
📌 Principles of network applications
network app을 만드는 법
각기 다른 end systems에서 실행되도록
네트워크를 통해 통신되도록
network core 기기에서 실행될필요 없음 → 어차피 2,3 계층까지만
applilcation 구조 두종류
-
Client-serverServer- client가 언제 요청할지 모르므로 항상 ON 상태
- 고정적, 영구적인 IP 주소
- 범위를 위해 data center에 있는 경우도 있음
Client- 서버와 접촉, 통신
- 간헐적으로 연결됨
- 동적 IP주소를 가짐 → 주소가 충분하지 않으므로
- client끼리 직접 통신을 하진 않음
- ex) HTTP, IMAP, FTP(File Tranfer Protocol), SFTP(Secure…)
-
Peer-peer서버같이 항상 ON 상태인 것은 없다
임의의 end systems끼리 직접 통신 가능
peer가 다른 peer 서비스 요청도 가능하고, 제공도 가능함
→
self scalability: 새로운 peer가 들어오면 공급자일수도, 요청자일수도 있음peer끼리는 간헐적으로 연결되고 IP주소를 변경한다 - 관리 복잡
ex) P2P 파일 공유
Process communicating
프로세스 : 호스트가 실행중인 프로그램
같은 호스트가 실행중인 2개의 프로세스의 통신은 inter-process communication이용 → OS가 지원
호스트가 다른 프로세스간의 통신은 message 교환을 이용
Client process : 통신을 시작하는 프로세스
Server process : 통신을 기다리는 프로세스
P2P구조는 client process & server process가 존재
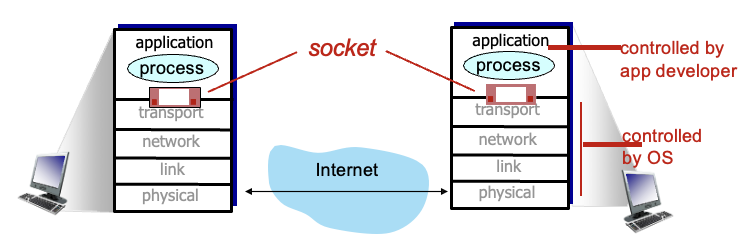
Socket : 프로세스가 message를 주고받는 통로
메시지를 받기위해서 프로세스는 identifier가 필요함
각 호스트 디바이스는 unique한 32bit IP주소를 가짐 → 하지만 이거로 충분 X
IP주소 + port 번호로 구분 → IP주소는 집주소, 각 집사람들 이름이 port number
port number는 정해져있음. HTTP : 80, mail : 25
즉, IP주소를 보고 호스트를 구분하고, port number로 프로세스를 구별함
application layer 프로토콜이 정의하는 것들
- 교환될 message 타입 → ex) request, response
- message의 syntax → message에 어떤 필드가 있고 어떤것을 나타내는지
- message의 semantic → 필드에 있는 정보의 의미
- 언제, 어떻게 프로세스가 message를 보내고 받을지
4계층 transport과의 관계도 생각해야함 → 통신 의뢰 → 소켓 이용
open protocols : RFCs에 의해 정의됨. 누구나 접근할 수 있게 정의됨. ex) HTTP, SMTP
proprietary protocols : ex) Skype
앱에서 어떤 전송을 요구하는가?
Reliabledata transfer :신뢰성있는 전송 → 손실이 없어야한다는 뜻 어떤 앱들은 100% 신뢰적인 데이터 전송을 요구 → ex) 파일 전송, 웹 어떤 앱들은 조금의 손실은 괜찮음 → ex) 오디오, 이미지 같은것 들은 속도가 더 중요
timing어떤 앱들은 속도가 중요함 → ex) 인터넷 전화, 게임
throughput어떤 앱들은 효율을 위해 최소의 처리량만을 요구 → ex) 멀티미디어 어떤 앱들은 어떤 것이든 처리가능한 처리량을 요구 → ex) elastic apps
- security
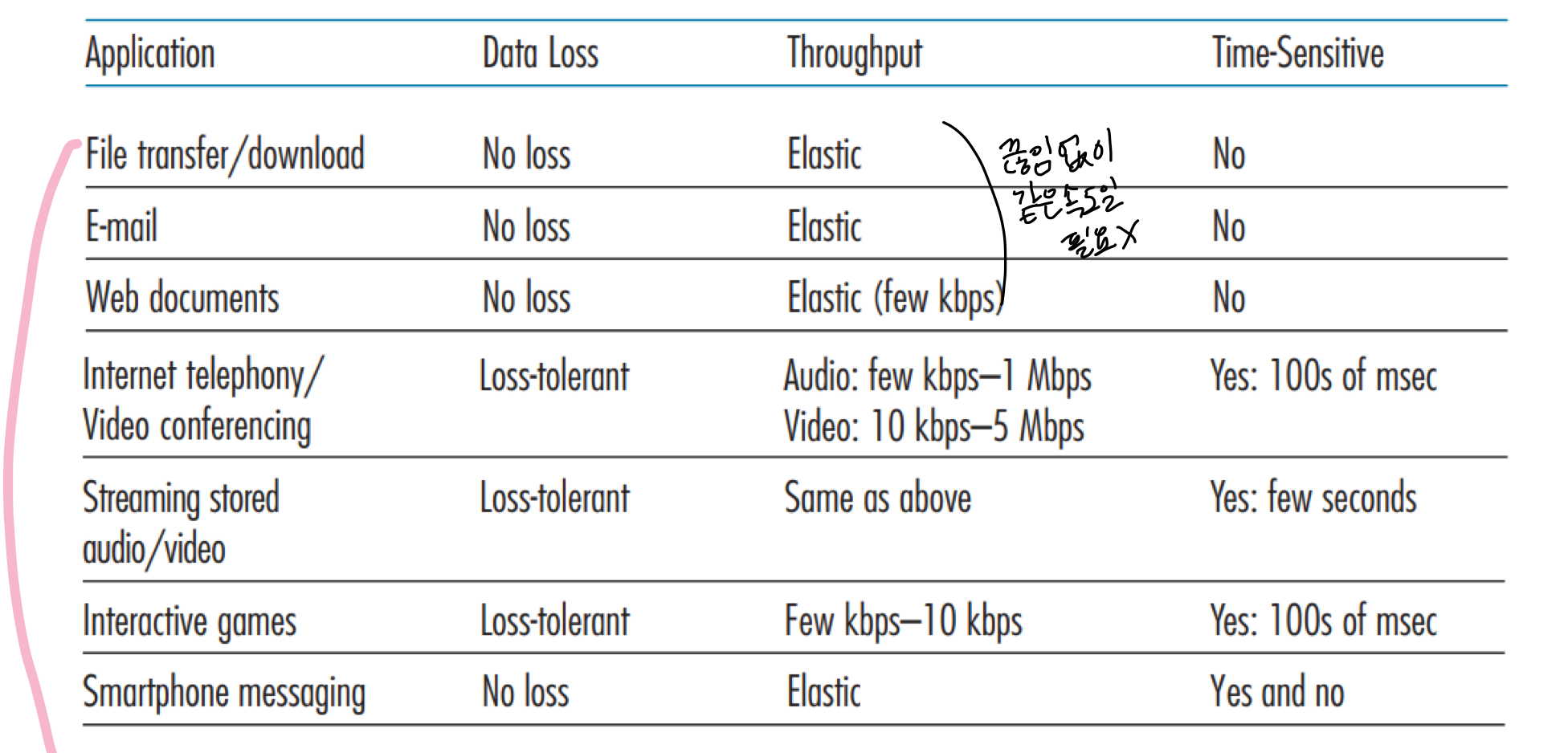
위의 세개는 througput이 별로 상관없다는 것
Internet transport protocols services
TCP 서비스
- reliable transport
신뢰적전송 : 이전에 연결 설정을 하고 Loss 생길시 재전송 → 데이터가 반드시 도착 보장 -RDT - flow control 흐름 제어 : sender가 너무 빨리 보낼 때 수신자가 속도 제어 가능
- congestion control 혼잡 제어
- timing, 최소 throughput, 보안은 관여하지 않음
- 연결 지향적 : client-server 사이에 연결 설정
UDP 서비스
- unreliable data transfer :
비신뢰적인데이터 전송 → 데이터가 잘 도착했는지 신경안씀 -UDT - 신뢰성, flow control, congestion control, timing, throughput 보장, 보안, 연결 설정 모두 안함 → 하는일이 별로 없음
속도가빠르다는 장점
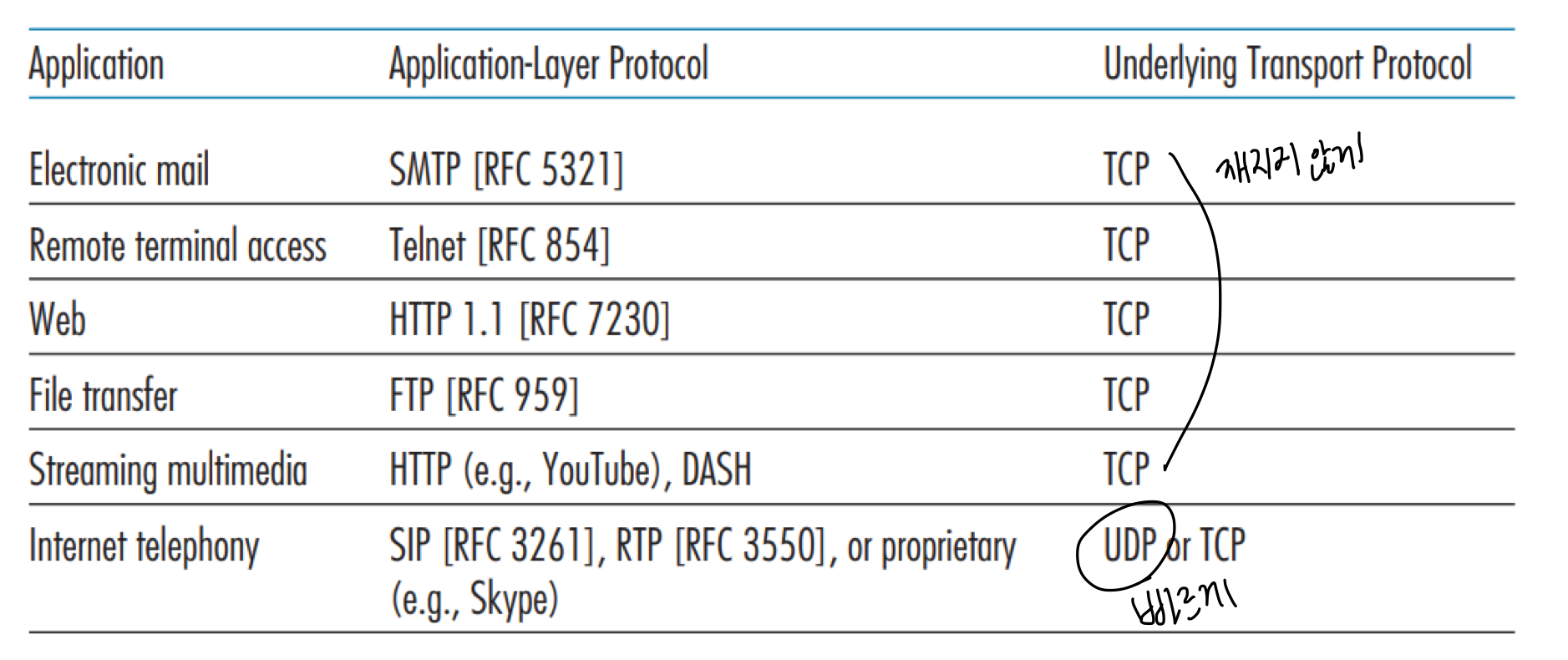
📌 Web and HTTP
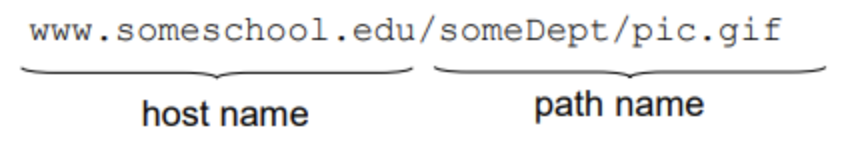
웹 페이지는 objects로 구성되어있음 → object는 HTML file, JPEG file, Java applet 등..으로 이루어짐
웹 페이지는 여러개의 참조된 objects를 포함하는 base HTML-file로 구성됨 → 각각은 URL으로 주소 표현가능함
스키마 : HTTP
host : edu까지
port : 80
path : some부터끝까지
query, fragment : 없는 상황
HTTP
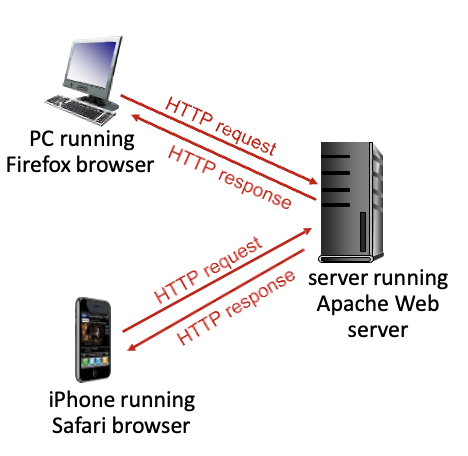
HTTP : Hyper Text Transfer Protocol → 웹의 어플리케이션 레이어에서의 프로토콜
- 클라이언트 : 요청하고 응답을 받는쪽이고 Web objects 보여줌 →
requestmessage - 서버 : 클라이언트의 요청에 따라 object를 보내줌 →
responsemessage
HTTP는 TCP를 사용
순서
- 클라이언트는 서버와의 TCP 연결을 만듦 (포트 80)
- 서버는 클라이언트로부터의 TCP 연결을 수락
- HTTP message(5계층)는 브라우저(HTTP 클라이언트)와 웹서버(HTTP 서버)간에 교환됨
- TCP 연결 닫음
HTTP는 stateless : 서버는 이전 클라이언트 request에 대한 정보를 기억하지 않음
↔ stateful
state를 기억하는 프로토콜은 매우 복잡해짐 : state가 만약 불일치하다면 다시 맞추는 과정이 필요한데 이는 매우 복잡
HTTP connections : two type
Non-persistent HTTP : 연결 후 하나만 보냄
- TCP 연결 open
- 최대 하나의 object만 전송
- TCP 연결 close
여러개의 object를 받는다면 여러번의 connection 필요


1a. 80 포트를 이용하여 client가 server와의 TCP 연결을 만듦
1b. 클라이언트의 연결 요청을 받고 이를 알려줌
- 서버로 request message를 요청함
- request message를 받고 요청한 object를 포함한 response message를 보내줌
- 서버측에서 TCP 연결을 끊음
- 클라이언트는 response message를 받음
10개의 jpeg 이미지를 받으려면 1-5번 과정 10번 반복해야함
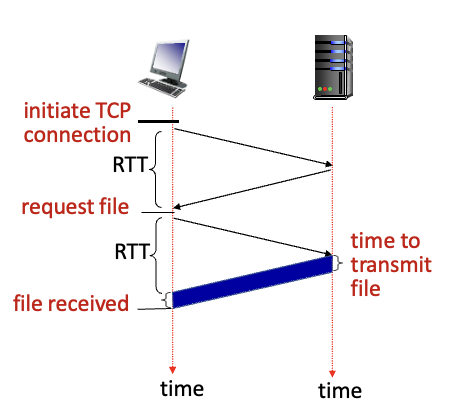
RTT : 패킷이 클라이언트에서 서버에 갔다가 돌아오는 시간
non-persistent HTTP의 response time :
초기 TCP 연결을 위해 1 RTT + request, response하는데 1RTT + object/file transmission time
= 2RTT + file transmission time
단점 : object 하나당 2RTT가 필요하고 OS 오버헤드가 심함. 동시에 여러개의 연결을 하더라도 TCP 부담, 오버헤드 존재 → Persistent HTTP
Persistent HTTP : 연결 후 필요한만큼 보냄
- TCP 연결 open
- 클라이언트와 서버 사이의 하나의 TCP 연결에 여러개의 objects 전송
- TCP 연결 close
HTTP 1.1
- 서버가 response를 보낸 후에도 연결을 닫지 않고 열어놓음
- HTTP message가 연결을 통해 계속 공유될 수 있음
- 일정시간동안 데이터가 오지 않으면 연결 닫음
- 클라이언트는 응답받자마자 요청가능
- 하나의 object당 약 1RTT 시간 소요 → 반으로 단축된 것!
HTTP request message
HTTP message는 request, reponse 두가지 종류

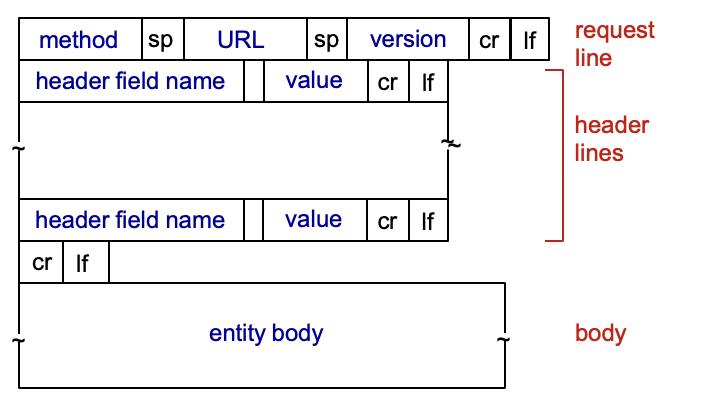
request할 때 보내는 방식 (클라이언트 → 서버)
POSTmethod 웹페이지는 입력 form을 포함할 수 도 있음유저가 입력한 내용은 body 내에들어와서 클라이언트에서서버로 보내짐리소스를 생성/업데이트 하기 위해 서버에 데이터 보내는 데 사용
GETmethod : HTTP의 GET request 메세지의 URL 필드에 사용자 정보 포함 클라이언트가 서버로정보 요청할 때 사용→ 데이터 읽을 때
- HEAD method
- PUT method : 서버에 파일 업로드 할 때
HTTP response message

맨위줄은 상태 표현 status
Last modified : 마지막 수정 날짜
status codes 종류
- 200 OK : 성공
- 301 Moved permanently : 요청한 자료가 없어졌다(옮겨졌다)
- 400 Bad request : 서버가 이해할 수 없는 request msg
- 404 Not found : 서버에서 request document 찾을 수 없음
- 505 HTTP version Not supported : HTTP 버전 다름
400번은 client 잘못, 500은 server 잘못
Cookies : 유저/서버 상태 유지
HTTP GET/response은 stateless함 : 정보를 기억하지 않음
클라이언트/서버가 state를 추적해야할 필요가 없음
모든 HTTP 요청은 독립적
→ HTTP는 state를 저장하지 않으므로 사용자 정보 등을 읽을 수 없음 → Cookie를 통해 state를 저장한다
쿠키 네가지 종류
- HTTP response msg의 헤더 라인에 쿠키
- 다음 HTTP request msg의 헤더 라인에 쿠키
- 유저의 브라우저, 호스트에 의해 관리되는 쿠키
- 웹사이트의 백엔드 db에 있는 쿠키
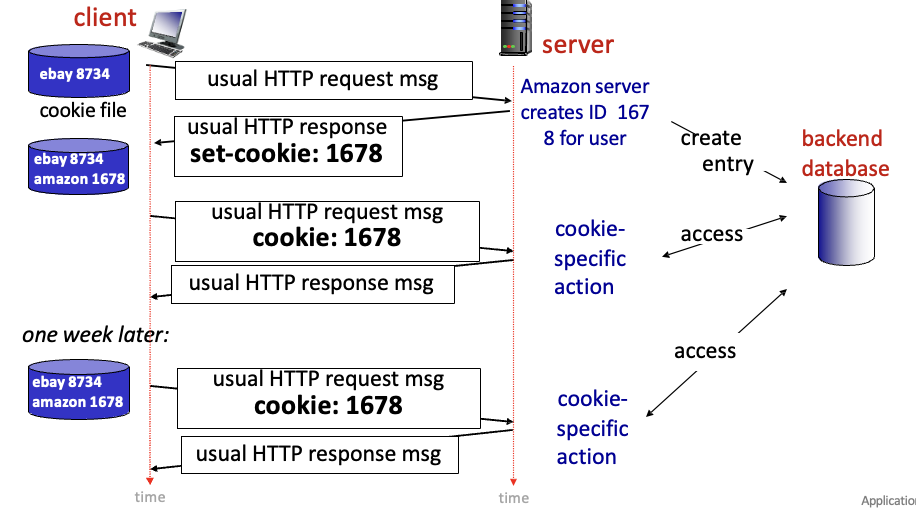
- 클라이언트 → 서버로 request msg 보냄
- 서버에서 user ID를 생성하여 데이터베이스에 저장하고, response에 정보 담아서 보냄
- 클라이언트는 쿠키 파일 생성하고, request 보낼때 쿠키 정보 담아서 보냄
- 서버는 request로 쿠키를 받았으므로 DB에 접근해서 정보 보여줌
- 시간이 지난 후에도 쿠키를 이용해서 똑같은 작업 가능
→ Stateful!
쿠키는 인증, 쇼핑카트, 추천, 유저 세션 유지 등에 사용
쿠키는 사용자에 대한 많은 정보를 가지게 됨
third party cookie (tracking cookie) : 웹 사이트 운영자가 아닌 다른 사람이 심은 쿠키로
Web caches (proxy servers)
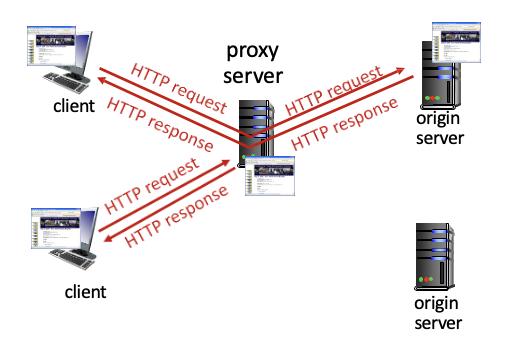
origin server에 접근 없이 proxy server(cache)에만 접근해서 클라이언트의 request를 수행하도록 하는 것 → 속도 향상
proxy server = Web Cache
브라우저(클라이언트)는 모든 HTTP request를 캐시로 보냄
- 요청 자료가 캐시에 있다면 : 캐시를 클라이언트에게 보냄
- 요청 자료가 캐시에 없다면 : 캐시가 origin server에 obejct 요청해서 받은 후에, 클라이언트에게 보내줌
캐시는 클라이언트, 서버 역할을 둘다함 → 서버에게는 클라이언트, 클라이언트에게는 서버
주로 캐시는 ISP에 의해 운영됨 (대학, 회사, residential ISP 등…)
+)
proxy pattern : 접근을 제한함
decorator pattern : 결과물을 꾸며줌
singleton pattern : 동일한 작업을 하나로 빼줌
장점
- client의 요청에 대한 응답 시간을 줄일 수 있다 → 캐시는 origin server보다 클라이언트에게 더 가까이 있음
- 서버의 트래픽 감소
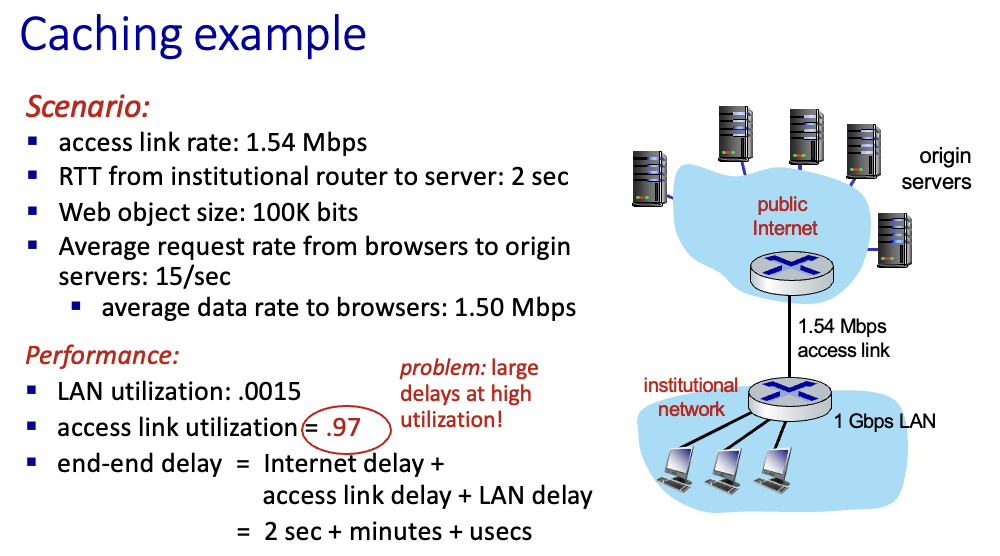
public internet으로 연결되는 링크에서 97% → 엄청난 딜레이
total delay = internet delay(2초) + access delay(매우 큼) + LAN delay
→ 즉 시간이 매우 많이 걸리게됨
access link를 1.54 Mbps에서 154 Mbps 등 더 빠른것으로 바꾼다면 속도는 빨라지겠지만 가격이 많이 들음
⇒ 즉, Web cache를 사용! (저렴함)

hit가 40%일때가 평균 delay = 약 1.2s가 나오므로 딜레이 훨씬 감소
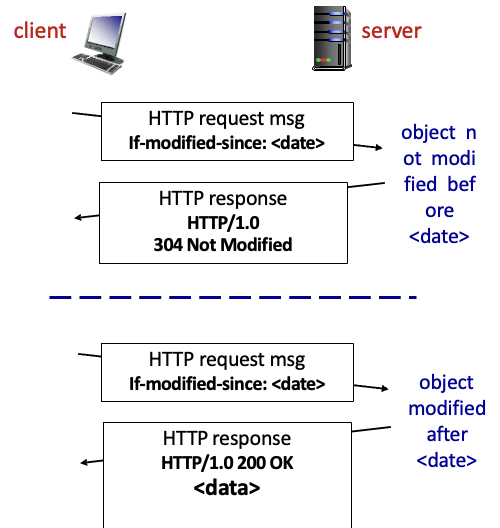
Conditional GET : 프록시 서버는 현재 자료가 최신인지 확인하기 어려움 → 캐시가 최신버전인지 아닌지 orgin server에서 확인하는 작업
여기서 client는 proxy server
이후로 변경된 것이 있는지 origin server로 물어봄
- 변경된 게 없음 : 갖고있던거 쓰면됨
- 변경된 게 있음 : 서버에서 reqeust로 최신 자료 보내줌
HTTP/2
HTTP 1.1 : 하나의 TCP 연결에서 FCFS 방식으로 다수의 GETs 처리
→ HOL(Head of Line) blocking 문제 발생 : 작은 object들이 큰 용량의 object를 기다려야함
또한 loss가 생기면 재전송해야하는데 이 또한 대역폭 차지하므로 비효율적
HTTP/2에서 달라진 점
- 우선순위를 정해서 먼저해야하는 것부터 처리 → FCFS가 필수는 아님
- client의 요청 전에 예측해서 object를 보냄
- object를 frames이라는 단위로 나눠서 HOL blocking 예방
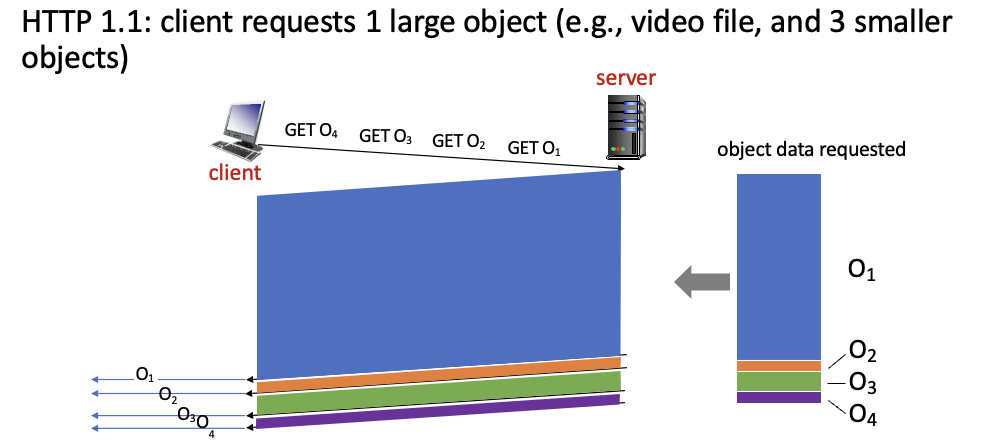
HTTP 1.1에서의 HOL blocking 문제
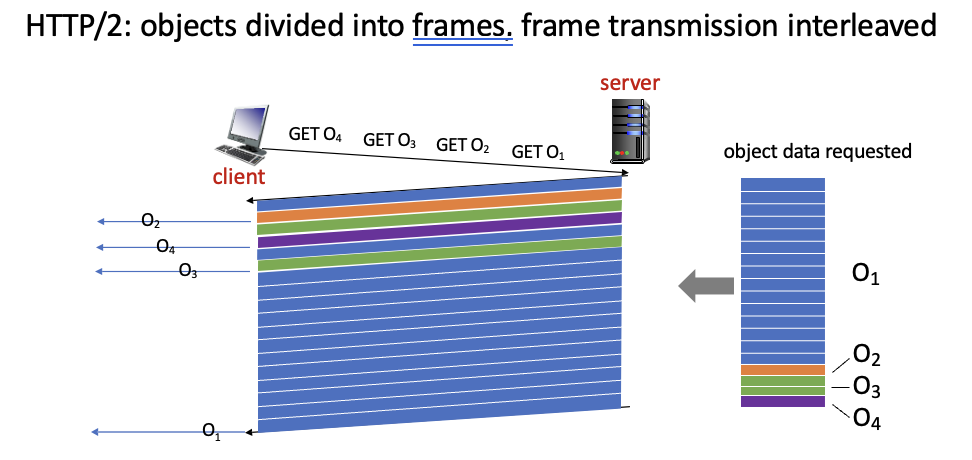
HTTP 2에서 frames을 통해 문제 해결
📌 Email, SMTP, IMAP
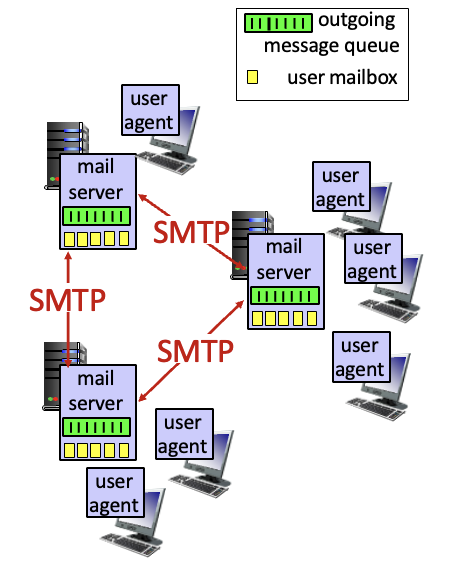
이메일의 3요소
User agents: 편집기. 메일 작성, 읽기 등을 수행함. mail reader라고도 함. 메세지들은 서버에 저장됨 → ex) Outlool, 아이폰 메일 client
Mail server: 서버끼리 데이터 전달. mailbox는 유저에게 온 메세지들을 저장. message queue는 보낼 메세지를 저장함.SMTP(Simple Mail Transfer Protocol)
이메일도 RFC에 표준으로 등록이 되어있음
이메일은 TCP를 이용하여 reliable 전송. 포트 25번
보내는 서버(클라이언트 처럼 행동)가 받는 서버에게 직접 전송
전송 과정 3단계
- handshaking : 연결 설정
- 메세지 전송
- 닫음
command/response 상호작용(HTTP 같이)
- Command : ASCII 문자. (request라고 보면됨)
- response : status 코드와 phrase
메일 전송 과정
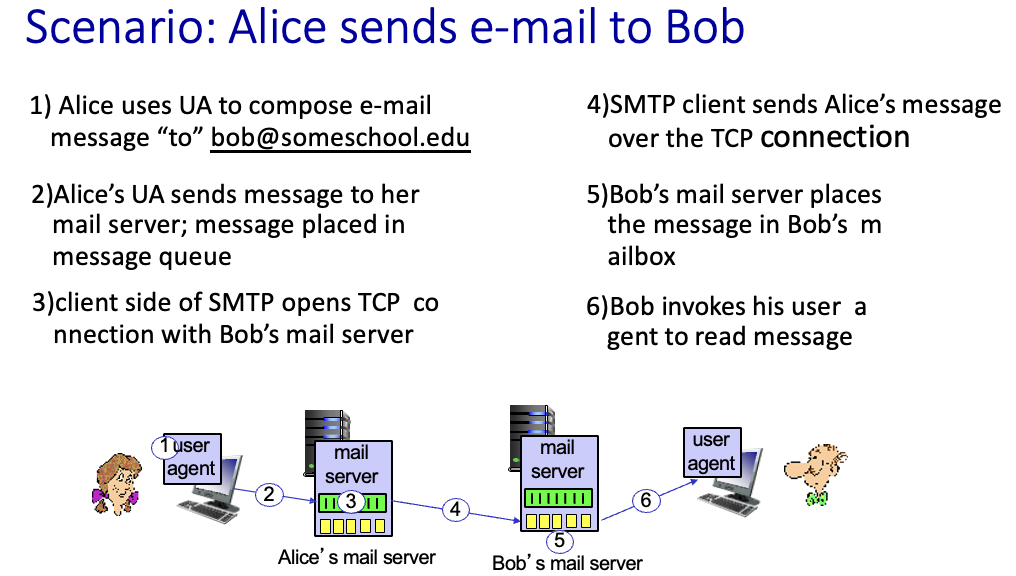
- 앨리스가 User Agent(편집기)를 사용하여 bob@…에게 보낼 메일을 작성
- 앨리스의 UA가 앨리스의 mail server로 메일을 보냄 →
message queue에 보낼 메일 저장됨 - Bob의 메일 서버와의 TCP 연결을 열음
SMTP가 TCP 연결을 통해 앨리스의 메세지를 보냄- Bob의
mailbox에 메일 저장됨 - Bob이 자신의 UA를 통해 메일 읽음
SMTP
HTTP와 SMTP 비교
- 둘다 ASCII코드의 command/response 상호작용이 있고, status code가 있음
- HTTP : pull - 내가 필요할 때 가져옴 / SMTP : push - 내가 필요할 때 메일을 보냄
- HTTP : 각각의 Object는 각 메세지 내에서 encapsulated
- SMTP : 여러개의 object를 한번에 보낼 수 있음
- SMTP는 persistent connection 이용 → 연속적
메일 포맷은 헤더 / 바디로 구성됨
- 헤더 : To, From, Subject → 실제 이메일 내에 들어가는 보내는 사람, 받는 사람 등
- 바디 : 메일 내용. ASCII
Mail access protocols
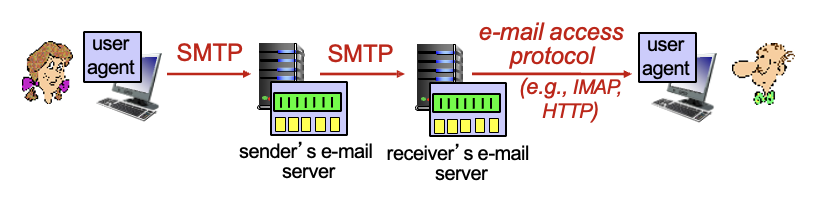
SMTP : 메일 서버 간 메일 전달, 저장에 사용
IMAP (Internet Mail Access Protocol) : 서버에 저장된 메세지를 읽고, 삭제, 폴더 관리 등을 할 수 있음
HTTP : gmail, Hotmail, Yahoo! 등..은 STMP와 IMAP를 제공
📌 DNS : Domain Name System
host, router는 IP주소를 통해 구분함
DNS
분산 계층 데이터베이스 구조를 가짐
host, name server를 IP주소로 번역하거나 반대로 이름으로 바꿔줌(resolve한다고 함) ⇒ 주로 도메인 이름으로 IP 주소 찾아준다고 보면됨
→ ex) 이름 : www.naver.com / IP주소 : 192.0.2.1 간의 변환
복잡한 것은 network’s edge에 있어야하므로 DNS가 5계층에 있는 것
DNS가 하는 일
- hostname ↔ IP주소 간의 상호변환
- host의 별명을 지어줌
- canonical : 원래 이름 / alias name : 별명
- mail server 별명 지어줌
- 경로 분산 : 웹 서버들을 복제 → 많은 IP 주소들을 하나의 이름으로 부름
DNS가 분산 계층 구조인 이유?
- single point of failure : 하나가 죽으면 서버 죽음
- 트래픽 크기
- 데이터베이스 하나만 있으면 거리가 멀어짐
- 유지보수
확장성을위해서
DNS는 아래와 같은 분산 계층 구조의 데이터베이스
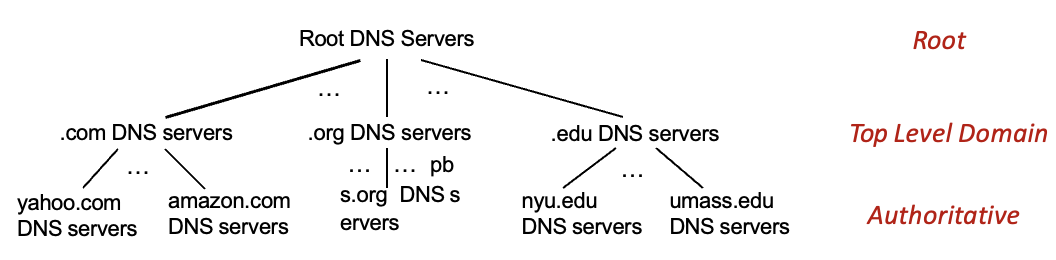
사용자가 www.amazon.com에 접속하고 싶어한다고 가정
→ 클라이언트가 .com DNS server를 찾기위해 루트 서버에 쿼리 보내고 받음
→ 클라이언트는 amazon.com DNS server를 찾기 위해 .com DNS server에 쿼리보내고 받음
→ 클라이언트는 www.amazon.com의 IP주소를 찾기위해 amazon.com DNS server에 쿼리 보내고 IP주소 받음
DNS는 매우매우 중요한 인터넷의 기능임 → DNSSEC : 보안 기능 제공
TLD (Top Level Domain) server : 최상위 레벨 도메인 → ex) .kr . com 등…국가 최상위 도메인과 일반 최상위 도메인
Local DNS name servers : 계층 구조에 속하지 않음. ISP마다 갖고 있음. 프록시 서버처럼 작동함
DNS name resolution : IP주소를 알아내는 과정
-
Iterated query
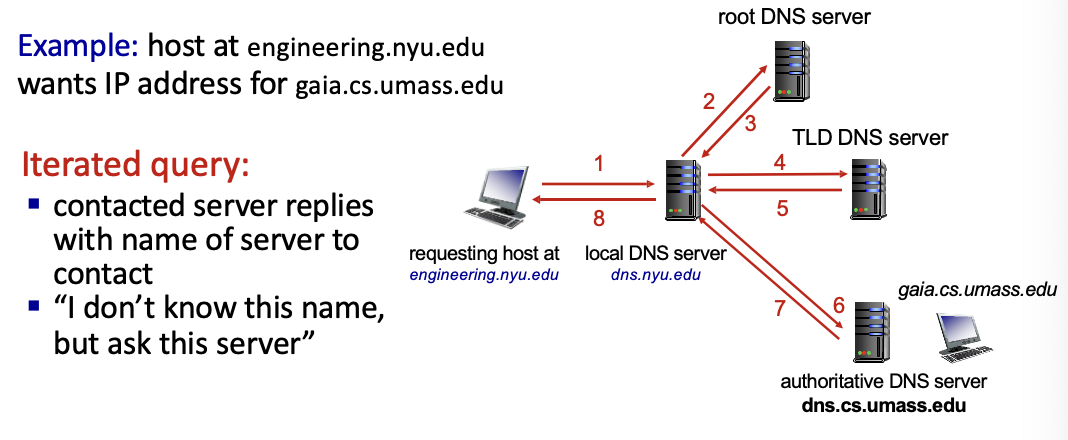
서버를 간접적으로 알려줌
사용자가 naver.com에 접속 원함 → 루트 DNS server에 질의 → ~어떤 서버에 물어보라고 전달 → 반복…
-
Recursive query루트 DNS server가 하위 서버를 찾고, 그 서버가 또 찾아서 돌려주는 재귀적인 방식
루트 DNS 서버에 부하가 많이 걸리는 단점
DNS에서도 캐시를 이용함 → TTL : 일정 시간동안 사용되지 않으면 삭제
TLD 서버는 주로 local name server에 저장되어있음
따라서 root 서버에는 거의 갈일이 없다
DNS : RR(Resource Record)를 저장하는 분산 데이터 베이스
→ RR 포맷 : (name, value, type, ttl)
- type = A ⇒ Address name : 호스트 네임 value : IP 주소
- type = NS ⇒ Name Server name : 도메인(ex. naver.com) value : Authoritative name server
- type = CNAME ⇒ Canonical Name name : 실제이름(canonical name) value : 별명 ex) www.naver.com(별명)의 진짜 이름은 따로 있음
- type = MX value : mail server의 이름
DNS protocol messages

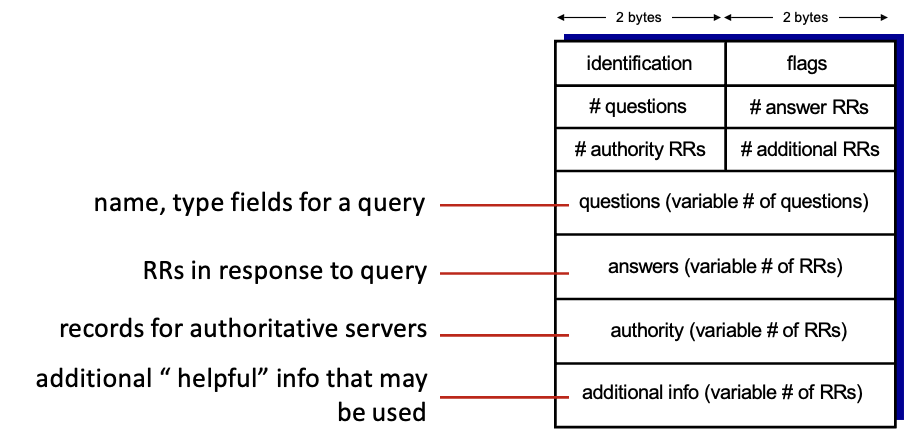
DNS 쿼리와 응답 메세지는 같은 포맷 사용
#붙어있는 애들까지가 헤더 → #은 개수 의미
questions : request 내용
밑에 3개는 응답에 관한 내용
DNS registrar : DNS 도메인 이름 등록할 때 대행해줌
DNS 보안
- DDoS 공격
- 루트 서버 공격
- TLD 서버 공격 : 더 위험함
- Redirect 공격
- man-in-middle : DNS 쿼리를 중간에서 가로챔
- DNS poisoning : 잘못된 정보를 보냄
- Exploit DNS for DDos
→ DNSSEC : 여러가지 공격 막기 위해 사용
📌 P2P applications
Peer to Peer 전에 배웠던 내용
- 항상 ON 상태 아님
- end systems끼리 직접 통신
- peer는 요청, 제공 다 가능 → self scalability 자기 확장성
- peer들은 간헐적으로 연결되며 IP주소 계속 바뀜 → 관리 어려움
File distribution time : client-server VS P2P
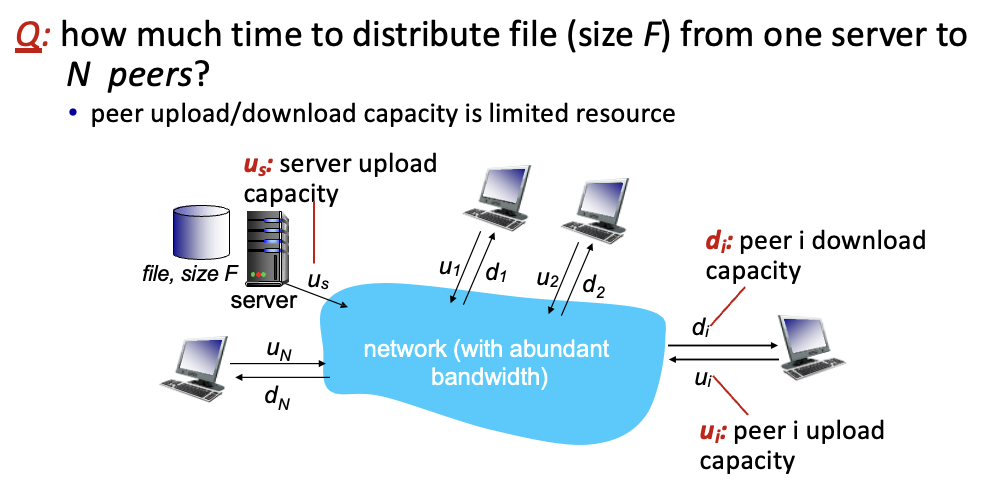
Q. 하나의 서버가 n개의 peers들에게 파일을 전송할때 걸리는 시간은?
-
client-server

F : 사이즈
: 초당 속도
→ 나누면 서버에서 클라이언트로 보내는데 걸리는 시간
F / d_min : 가장 느린 클라이언트가 파일을 받는데 걸린 시간
보내는 시간, 받는 시간 중 더 긴애를 선택 → 일반적으로 보내는게 시간 더 많이 걸림(N명한테 보내는 시간이므로)
-
P2P

서버는 최소 하나 올리면됨
각 클라이언트는 파일을 받게됨
파일을 받은 클라이언트는 다시 서버가 되어서 전송에 참여 가능
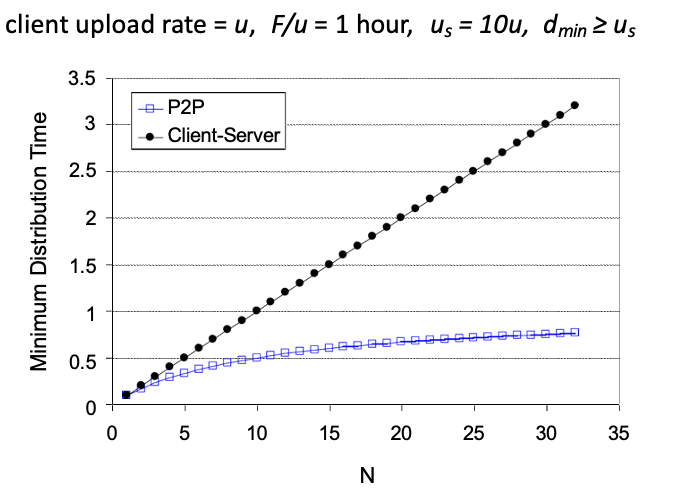
결과적으로 P2P가 여러사람이 같이 일을 하므로 분산이 되어 시간이 더 적게 걸림
BitTorrent
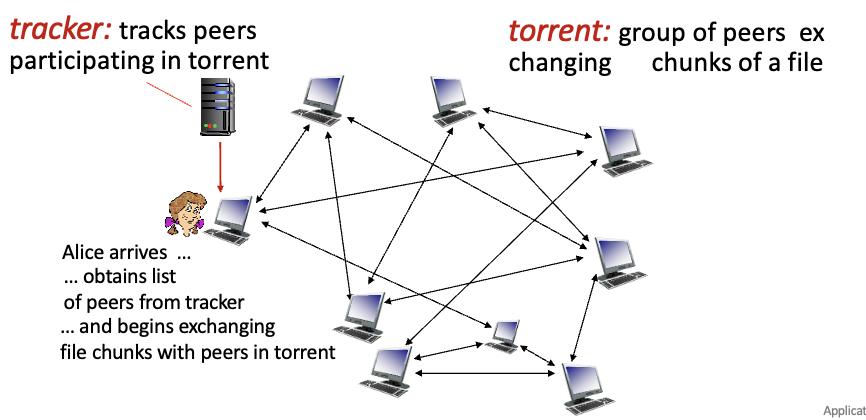
파일을 256kb의 청크로 나눠서 분배
Torrent : 파일 청크를 주고받는 것에 참여하는 peers들의 집합
tracker : 제어 정보를 가지고 있음. 파일 데이터를 갖고 있진 않으며, 파일 전송에도 참여하지 않음
peer가 torrent에 들어오게되면
- tracker에 등록
- peer들에 대한 리스트를 받음
→ 시간이 지나면서 peer들의 chunk를 받음 : 다운받으면서 자기것도 업로드
churn : peer들은 나갔다가 들어갔다 할 수 있음
모든 자료를 갖게되면, 나가던지(이기적) 머무르던지(이타적) 선택할 수 있음
Requesting chunks
peer들은 항상 각기 다른 정보들을 가지고 있음
주기적으로 어떤 chunks를 가지고 있는지 확인해야함
peer로 부터 없는 chunks를 받을땐, 희귀한걸 먼저 받는다
Sending chunks : tit-for-tat
현재 나에게 가장 빨리 청크를 보낼 수 있는 4명의 peer에게 청크를 받고 나도 보냄
→ chocked : 나머지 peers. 나에게 청크보냈는데 나는 보내지 않았을수도
4명의 피어는 10초마다 갱신
optimistically unchoke : 30초마다 랜덤하게 peer를 선택해서 chuck를 보내줌
→ 나에게 아무것도 주지 않았더라도 보내줄 수 있음
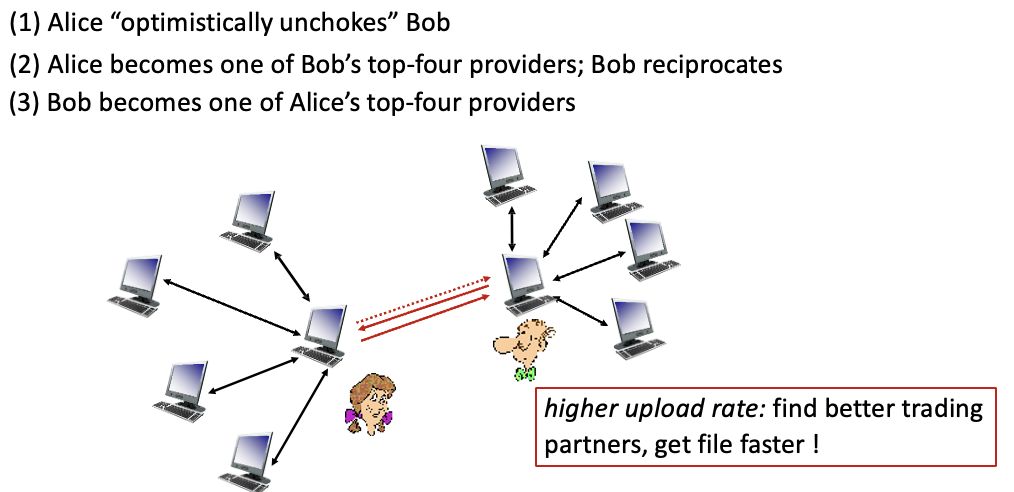
- 앨리스는 랜덤하게 bob에게 chunk보냄
- 그로 인해 앨리스는 bob의 top4 peer에 들게됨
- bob이 앨리스에게 chunk제공
📌 Video Streaming and CDN(Content Distribution Networks)
Stream video traffic : 인터넷 대역폭의 많은 부분 차지 → ex) 넷플, 유튜브등은 residential ISP 트래픽의 80% 차지
목표 : 최대한 많은 유저들에게 도달 + heterogeneity : 서로 다른 망을 가지고 있어도 꾸준히 서비스 제공해야함
→ 분산 + application-level 인프라구조
DASH : Dynamic, Adaptive Streaming over HTTP → 네트워크 상태에 맞는 화질 선택 가능
서버
- 비디오 파일을
여러개의 chunk로 나눔 - 각 chunk는 각각 다른 화질로 저장, 인코딩됨
- manifest file : 서버측에서 다른 chunk에 따른 URL을 제공 → 네트워크 속도에 따라 다르게 제공
클라이언트
- 서버-클라이언트 사이의
대역폭을 주기적으로 측정 - 현재 측정 대역폭에서 사용할 수 있는 가장 큰 데이터를 받음 → 시간마다 다를 수 있음
- 언제 요청할지, 어떤 chunk를 요청할 것인지, 어디에 있는 chunk를 요청할건지(가까운거 또는 높은 대역폭 가능한것)등을 client가 intelligence하게 결정할 수 있게해줌
Streaming Video = 인코딩 + DASH + playout buffering
CDN : Content distribution networks
Q. 어떻게 동시접속해있는 수많은 유저들에게 콘텐츠를 스트리밍할 것인가?
- 방법 1 : 하나의 거대한 mega server single point of failure 네트워크 혼잡 클라이언트와의 거리 멀어짐 같은 데이터가 대역폭 너무 많이 사용 → 확장성 X
- 방법 2 : 지역적으로 분산된 사이트를 두고 비디오의 복사본을 저장, serve → 이게
CDN- enter deep : 많은 access network에 CDN 서버를 둠 유저랑 가깝다 → 빠름 비용이 비싸서 잘 안씀
bring home: access network들 근처에 큰 클러스터를 둠. 개수는 많지 않음 느리지만 이거 많이 사용
- enter deep : 많은 access network에 CDN 서버를 둠 유저랑 가깝다 → 빠름 비용이 비싸서 잘 안씀
Ex) 유저가 Netflix에 Madmen 영화를 요청하면
→ 서버에서 manifest file을 줘서 어디있는지 찾음
→ 가까운 서버에서 선택되나 네트워크 혼잡시 다른 경로도 채택될 수 있음
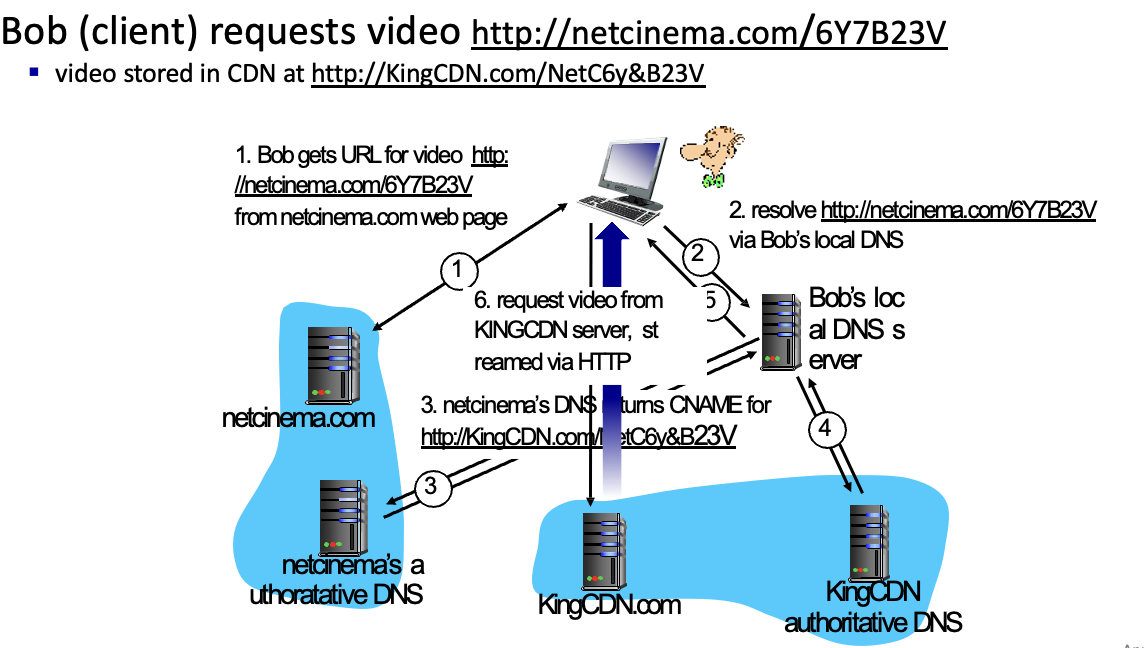
Bob(client)가 비디오 요청하는 예시
- bob이 비디오에 대한 URL 얻음
- Bob의 Local DNS에서 resolve 요청
- authoratitive DNS에서 실제 data의 CName(실제이름) 리턴받음
- 받은 내용을 토대로 IP주소를 받아서 실제 열고자하는 동영상 주소를 받음
- Bob한테 전달
- client가 해당 주소에 접속하여 비디오 받음
유튜브가 이런 방식
📌 socket programming with UDP and TCP
socket programming
socket : application 프로세서와 transport 프로토콜 사이의 문
socket 2 종류
- UDP : unreliable datagram(4계층에서는 segment이라고하는데 UDP에서는 datagram이라고도 한다), 속도 빠름
- TCP : reliable, 바이트 단위로 순서대로 전송
UDP를 이용한 socket programming
client와 server 사이의 연결 설정 없음
- handshaking 과정 없음(연결 설정하는 과정 없음)
- sender : IP주소와, 포트번호를 붙여서 보내야함
- receiver : 받은 패킷에서 sender의 IP 주소와 포트번호 추출해야함
전송되는 데이터는 손실될 수도 있고 정해진 순서도 없음
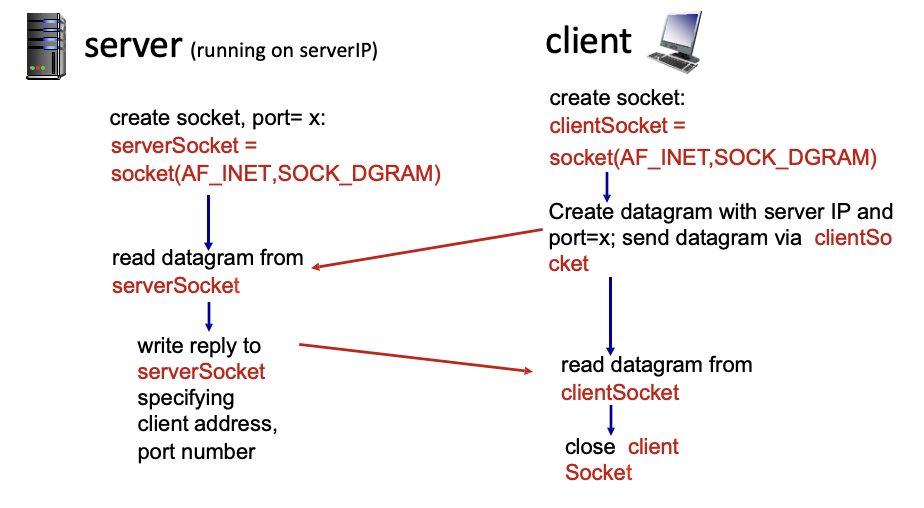
1s. 포트번호 설정 후 socket(인터넷용, 데이터그램 운반 가능한 소켓) 으로 소켓 만듦
1c. 동일하게 소켓 생성
2c. 서버 IP와 포트번호를 붙인 datagram 생성하고 client 소켓을 통해 전송
2s. server 소켓을 통해 datagram 받음
3s. client의 IP주소, port 번호를 추출하고 요청한 작업을 해서 다시 보내줌
3c. client 소켓을 통해 datagram 받음
4c. client 소켓 닫음
TCP를 이용한 socket programming
Client가 서버에 먼저 연결 설정을 해야함 → 서버가 우선 작동하고 소켓 만들어야함(UDP도 동일)
먼저 Welcome socket으로 연결을하고
연결된 후에는 서버에서 새로운 socket을 만들어서 공유함
서버가 여러명을 클라이언트와 연결 가능
TCP이므로 순서대로 받게되며 손실시 재전송
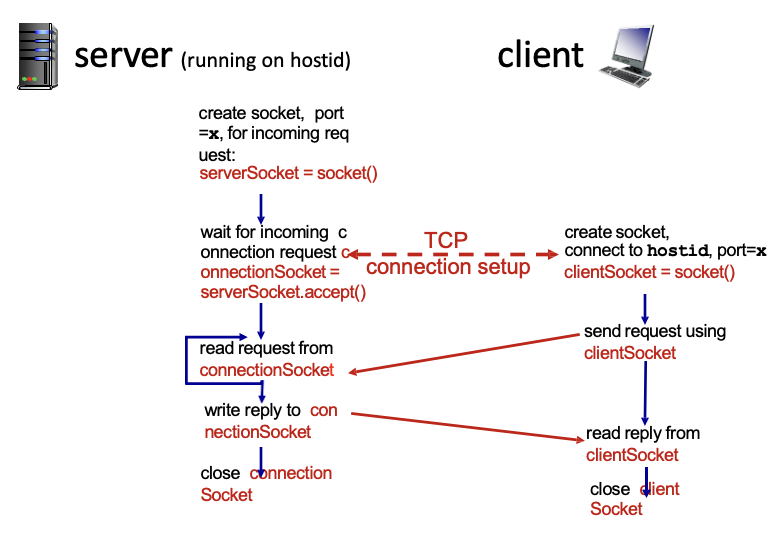
1s. 포트번호 설정 및 소켓 생성
2s. 연결 요청이 들어올때까지 기다리다가 요청오면 연결
1c. 소켓 만들고 서버에 연결 요청 // 여기까지가 handshaking
2c. 서버에 요청 전달
3s. 새로운 소켓 만든 후 요청 받음
이후 UDP와 동일…
