machine"의 마지막 글자가 "e"이기 때문
- 기존 COT prompting은, 테스트 할 단어의 목록이 예시에 있는것 보다 훨씬 길 경우 성능이 저하됨
Least-to-most prompting

(1) 분해: 단어 목록을 일련의 하위목록으로 분해

(2) 입력을 원하는 출력으로 매핑함
COT prompting

프롬프트는 표 2의 Least-to-most prompting와 동일한 목록을 사용하지만, 차이점은 COT는 scratch로 작성한 단어 목록 하나하나의 예시를 사용함
Results
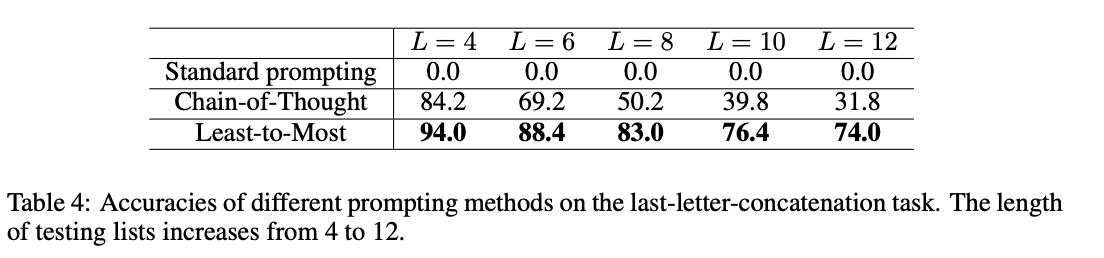
- 다양한 길이의 단어목록을 구성하기 위해 Wiktionary에서 무작위로 단어를 샘플링
- L은 단어 목록의 길이를 의미하며, 주어진 길이마다 500개의 목록이 구성됨
Error Analysis
- 긴 목록에서 100%의 정확도를 달성하지는 못하는데, 대부분의 오류는 마지막 글자를 잘못 선택한 것이 아니라, 연결오류 (문자 생략 또는 추가) 때문
- "hollow, supplies, function, gorgeous"라는 목록에서 모델이 "wsn"과 "s"를 연결하는 과정에서 마지막 글자인 "s"를 중복시켜, 결과적으로 "wsns" 대신 "wsnss"라고 예측
3.2 COMPOSITIONAL GENERALIZATION
- SCAN은 compositional generalization을 평가하는 데이터셋
- 자연어 명령을 동작 시퀀스로 매핑하는 작업을 요구

- Sequence-to-sequence 모델은 성능이 저조한데, 훈련 세트의 동작 시퀀스(전체 세트의 약 80%, 20,000개 이상의 예시 포함)가 테스트 세트의 동작 시퀀스보다 짧기 때문임
Least-to-most prompting

(1) 긴 명령어를 짧은 명령어 목록으로 분해하는 방법을 보여주는 8개의 예시가 포함된 분해

(2) 자연어 명령어를 동작 시퀀스로 매핑하는 방법을 보여주는 14개의 예시가 포함된 명령어 매핑
(언어 모델의 입력 크기 제한(일반적으로 최대 2048 토큰)을 충족하기 위해 파이썬 표기법을 사용
예를 들어, 프롬프트 설계에서 "look twice"를 "LOOK" * 2로 매핑하고 "LOOK LOOK"으로 매핑하지 않음)
COT prompting
Least-to-most prompting와 동일한 목록을 사용하지만, 분해 과정은 없고 표7과 동일한 입력 사용
Results

Error Analysis
- 총 13개의 에러
- 6개는 "twice"와 "thrice"를 "around" 뒤에 잘못 해석한 것이며, 나머지는 "after"를 "and"로 잘못 해석한 것
- 예를 들어, "walk opposite right twice after run around right thrice"라는 명령에서, code-davinci-002는 "run around right"을 ("TURN RIGHT" + "RUN") 4로 정확히 번역했지만 thrice"를 이 표현에 적용하는 과정에서 실수를 하여 ("TURN RIGHT" + "RUN") 4 3 또는 ("TURN RIGHT" + "RUN") 12 대신에 ("TURN RIGHT" + "RUN") * 9를 생성함
3.3 MATH REASONING
-
GSM8K와 DROP에서 수학적 문제를 해결하기 위해 Least-to-most prompting를 적용

-
LLM이 Least-to-most prompting와 결합하여 프롬프트에서 봤던 문제보다 더 어려운 문제를 해결할 수 있는지 확인하는데에 집중함
-
단순히 해결 단계의 수로 문제의 난이도를 측정하였음
Least-to-most prompting

- 첫 번째 부분(“이 문제를 분해해 봅시다”로 시작)은 원래 문제를 더 간단한 하위 문제로 분해하는 방법을 보여주고, 두 번째 부분은 하위 문제들이 순차적으로 어떻게 해결되는지를 보여줌 -> 이 프롬프트는 분해와 하위 문제 해결을 단일 단계로 결합한 것이고, 성능을 더 향상시키기 위해 이전 섹션처럼 분해와 하위 문제 해결을 각각 별도의 프롬프트로 설계할 수도 있음!
COT prompting

Results
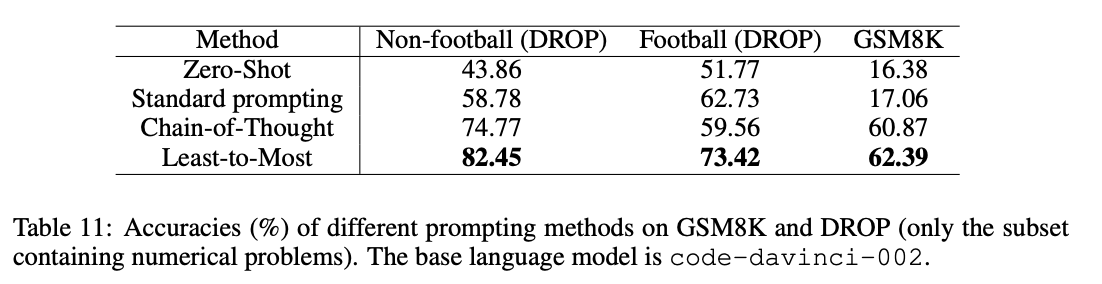
- GSM8K에서, 60.97%에서 62.39%로 약간 향상되었지만, 적어도 5단계 이상이 필요한 문제를 해결하는 데 있어 성능을 크게 향상함

- DROP에서, 훨씬 우수한 성과를 보였고, 이는 아마도 DROP의 대부분의 문제들이 쉽게 분해될 수 있기 때문일 것으로 추측
- Football(축구 경기와 관련된 점수계산, 경기결과 예측등의 문제들)
4 LIMITATION
- 분해 단계는 일반적으로 다양한 도메인에서 잘 일반화되지 않음
- 예를 들어, 수학 문제를 분해하는 방법을 보여주는 프롬프트는 LLM에게 "아리스토텔레스가 노트북을 사용했을까?"와 같은 상식 추론 문제를 분해하는 방법을 가르치는 데 효과적이지 않고, 이러한 유형의 문제에 대해 최적의 성능을 달성하려면 새로운 프롬프트를 설계해 분해 과정을 시연해야 함.
- 수학 문제를 더 간단한 하위 문제로 성공적으로 분해할 수 있을 때, 우리는 본질적으로 원래 문제를 해결한 셈이며, least-to-most의 직관과 동일하지만, 마지막 글자 연결 작업과 SCAN 벤치마크에서 뛰어난 결과가 나온 이유는 이 작업들에서 분해가 비교적 단순하기 때문
5 CONCLUSION AND DISCUSSION
-
언어 모델이 프롬프트에 있는 문제보다 더 어려운 문제를 해결할 수 있도록 하기 위해 least-to-most의 프롬프팅을 도입
-
문제의 상향식 분해(top-down decomposition)와 하향식 해결 생성(bottom-up resolution generation)으로 이루어짐
-
일반적으로, 프롬프팅은 LLM에게 추론 능력을 가르치는 최적의 방법이 아닐 수 있음
-
프롬프팅은 언어 모델에게 피드백을 고려하지 않고 지시를 내리는 일방향적 의사소통 방식으로 볼 수 있으며, 자연스러운 발전은 프롬프팅을 완전한 쌍방향 대화로 발전시키는 것임
