

📌 시스템 생명 주기
요구사항 → 분석 → 설계 → 정제와 코딩 → 검증
요구사항
프로젝트의 목적을 정의한 명세들의 집합
입력과 출력에 관한 정보 기술
분석
문제들을 다룰 수 있는 작은 단위들로 나눔
상향식 bottom up / 하향식 top down
설계
추상 데이터 타입 생성
알고리즘 명세와 설계 기법 고려
정제와 코딩
데이터 객체에 대한 표현 선택
수행되는 연산에 대한 알고리즘 작성
검증
정확성 증명 - 수학적 기법 이용
테스트 - 프로그램의 정확한 수행 검증, 성능 검사
오류 제거 - 독립적 단위로 테스트 후 전체 시스템으로 통합
📌 객체 지향 설계
구조적 프로그래밍 설계와 비교하면 분할-정복 기법을 사용한다는 점이 유사함 → 복잡한 문제를 여러개의 단순한 부분 작업으로 나눠 각각을 개별적으로 해결
차이점은 과제 분할 방식
- 알고리즘적 분해(함수적 분해) 고전적 프로그래밍 기법으로 소프트웨어를 기능적 모듈로 분해함 ex) C의 함수
- 객체 지향적 분해 응용 분야의 객체를 모델링하는 객체의 집합 소프트웨어의 재사용성을 조장 변화에 유연한 소프트웨어 시스템 직관적
+) 객체 지향 4대 요소
- 캡슐화 : 정보가 밖에서 안보이게 은닉하는 것
- public, protected, 디폴트, private : 접근지정자 → 접근 가능 범위 지정
- 상속 : ex) 남자클래스는 사람클래스 상속받음
- extends
- 다형성 : 같은 메소드로 다른 결과 ex) 연산자 오버로딩 : 같은 연산자인데 피연산자가 다르면 다른 역할
- overloading, overriding
- 추상화 : 객체의 명세와 구현을 분리한 것. 추상화의 정도가 큰 것이 좋은것
- interface, abstract
API (Application Programming Interface) : 시스템을 이용하기 위한 명령어들을 미리 만들어 놓은 것
📌 객체 지향 프로그래밍
객체 : 계산을 수행하고 상태를 갖는 개체. 데이터 + 절차적 요소
객체 지향 프로그래밍 : 객체는 기본적인 구성 단위로 타입(클래스)의 인스턴스임.
클래스는 공통된 속성과 동작을 공유하는 객체들의 그룹.
클래스끼리는 상속으로 연관됨
디자인 패턴 : 특정상황에서 공통적으로 발생하는 문제에 대해 재사용 가능한 해결책들을 모은 것
객체 지향 언어 : 객체 지원. 모든 객체는 클래스에 속함. 상속 지원
객체 기반 언어 : 객체와 클래스 지원. 상속 미지원
📌 데이터 추상화와 캡슐화
데이터 추상화 : 객체의 명세와 구현을 분리
데이터 캡슐화 : 정보가 외부에서 안보이게 은닉하는 것 → 접근지정자 : public, private 등…
추상 데이터 타입 ADT : 객체와 연산에 대한 명세가 객체의 표현과 연산의 구현으로부터 분리된 방식으로 구성된 데이터 타입 → 즉 클래스에서 명세와 구현을 분리한 것
데이터 추상화와 캡슐화의 장점
- 소프트웨어 개발의 간소화 : 복잡한 작업을 부분 작업들로 분해
- 테스트와 디버깅 : 각 부분 작업을 독자적 테스트, 디버깅
- 재사용성 : 자료구조에 대한 코드와 연산을 추출해서 다른 소프트웨어 시스템에서도 사용
- 데이터 타입 표현에 대한 수정 : 데이터 타입의 내부 구현에 직접 접근하는 연산들만 수정
📌 C++ 기초
프로그램의 실행 : 컴파일 → 링크 → 적재
scope 영역 : 파일 영역 / 네임스페이스 영역 / 지역 영역 - 블록 안에서 선언 / 클래스 영역 - 클래스 정의 관련
포인터 : 객체의 메모리 주소 저장
레퍼런스 타입 : 객체에 대한 또 다른 이름을 제공
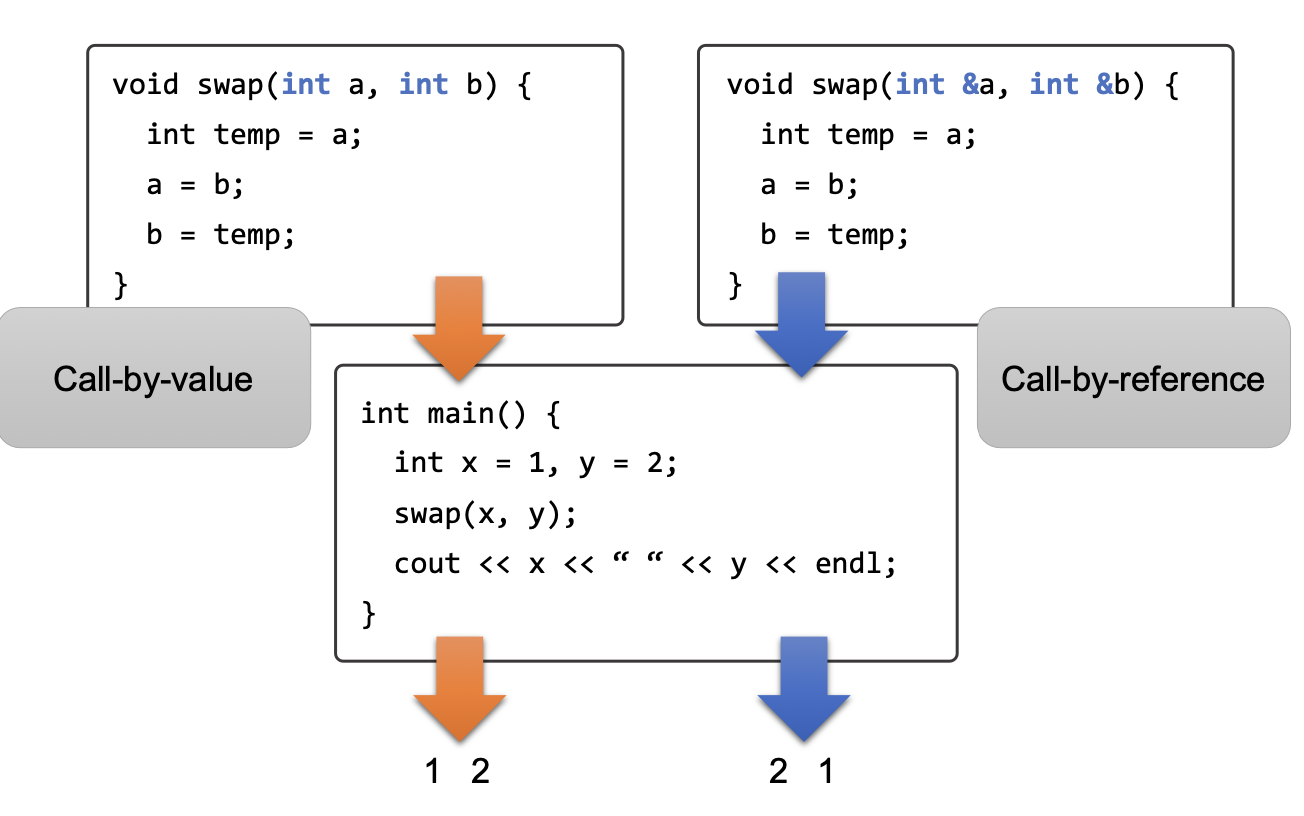
- Call by value : 매개변수로 값만 넘겨줌
- Call by reference : 매개변수로 주소값을 넘겨줌
동적 메모리 할당
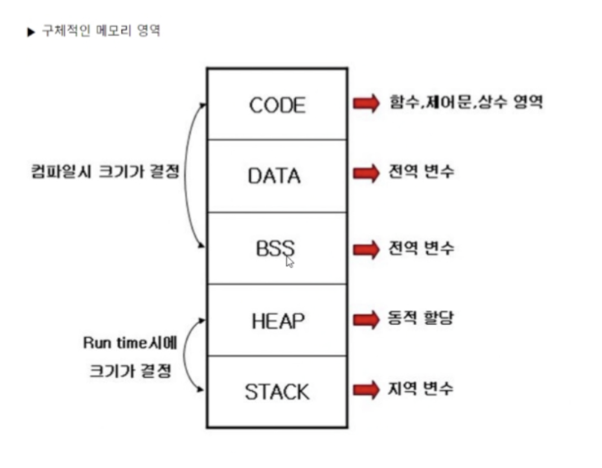
- 정적 static : 컴파일 타임 → 프로그램 시작 전
- 동적 dynamic : 런타임 → 프로그램 실행 중
code(=text) 영역은 실행파일이 올라가는 영역
data 영역은 초기화 된 전역/정적 변수
bss 영역은 초기화 안된 전역/정적 변수
heap에는 동적 메모리 할당
stack에는 시스템 스택이 쌓임 (main → activation record → ….)
📌 알고리즘
알고리즘 : 특정 작업을 수행하는 명령어들의 유한 집합
알고리즘의 요건
- 입력 : 외부에서 제공되는 데이터가 0개 이상
- 출력 : 적어도 한개 이상의 결과 생성
- 명확성 : 명령이 명확하고 모호하지 않아야함
- 유한성 : 어떤경우에도 반드시 종료
- 유효성 : 반드시 실행 가능
알고리즘 기술 방법은 자연어, flowchart, pseudocode, c언어 등등이 존재
📌 선택 정렬, 이원 탐색, 순환 알고리즘
선택 정렬

n ≥ 1개의 서로 다른 정수들의 집합을 정렬하는 알고리즘
정렬되지 않은 정수들중 가장 작은 값을 찾아서 정렬된 리스트 다음 자리에 놓는 방법
즉, 리스트를 전체 다 탐색하여 가장 작은 것을 맨앞으로 가져오는 것을 반복하며 앞에서부터 확정시켜나가는 방식
Binary search 이원 탐색
이미 정렬된 배열에서 어떤 값을 찾을때 사용하는 방법
배열을 반복적으로 반으로 나누어가면서 중간 값과 비교하며 위치를 찾아나감
left = 0; right = n-1; middle = (left + right) / 2;
찾고자하는 값인 x와 middle번째 인덱스를 비교해서
middle보다 작으면 right = middle - 1;
크면 left = middle + 1;
같으면 반환
순환 알고리즘
수행이 완료되기 전에 자기 자신을 다시 호출하는 것
- 직접 순환 : 함수가 그 수행이 완료되기 전에 자기 자신을 다시 호출
- 간접 순환 : 호출 함수를 다시 호출하게 되어있는 다른 함수를 호출
순환의 장점은 이해하기 쉽고, 쉽게 프로그래밍 가능하다는 점이나, 단점은 수행 시간과 공간 사용에 있어서 비효율적임
📌 성능 분석과 측정
공간 복잡도
프로그램을 실행시켜 완료하는 데 필요한 메모리 양
시간 복잡도
프로그램을 완전히 실행시키는데 필요한 시간
- 빅오 O(n) : 점근적 상한. 적어도 얘보단 작다. 빅오를 빅세타처럼 주로 사용 ex) n = O(n), O(n^2) 등..
- 빅오메가 : 점근적 하한. 적어도 얘보단 크다 ex) n^2 = O(n), O(n^2)
- 빅세타 : 상한과 하한 모두 만족
무작위 테스트 데이터 생성 후 측정한 실행시간을 최악의 경우의 시간으로 사용
평균인 경우의 시간 측정도 사용
