
0. 들어가기 전에
사실 엄연히 말하자면 웹 스크래핑에 가까운 기능이지만, 대부분 크롤링이라고 퉁치기에 크롤링이라는 단어로 포스팅을 할 예정이다.
간단한 크롤링으로 정보를 긁어오는 명령어를 만들어 보자.
0-1. robots.txt
robots.txt는 웹 사이트가 크롤러들의 접근을 제한하는 규약이다. 의무는 아니지만, 가능하면 robots.txt의 규칙을 지키며 크롤링하자. 웹사이트 주소/robots.txt 에서 확인 가능하다.
예시로 naver의 robots.txt를 보자.
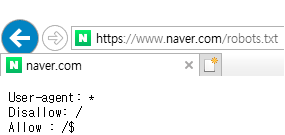
원칙적으로는 모든 크롤러에 대하여 첫 페이지만 크롤링이 가능하다고 표시되어 있다.
아래는 구글의 robots.txt 소개 페이지이다.
https://developers.google.com/search/docs/advanced/robots/intro?hl=ko
1. 패키지 설치
pip install bs4
pip install lxml
터미널에 위의 구문을 입력해 크롤링을 위한 패키지를 설치해주자.
(parser library로 html.parser 대신 lxml을 쓸 텐데 둘의 차이점은 아래와 같다.)
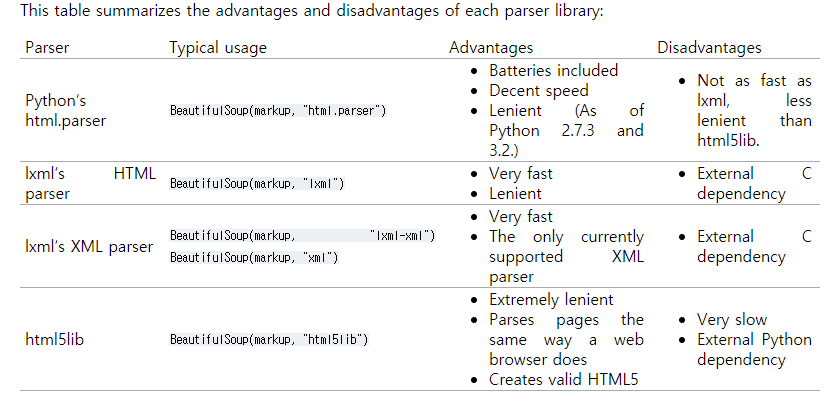
2. 크롤링 해보기
국내 코로나 확진자 수를 공식 홈페이지에서 크롤링(스크래핑)해보겠다. 먼저 robots.txt를 살펴보자.
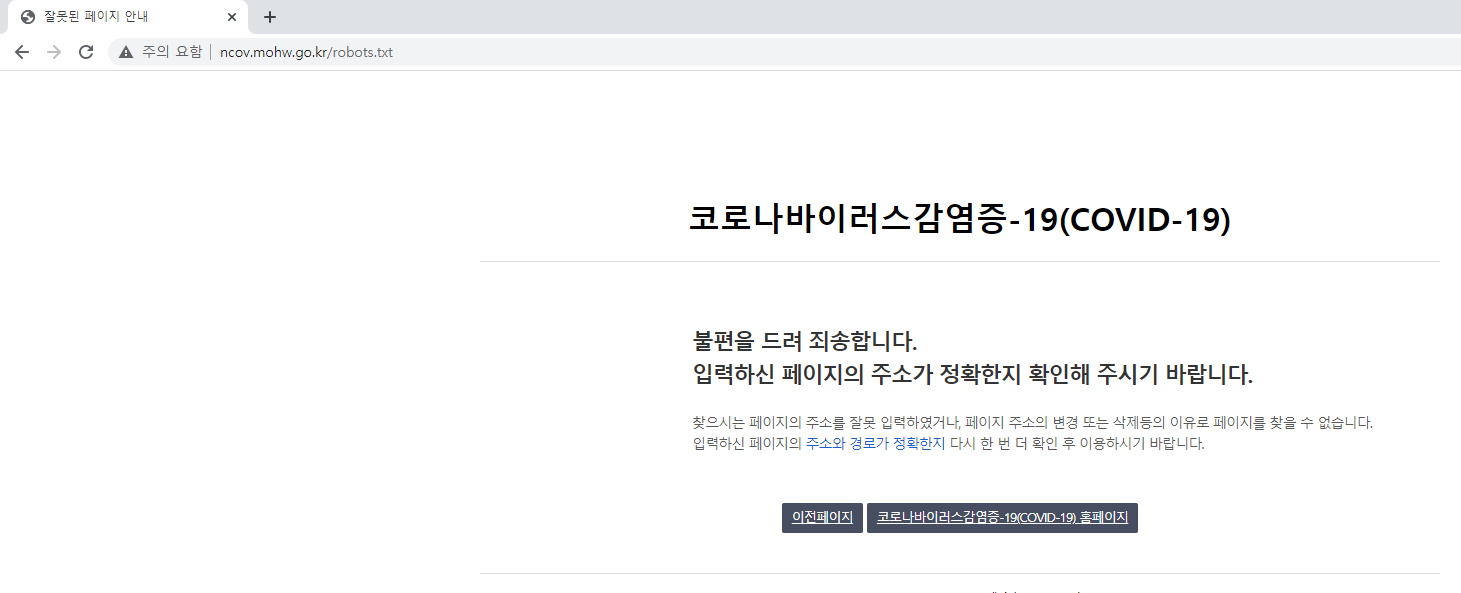
홈페이지에서 확진자 수가 있는 element를 찾아보자.
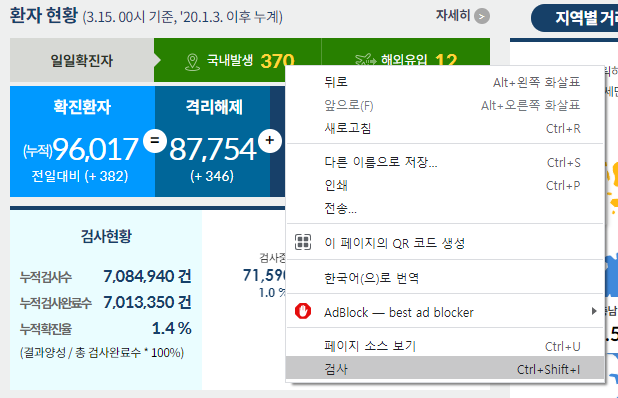
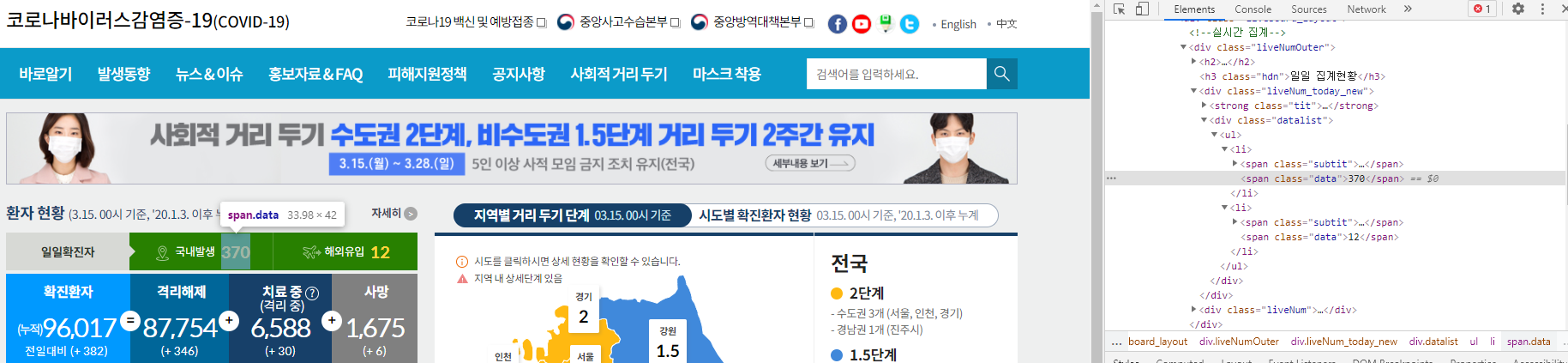
위의 정보로 아래 코드를 작성해 확진자 수를 크롤링 해보자.
import discord
import requests
from bs4 import BeautifulSoup
@bot.command(aliases=['코로나']) # !코로나 입력 시에도 실행 가능
async def crawl(ctx):
url = "http://ncov.mohw.go.kr/"
response = requests.get(url) # get 방식으로 웹 정보 받아오기
response_code = int(response.status_code) # 응답 코드 받기
if response_code == 200: # 정상 작동(코드 200 반환) 시
soup = BeautifulSoup(response.content, 'lxml')
else: # 오류 발생
await ctx.send("웹 페이지 오류입니다.")
# element 찾기
# soup.find ()로 <div class="liveNum_today_new"> 에서 확진자 수 데이터가 들어 있는 <span class="data"> 리스트 가져오기
today = soup.find("div", {"class": "liveNum_today_new"}).findAll("span", {"class": "data"})
today_domestic = int(today[0].text) # 리스트 첫 번째 요소 (국내발생)
today_overseas = int(today[1].text) # 리스트 두 번째 요소 (해외유입)
accumulate_confirmed = soup.find("div", {"class": "liveNum"}).find("span", {"class": "num"}).text[4:] # 앞에 (누적) 글자 자르기
embed = discord.Embed(title="국내 코로나 확진자 수 현황", description="http://ncov.mohw.go.kr/ 의 정보를 가져옵니다.", color=0x005666)
embed.add_field(name="일일 확진자",
value=f"총: {today_domestic + today_overseas}, 국내: {today_domestic}, 해외유입: {today_overseas}",
inline=False)
embed.add_field(name="누적 확진자", value=f"{accumulate_confirmed}명", inline=False)
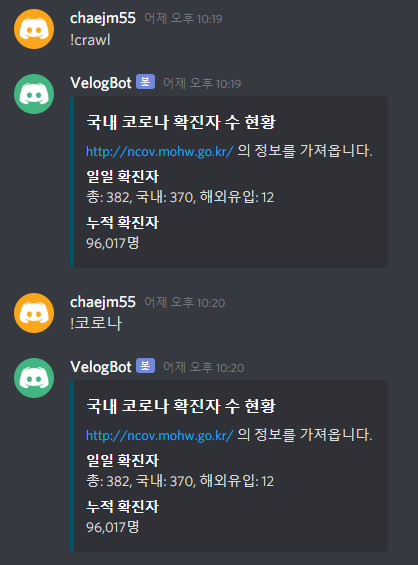
await ctx.send(embed=embed)실행결과는 다음과 같다. aliases를 사용하여 !코로나 로도 실행이 가능하다.
또는 css selector로 할 수도 있다.
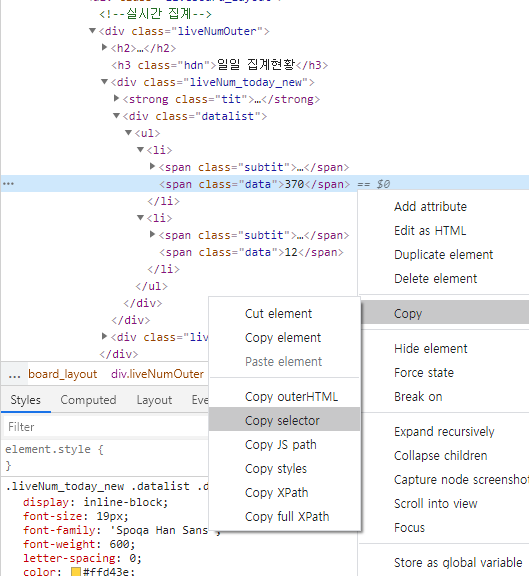
아래 코드 처럼 나머지를 크롤링 해도 된다.
today_domestic = int(soup.select("body > div > div.mainlive_container > div.container > div > div.liveboard_layout > div.liveNumOuter > div.liveNum_today_new > div > ul > li:nth-child(1) > span.data"))3. 발생할 법할 에러
1) RequestException
requests.exceptions.RequestException에 정의된 exception 들이다.
- HTTPError: 잘못된 HTTP status 반환 시
- Timeout: 요청이 시간 초과 되었을 시
- ConnectionError: 네트워크 문제 발생 시
- TooManyRedirects: 최대 redirect 횟수 초과 시
공식문서: https://requests.readthedocs.io/en/latest/user/quickstart/#errors-and-exceptions
2) AttribteError

받아온 데이터가 없을때 soup.find()를 사용하거나 soup.find().find() 사용 시 이전 데이터가 없다면 None에 find()를 사용하기에 error가 발생한다. 태그를 다시 한 번 확인해보자.
4. 마무리
간단하게 크롤링(스크래핑)하는 명령어를 만들어봤다. 크롤링하는 코드는 특히 웹페이지가 변할 때마다 작동하지 않을 수 있으므로 지속적인 유지보수가 필요하다.
time.sleep(259200)
