Abstract
SOTA 문장 임베딩을 크게 발전시키는 간단한 contrastive learning framework인 SimCSE를 제시
먼저 입력 문장을 받고 standard dropout만 noise로 사용하여 contrastive objective로 스스로를 예측하는 unsupervised 접근법을 설명함
dropout이 최소한의 data augmentation으로 작용하고, 이를 제거하면 representation collapse가 됨
그리고, 자연어 inference dataset의 주석을 사용("entailment" pair를 긍정으로, "contradiction" pair를 hard 부정)해서 contrastive learning framework에 통합하는 supervised learning을 제안
-> 따라서 standard semantic textual similarity (STS) task에 대해 SimCSE를 평가하며, BERTbase를 사용한 supervised and unsupervised model은 이전에 비해 향상됨
-> 또한 이론적으로나 경험적으로 contrastive learning object가 ore0trained embedding의 이방성 공간을 보다 균일하게 정규화하고 supervised signal을 사용할 수 있을때 양성 쌍을 더 잘 정렬한다는 것을 보여줌
1 Introduction
보편적인 문장 embedding을 배우는 것은 자연어 처리의 근본적인 문제임
따라서, 본 연구에서는 SOTA 문장 임베딩 방법을 발전시키고 BERT또는 RoBERTa와 같은 pre-trained LM과 결합할때 constrative object가 매우 효과적일 수 있음을 보여줌
-> label이 지정되거나 지정되지 않은 data에서 우수한 sentence embedding을 생성할 수 있는 간단한 constrative senetence embedding framework인 SimCSE를 제시
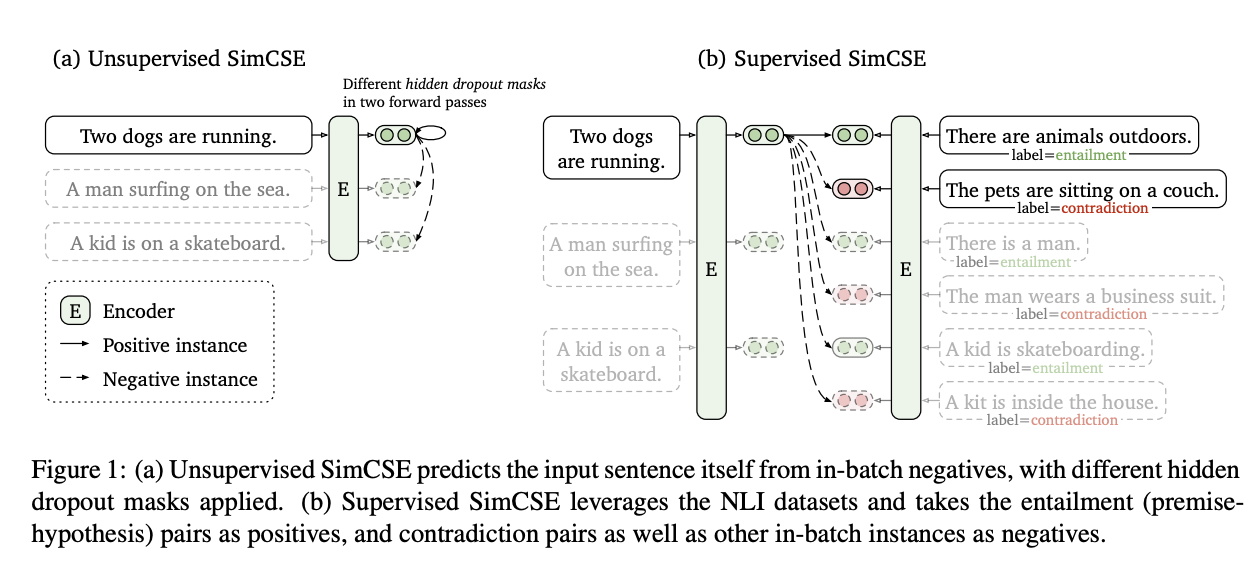
unsupervised SimCSE는 noise로 사용되는 dropout만으로 입력문장 자체를 예측함 == 같은 문장을 supervised encoder에 두번 전달
-> dropout을 두번 적용하면 positive pair으로 두개의 서로다른 embedding을 얻을 수 있음
그런 다음 "negative"과 동일한 Mini-batch의 다른 문장을 갖고 부정 중 긍정적인 문장을 예측함
-> dropout이 숨겨진 representation의 최소한의 data augmentation의 역할을 하는 동시에 이것을 제거하면 representation collapse가 일어남
supervised SimCSE는 문장 임베딩에 자연어 추론(NLI) dataset를 사용하는 것을 기반으로 구축되며, 주석이 달린 pair를 constrative learning에 통합함
3개로 분류하는 이전 작업과 달리, entailment pair가 긍정적 instance로 사용된다는 것을 활용함
또한, 해당되는 contradiction pair을 hard negative로 추가하면 성능이 더욱 향상된다는 것을 발견함
경험적 분석을 통해, unsupervised SimCSE가 본질적으로 균일성을 향상시키는 동시에 dropout noise를 통해 degenerated alignment를 방지하여 representation의 expressiveness를 향상시킨다는 것을 발견함
또한 pre-trained word embedding이 이방성을 겪는다는 최근 연구 결과와 연관성을 도출하고 스펙트럼 관점을 통해 constrative objective learning이 sentence embedding 공간의 단일 값 분포를 "평탄화"하여 균일성을 향상시킨다는 것을 증명함
우리는 7개의 STS 작업과 7개의 transfer task에 대해 SimCSE에 대한 포괄적인 평가를 수행하고 SOTA를 달성
2 Background
- contrastive learning: 의미적으로 가까운 이웃은 가깝게, 먼 이웃은 멀게!
- pair 구성이 중요함
alignment: positive pair 사이의 feature가 얼마나 가까운지
Uniformity: 공간상의 feature distribution
3 Unsupervised SimCSE
dropout noise as data augmentation
4 Supervised SimCSE
entailment, contradiction으로 pos,neg pair 구성
5 Connection to Anisotropy
Isotropy <-> Anisotropy
sentence embedding 은 서로 흩어져야 잘 됨
