Abstract

심볼 튜닝(symbol tuning)
- 자연어 레이블(예: "긍정적/부정적 감정 분석")을 임의의 기호(예: "foo/bar")로 대체하여 LM을 fine-tuning하는 기법
- 언어 모델 fine-tuning이 모델의 행동과 성능을 크게 변화시킬 수 있다는 기존 연구들과 관련이 있음 (예를 들어, Instruction Tuning은 작업을 명령어로 표현해 파인튜닝하여 제로샷 성능을 향상시킴)
- 모델이 명령어 또는 자연어 레이블을 사용해 작업을 파악할 수 없을 때, 대신 input-label 매핑을 학습하여 작업을 이해해야 한다는 직관을 활용함
- 우리의 연구는 in-context 예시와, 불충분하게 설명된 프롬프트를 사용하는 설정에 초점을 맞춤
작업을 설명하는 명령어나 자연어 레이블이 충분히 제공되지 않아서 모델이 작업을 이해하기 어려운 경우입니다. 예를 들어, 단순히 문장만 주어지고 "Foo" 또는 "Bar"와 같은 임의의 기호가 레이블로 주어진다면, 모델은 이 프롬프트만으로는 어떤 작업을 수행해야 하는지 쉽게 파악할 수 없습니다. 이 경우 모델은 인컨텍스트 예시를 통해서 작업의 패턴을 추론해야 합니다.
결과
- PaLM 모델에서 symbol tuning 실험
- symbol tuning은 보지 못한 새로운 In context learning에서 성능을 향상시키고, 명령어 또는 자연어 레이블이 없는 미비한 프롬프트에 훨씬 더 강력하게 대응함
- 알고리즘적 추론 작업에서 훨씬 더 강력하며, List Functions 벤치마크에서 최대 18.2% 더 나은 성능을, Simple Turing Concepts 벤치마크에서 최대 15.3% 더 나은 성능을 보임
- In-context에서 뒤바뀐 레이블을 따르는 데 있어 큰 개선을 보이며, 사전 지식을 무시하고 In-context 정보를 활용할 수 있는 능력이 더 뛰어남
1. Introduction
-
인간 지능의 중요한 특징 중 하나는 인간이 소수의 예시만으로도 추론을 통해 새로운 작업을 학습할 수 있음!
-
언어 모델의 확장을 통해, In-context에서 주어진 소수의 예시를 통해 복잡한 추론 작업을 수행할 수 있는 능력이 존재
-
그러나 언어 모델은 프롬프트에 의존적이며, 이는 모델이 강력한 방식으로 추론하지 않고 있음을 나타냄
- 정교한 프롬프트 엔지니어링이 필요
- Instruction 이 필요
- 작업 성능이 임의의 레이블을 가진 예시를 보여주어도 영향을 받지 않음
- 문장: "이 영화 정말 훌륭했어!" → 레이블: "부정적"
- 문장: "이 영화는 별로였어." → 레이블: "긍정적"
-> 모델이 이 잘못된 레이블을 무시하고 여전히 문장의 실제 감정(긍정적/부정적)에 맞게 예측을 수행할 수 있는 경우
-> 즉, 모델이 프롬프트로 제공된 예시의 레이블에 의존하지 않고, 자체적으로 학습된 패턴에 따라 작업을 수행한다는 의미
- 뒤바뀐 레이블을 보여주었을 때도 예상치 못한 행동을 보이는 등의 현상
- 문장: "고양이는 동물이다." → 레이블: "거짓(False)"
- 문장: "물은 젖는다." → 레이블: "거짓(False)"
-> 모델은 본래 학습된 지식을 기반으로 이 문장들이 참(True)이라는 것을 알고 있지만, 프롬프트에서 뒤바뀐 레이블("거짓(False)")을 보고 혼란스러운 반응을 보일 수 있음
-> 모델이 이 뒤바뀐 레이블을 따르지 않고 원래의 참(True)으로 답하거나, 반대로 모델이 레이블에 너무 의존해 부정확한 출력을 내놓을 수 있음
-
따라서, 이 논문에서는 In-context에서 제시된 input-label mapping을 사용해 inference & train 능력을 크게 향상시키는 간단한 fine-tuning 절차인 "symbol tuning" 제안
-
symbol 절차에서는 자연어 label을 임의의 기호로 재매핑함
-> 핵심은 언어 모델이 자연어 명령어(instructions)나 자연어 레이블(labels)에 의존하지 않고도 작업을 수행할 수 있도록 학습해야 함! -
22개의 다양한 NLP 데이터셋을 혼합하여 각기 다른 기호를 label로 사용해 symbol tuning을 수행하고, 여러 크기의 instruction-tuned PaLM models (Flan-PaLM)을 사용해 실험을 진행함(8B, 62B, 62B-cont, 540B)
- symbol tuning은 다양한 환경에서 in-context 학습 작업에 대해 기본 모델의 성능을 향상시킴
- 알고리즘적 추론 작업에서 더 뛰어난 성능을 보이며, 이는 심볼 튜닝이 자연어 데이터만 포함하고 수치적 또는 알고리즘적 데이터는 포함하지 않았음에도 불구하고 놀라운 결과를 냄
알고리즘적 추론 작업이란, 예를 들어 리스트에서 마지막 요소를 제거하거나, 문자열에서 0과 1을 교환하는 것과 같이 명확한 규칙을 따르는 작업을 의미합니다. 이러한 작업은 보통 수학적 또는 논리적 추론을 요구합니다.
- label이 뒤바뀐 입력을 사용한 실험을 진행했으며, 사전 학습된 언어 모델은 어느 정도 뒤바뀐 레이블을 따를 수 있는 능력이 있지만, 이 능력은 instruction tuning 중에 사라지는 문제점이 있었음 하지만, 심볼 튜닝을 통해 다시 복원할 수 있음을 입증함!
2. Symbol tuning
-
LLM은 프롬프트에서 어떻게 제시되는지에 매우 민감하다는 점이 있으며, 이는 언어 모델이 견고한 방식으로 추론하지 못하고 있음을 시사함
-
따라서, instruction tuning을 사용해서 성능을 향상시키고 in-context에 제시된 예시를 더 잘 따르도록 돕는 것으로 정의되었음

-
그러나 한 가지 단점은, Instruction, Exemplar, label을 통한 예시들이 Evaluation example에서 중복적으로 정의되기 때문에, 모델이 실제로 예시를 사용해 학습하도록 강요되지 않는다는 점이 있음
- Figure 1의 왼쪽에서, 예시가 모델이 작업을 이해하는 데 도움을 줄 수 있지만, 모델이 예시를 무시하고 단순히 명령어만 읽더라도 작업을 수행할 수 있음
-
따라서, 모델이 in-context learning에서 더 나아지도록 하기 위해, symbol tuning을 제안
-
Instruction이 제거되고, label이 의미적으로 관련 없는 label(예: "Foo", "Bar" 등)로 대체된 예시로 fine-tuning됨
-
따라서, 모델이 꼭 in-context의 작업을 봐야하며, in-context에서 제시된 예시를 보지 않으면 작업이 어려워짐
- 예를 들어, 이전 단락의 프롬프트가 “<문장>. 답: {Foo, Bar}”로 변경되었다면 (Figure 1의 오른쪽) 작업을 파악하기 위해 여러 in-context의 예시가 필요하게 됨
-> "Foo"가 무엇을 의미하는지, "Bar"가 어떤 상황에서 사용되는지를 예시를 통해 학습하기 때문에, 이전에 본 적 없는 작업에서도 in-context의 예시와 label간의 관계를 추론해야 하는 상황에서 더 잘 대응할 수 있게 됨
-> 이는 symbol tuning에서 모델에게 단순히 명령어를 따르는 것이 아니라, 주어진 예시를 분석하고 그 예시들로부터 패턴을 찾아내는 능력을 길러주기 때문!
- 예를 들어, 이전 단락의 프롬프트가 “<문장>. 답: {Foo, Bar}”로 변경되었다면 (Figure 1의 오른쪽) 작업을 파악하기 위해 여러 in-context의 예시가 필요하게 됨
Summary
이전 연구에서는 언어 모델이 instruction과 label에 의존해 작업을 수행하면서, in-context에서 제시된 예시를 제대로 활용하지 못하는 한계가 있었음
- 정교한 프롬프트 엔지니어링이 필요
- Instruction 이 필요
- 작업 성능이 임의의 레이블을 가진 예시를 보여주어도 영향을 받지 않음
- 뒤바뀐 레이블을 보여주었을 때도 예상치 못한 행동을 보이는 등의 현상
심볼 튜닝(symbol tuning)은 자연어 label을 임의의 기호로 대체 + instruction을 제거하는 방법
- 모델이 in-context 예시와 label간의 관계를 추론하도록 학습함으로써 이 문제를 해결할 수 있음!
- 이를 통해 모델은 보지 못한 새로운 작업에서도 in-context learning을 통해 더 나은 성능을 발휘할 수 있게 되었음
3. Experimental setup
3.1 Tuning tasks & prompt formatting
- 데이터셋 선정: HuggingFace에서 제공하는 22개의 공개된 NLP 데이터셋을 심볼 튜닝 절차에 사용함
- 작업 유형: 심볼 튜닝이 binary label을 필요로 하기 때문에 classification task로 진행
- 프롬프트 구성: 각 데이터셋에서 학습 데이터의 예시를 사용해 튜닝에 사용할 프롬프트를 구성함. 프롬프트는 무작위로 선택된 input-label 형식을 사용하며, 클래스당 2~10개의 무작위 인컨텍스트 예시를 포함
- 레이블 매핑(boo,foo같은): 레이블은 약 3만 개의 임의 레이블 세트 중에서 무작위로 선택해 다시 매핑함

3.2 Evaluation tasks
- 평가 목표: 모델이 이전에 보지 못한 작업에서의 성능을 평가하기 위해, symbol tuning에서 (22개의 데이터셋) 사용되지 않은 11개의 NLP 데이터셋을 선택함
- 데이터셋 선정: HuggingFace에서 제공되는 11개의 NLP 데이터셋을 사용했으며, 각 데이터셋의 검증 분할에서 최대 100개의 예시를 무작위로 선택하여 평가 프롬프트를 생성함
- 프롬프트 구성: 각 평가 프롬프트는 무작위로 선택된 입력-레이블 형식을 사용하며, 클래스당 인컨텍스트 예시 수를 4개로 고정함
- 평가 설정: 4가지 인컨텍스트 학습(ICL) 설정을 사용해 프롬프트를 생성함
- Instruction 포함 여부 O/X
- 자연어 label 포함 여부 O/X -> 자연어 포함 안될때는 foo, bar 같은 label을 사용
왜 이렇게 했지? 이해안됨
3.3 Models & finetuning procedure
- 모델 및 튜닝 설정: Flan-PaLM 모델(8B, 62B, 540B)과 Flan-PaLM-62B-cont(1.3T 토큰으로 학습된 모델)를 사용
- 데이터셋 및 샘플링: 모든 데이터셋을 혼합하여 무작위 샘플링을 수행했고, 데이터셋당 학습 예시 수를 최대 25,000개로 제한함. input-label은 EOS 토큰으로 구분함
- 튜닝 설정: 각 모델에 대해 배치 크기 32, Adafactor 옵티마이저를 사용했으며, 8B 및 62B 모델은 4,000 step, 540B 모델은 1,000 step 튜닝 진행
4 Symbol-tuned models are better in-context learners
- symbol tuning은 다양한 환경에서 in-context 학습 작업에 대해 기본 모델의 성능을 향상시킴
-
심볼 튜닝은, 모델은 자연어 label이랑 instruction으로 부터 학습할 수 없도록 프롬프트가 수정되기 때문에, 작업을 성공적으로 수행하려면 in-context 예시를 보고 label로부터 추론하는 법을 학습해야 함
-
따라서 심볼 튜닝된 모델은 작업이 명확하지 않고 in-context내에서 예시와 label 간의 추론이 필요한 환경에서 더 나은 성능을 보여야 함 -> instruction과 label이 모두 제공되지 않는 프롬프트를 사용하는 경우!
-
그래서 아래 4개의 설정을 한것이었음

-
실험결과
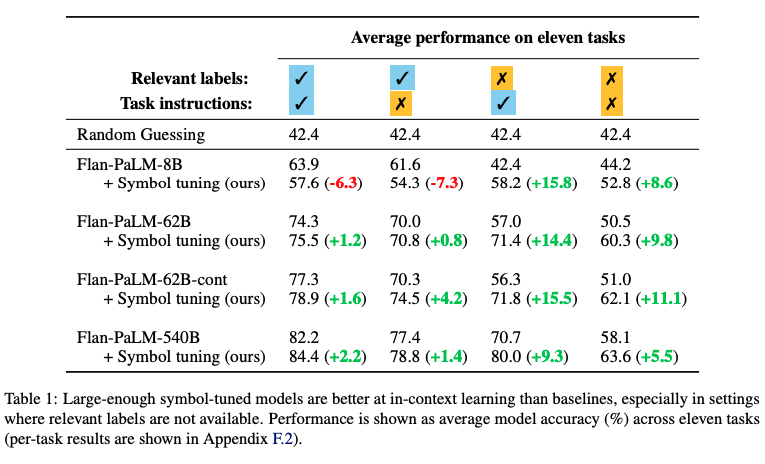
-
심볼 튜닝은 자연어 label이 없는 설정에서 큰 성능 향상을 보임(+5.5%에서 +15.5%)
-
특히, 관련된 레이블이 없는 경우 심볼 튜닝된 Flan-PaLM-8B 모델이 일반 Flan-PaLM-62B 모델보다 성능이 뛰어나고, 심볼 튜닝된 Flan-PaLM-62B 모델이 일반 Flan-PaLM-540B 모델보다 성능이 뛰어남
-
이 성능 차이는 심볼 튜닝이 더 작은 모델이 in-context example로부터 input-label mapping을 학습하는 데 큰 모델만큼 잘 수행할 수 있도록 도와줄 수 있음을 시사함
-
또한, 심볼 튜닝된 모델은 관련 레이블만 있거나 명령어만 있는 환경에서도 어느 정도 유사한 성능을 보여주었으나, 작은 모델에서는 성능이 과적합때문에 약간 감소하였음
5 Symbol tuning improves algorithmic reasoning
- 알고리즘적 추론 작업에서 더 뛰어난 성능을 보이며, 이는 심볼 튜닝이 자연어 데이터만 포함하고 수치적 또는 알고리즘적 데이터는 포함하지 않았음에도 불구하고 놀라운 결과를 냄
- 심볼 튜닝은 기호(foo, bar)들이 task와 전혀 관련이 없고 instruction도 제공되지 않기 때문에, 모델이 in-context 예시에서 input-label 매핑을 학습하도록 강제하게 설계됨
- 이러한 이유로, 심볼 튜닝은 모델이 자연어 input을 임의의 기호로 매핑하는 능력뿐만 아니라 알고리즘과 같은 형태의 입력-레이블 매핑을 학습하는 능력도 향상시킬 것이라고 가정!
- 따라서, BIG-Bench의 알고리즘적 추론 작업에 대해 실험을 수행함
- 먼저, 입력 리스트와 출력 리스트 사이의 변환 함수(예: 리스트에서 마지막 요소 제거)를 식별해야 하는 리스트 함수 작업을 실험했습니다. 이 작업들은 4개의 예시로 평가되었으며, 평가 설정은 동일하게 4가지 사용
- 또한, 바이너리 문자열을 사용해 입력을 출력으로 매핑하는 개념을 학습해야 하는 간단한 튜링 개념 작업에서도 모델을 테스트(예: 문자열에서 0과 1을 교환)
왜 이 알고리즘 평가방법을 사용할까?
1. 심볼 튜닝 작업은 이산적인 레이블(예: "긍정적", "부정적")을 사용하는 분류 문제임 -> 정해진 답을 고르는 문제인 반면, 알고리즘 작업은 개방적인 생성 문제
-> 따라서 정해진 답이 아닌, 모델이 규칙을 학습하여 스스로 출력을 생성해야 하는 작업
2. 또한 알고리즘 작업은 상식이나 특정 도메인 지식이 필요하지 않음 -> 심볼 튜닝 과정에서 모델이 자연어 데이터만을 사용해 학습했기 때문에, 이러한 알고리즘 작업은 모델이 단순히 학습한 지식이 아닌, 주어진 입력과 레이블 간의 패턴을 인식하는 능력을 테스트하기에 적합함
3. 알고리즘 작업은 모델이 다양한 작업 유형에 대해 일반화할 수 있는지를 테스트하는 데 유용하기 때문 -> 심볼 튜닝이 분류 문제에만 국한되지 않고, 더 복잡한 규칙 기반의 생성 작업에서도 잘 작동하는지 확인할 수 있음
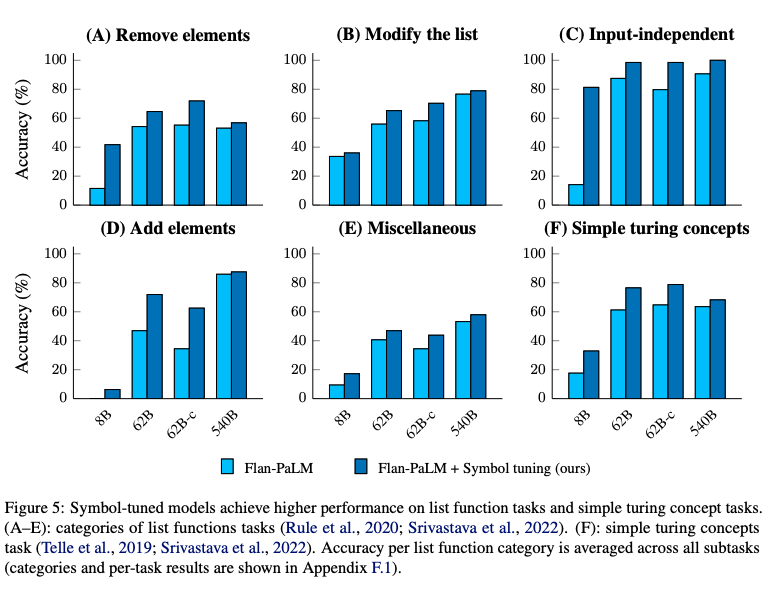
- 리스트 함수 작업: 20개의 리스트 함수 작업을 5개의 카테고리로 나누어 분석함 (A-E)
- 튜링 개념 작업: 바이너리 문자열을 다루는 간단한 튜링 개념 작업에서도 모델 성능이 향상되었습니다:
-> 심볼 튜닝이 알고리즘 데이터 없이도 모델의 in-context 능력을 크게 강화했음을 보여줌
6. Symbol-tuned models can override priors via flipped labels
- label이 뒤바뀐 입력을 사용한 실험을 진행했으며, 사전 학습된 언어 모델은 어느 정도 뒤바뀐 레이블을 따를 수 있는 능력이 있지만, 이 능력은 instruction tuning 중에 사라지는 문제점이 있었음 -> 하지만, 심볼 튜닝을 통해 다시 복원할 수 있음을 입증함!
-
pretrained LM이 뒤바뀐 label을 따를 수 있지만, instruction tuning을 하면 이 능력을 저하시킨다는것을 이전연구에서 보여줌
-
반면 심볼 튜닝은 모델이 in-context에서 제시된 label을 임의의 기호(foo, bar)로 간주하도록 강제하여, 뒤바뀐 label과 상충하는 사전 지식의 사용을 줄이도록 함
-
in-context 예시와 evaluation 예시 모두의 label을 뒤집음
- 예를 들어, SST2 데이터셋의 경우, "긍정적인" 감정으로 레이블된 모든 예시가 이제 "부정적인" 감정으로 labeling됨
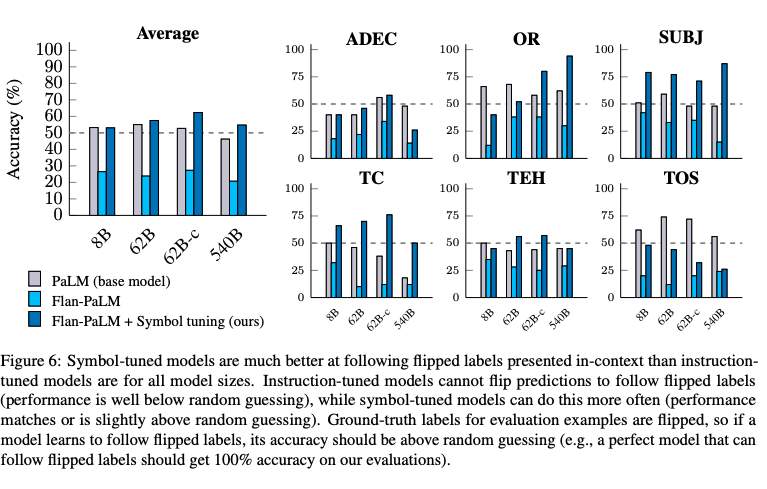
- 심볼 튜닝은 instruction tuning동안 없어진 뒤바뀐 label을 따르는 능력을 복원함
- 모든 모델 크기에서 유사한 경향을 확인할 수 있는데, instruction tuning된 모델은 뒤바뀐 레이블을 따를 수 없으며, 심볼 튜닝된 모델은 훨씬 더 잘 따를 수 있음
- 이 결과는 또 다른 유형의 일반화된 인컨텍스트 학습 능력을 나타내며, 심볼 튜닝 동안 뒤바뀐 label을 포함하지 않았음에도 불구하고 성과가 나타남
- 심볼 튜닝의 성능 향상은 크지만, 뒤바뀐 레이블 설정에서의 성능이 평균적으로 base model보다 크게 나아지지 않았으므로, 이 분야에서 더 많은 연구가 필요함
8. Limitation & Conclusion
- 생성 작업 적용의 어려움: 심볼 튜닝은 binary label을 가진 분류 작업에 적용되었지만, 생성 작업(예: 텍스트 생성)에서는 어떻게 기호로 매핑할지 명확하지 않기 때문에, 이러한 설정에 적용하는 방법이 필요함
- 데이터셋 확장: 22개의 NLP 데이터셋을 사용해 심볼 튜닝을 수행했지만, 더 많은 작업을 추가하는 실험은 진행하지 않음
- 모델의 다양한 설정: 심볼 튜닝은 instruction tuning된 모델에 적용했는데 , 모델 아키텍처, 학습 과정에 따라 심볼 튜닝의 효과가 달라질 수 있음
- 다른 언어 모델에 대한 적용: 심볼 튜닝을 Flan-PaLM 모델군에만 적용했기 때문에, 다른 언어 모델에도 효과적인지는 아직 명확하지 않음
- 심볼 튜닝을 통해 모델이 in-context learning에서 input-label 매핑을 학습하는 능력을 향상시키고, 더 나아가 symbol 기반으로 추론할 수 있는 언어 모델을 개선하는 연구를 촉진하려고 함.
