원본 huggingface link: https://huggingface.co/learn/nlp-course/chapter7/6?fw=pt
최근, OpenAI의 Codex 모델을 기반으로 한 TabNine 및 GitHub의 Copilot과 같은 도구 덕분에 코드를 생성하는 작업이 주목받고 있음 -> 이러한 텍스트 생성 작업은 auto-regressive or causal language models such as GPT-2 모델이 잘 처리함
This section we will build a scaled-down version of a code generation model!
이번 섹션에서는 코드 생성 모델의 축소판을 구축하는것이 목표!
Gathering the data
- 180GB의 GitHub 덤프, 약 2천만 개의 Python 파일을 포함하는 codeparrot을 사용하여 데이터셋
- 그러나 전체 코퍼스에서 훈련하는 것은 시간과 계산 자원이 많이 소모되기 때문에, codeparrot 데이터셋을 필터링함
- 데이터셋의 크기 때문에 다운로드를 피하고 스트리밍 기능을 사용하여 실시간으로 필터링
def any_keyword_in_string(string, keywords):
for keyword in keywords:
if keyword in string:
return True
return Falsefilters = ["pandas", "sklearn", "matplotlib", "seaborn"]
example_1 = "import numpy as np"
example_2 = "import pandas as pd"
print(
any_keyword_in_string(example_1, filters), any_keyword_in_string(example_2, filters)
)
## False True
- 이 함수는 문자열에 특정 키워드가 포함되어 있는지 확인하며, 첫 번째 예제에서는 키워드가 포함되지 않아 False를 반환하고, 두 번째 예제에서는 포함되어 True를 반환
- 이것을 사용하여 우리가 원하는 요소를 필터링하여 데이터셋을 스트리밍하는 함수를 만들 수 있음
def filter_streaming_dataset(dataset, filters):
# 필터링된 데이터를 저장할 기본 딕셔너리 생성
filtered_dict = defaultdict(list)
# 전체 샘플 수를 카운트할 변수 초기화
total = 0
for sample in tqdm(iter(dataset)):
# 전체 샘플 수 증가
total += 1
# sample의 "content"에 filters의 키워드가 포함되어 있는지 확인
if any_keyword_in_string(sample["content"], filters):
# 키워드가 포함된 경우, 해당 샘플의 모든 필드를 filtered_dict에 추가
for k, v in sample.items():
filtered_dict[k].append(v)
# 필터링 후 남은 데이터의 비율을 출력
print(f"{len(filtered_dict['content'])/total:.2%} of data after filtering.")
# 필터링된 데이터를 Dataset 객체로 변환하여 반환
return Dataset.from_dict(filtered_dict)그런 다음 이 함수를 스트리밍 데이터셋에 적용할 수 있음
from datasets import load_dataset
split = "train" # "valid"
filters = ["pandas", "sklearn", "matplotlib", "seaborn"]
data = load_dataset(f"transformersbook/codeparrot-{split}", split=split, streaming=True)
filtered_data = filter_streaming_dataset(data, filters)
## 3.26% of data after filtering.- 이로써 원본 데이터셋의 약 3%가 남게 되어 (6GB) 60만 개의 Python 스크립트로 구성됨!
- 이 긴 과정을 직접 거치고 싶지 않다면, Hub에서 제공하는 필터링된 데이터셋을 다운로드할 수 있음
from datasets import load_dataset, DatasetDict
ds_train = load_dataset("huggingface-course/codeparrot-ds-train", split="train")
ds_valid = load_dataset("huggingface-course/codeparrot-ds-valid", split="validation")
raw_datasets = DatasetDict(
{
"train": ds_train, # .shuffle().select(range(50000)),
"valid": ds_valid, # .shuffle().select(range(500))
}
)
raw_datasets
'''
DatasetDict({
train: Dataset({
features: ['repo_name', 'path', 'copies', 'size', 'content', 'license'],
num_rows: 606720
})
valid: Dataset({
features: ['repo_name', 'path', 'copies', 'size', 'content', 'license'],
num_rows: 3322
})
})
'''*언어 모델의 학습은 시간이 오래걸리기 때문에, 먼저 위의 주석 처리된 두 부분 라인의 주석을 해제하여 데이터의 일부 샘플로 학습 루프를 실행하고, 학습이 성공적으로 완료되고 모델이 저장되는지 확인하는 것이 좋음
for key in raw_datasets["train"][0]:
print(f"{key.upper()}: {raw_datasets['train'][0][key][:200]}")
'''
'REPO_NAME: kmike/scikit-learn'
'PATH: sklearn/utils/__init__.py'
'COPIES: 3'
'SIZE: 10094'
'''CONTENT: """
The :mod:`sklearn.utils` module includes various utilites.
"""
from collections import Sequence
import numpy as np
from scipy.sparse import issparse
import warnings
from .murmurhash import murm
LICENSE: bsd-3-clause'''
'''- content 필드에 우리 모델이 학습할 코드가 포함되어 있음을 확인함!
Preparing the dataset
- 첫 단계는 데이터를 토큰화: 데이터를 모델 훈련에 사용할 수 있는 형태로 변환
- context size 선택: 짧은 함수 호출 자동 완성이 목표이므로 작은 문맥 크기(128 토큰)를 선택하여 이는 훈련 속도를 높임
- context size: 모델이 한 번에 처리할 수 있는 토큰(단어나 부분 단어)의 최대 수
- 큰 context size: 더 긴 문맥 이해 가능, 더 많은 자원 필요
- 작은 context size: 제한된 문맥 이해, 적은 자원으로 빠른 처리 가능 - context size 보다 큰 문서: 큰 문서 단순히 자르는 대신 'return_overflowing_tokens' 옵션을 사용하여 전체 입력을 여러 청크로 나눔 -> 'return_length' 옵션으로 각 청크의 길이를 자동으로 확인
- 작은 문서: 문맥 크기보다 작은 마지막 청크는 제거하여 패딩 문제를 방지
from transformers import AutoTokenizer
context_length = 128
tokenizer = AutoTokenizer.from_pretrained("huggingface-course/code-search-net-tokenizer")
outputs = tokenizer(
raw_datasets["train"][:2]["content"], # 훈련 데이터셋의 처음 두 개 샘플의 내용을 가져옴
truncation=True, # 최대 길이를 초과하는 토큰을 자르기
max_length=context_length,
return_overflowing_tokens=True, # 최대 길이를 초과하는 토큰을 새로운 청크로 반환
return_length=True, # 각 청크의 길이를 반환
)
'''
# 총 34개의 입력 ID 시퀀스(청크)가 생성
Input IDs length: 34
Input chunk lengths: [128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 117, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 41]
# 각 청크가 원본 입력의 어느 샘플에서 왔는지 나타냄
Chunk mapping: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
'''- Dataset.map() 함수를 사용하여 큰 텍스트 문서를 여러 개의 작은, 일정한 크기의 샘플로 나누어 효율적으로 대규모 데이터를 처리함
def tokenize(element):
# 입력 텍스트를 토큰화하고 여러 청크로 나눔
outputs = tokenizer(
element["content"],
truncation=True,
max_length=context_length,
return_overflowing_tokens=True,
return_length=True,
)
input_batch = []
# 각 청크를 순회하면서 정확히 context_length와 일치하는 청크만 선택
for length, input_ids in zip(outputs["length"], outputs["input_ids"]):
if length == context_length:
input_batch.append(input_ids)
return {"input_ids": input_batch}
# 데이터셋의 모든 샘플에 tokenize 함수를 적용
tokenized_datasets = raw_datasets.map(
tokenize,
batched=True,
remove_columns=raw_datasets["train"].column_names
)
print(tokenized_datasets)
'''
DatasetDict({
train: Dataset({
features: ['input_ids'],
num_rows: 16702061
})
valid: Dataset({
features: ['input_ids'],
num_rows: 93164
})
})
'''Initializing a new model
- GPT-2 모델을 새로 초기화: 작은 GPT-2 모델을 사용하여 pre-trained된 구성을 로드하고, 토크나이저 크기가 모델의 어휘 크기와 일치하는지 확인한 다음, bos와 eos (시퀀스의 시작과 끝) 토큰 ID를 전달
from transformers import AutoTokenizer, GPT2LMHeadModel, AutoConfig
config = AutoConfig.from_pretrained(
"gpt2",
vocab_size=len(tokenizer),
n_ctx=context_length,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
)- 새로운 모델 로드: pre-trained()사용하지 않고!
- 1억 2400만 개의 파라미터를 가짐
model = GPT2LMHeadModel(config)
model_size = sum(t.numel() for t in model.parameters())
print(f"GPT-2 size: {model_size/1000**2:.1f}M parameters")
# GPT-2 size: 124.2M parameters
- 학습을 시작하기 전에, 배치를 생성할 데이터 콜레이터를 설정: DataCollatorForLanguageModeling
- 언어 모델링을 위해 특별히 설계됨: 인과적 언어 모델링에서는 입력이 레이블 역할도 하기 때문에, 데이터 콜레이터는 학습 중에 이를 즉석에서 생성하므로 input_ids를 복제하여 준비할 필요 없음!
- DataCollatorForLanguageModeling은 마스크 언어 모델링(MLM)과 인과적 언어 모델링(CLM) 모두를 지원하며, 기본적으로 MLM용 데이터를 준비하지만, mlm=False 인자를 설정하여 CLM으로 전환할 수 있음
from transformers import DataCollatorForLanguageModeling
tokenizer.pad_token = tokenizer.eos_token # 패딩 토큰을 문장 끝(EOS) 토큰과 동일하게 설정함
data_collator = DataCollatorForLanguageModeling(tokenizer, mlm=False) # mlm=False로 설정하여 인과적 언어 모델링함 (CLM)
out = data_collator([tokenized_datasets["train"][i] for i in range(5)]) # 훈련 데이터셋에서 처음 5개의 샘플을 선택
for key in out:
print(f"{key} shape: {out[key].shape}")
'''
input_ids shape: torch.Size([5, 128])
attention_mask shape: torch.Size([5, 128])
labels shape: torch.Size([5, 128])
'''- 모든 준비는 끝!!
- Trainer를 실행해야함: warm_up이 있는 코사인 학습률 스케줄을 사용하고 배치 크기를 256으로 설정할 것 (per_device_train_batch_size * gradient_accumulation_steps)
- 그래디언트 누적은 단일 배치가 메모리에 맞지 않을 때 사용되며, 여러 번의 순전파/역전파를 통해 점진적으로 그래디언트를 구축
from transformers import Trainer, TrainingArguments
args = TrainingArguments(
output_dir="codeparrot-ds",
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
evaluation_strategy="steps",
eval_steps=5_000,
logging_steps=5_000,
gradient_accumulation_steps=8,
num_train_epochs=1,
weight_decay=0.1,
warmup_steps=1_000,
lr_scheduler_type="cosine",
learning_rate=5e-4,
save_steps=5_000,
fp16=True,
push_to_hub=True,
)
trainer = Trainer(
model=model,
tokenizer=tokenizer,
args=args,
data_collator=data_collator,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["valid"],
)
trainer.train()Code generation with a pipeline
- pipeline 라이브러리를 사용하여 모델을 GPU에 장착해보기
import torch
from transformers import pipeline
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
pipe = pipeline(
"text-generation", model="huggingface-course/codeparrot-ds", device=device
)- generate code 1) scatter plot먼저 만들어보자!
txt = """\
# create some data
x = np.random.randn(100)
y = np.random.randn(100)
# create scatter plot with x, y
"""
print(pipe(txt, num_return_sequences=1)[0]["generated_text"])- 1) 결과
# create some data
x = np.random.randn(100)
y = np.random.randn(100)
# create scatter plot with x, y
plt.scatter(x, y)
# create scatter- generate code 2) 두 배열로 DataFrame을 생성
txt = """\
# create some data
x = np.random.randn(100)
y = np.random.randn(100)
# create dataframe from x and y
"""
print(pipe(txt, num_return_sequences=1)[0]["generated_text"])- 2) 결과 (생성된 토큰 수가 제한되어 있어서 for 루프가 잘림)
# create some data
x = np.random.randn(100)
y = np.random.randn(100)
# create dataframe from x and y
df = pd.DataFrame({'x': x, 'y': y})
df.insert(0,'x', x)
for- generate code 3) 좀 더 복잡한 groupby 연산
txt = """\
# dataframe with profession, income and name
df = pd.DataFrame({'profession': x, 'income':y, 'name': z})
# calculate the mean income per profession
"""
print(pipe(txt, num_return_sequences=1)[0]["generated_text"])- 3) 결과
# dataframe with profession, income and name
df = pd.DataFrame({'profession': x, 'income':y, 'name': z})
# calculate the mean income per profession
profession = df.groupby(['profession']).mean()
# compute the- generate code 4) scikit-learn을 사용하여 랜덤 포레스트 모델
txt = """
# import random forest regressor from scikit-learn
from sklearn.ensemble import RandomForestRegressor
# fit random forest model with 300 estimators on X, y:
"""
print(pipe(txt, num_return_sequences=1)[0]["generated_text"])- 4) 결과
# import random forest regressor from scikit-learn
from sklearn.ensemble import RandomForestRegressor
# fit random forest model with 300 estimators on X, y:
rf = RandomForestRegressor(n_estimators=300, random_state=random_state, max_depth=3)
rf.fit(X, y)
rfTraining with 🤗 Accelerate
- Trainer()를 사용하지 않고 train loop를 제어하는 방식: 🤗 Accelerate
🤗 Accelerate
🤗 Accelerate는 분산 설정에서 추론을 쉽게 훈련하거나 실행할 수 있도록 설계된 라이브러리입니다. 분산 환경 설정 프로세스를 간소화하여 PyTorch 코드에 집중할 수 있도록 해줍니다.
- 이 태스크는 코드를 generation하는 것 이므로, 데이터과학에 많이 사용되는 코드에 더 많은 가중치를 부여하는 것이 합리적임!
- 빈번하게 사용되는 keyword만 추려보자
keytoken_ids = []
for keyword in [
"plt",
"pd",
"sk",
"fit",
"predict",
" plt",
" pd",
" sk",
" fit",
" predict",
"testtest",
]:
ids = tokenizer([keyword]).input_ids[0]
if len(ids) == 1:
keytoken_ids.append(ids[0])
else:
print(f"Keyword has not single token: {keyword}")
# 'Keyword has not single token: testtest'- logit과 input:
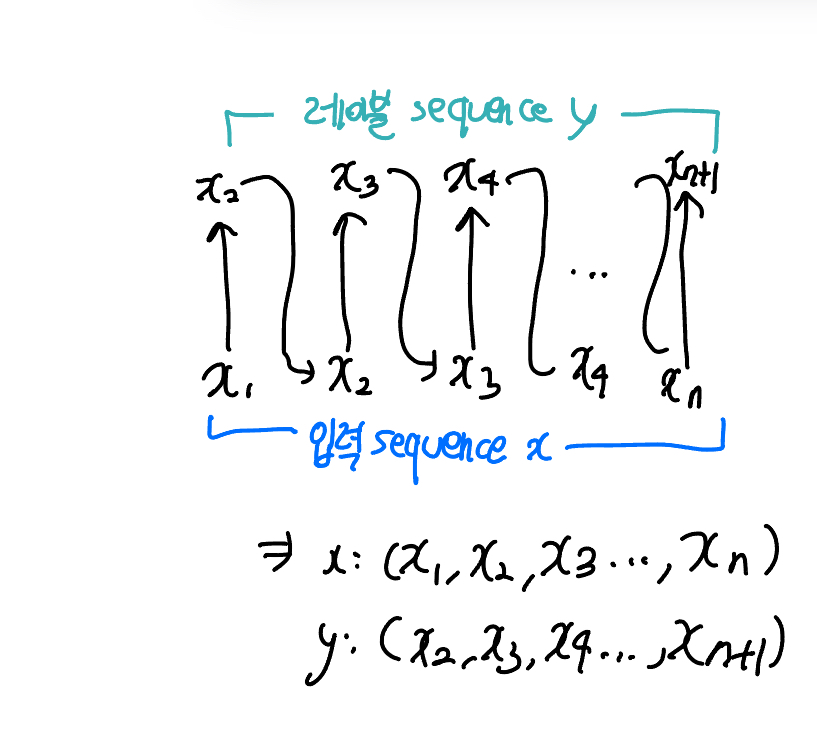
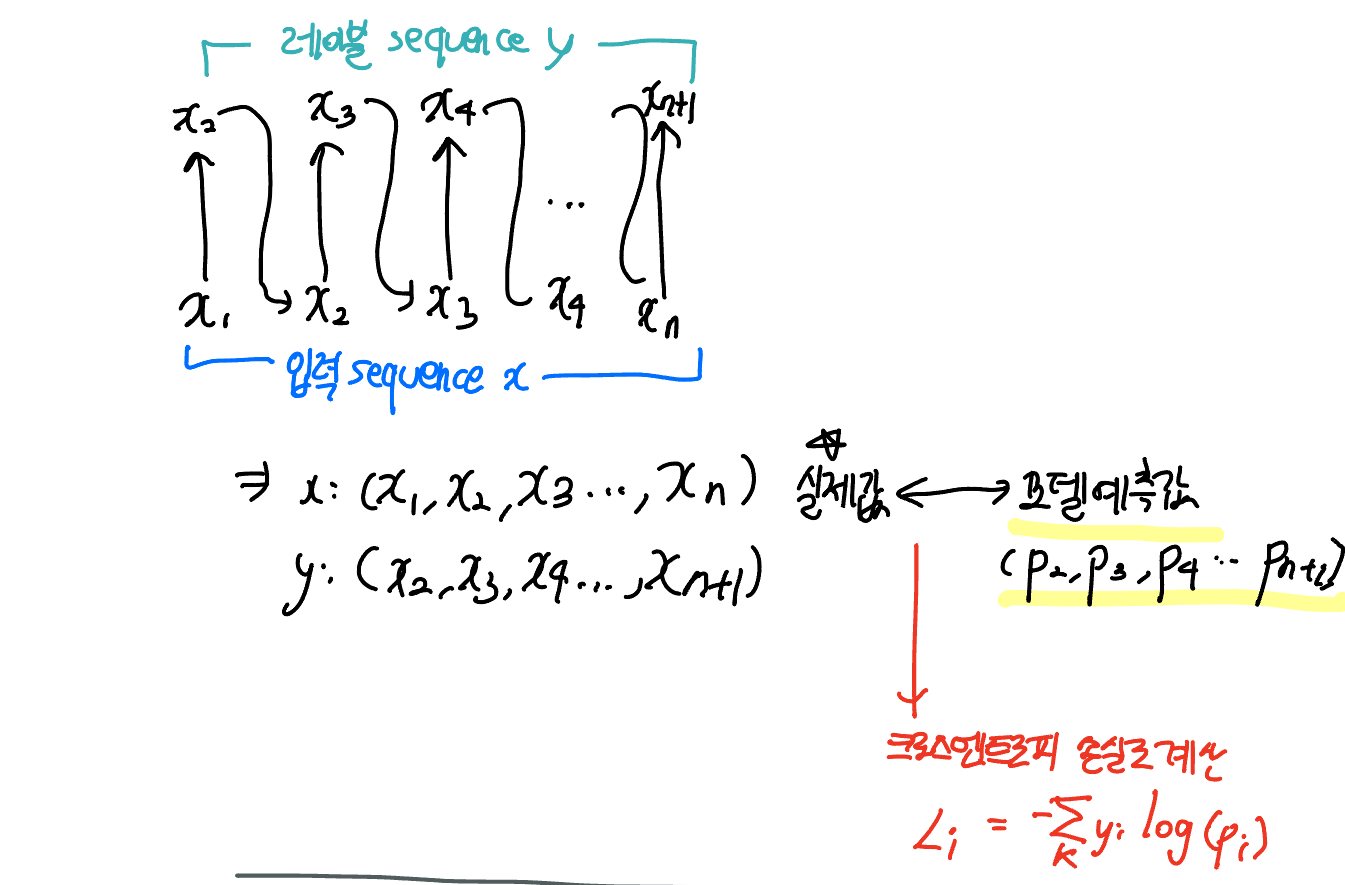
- 모델이 다음 토큰을 예측할 때, 현재 토큰을 기반으로 함. 따라서 예측할 토큰(레이블)은 입력 시퀀스를 하나 오른쪽으로 이동시켜 얻을 수 있음!
- 예를 들어, 입력 시퀀스가 [A, B, C]라면, 레이블 시퀀스는 [B, C]
- 마찬가지로, 모델이 생성하는 예측 값(logit)도 마지막 예측 값은 필요 없으므로 자름 - loss 계산:
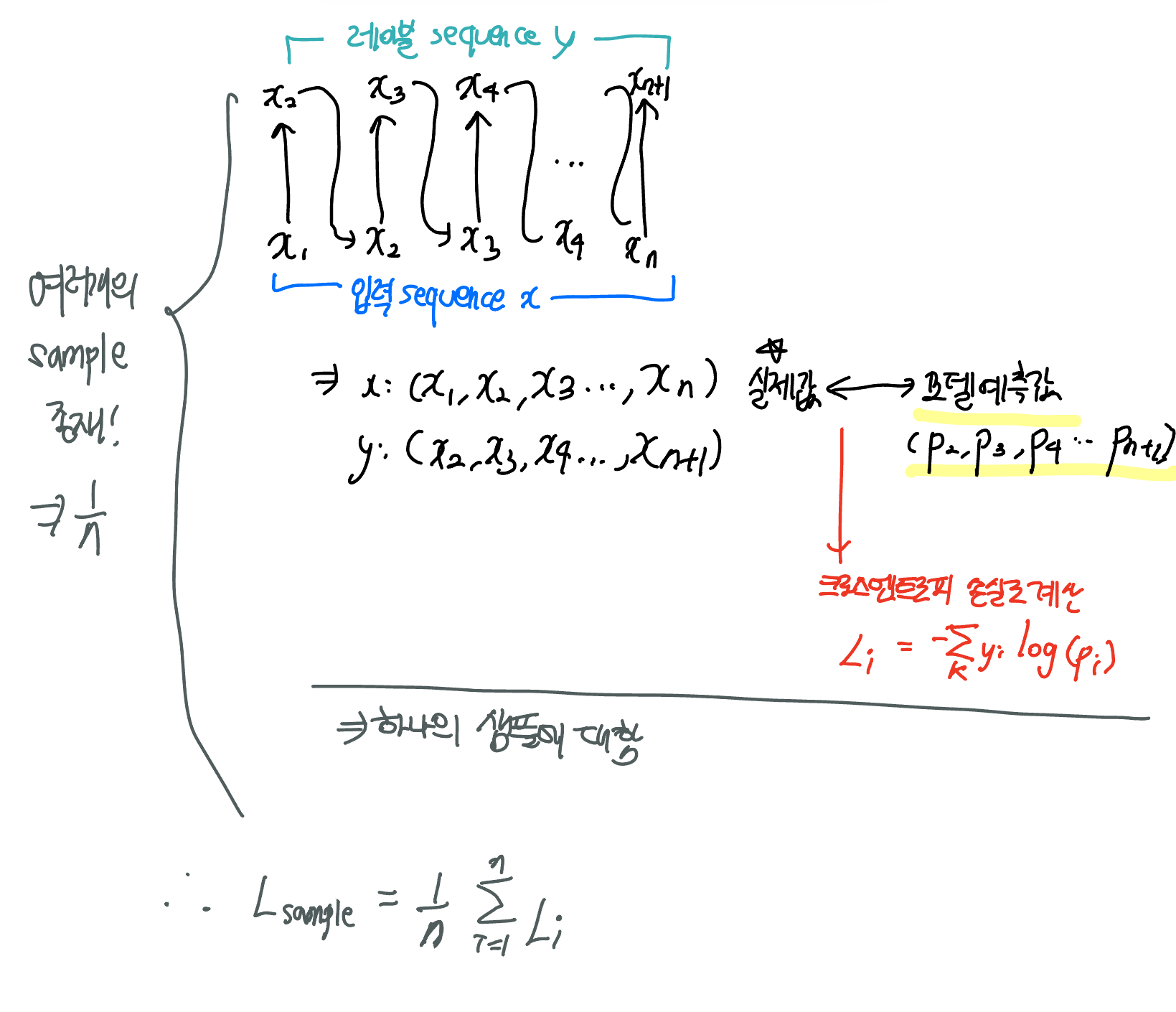
- 각 토큰에 대해 손실을 계산하며 이는 모델의 예측 값(로짓)과 실제 값(레이블) 간의 차이를 측정
- 각 샘플에 대해 평균 손실을 계산 - 키워드 발생 횟수 세기:
- 각 샘플에서 특정 키워드(예: plt, pd, fit, predict)가 얼마나 자주 등장하는지 세기
- 이러한 키워드는 데이터 과학 라이브러리에서 자주 사용되므로 모델이 잘 예측하도록 하고싶기 때문 - 가중치 계산 및 적용:
- 키워드가 많이 포함된 샘플에 더 큰 가중치를 주어, 모델이 이러한 샘플을 더 중요하게 학습하도록 함- 키워드가 하나도 포함되지 않은 샘플을 완전히 무시하지 않기 위해 모든 샘플의 가중치에 1을 더함
from torch.nn import CrossEntropyLoss
import torch
def keytoken_weighted_loss(inputs, logits, keytoken_ids, alpha=1.0):
# 입력 시퀀스를 오른쪽으로 하나 이동하여 레이블 생성 (처음 토큰은 제거)
shift_labels = inputs[..., 1:].contiguous()
# 마지막 예측 값(로짓)을 제거하여 정렬
shift_logits = logits[..., :-1, :].contiguous()
# 각 토큰에 대한 손실 계산
loss_fct = CrossEntropyLoss(reduce=False)
# 손실을 1차원 배열로 변환하여 계산
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
# 손실을 샘플별로 다시 크기를 조정하고 평균 계산
loss_per_sample = loss.view(shift_logits.size(0), shift_logits.size(1)).mean(axis=1)
# 키워드 발생 횟수 계산 및 스케일 조정
weights = torch.stack([(inputs == kt).float() for kt in keytoken_ids]).sum(axis=[0, 2])
weights = alpha * (1.0 + weights)
# 가중 평균 손실 계산
weighted_loss = (loss_per_sample * weights).mean()
return weighted_loss


- 이 멋진 새로운 손실 함수로 훈련을 시작하기 전에 몇 가지 준비가 필요함:
- 데이터를 배치로 로드하기 위한 데이터로더가 필요
- 가중치 감쇠(weight decay) 매개변수를 설정
from torch.utils.data.dataloader import DataLoader
# 데이터셋 형식을 "torch"로 설정
tokenized_dataset.set_format("torch")
# 훈련 데이터로더 설정
train_dataloader = DataLoader(tokenized_dataset["train"], batch_size=32, shuffle=True)
# 평가 데이터로더 설정
eval_dataloader = DataLoader(tokenized_dataset["valid"], batch_size=32)- 학습률 스케줄러 설정, 에폭 및 스텝 수 설정
from transformers import get_scheduler
# 훈련 에폭 수 설정
num_train_epochs = 1
# 에폭당 업데이트 스텝 수
num_update_steps_per_epoch = len(train_dataloader)
# 총 훈련 스텝 수
num_training_steps = num_train_epochs * num_update_steps_per_epoch
# 선형 학습률 스케줄러 설정
lr_scheduler = get_scheduler(
name="linear",
optimizer=optimizer,
num_warmup_steps=1_000,
num_training_steps=num_training_steps,
)
- accelerator를 활용한 train loop
from tqdm.notebook import tqdm # 진행률 표시줄 라이브러리
# 그라디언트 누적 단계 수 설정
gradient_accumulation_steps = 8
# 평가를 수행할 스텝 간격 설정
eval_steps = 5_000
# 모델을 훈련 모드로 설정
model.train()
completed_steps = 0 # 완료된 스텝 수 초기화
# 훈련 에폭 반복
for epoch in range(num_train_epochs):
# 훈련 데이터로더 반복
for step, batch in tqdm(enumerate(train_dataloader, start=1), total=num_training_steps):
# 배치에서 입력 아이디를 모델에 전달하여 로짓(logits) 계산
logits = model(batch["input_ids"]).logits
# 사용자 정의 손실 함수로 손실 계산
loss = keytoken_weighted_loss(batch["input_ids"], logits, keytoken_ids)
# 100 스텝마다 훈련 손실 출력
if step % 100 == 0:
accelerator.print({
"samples": step * samples_per_step,
"steps": completed_steps,
"loss/train": loss.item() * gradient_accumulation_steps,
})
# 그라디언트 누적 단계 수로 손실을 나누어 스케일 조정
loss = loss / gradient_accumulation_steps
# 손실을 통해 역전파 수행
accelerator.backward(loss)
# 그라디언트 누적 단계 수마다 최적화 수행
if step % gradient_accumulation_steps == 0:
# 그라디언트 클리핑 수행 (최대값 1.0)
accelerator.clip_grad_norm_(model.parameters(), 1.0)
# 옵티마이저 스텝 수행
optimizer.step()
# 학습률 스케줄러 스텝 수행
lr_scheduler.step()
# 그라디언트 초기화
optimizer.zero_grad()
# 완료된 스텝 수 증가
completed_steps += 1
# 평가를 수행할 스텝마다 모델 평가
if (step % (eval_steps * gradient_accumulation_steps)) == 0:
# 평가 함수 호출하여 평가 손실과 퍼플렉서티 계산
eval_loss, perplexity = evaluate()
# 평가 손실과 퍼플렉서티 출력
accelerator.print({"loss/eval": eval_loss, "perplexity": perplexity})
# 모델을 다시 훈련 모드로 설정
model.train()
# 모든 프로세스가 동기화되도록 대기
accelerator.wait_for_everyone()
# 모델을 언랩하여 저장
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
# 메인 프로세스에서 토크나이저 저장
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
# 중간 훈련 상태를 커밋하여 저장소에 푸시
repo.push_to_hub(commit_message=f"Training in progress step {step}", blocking=False)
멋져요