

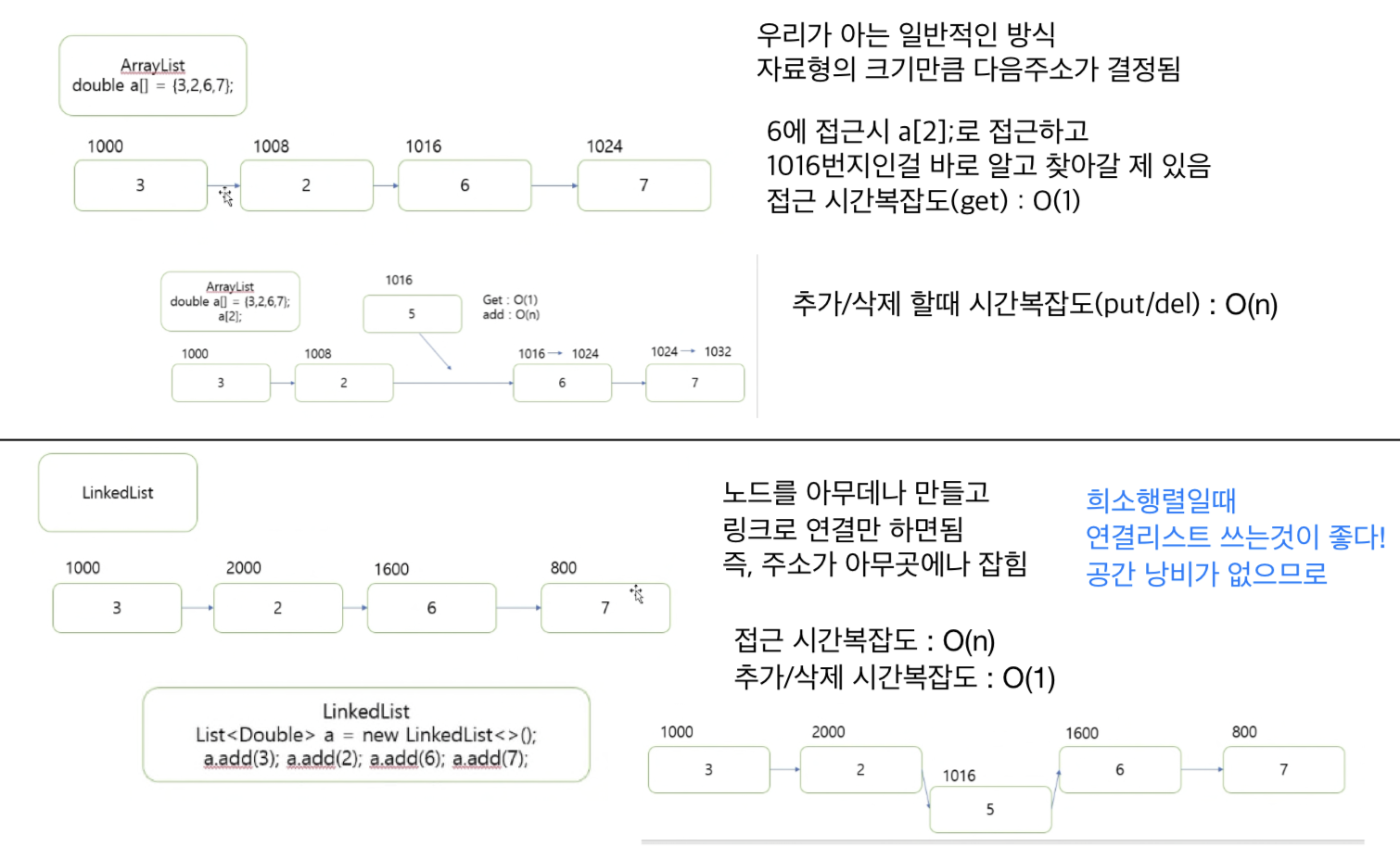
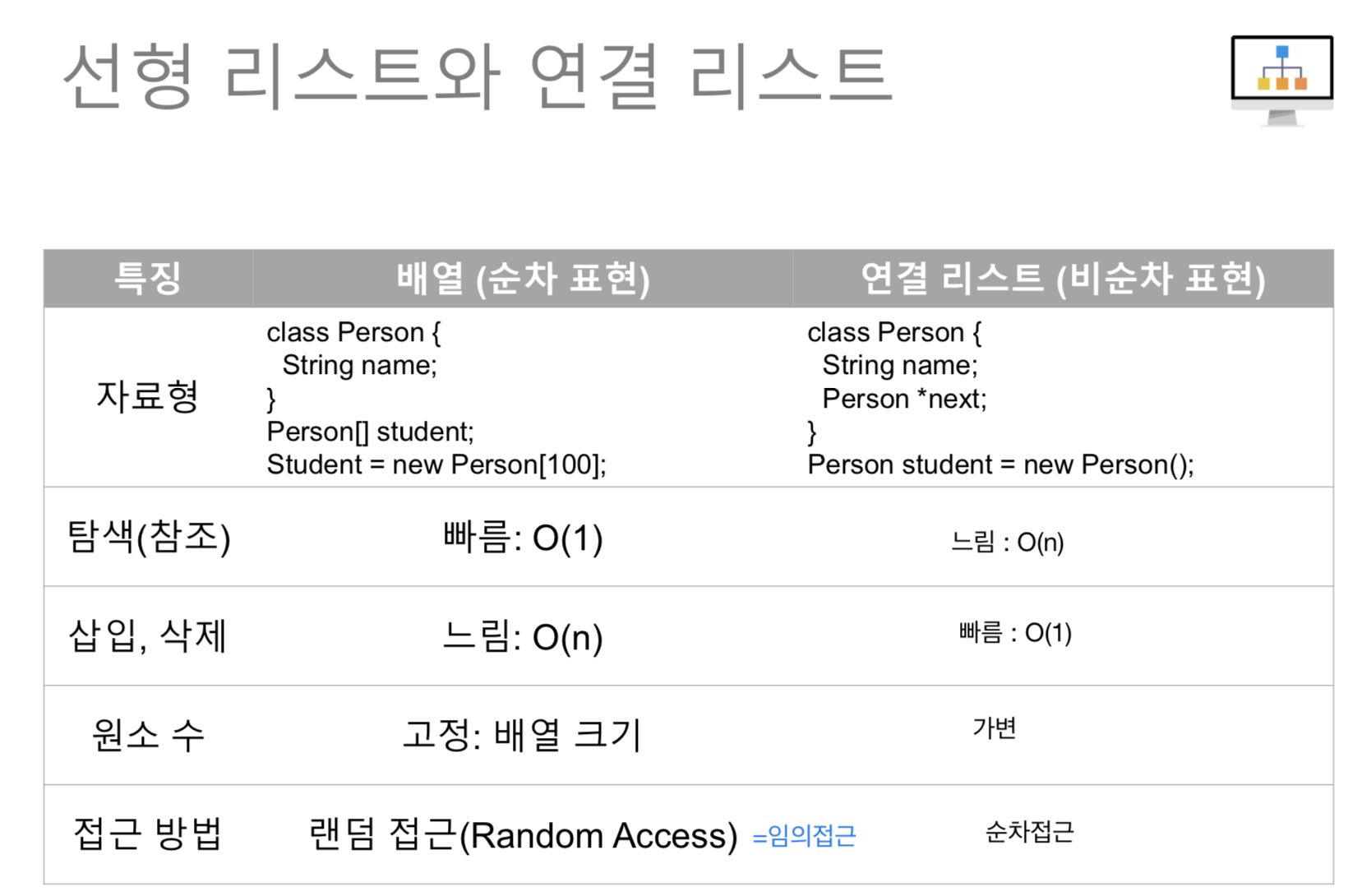
📌 Array VS Array list VS Linked list
Array 배열
int [] arr = new int [10];
선언할 때 크기와 데이터 타입 지정. 즉, 공간에 할당할 사이즈 미리 정해놓고 사용
- 장점 : 검색 편리 → 랜덤 액세스. 임의접근 가능 → O(1)
- 단점 : 데이터가 늘어날때나 최대사이즈를 알 수 없을때 사용하기에 부적합 데이터 삽입, 삭제 비효율적 → O(n)
Array list
ArrayList<Integer> arrList = new ArrayList<>();
선언 시 크기를 정해주지 않아도됨
- 장점 : 중간에 데이터 추가나 삭제가 가능하다 (즉 데이터가 늘어나도 괜찮음) 인덱스가 있으므로 검색도 빠름 → O(1)
- 단점 : 데이터 삽입, 삭제 시간 오래걸림 → O(n)
Linked list
LinkedList<Integer> linkedList = new LinkedList<Integer>();
연속적인 메모리 위치에 저장되지 않는 선형 데이터 구조
포인터를 사용하여 연결됨
각 노드는 데이터필드, 다음 노드에 대한 참조를 포함하는 노드로 구성
단일, 다중 등 여러가지 종류가 있음
- 장점 : 삽입, 삭제 편리 → O(1)
- 단점 : 랜덤액세스가 불가능하다. 즉, 첫번째 노드부터 순차적으로 접근해야함 → 검색 느림 → O(n)
📌 C++ 클래스
C++는 명세와 구현을 구별하고 사용자로부터 ADT의 구현을 은닉하기 위해 클래스 제공
클래스 구성
- 클래스 이름
- 데이터 멤버
- 멤버 함수
- 프로그램 접근 레벨 : 멤버 및 멤버 함수
- public / protected / private 등..
- 자바기준으로는 public > protected > default > private
생성자와 파괴자 함수 : 클래스의 특수한 멤버 함수
연산자 다중화 : 특정 데이터 타입을 위한 연산자를 구현하는 정의를 허용
C++의 struct : 묵시적 접근 레벨 public
union : 제일 큰 멤버에 맞는 저장장소 할당, 보다 효율적인 기억장소 사용
static 클래스 데이터 멤버 : 클래스에 대한 전역 변수. 모든 클래스 객체는 이를 공유. 정적 데이터 멤버는 외부에서 정의
📌 Sparse Matrix 희소 행렬
희소 행렬 : (0이 아닌 원소 수 / 전체 원소 수)가 매우 작은 것
→ 즉, 행렬의 대부분의 요소가 0인 행렬
행렬에 대한 연산은 생성, 전치, 덧셈, 곱셈 등이 있음
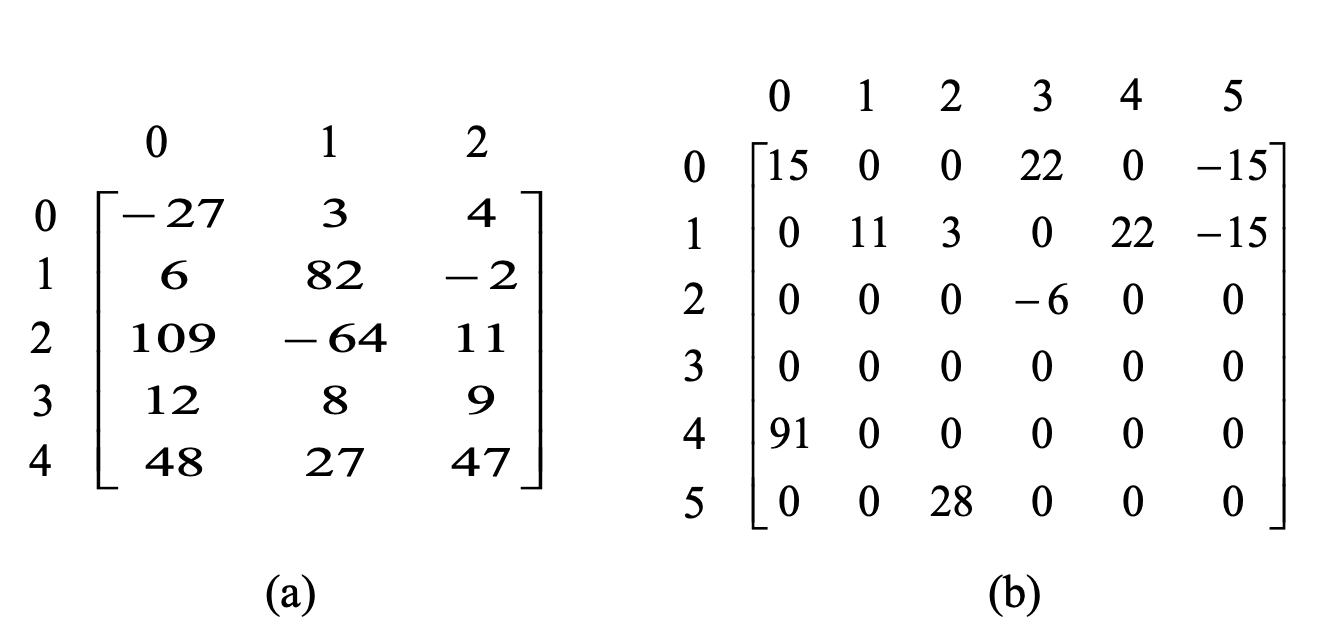
두행렬을 비교해보면 왼쪽은 밀집 행렬, 오른쪽은 희소 행렬
효율적인 희소 행렬 표현
- <행, 열, 값> 3원소 쌍으로 유일하게 식별가능
- 각 행의 3원소 쌍들을 열 인덱스 오름차순으로 저장
- 연산 종료를 보장하기 위해서는 행렬의 행과 열의 수(rows, cols), 0이 아닌 항의 수(terms)를 알아야함
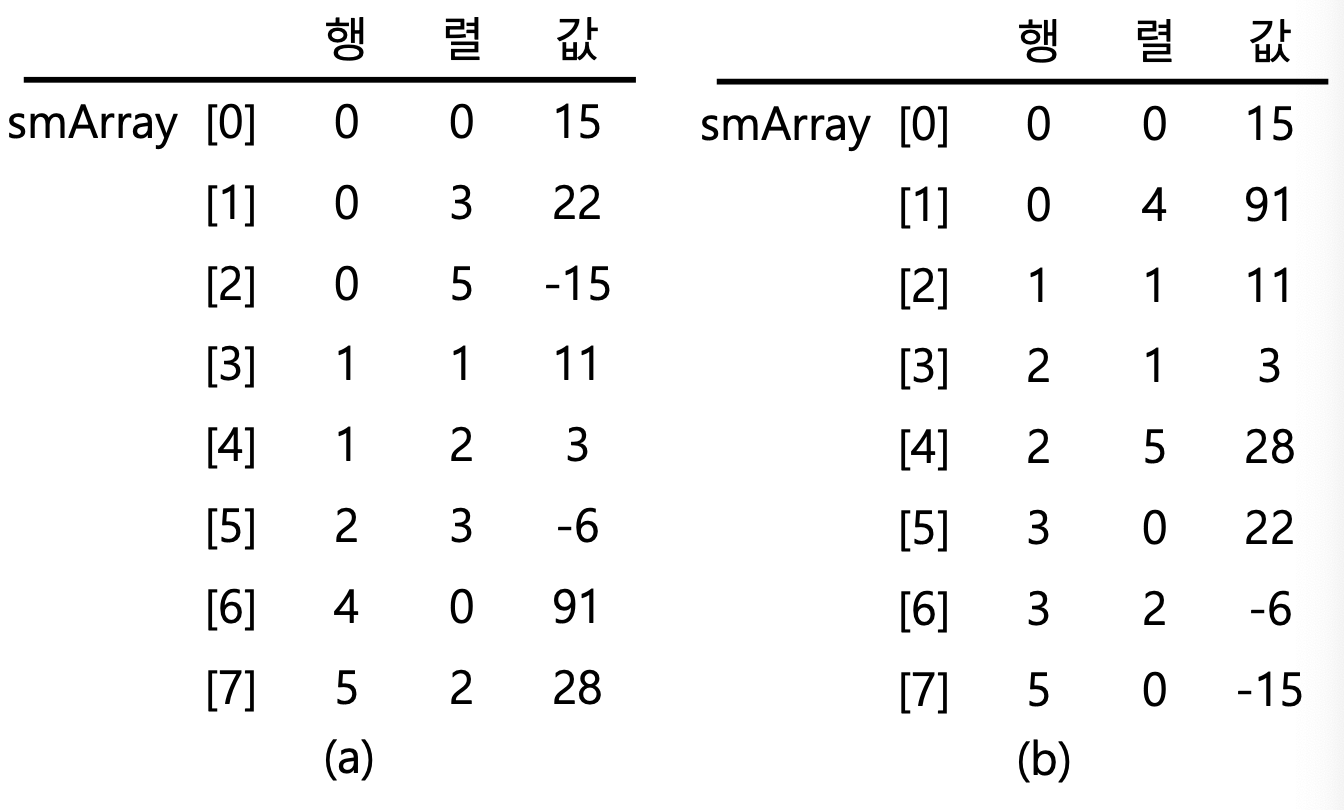
원소 쌍으로 저장된 희소행렬과 전치 행렬 예시
*추가
인접행렬 : 공간복잡도 O(n^2)
인접리스트 : 공간복잡도 O(n+m) → n이 최대 노드 개수 , m이 노드수라면 n+2m
구현이 어렵다는 단점
희소행렬 : 인접 리스트 자료구조 사용 → 링크드 리스트로 구현
밀집행렬 : 인접 행렬 자료구조 사용 → 어레이 리스트(배열)로 구현
인접리스트는 접근 시간이 짧지만 추가,삭제 시간복잡도 높음
어레이리스트는 접근 시간 길지만 추가,삭제 시간복잡도 짧음
📌 행렬의 전치
원래의 행렬 각 행 i에 대해 원소 (i,j,값)을 가져와서 (j,i,값)으로 저장
알고리즘 : for (열 j에 있는 모든 원소에 대해) {원소 (i,j,값)을 원소(j,i,값)으로 저장}
→ 실행시간 : O(terms * cols)
단순 2차원 배열으로 표현
- 가장 단순한 형태의 알고리즘
- 새로운 행렬 b[j][i] = 기존행렬 a[i][j] 이거를 반복문 돌면서 해주면됨
FastTranspose
메모리를 조금 더 사용한 대신 실행시간의 감소
행렬 *this의 각 열에 대한 원소 수를 구함 → 전치 행렬 b의 각 행의 원소 수를 결정 → 이 정보에서 전치행렬 b의 각 행의 시작위치 구함 → 원래 행렬 a에 있는 원소를 하나씩 전치행렬 b의 올바른 위치로 옮김
→ 실행시간 : O(colums + terms)
📌 행렬 곱셈
행렬 a(m n ) 과 행렬 b(n p)의 곱셈 → 행렬 d의 차원은 (m * p)
순서리스트로 표현된 두 희소 행렬의 곱셈
- result의 원소를 열 단위로 계산
- 이전 계산 원소를 이동하지 않고 적절한 위치에 저장
- 행렬 a의 한 행을 선택하고 j = 0,1,…,b.cols-1에 대해 b의 j열에 있는 모든 원소를 찾음
- a의 i행과 b의 j열의 원소들이 정해지면 다항식 덧셈과 유사한 합병연산 수행
희소행렬의 곱셈
a의 행 r이 곱해지는 동안의 소요시간 :
a의 행 currRowA에 대해 한번 반복하는데 걸리는 시간 :
전체 소요시간 :
📌 배열의 표현
배열의 표현순서 : 행우선 / 열우선
- 행우선 저장순서 : a[0][0][0][0, ]a[0][0][0][1], a[0][0][0][2], … ,a[0][0][1][0] → 사전순서
1차원 배열 : a[0]의 주소를 라고할때, a[i]의 주소는
2차원 배열 : a[0][0]의 주소를 라고할때, a[i][0]의 주소는 col개수
3차원, n차원 배열도 같은 개념
2차원 배열도 1차원 배열과 동일하게 pointer → 값이 순서대로 저장됨
ex) 2차원 int 배열이라면 0,4,8,12 … 이런식으로
📌 스트링 패턴 매치 : KMP 알고리즘
스트링 추상 데이터 타입 : 문자열(string)의 형태
→ 연산 : 공백 스트링 생성, 스트링 읽기 또는 출력, 두 스트링 concatenation, 복사 등등…
문자열 탐색 알고리즘
s 스트링에서 pat 스트링을 찾는 알고리즘
부르트포스 알고리즘 : 모든 경우를 다 구하는 것 → 시간복잡도 매우 큼
문자열 탐색을 부르트포스 알고리즘을 이용해서 다 구한다면, 인덱스를 한자리씩 옮기면서 다 비교하는 방식일 것
이때 텍스트의 길이를 N, pattern의 길이를 M이라고 하면 → O(N*M)
KMP 알고리즘
접두사와 접미사를 이용하여 실패함수를 정의한다
ex) 텍스트 : abcdabcdabee의 경우
| 0 | a | -1 |
|---|---|---|
| 1 | ab | -1 |
| 2 | abc | -1 |
| 3 | abcd | -1 |
| 4 | abcda | 1 |
| 5 | abcdab | 2 |
| 6 | abcdabc | 3 |
| 7 | abcdabcd | 4 |
| 8 | abcdabcda | 1 |
| … | … |
위와같이 실패함수를 정의할 수 있디
이때 pattern : abcdabe라면
첫번째 검사에서 인덱스 5까지 일치하고, 인덱스 6인 e에서 다른것을 확인할 수 있다
→ 이때 인덱스 5의 실패함수가 2이므로 중간단계 뛰어넘고 인덱스4부터 다시 확인해보면 된다
100만 = 10^6 = 2^20
