
📌 Transport layer services
서로 다른 host에서 실행중인 process끼리의 통신을 지원하는 것이 목표
sender : application 메세지를 segment로 잘라서 3계층으로 넘김
receiver : segment에서 헤더를 떼고 5계층으로 올려줌
2가지 프로토콜 지원 : TCP, UDP
Ex)
Ann’s house의 12명의 아이들이 Bill’s house의 12명의 아이들에게 편지를 보냄
application mesage : 봉투 속의 편지
process : 아이들
host : 집
transport layer 4계층 : Ann and Bill
network layer 3계층 : 우체국 서비스
즉 3계층은 host간의 통신, 4계층은 process간의 통신(3계층에 의존적)

Sender : 5계층에서 받은 message에 헤더를 붙여서 segment로 만들고 3계층으로 전달
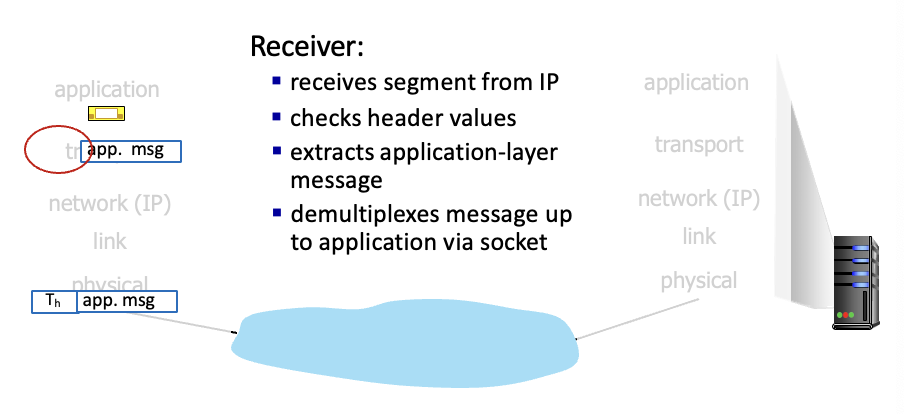
Receiver : 3계층에서 받은 segment에서 헤더를 체크하고 맞으면 추출해서 5계층으로 올려보냄
| TCP | UDP |
|---|---|
| reliable, 순서있음 | reliable, 순서없음 |
| 혼잡, 흐름, 통제 O | 혼잡, 흐름, 통제 X |
| 연결 설정 O | 연결 설정 X |
| best effort → 최선을 다한다는 뜻. 근데 안되도 어쩔 수 없다 |
📌 Multiplexing and demultiplexing
서버는 client를 구별해야하는가?
Multiplexing 다중화 : 여러 프로세스들의 데이터가 소켓을 통해 4계층으로 내려올때, 4계층의 헤더를 붙여서 캡슐화시키는 것
Demultiplexing 역다중화 : 3계층으로부터 받은 segement의 헤더 정보를 확인하여(IP, port 번호 등) 맞는 소켓으로 보내 5계층으로 전달하는 방법
3계층의 datagram에는 source, 목적지 IP 주소가 있음 → 4계층으로 전달
4계층의 각 segment는 source, 목적지의 port number이 있음
소켓이 만들어질때 IP, port를 bind
Connectionless demultiplexing
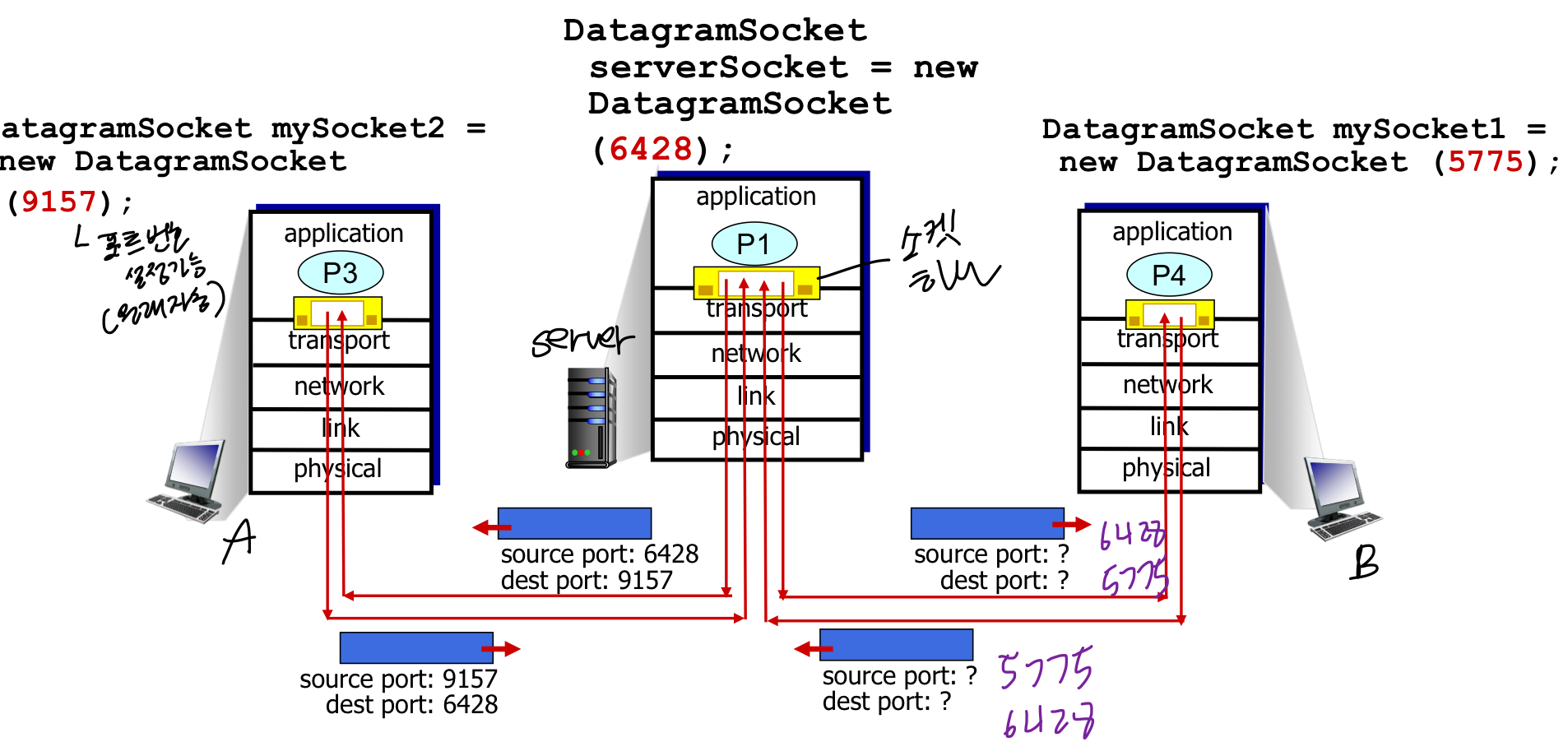
UDPsocket으로 보낼 datagram 만들 때 →목적지 IP 주소, port 주소중요 → 연결 설정하지 않으므로 source 쪽은 크게 중요하지 않음
- UDP segment를 받을때 → 목적지 port 번호를 식별하여 올바른 소켓에게 보내줌 목적지가 같지만 source가 다른 데이터는 같은 소켓으로 들어가게됨
Connection-oriented demultiplexing
TCP 소켓은 4가지 정보로 확인 : source IP, port, dest IP, port
receiver : 소켓에 연결하기 위해 받은 데이터의 4가지 정보를 모두 보고 다르면 다른 소켓으로 감
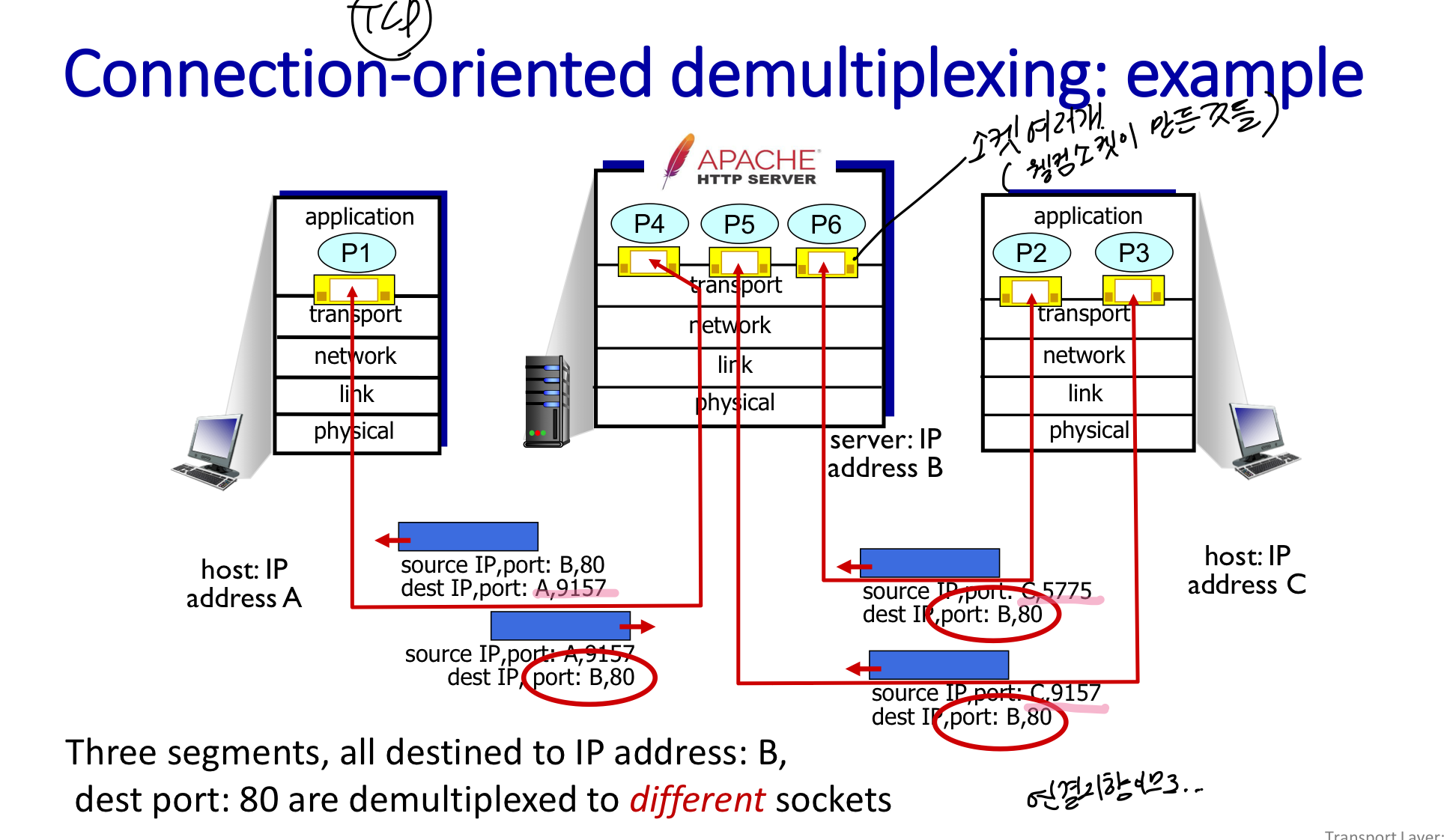
TCP는 소켓이 여러개 → IP,port 중 하나라도 다르면 다른 소켓으로 → 연결 지향이므로
📌 UDP : Connectionless transport
UDP : User Datagram Protocol
“no frills”, “bare bones”라고 함
“best effort” → 손실 가능, 순서 없음
연결 설정 없음 : handshaking 없음, 각 UDP segment는 독립적
UDP를 사용하는 이유
- 연결 설정이 없음 → RTT 시간 줄일 수 있음
- 간단함
- 헤더 사이즈가 더 작음
- congestion control 없음
UDP를 사용하는 곳 : 스트리밍 앱(손실 ㄱㅊ, 속도가 중요), DNS, SNMP, HTTP/3
만약 UDP에서 신뢰성 등을 추가하고 싶으면 application layer에서 추가해주면됨
→ ex) HTTP/3 : UDP 기반 + 필요한건 5계층에서 추가적으로
Sender : 5계층에서 내려온 msg받음. 헤더를 붙여 UDP segment 생성. IP를 통해 segment 전송
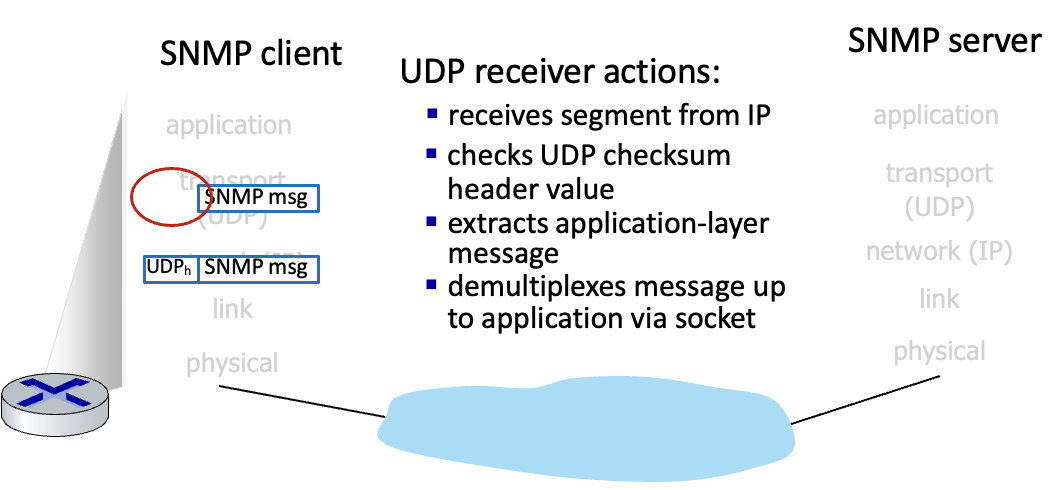
receiver : IP를 통해 segment 받음. UDP checksum 헤더 확인. 5계층 msg 추출. 소켓을 통해 디멀티플렉싱
UDP segment header
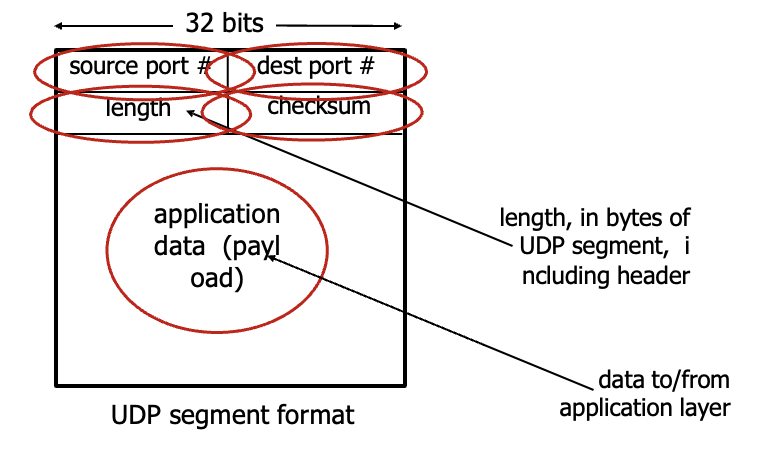
위의 4개가 UDP 헤더고 아래는 기존 내용(메세지 자체)
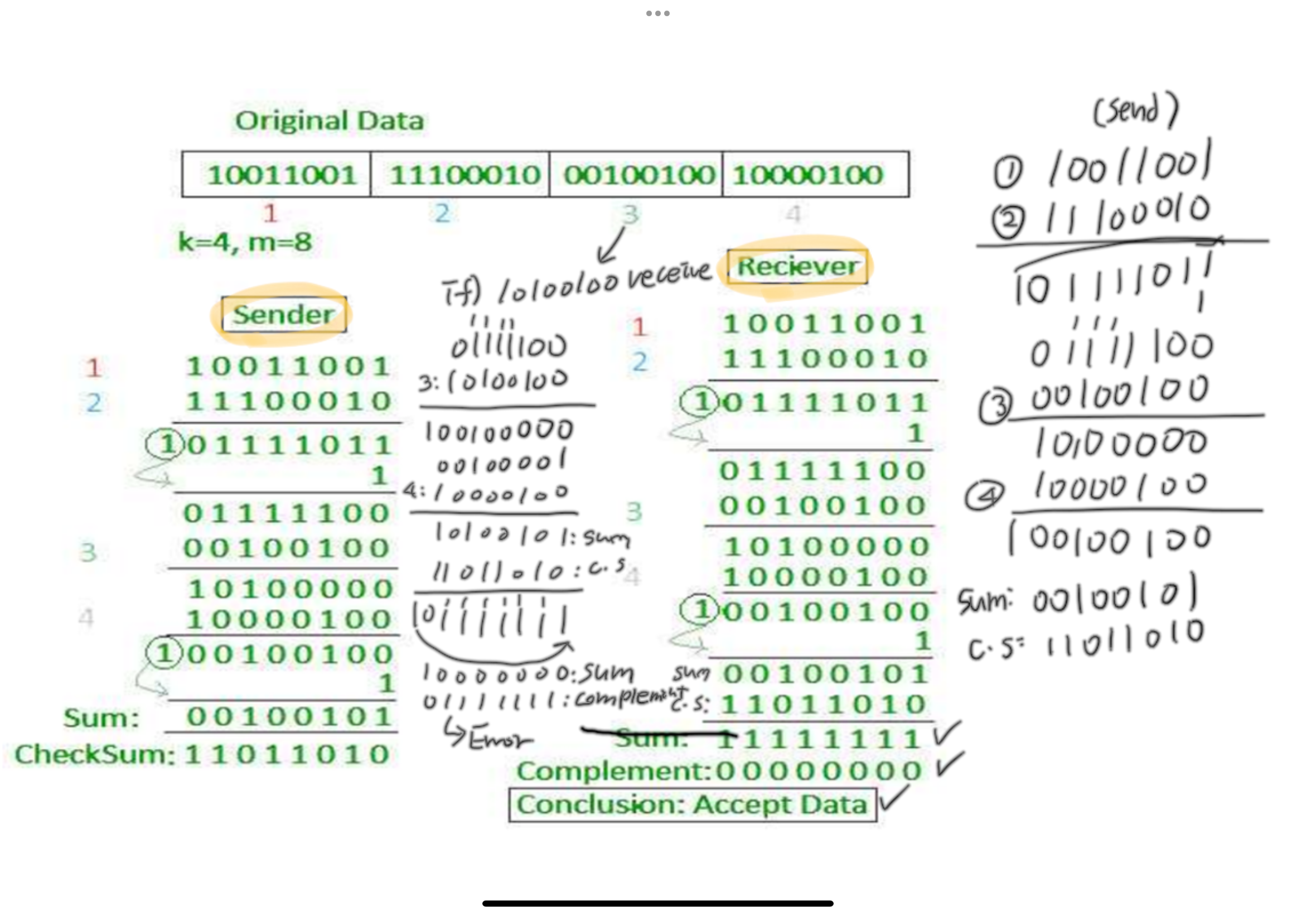
UDP checksum
전송받은 segment에 에러가 있는지 감지함
sender : 1의 보수 방법으로 checksum 만듬
receiver : 받은 segment의 checksum 검사
- 일치하지 않음 : 에러 감지
- 일치 : 에러 감지되지 않음. 그러나 없다고 보장은 X

내용을 16비트로 자른 후 더함 → 넘친거는 다시 앞에다가 더해줌 → 1의 보수 취해주기 : 모든 값들을 다 반대로 뒤집어주기

하지만 모든 에러를 다 잡을 수 있는 것은 아님
예를 들어 위와같이 비트에 에러가 생길 경우에는 체크섬에 변화가 없으므로 에러 탐지 불가
예시
📌 Principles of reliable data transfer
RDT - Reliable Data Transfer : 신뢰성있는 데이터 전송
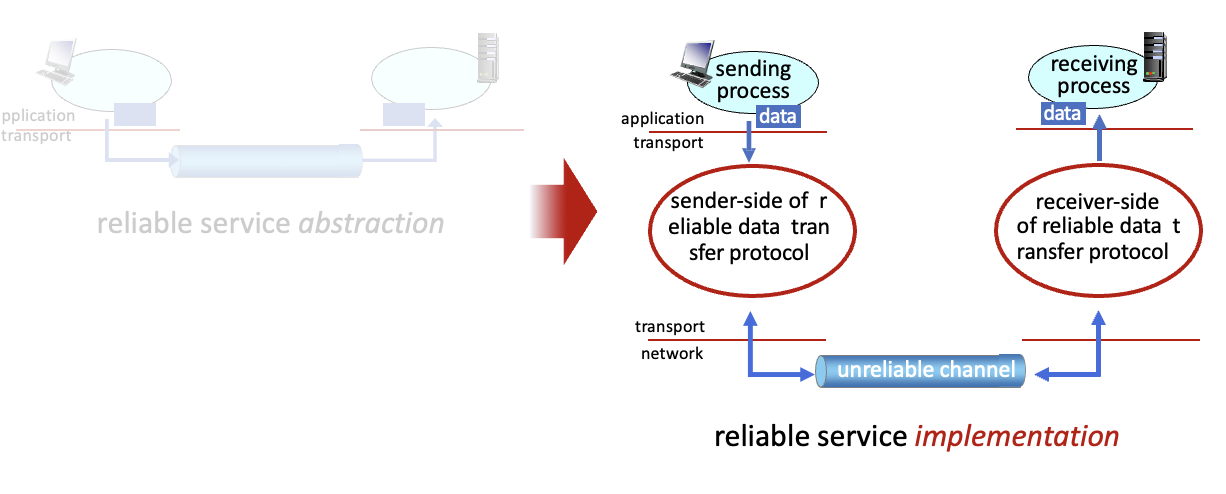
reliable한 전송을 하려면 아래 계층도 reliable해야함 → 그러나 IP는 reliable하지 않음
Sender와 receiver는 서로의 상태를 알 수 없음.
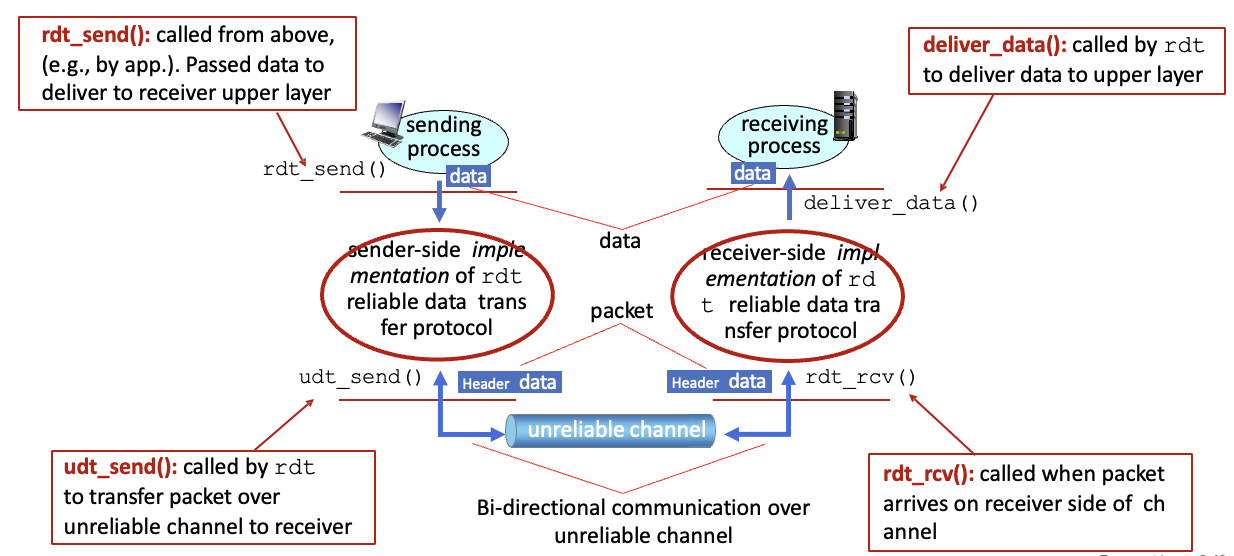
RDT : Reliable Data Transfer → 신뢰적 데이터 전송
UDT : Unreliable Data Tranfer → 비신뢰적 데이터 전송
rdt_send() : 상위 계층에서 호출됨(5계층 앱 등에서)
ude_send() : 신뢰할 수 없는 하위 계층으로 데이터 전송시
rdt_rcv() : 패킷받았을 때 4계층에 알려줌
deliver_data() : 5계층에게 넘겨줌
RDT : Reliable Data Transfer
데이터는 단방향으로 흐르고 제어는 양방향 가능하다고 가정
RDT 1.0 : reliable transfer over a reliable channel
신뢰성 있는 채널에서의 신뢰성 있는 전송 → channel, 3계층이 완벽하다고 가정하는 것
- 비트 에러 없음
- 패킷 loss 없음

rdt_send(data) : 5 → 4
packet = make_pkt(data) : 5계층에서 받은 message + header로 패킷 생성
udt_send(packet) : 4 → 3 패킷 보냄
rdt_rcv(packet) : 패킷 받음 3 → 4
extract(packet, data) : 4계층. 패킷에서 데이터 추출
deliver_data(data) : 4 → 5 데이터 보냄
RDT 2.0 : Channel with bit errors
channel에서 bit error는 있을 것이라고 가정 → checksum 이용
flip bits : 비트 바뀌는 에러
acknowledgements (ACKs) : 데이터 잘 받았다는 응답
negative acknowledgements (NAKs) : 데이터에 에러있다는 응답 → sender는 패킷 재전송
stop and wait : 송신자가 패킷 하나를 보내고 수신자로부터의 응답을 기다리는 방식 → 서로의 상태를 알 수 없으므로
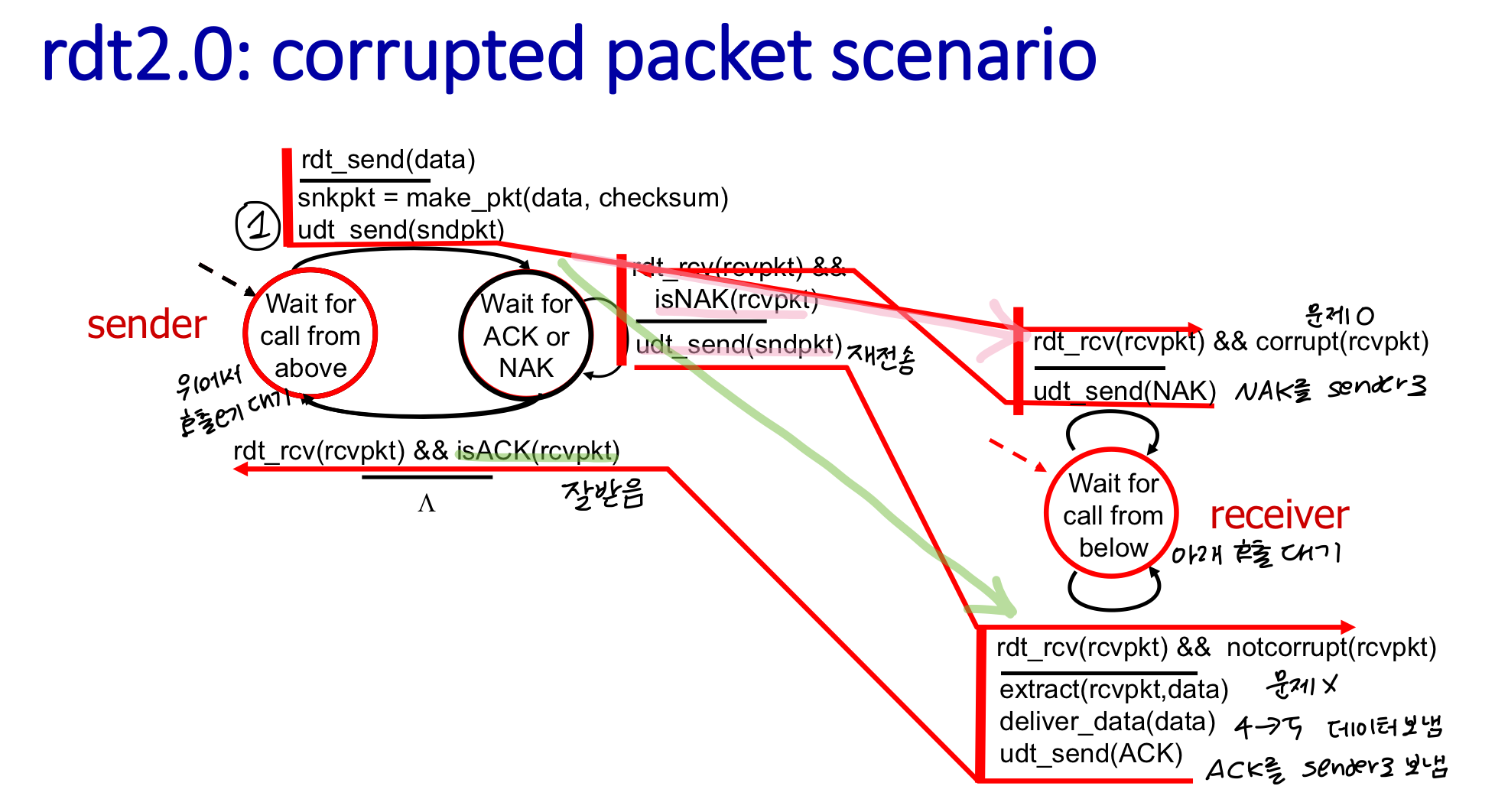
sender가 패킷 전송
→ receiver가 패킷 받음 && 손상 O : NAK응답 보냄 → sender는 재전송
→receiver가 패킷 받음 && 손상 X : 문제 없음. 데이터 5계층으로 올리고 ACK응답 보냄
rdt 2.1 : sender, handling garbled ACK/NAKs
하지만 rdt2.0에도 문제점이 있음 : ACK/NAK도 손상이 가능하다
→ 그냥 재전송해줄수도 없음. 한번에 하나씩만 데이터 처리하므로
→ sender가 보내는 패킷에 sequence number 부여
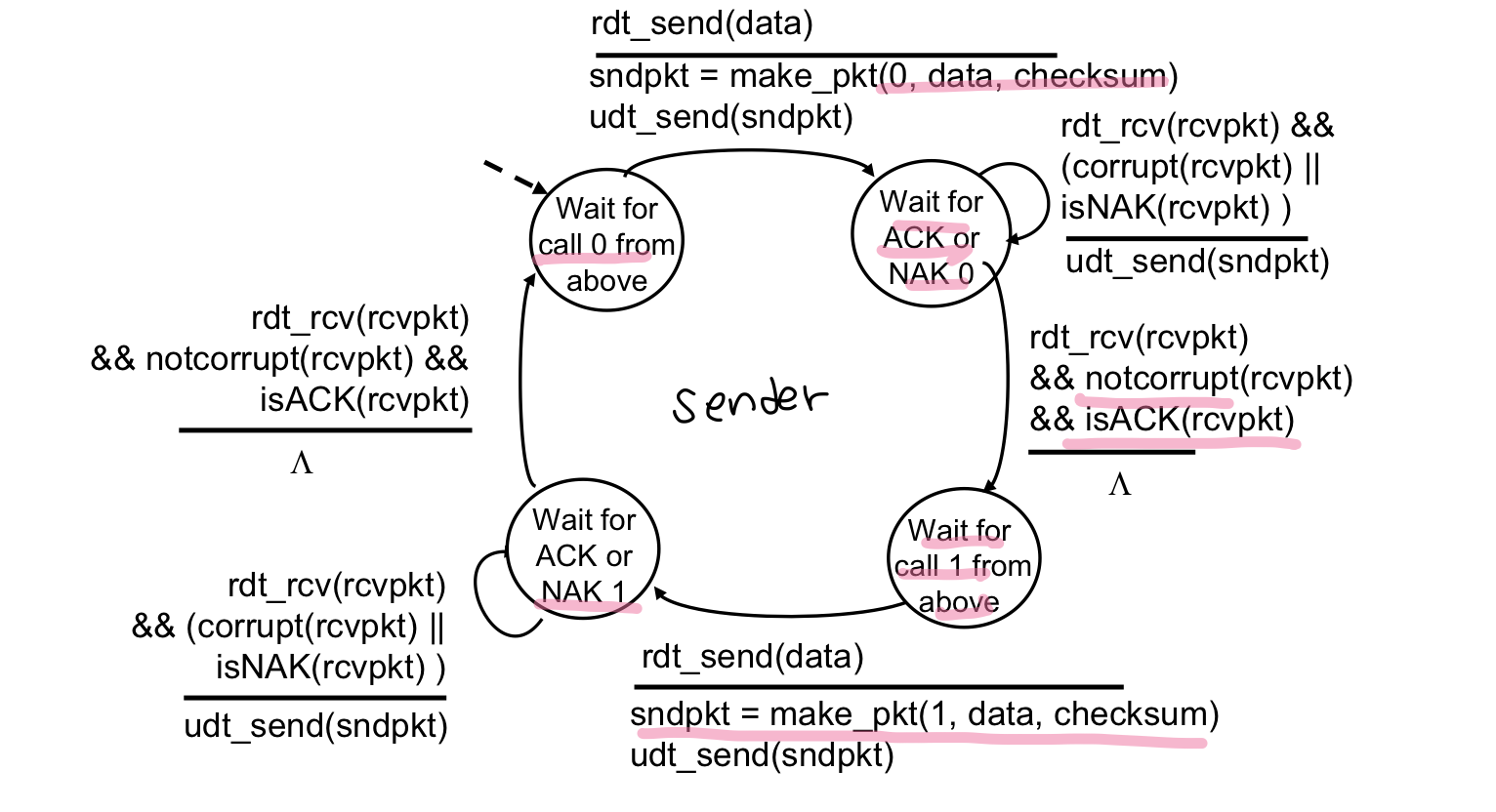
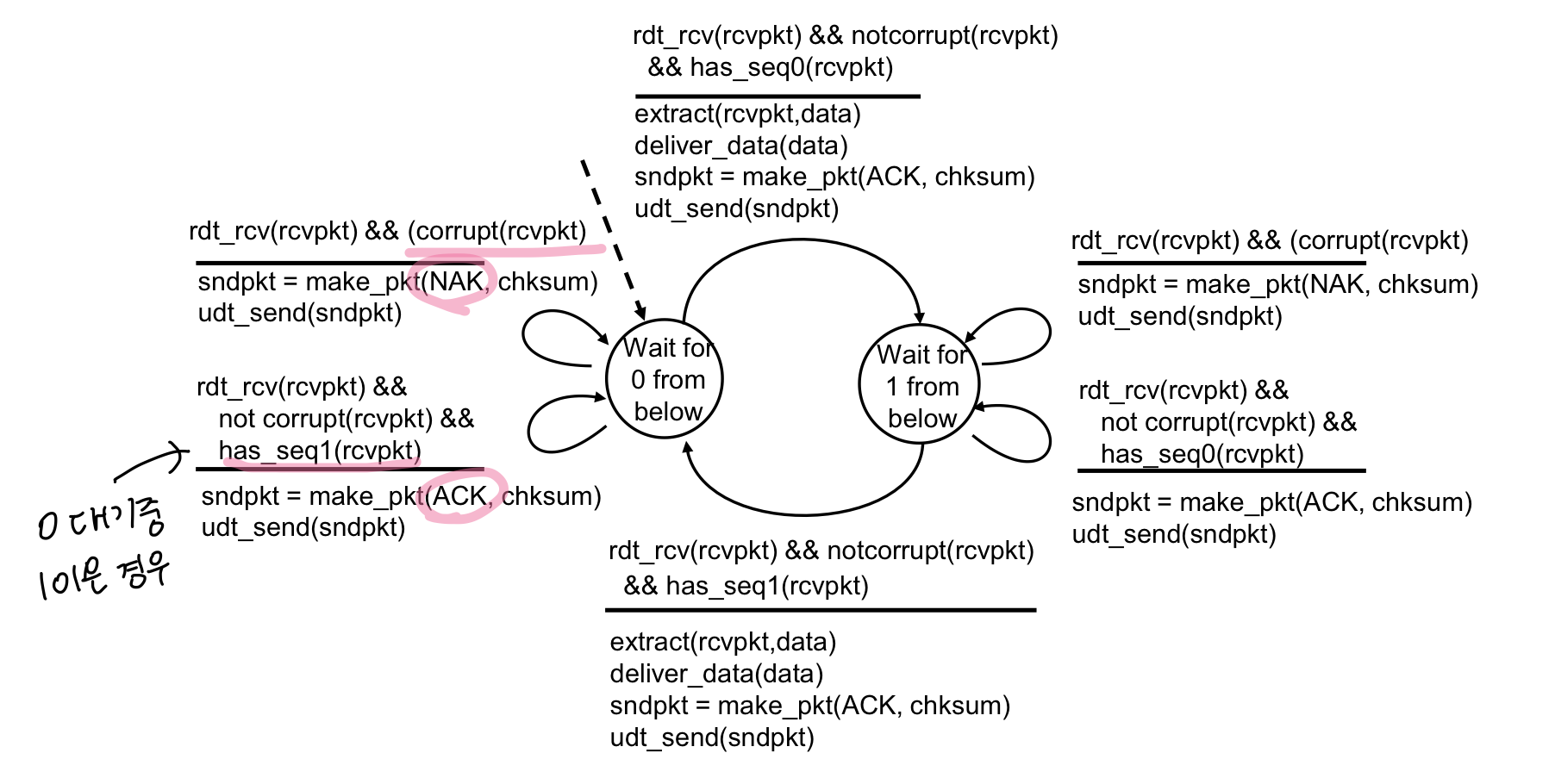
sender : 0번 패킷을 보내고
- NAK이 들어오면 패킷 재전송하고
- ACK이면 1번 패킷만들러 이동
receiver : 0번 패킷 대기중
- corrupt 데이터 받으면 → NAK보냄
- 0번 대기중인데 1번 패킷 데이터 받음 → ACK을 제대로 못받았다고 판단하고 ACK 다시보냄
- 제대로 잘 받았으면 → 1번 패킷 대기하러 이동
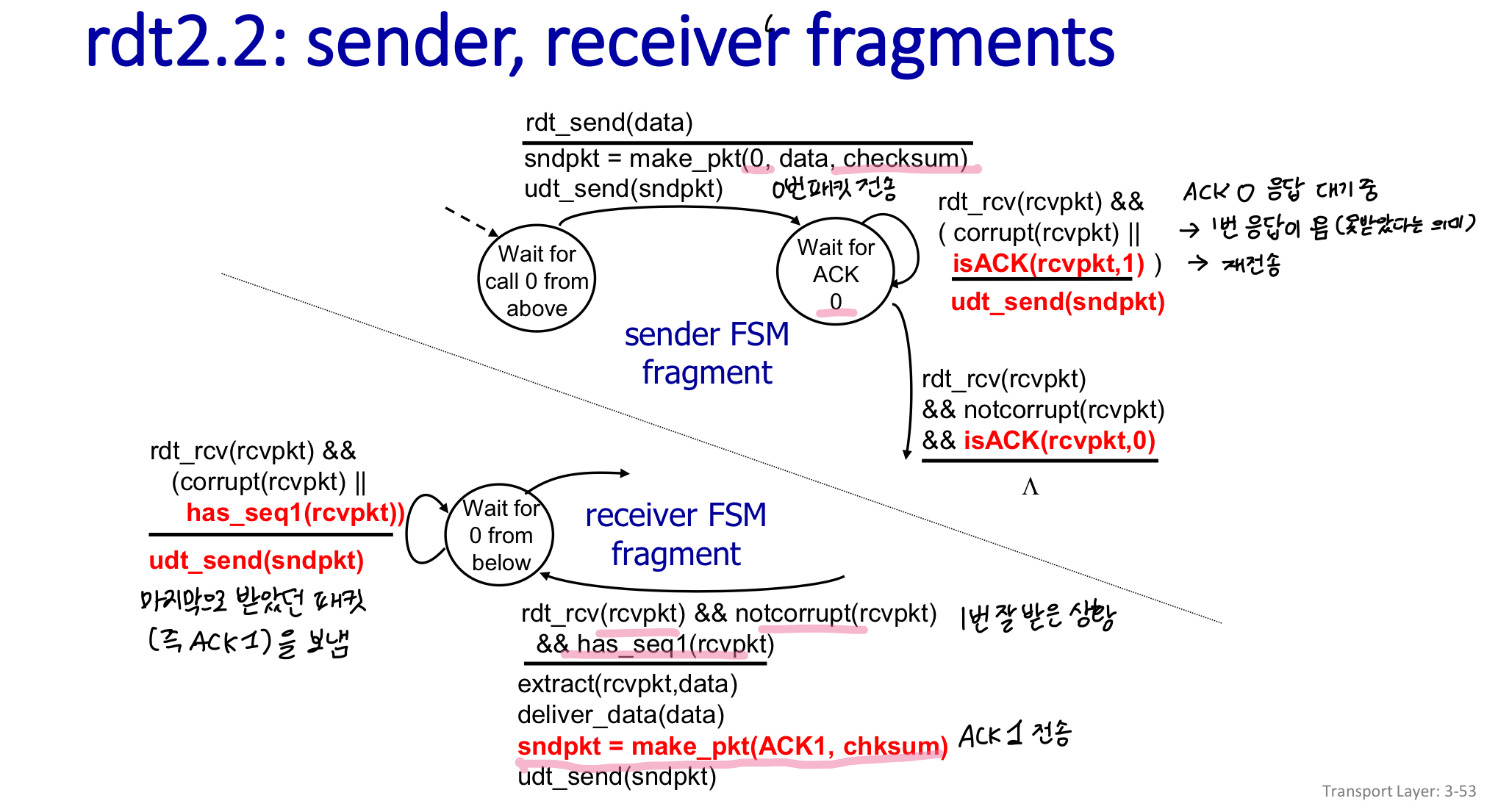
rdt 2.2 : a NAK-free protocol
2.1과 동일한데 ACKs만 사용
NAK을 보내는 대신, receiver는 마지막으로 받은 패킷의 번호를 보냄 → sender가 마지막으로 보낸 패킷의 번호와 일치하지 않으면, 제대로 안갔구나 하고 재전송해주는 것
TCP는 NAK-free
rdt 3.0 : channels with errors and loss
채널에서 에러뿐만 아니라 loss도 발생 가능
sender는 ACK를 “reasonable”한 시간만큼만 기다림
→ 만약 그 시간안에 응답이 오지 않는다면 재전송 해줌
→ loss가 아니라 그냥 delay라 응답이 오지 않았었을수도 있음 : 그런 경우에는 sequence number로 해결
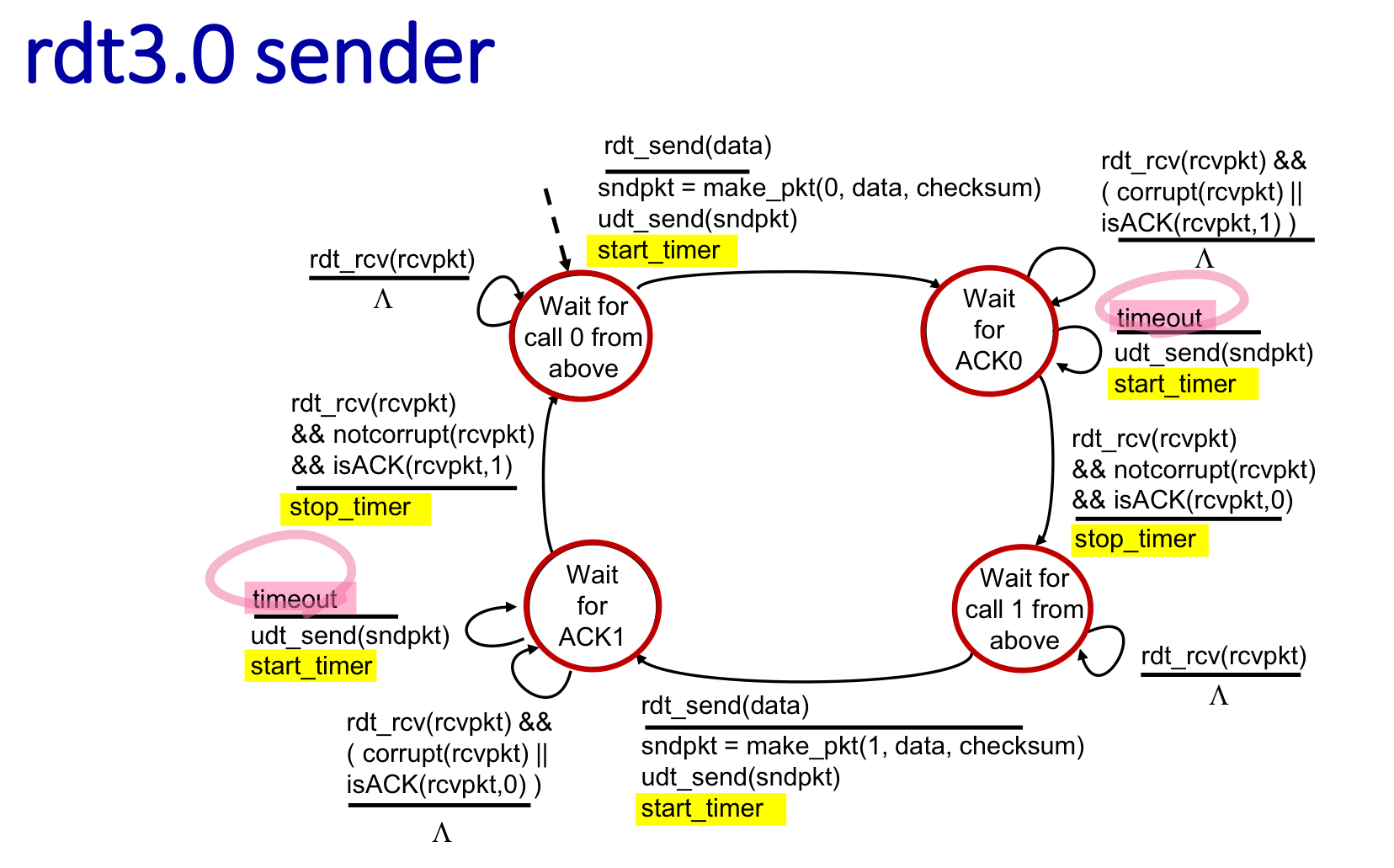
sender : 0번 패킷을 보내고 시작타이머 설정
- 0번 대기중인데 1번 응답옴 : 2.2와는 다르게 그냥 무시 → 어차피 타임아웃되면 재전송
- 타임아웃 (아무응답 안옴) : 패킷 재전송
- ACK 0가 제대로 돌아옴 : 타이머 종료
3.0에서 가능한 액션 4종류
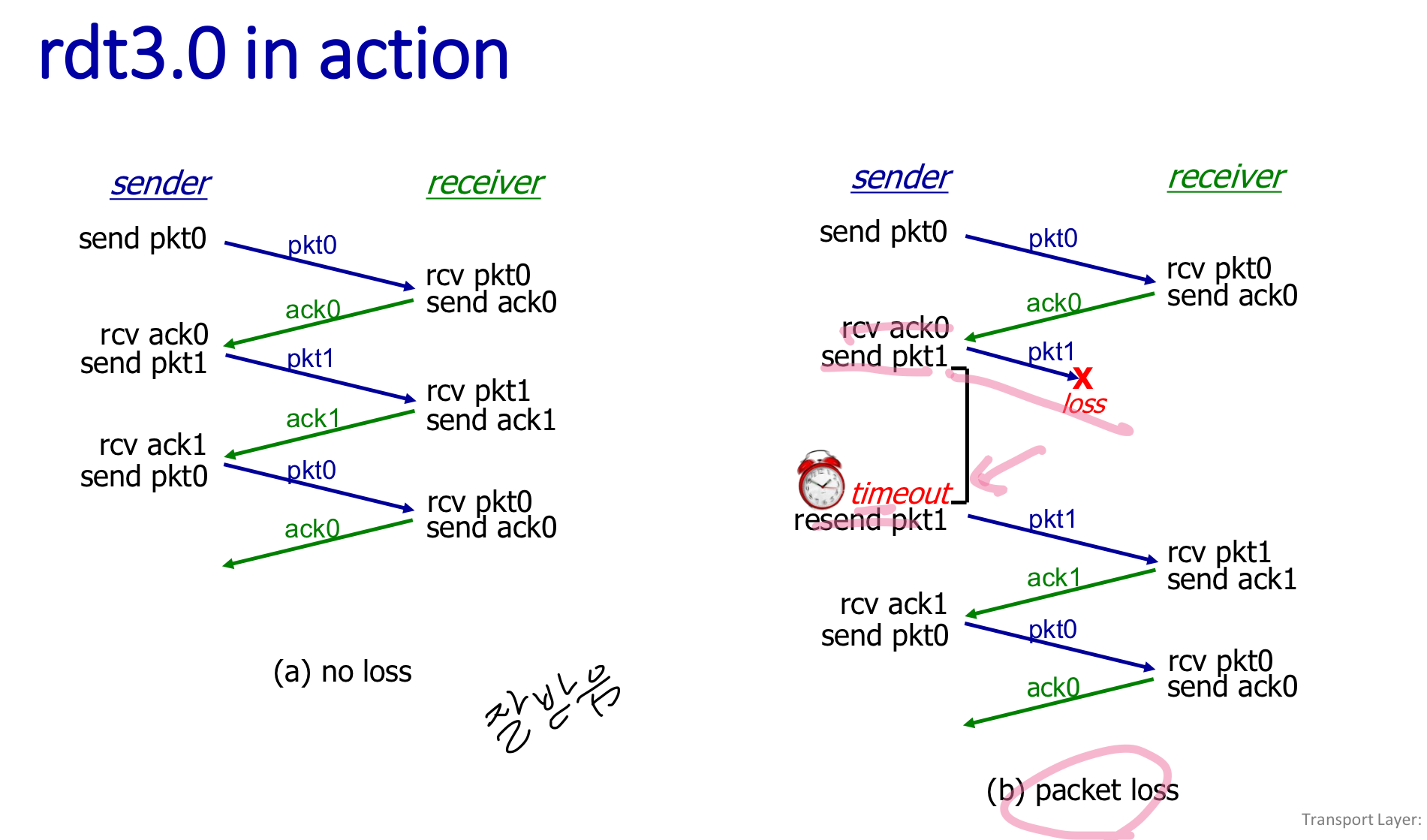
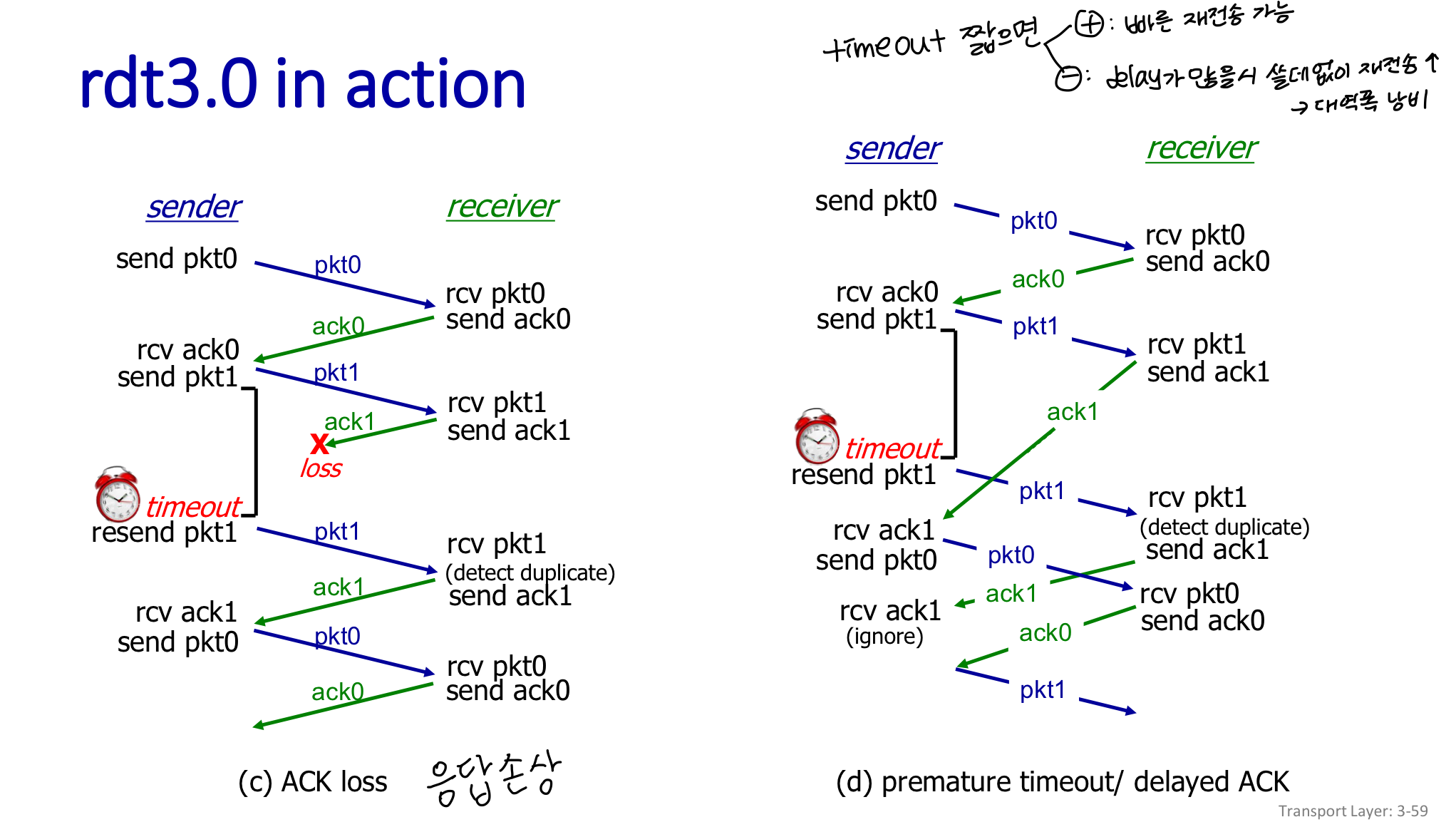
- 정상적으로 주고받는 경우
- 패킷이 loss 되어서 응답이 안돌아옴 : time out → 재전송
- 응답을 보냈는데 loss된 경우 : time out → 재전송
- 응답을 보냈지만 delay때문에 이미 time out 된 경우 : 1을 받았다는 것을 안 순간 0번 패킷을 전송. 중복된 것들은 그냥 무시됨
timer 짧게 하면 빠른 재전송이 가능하나, 딜레이가 많을 경우 쓸데없이 재전송하느라 대역폭 낭비할 수 있음
Performance of rdt 3.0
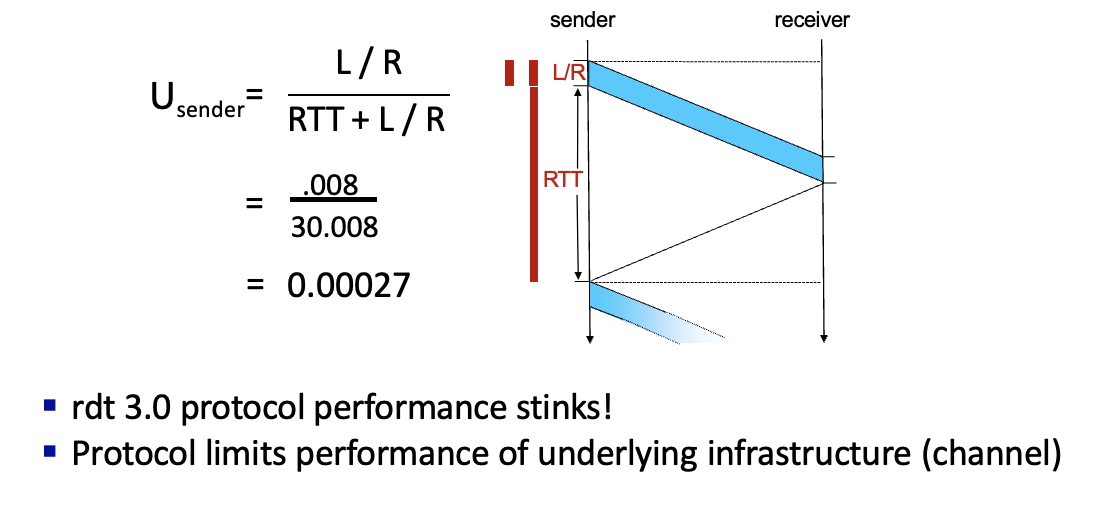
stop-and-wait 사용시 시간이 너무 오래걸림
한번갔다 올때 걸리는 시간이 RTT + L/R transmission delay
utilization이 너무 안좋음 → pipelining 사용
rdt 3.0 : pipelined protocls operations
pipelining : 한번에 하나가 아닌 여러개씩 패킷 주고받는 방식
- sequence number의 범위가 증가해야함 → 원래는 0,1
- 버퍼가 필요해짐
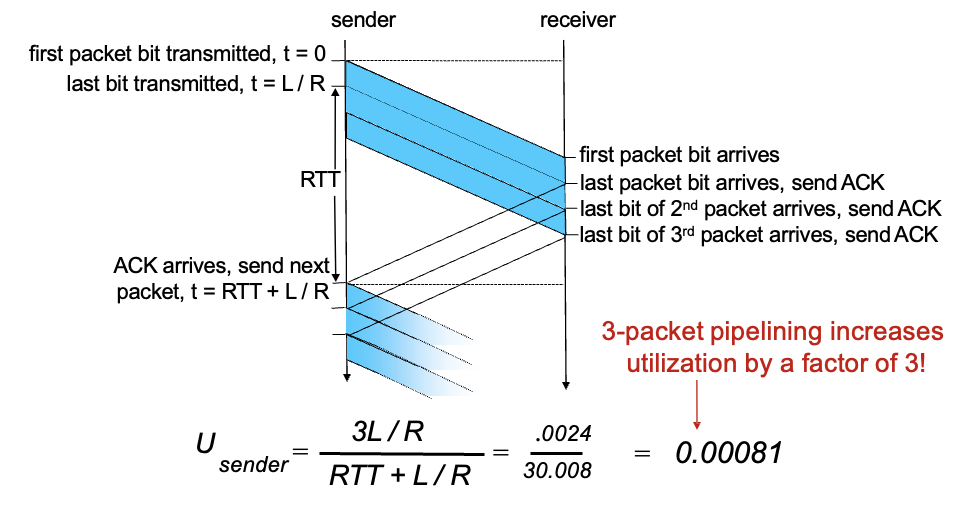
utilization이 크게 증가
Go-Back-N
sender
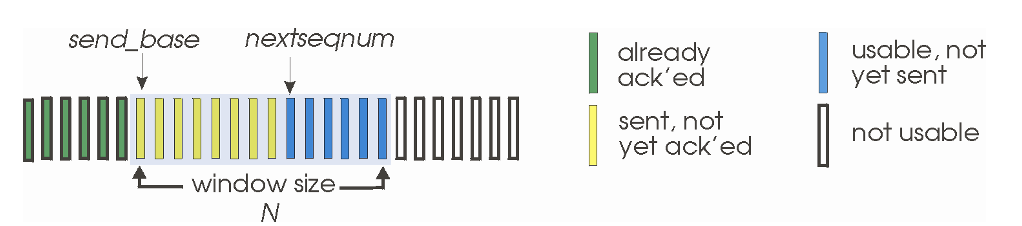
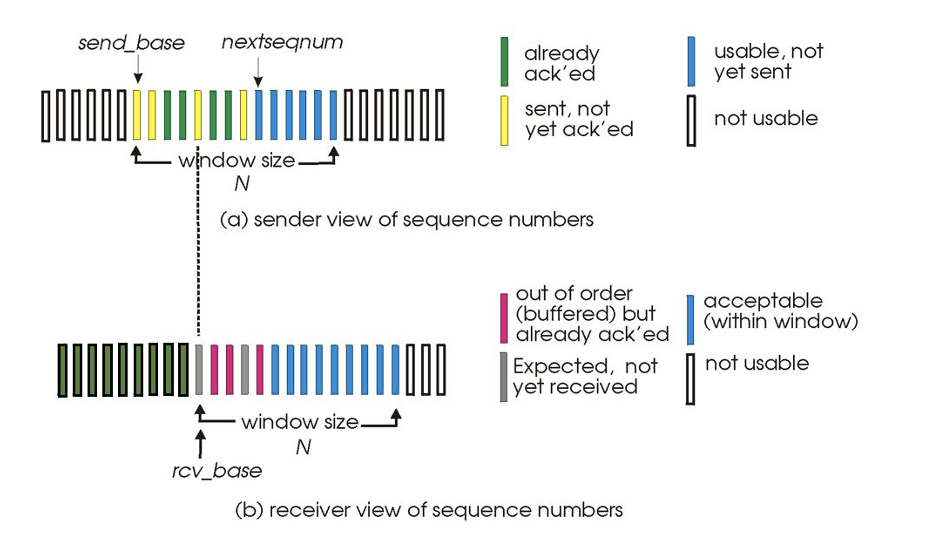
window : ACK가 없을때 최대로 보낼 수 있는 사이즈 N으로 지정
상태 4가지
- 초록색 : 이미 ACK받음 → 잘 보내고 저쪽에서도 잘 받음
- 노란색 : 보냈으나 아직 ACK는 못받음
- 파란색 : 보낼수있으나 아직 안보냄
- 흰색 : 아직 못보냄
cumulative ACK : ACK(n) → n번 ACK까지 모두 잘 받았다는 뜻 → 윈도우를 n+1로 밀음
타이머는 가장 오래전에 보낸 패킷에 대해서만 맞춤
timeout(n) : n번을 포함해서 그 뒤의 패킷들 다 재전송
receiver
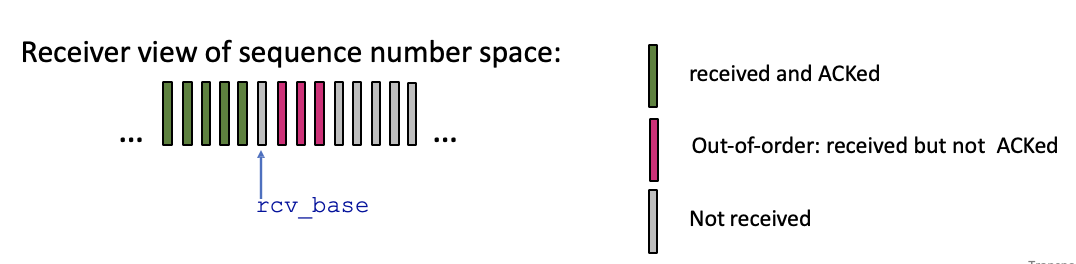
제대로 온 패킷에 대해서면 ACK 보내는데 무조건 순서대로
→ 자기보다 작은 숫자가 패킷을 못받아서 ACK를 못보냈다면 그보다 큰 숫자들은 패킷 받아도 ACK못보냄
위 그림에서 핑크색은 패킷 받았지만 ACK 못 보낸것 : 버려짐
rcv_base는 마지막 초록색 부분으로 돌아오게되고 그 이후 것들은 어차피 다 버려지고 다시 받아야됨
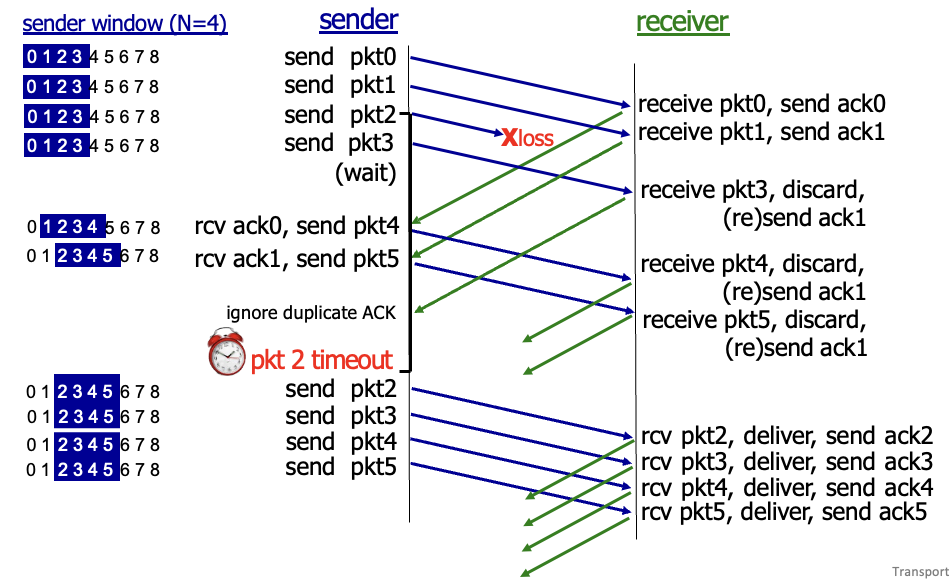
0,1번 패킷은 ACK받았으므로 window 밀음
→ 2번 패킷이 loss된 상황
→ receiver측에서는 그 이후로 도착하는 패킷들 다 버려짐
→ 2번에 대해서 timeout되고 window의 시작점인 2번부터 다시 전송
Selective repeat
모든 패킷에 대해 개별적으로 체크해줌
sender는 ACK되지 않은 패킷에 대해 개별적으로 타임아웃/재전송
send_base앞에는 초록색이라고 보면됨. 잘못칠해진거
이미 ACK된거랑 ACK안된거랑 섞여있는 상태
window 시작점은 ACK못받은 패킷으로 유지중
Sender
- 위의 계층으로 부터 데이터 받음 : 만약 window에 남은 자리가 있다면 패킷 보냄
- 타임아웃 : 재전송
- sender 윈도우내의 범위의 ACK가 왔을때 받았다고 표시해줌(초록색) 만약 그게 윈도우 내에서 가장 작은 숫자의 패킷이였다면(노란색) 초록색 칠하고 오른쪽으로 한칸 밀음
receiver
- receiver 윈도우 범위 내의 패킷 도착 → ACK보냄 만약 이게 순서가 안맞으면 일단
버퍼에 저장해놓음 순서가 맞다면 버퍼에 있는 애들까지 한번에 다 상위계층으로 보내고 윈도우 이동
- 전 윈도우 범위에 포함되었던 패킷 도착 : ACK만 다시 보내줌
- 이외 : 무시
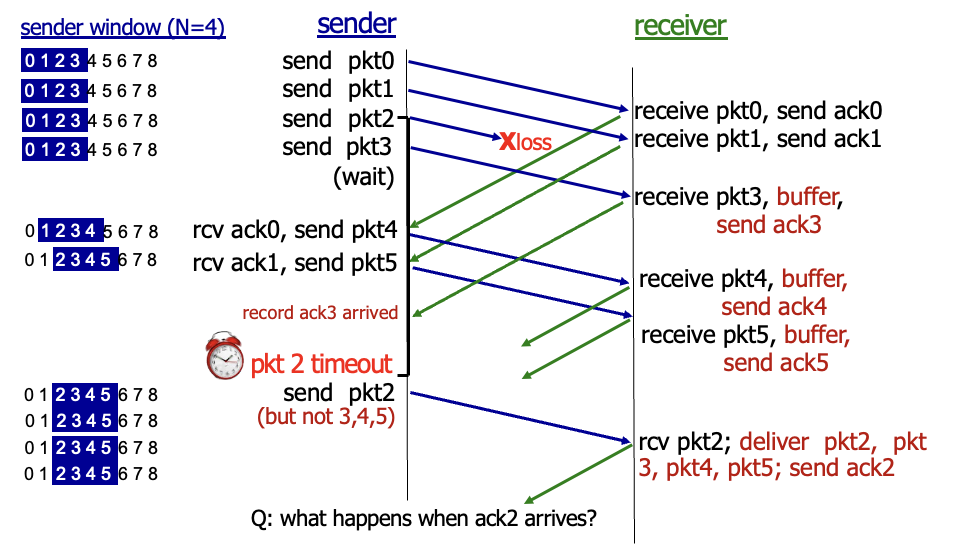
2번 패킷 loss 상황
→ 0,1번 제대로 가고 ACK도 받았으므로 window 밀리고 패킷도 추가로 보냄
→ 지금 2번에서 loss 났으므로 그 후에 간 패킷들 다 버퍼에 저장되는 중. ACK는 보내지만 상위계층으로 전달하진 않음
→ 2번 타임 아웃 : 2번만! 재전송
→ receiver는 2번 받고 버퍼에 있던 애들까지 다 5계층으로 전달. ACK도 보냄
문제점
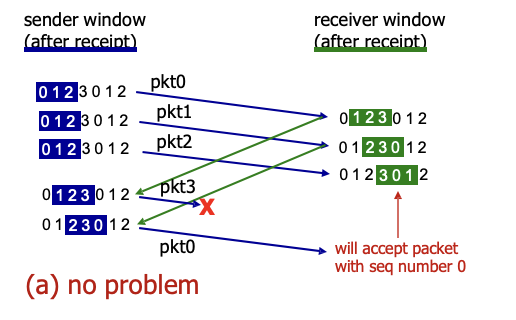
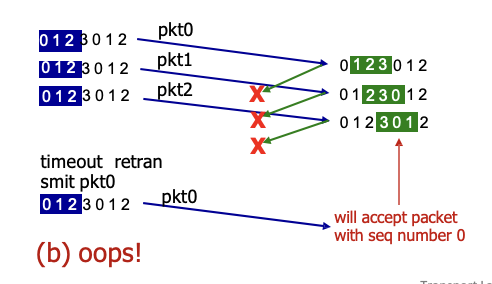
receiver 측에서는 ACK를 보내고 자신의 window 밀음
오른쪽에서 ACK가 loss된 상황인데 다시 보내는 패킷이 윈도우에 있어서 문제가 생김
이런 경우에는 window 크기는 사용하는 sequence number / 2 이하여야됨
📌 Connection-oriented transport : TCP
TCP
point-to-point: 하나의 수신자(IP, port) - 하나의 송신자(IP, port)끼리 통신reliable,순서대로- full duplex data : 양방향 통신
- cumulative ACKs : n번 이전의 ACK들 잘 받은것을 보장
- pipelining : window size로 congesion and flow control
- 연결 지향적 : handshaking
- flow controlled : sender는 receiver가 너무 많이 받지 않도록 조절
TCP segment structure
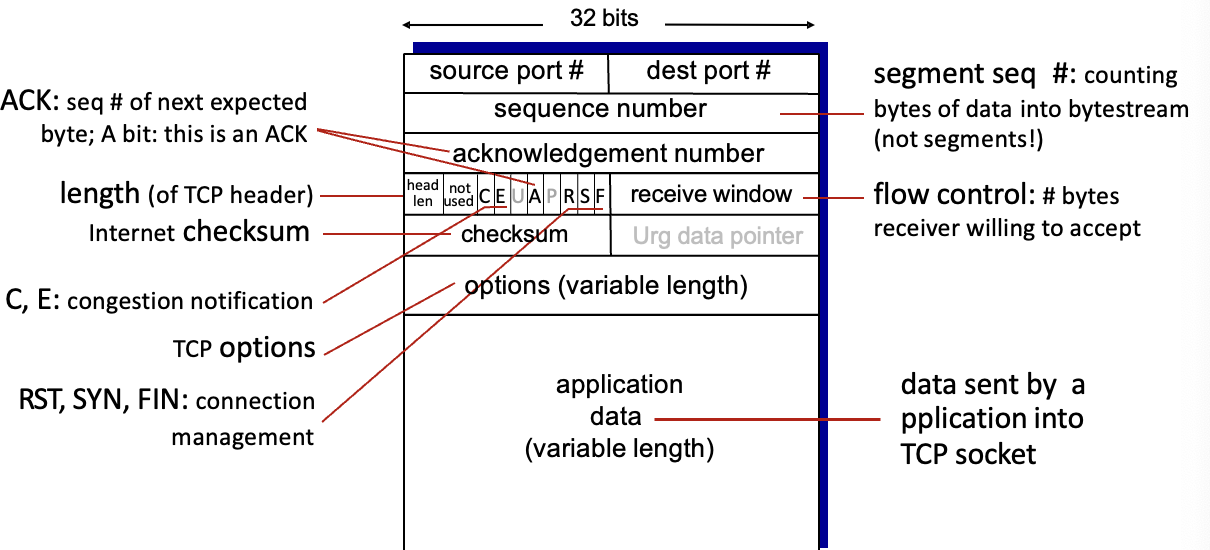
source, 목적지의 port번호
sequence number
ACK num : ACK(3)이면 2번까지 받았으니 3번을 보내라는 의미 → 위에서는 3까지 받았다는 의미였음
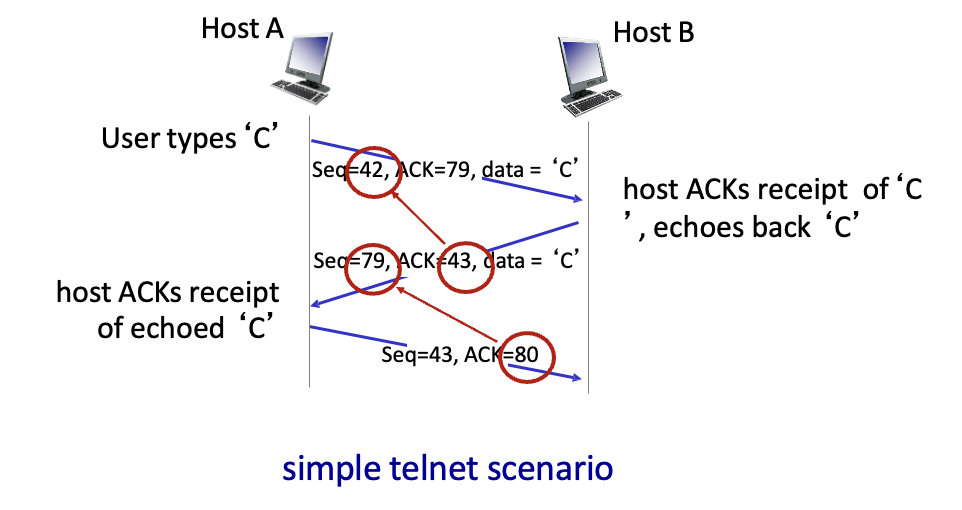
host A : 42번 보냈다. 79번을 보내라는 의미
host B : 79번 보냈다. 43번 보내라는 의미
데이터와 ACK을 한 segment에 담아서 보내는 방식 → piggy bag
TCP round trip time, timeout
어떻게 TCP의 timeout 설정할지 : RTT보단 조금 더 길게
- 너무 짧으면 : 필요없는 재전송 많아짐
- 너무 길면 : loss에 대해서 응답 느려짐
RTT어떻게 측정할건지? → SampleRTT : 실제측정값. 재전송 무시
EstimatedRTT : SampleRTT를 부드럽게 평균정도로 만듦 → 아래 그림에서 보라색
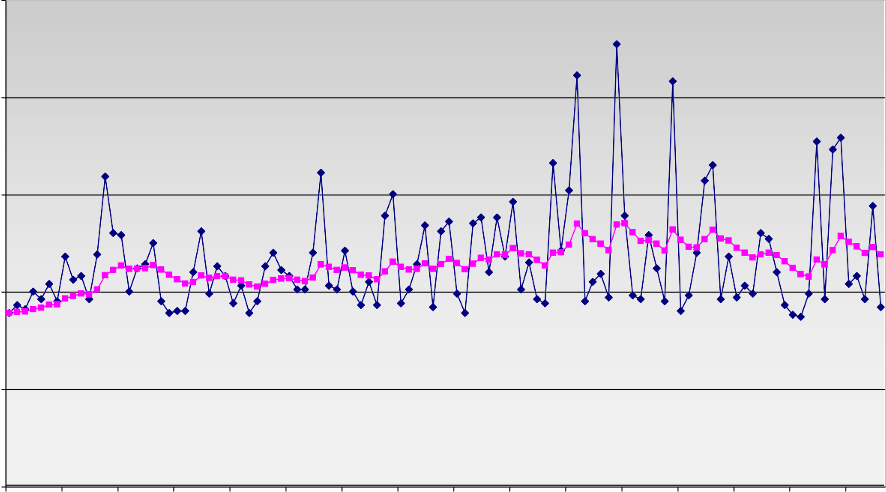
saftey margin이라는 값을 추가하여 timeout 잡아줌
TCP sender : event
어플리케이션 layer로부터 데이터 받음seq #을 추가하여 segment 생성하고 순서대로 보냄
timeout재전송 하고 타이머 다시 설정해줌
ACK 받음만약 이전에 unACKed된 거였다면 업데이트해줌 timer 뒤로 미룸
TCP receiver
- 순서에 맞는 segment 도착. 예상 seq#까지의 다른 데이터들도 모두 ACKed →
delayed ACK. 다음 segment까지 최대 500ms대기하고 없으면 ACK전송
- 순서에 맞는 segment 도착. delay ACK 대기 중 →
cumulative ACK 전송. 이전 ACK까지 같이 보냄
- 순서가 맞지 않은 segment 도착 →
duplicated ACK보냄 : 지금받아야하는 것의 번호를 보내서 빠진거있다고 알려줌
- gap을 채워주는 segment가 도착 → 이전에 왔던 것까지 ACK보냄
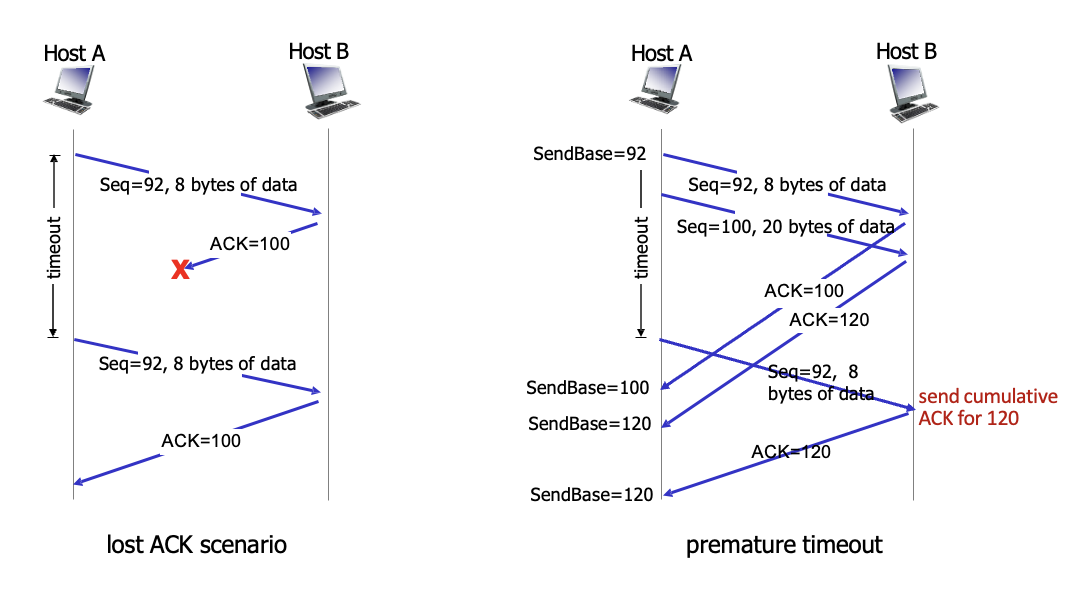
-
ACK가 loss되어서 재전송
-
time out을 짧게 설정한 예시 : 응답이 도착하기 전에 time out
받은거 또 받아도 무시하면 됨(재전송 문제 X)
그러나 안써도될 대역폭 낭비
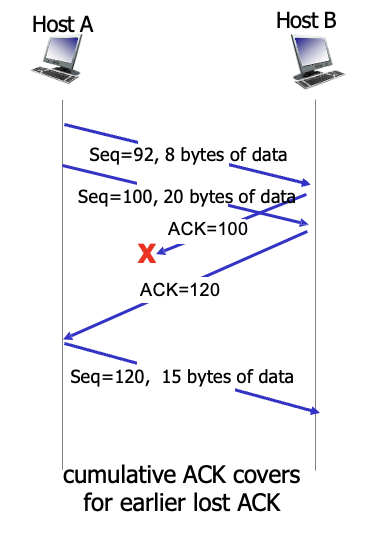
누적 ACK이므로 마지막만 잘오면됨. 92-100도 잘받음
만약 92를 보냈는데 이게 가는 과정에서 Loss가 나서 못받았다면 계속 ACK=92를 보내게됨
receiver의 buffer의 기능은 순서번호를 맞춰주는 기능
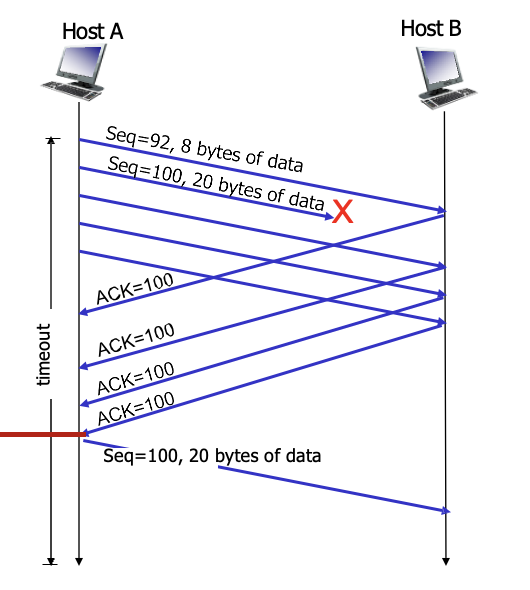
TCP fast retransmit : 3번 같은 ACK를 받으면 loss일 확률이 높으니 time out이 끝나지 않았더라도 재전송 → 빨리빨리 망을 비워주는 것
TCP flow control
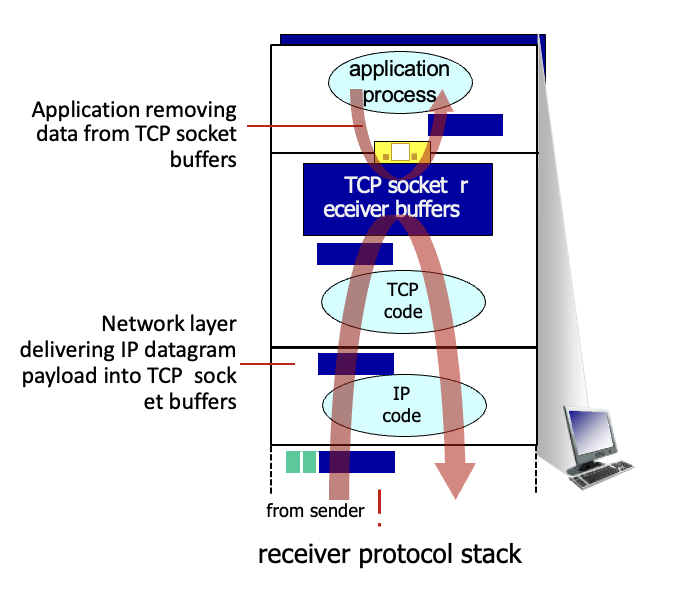
소켓을 통해 5계층으로 보내는 속도보다 3계층에서 데이터가 오는 속도가 더 빠르면? (즉 송신자 속도 > 수신자 속도)
→ flow control 해줘야함 : 송신자가 너무 빨리 보내지 못하게 수신자가 제어
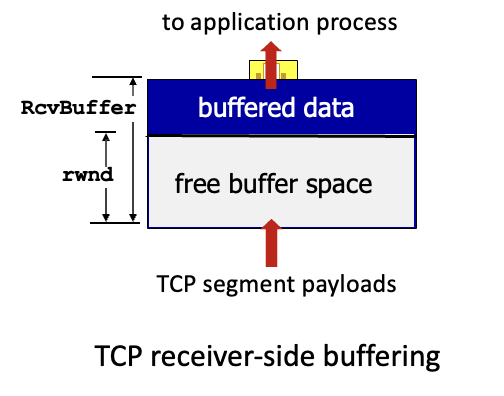
receiver는 rwnd 필드 = free buffer space(즉 남은 공간)이 얼마나 있는지 TCP 헤더에 붙여서 보냄
- RcvBuffer는 보통 4096byte
sender는 rwnd값을 받고 보낼 데이터 양을 제한함
오버플로우가 일어나지 않는 것을 보장
TCP connection management
데이터 교환 전에 sender/receiver는 handshake 과정이 있음
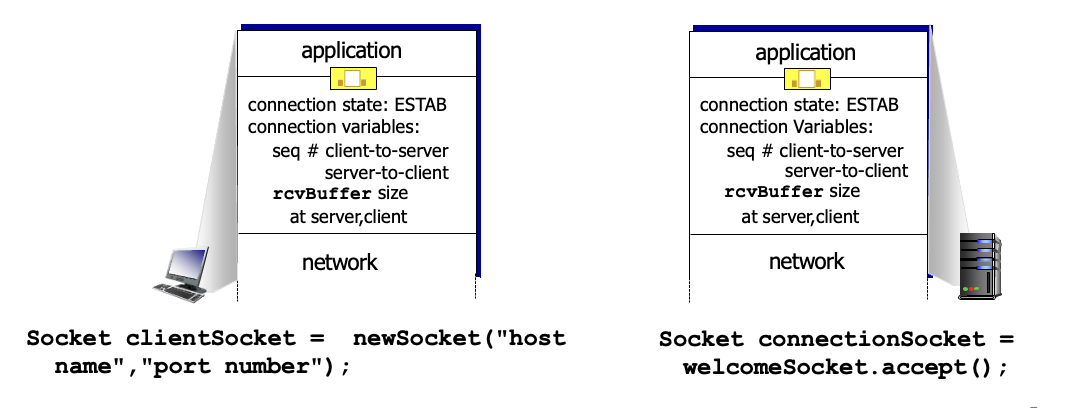
state : 계속 변하는 상태 정보
seq : client, server 번호 각각 존재
TCP 3-way handshake
연결을 위해서는 최소 3번 왔다갔다 해야됨 → 2 way는 불가
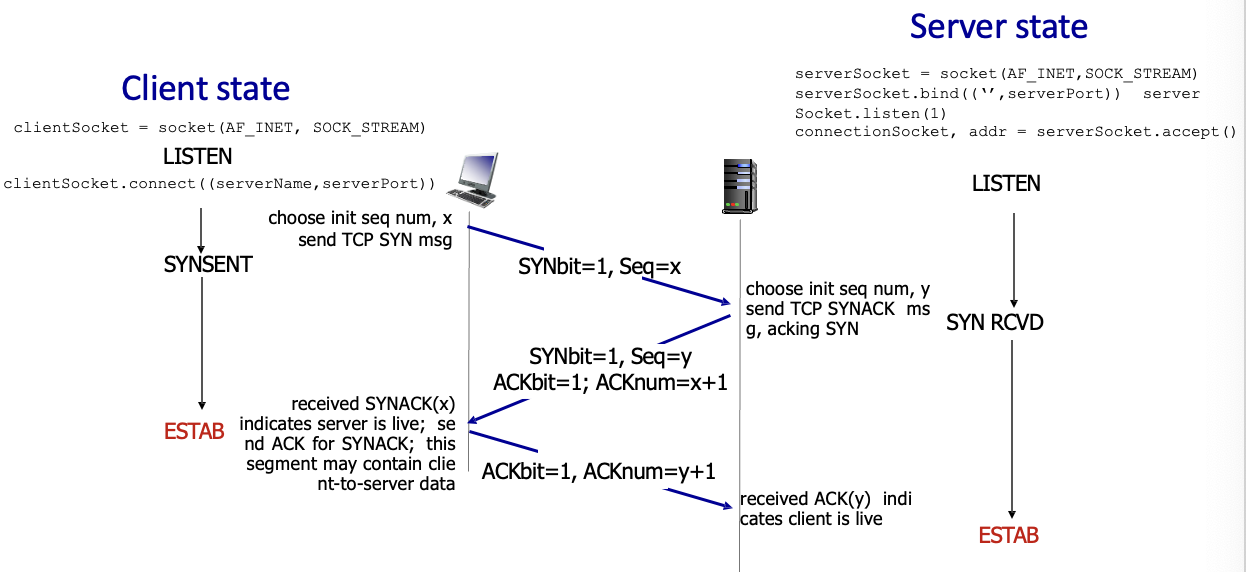
- client → server :
SYNbit1로 설정, seq 랜덤 설정 → SYNSENT 상태 - server → client :
SYNbit1로 설정, seq 랜덤설정.ACK보냄 → SYNRCVD 상태 ACK보냄.데이터담아서 보낼 수 있음
Closing a TCP connection → 4way
연결 끊을 땐 각각 끊음 → FIN bit = 1을 보냄
FIN 받으면 ACK 보냄
즉, 각각 끊는다고 FIN보내고 ACK받는 과정을 진행하므로 총 4번 왔다갔다
→ 연결끊어도 잠시 열어둔 다음에 종료함
📌 Principles of congestion control
flow control : 수신자가 자신의 남은 버퍼 용량을 알려주는 방식으로 해결
→ congestion control은 망 자체가 혼잡하므로 처리하기가 복잡하다
네트워크에 너무 많은 sender가 존재하고, 데이터가 너무 많을 때 → 딜레이가 길어지고, 패킷 loss
Causes/costs of congestion : scenario 1
가장 간단한 시나리오
- 하나의 라우터,
무한버퍼 - input, output link 용량 : R
- 2개의 flow
- 재전송 필요 X → 무한 버퍼니까 loss가 안일어남
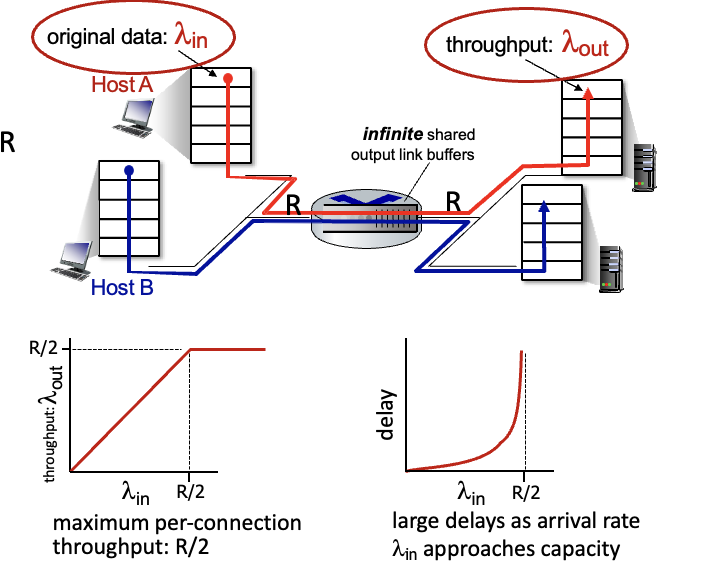
output link의 최대 처리량은 R/2 → 둘이서 쓰니까
input link의 사용량이 R/2에 가까워질수록 delay 증가
Causes/costs of congestion : scenario 2
- 하나의 라우터,
유한버퍼 - sender는 lost, timeout packet에 대해서 재전송 해줘야됨
5계층 input과 4계층 input은 다름 → 4계층은 재전송 포함
-
perfect knowledge
sender가 라우터 버퍼의 상황을 완벽히 안다고 가정
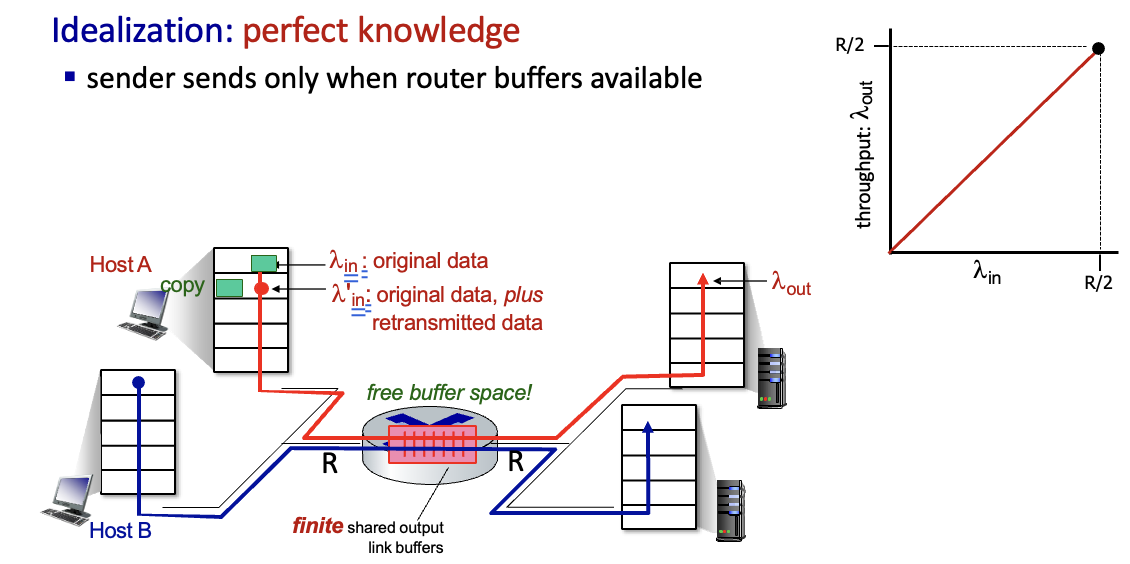
버퍼가 비었을때만 보내므로 처리량 R/2 → 하지만 완벽하게 아는 것 불가능
-
some perfect knowledge
버퍼가 꽉차서 loss될 수 있으며, sender는 패킷이 loss되었을때만 알고 재전송한다고 가정
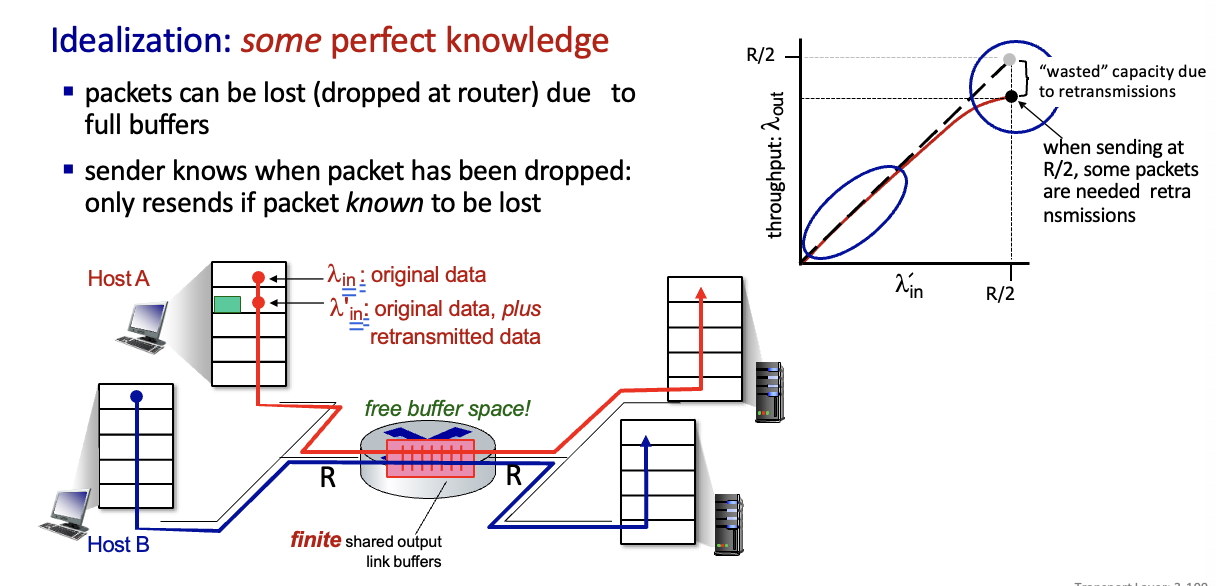
그래프가 살짝 휘어지는 이유는
재전송때문에낭비되는 용량이 있기때문 -
un-needed duplicates
패킷은 loss될 수 있으며 이때 재전송 필요하고, 만약 loss되지 않았는데 타이머가 일찍 만료되어 2개의 복사본이 갈 수도 있다고 가정 → 현실적 시나리오
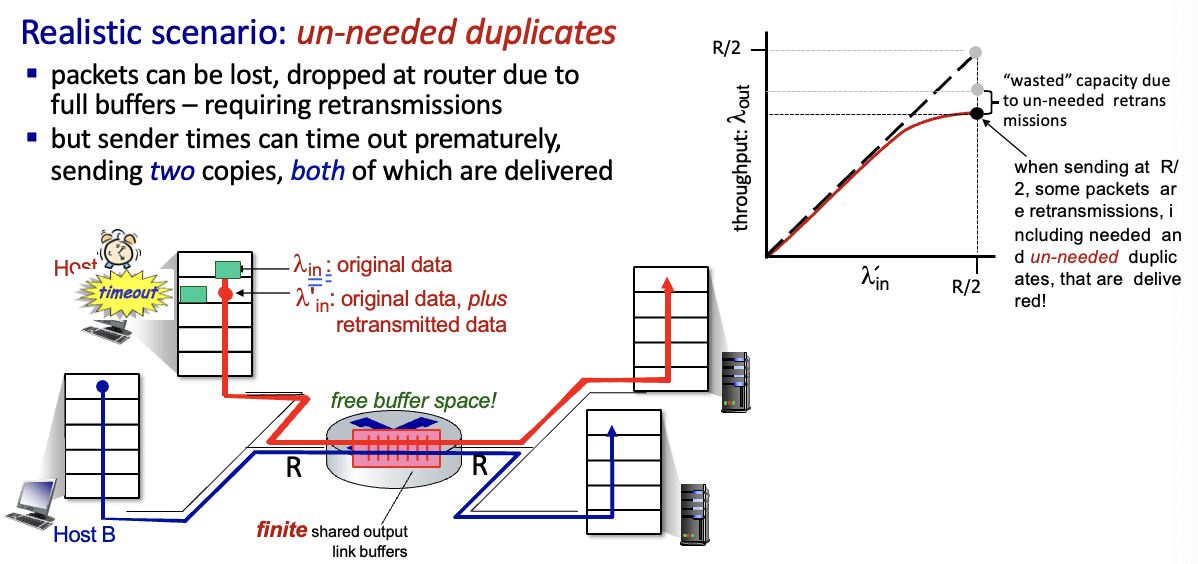
그래프가 좀 더 휘게됨.
필요없는 복사본 전송으로 인해
Causes/costs of congestion : scenario 3
- 네개의 sender
- multi-hop paths :
여러개의 라우터를 거침 - 타임아웃 / 재전송
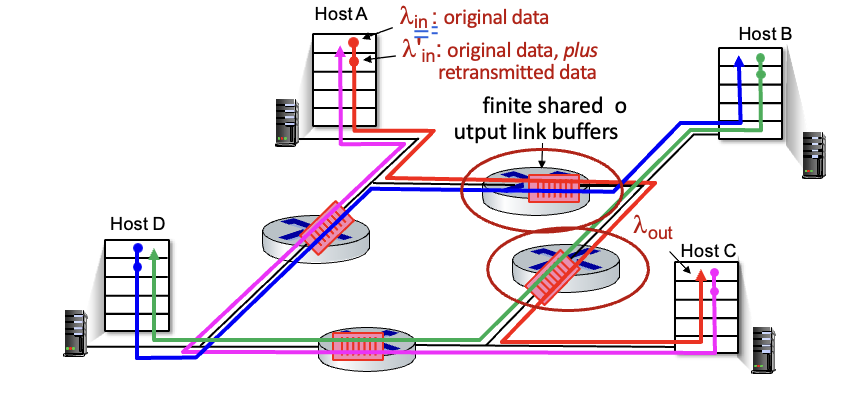
가장 위에 있는 라우터를 예시로 들면
→ 빨강, 파랑에서 데이터가 오는데 빨강이 더 먼저 도착함
→ 파랑 쪽 데이터는 loss 확률 올라가고, delay 발생
→ 계속 재전송할거 생기고 망은 점점 더 혼잡해지고…
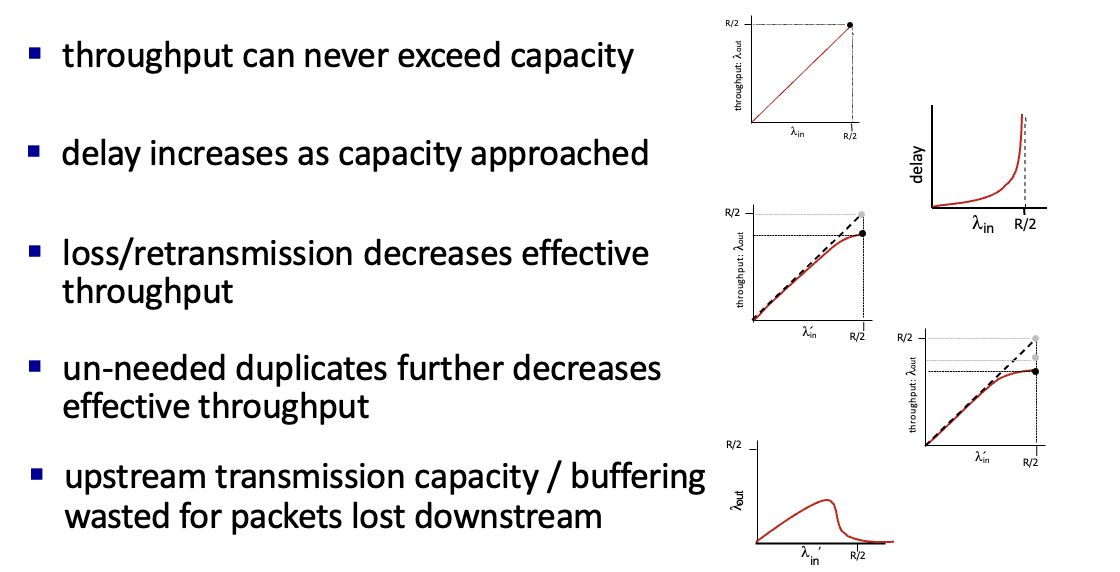
throughput은 용량을 초과할 수 없음
용량이 커질수록 delay는 증가함
loss / 재전송 / 불필요한 복제본의 전송은 효과적인 throughput을 감소시킴 → 실제 전송되는 양이 감소
Approaches towards congestion control 2가지 해결책
-
End-end congestion control
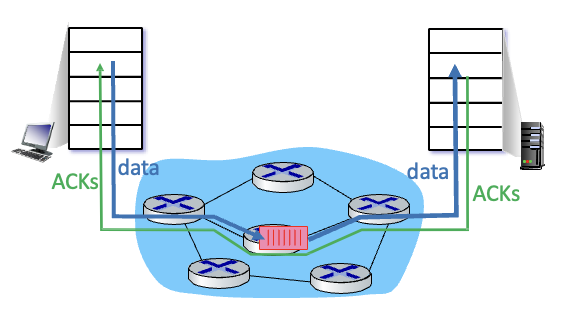
네트워크로 부터 명시적 피드백이 오진 않음
delay, loss를 통해 혼잡한지 판단
TCP를 통해 접근
-
Network-assisted congestion control
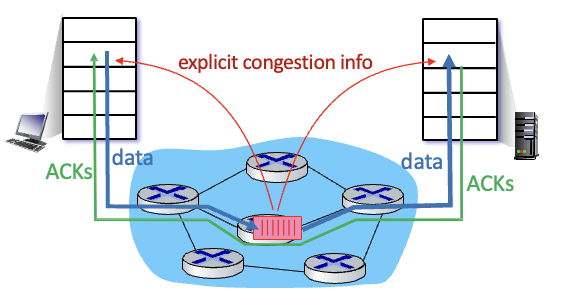
라우터가 sender, receiver에게 직접적인 피드백을 줌
📌 TCP congestion control
sender는 packet loss전까지 전송률을 증가시키고, loss가 발생하면 전송률 감소시키도록
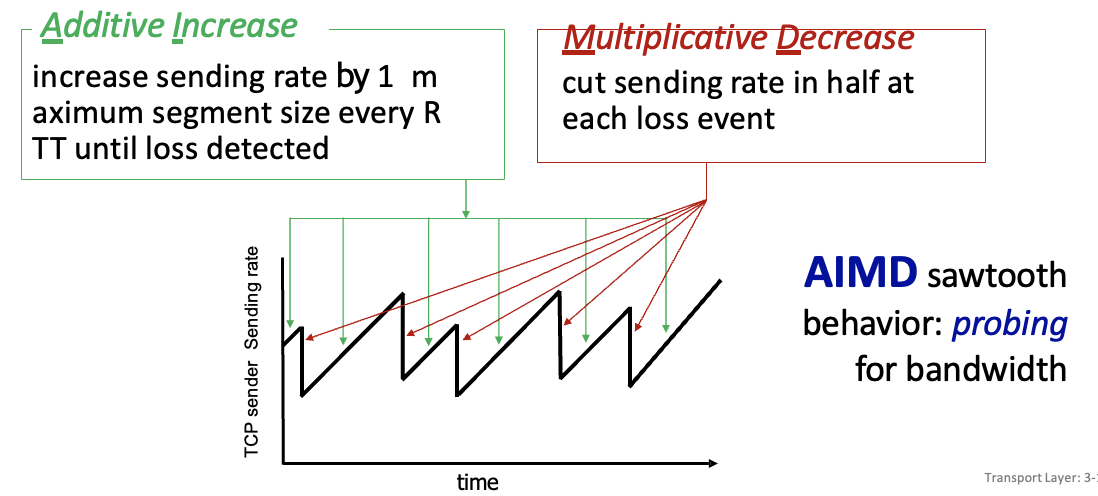
AIMD(Additive Increase Multiplicative Decrease) : 전송률을 증가시킬때는 조심스럽게 증가하고, loss가 발생하면 전송률을 반으로 확 줄이는 방식
→ 정체가 잘 풀릴수 있도록 해줌
TCP Reno: 3번 중복 ACK로 인해 loss가 탐지된 경우 특정 패킷이 문제이므로 적당히 감소시킴TCP Tahoe: timeout으로 인해 loss 탐지된 경우 망자체가 혼잡해서 더 심각한 경우이므로 훅 떨어트림

sender의 window size는 네트워크 congestion 상태를 보고 유동적으로 조정
망이 혼잡하지 않다면 크기 커지고 혼잡시 작아짐
느리게 시작해서 매우 빠르게 증가함 → 배로 늘리는 방식
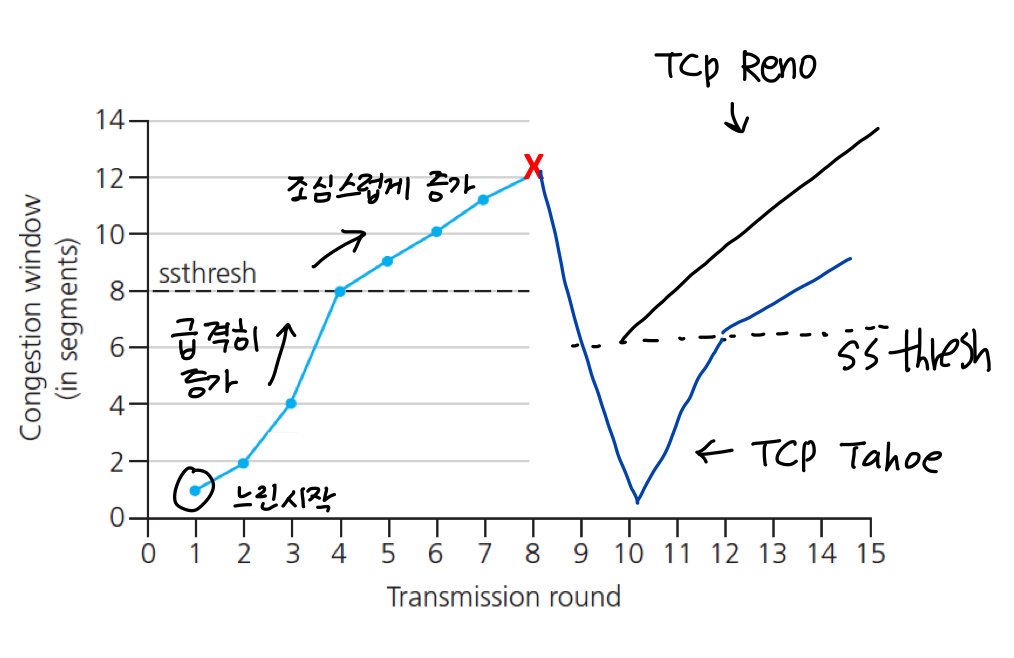
급격히 증가하다가 ssthresh값을 넘으면 조심스럽게 증가
loss가 생기면 그 값의 1/2을 ssthresh로 새로 설정
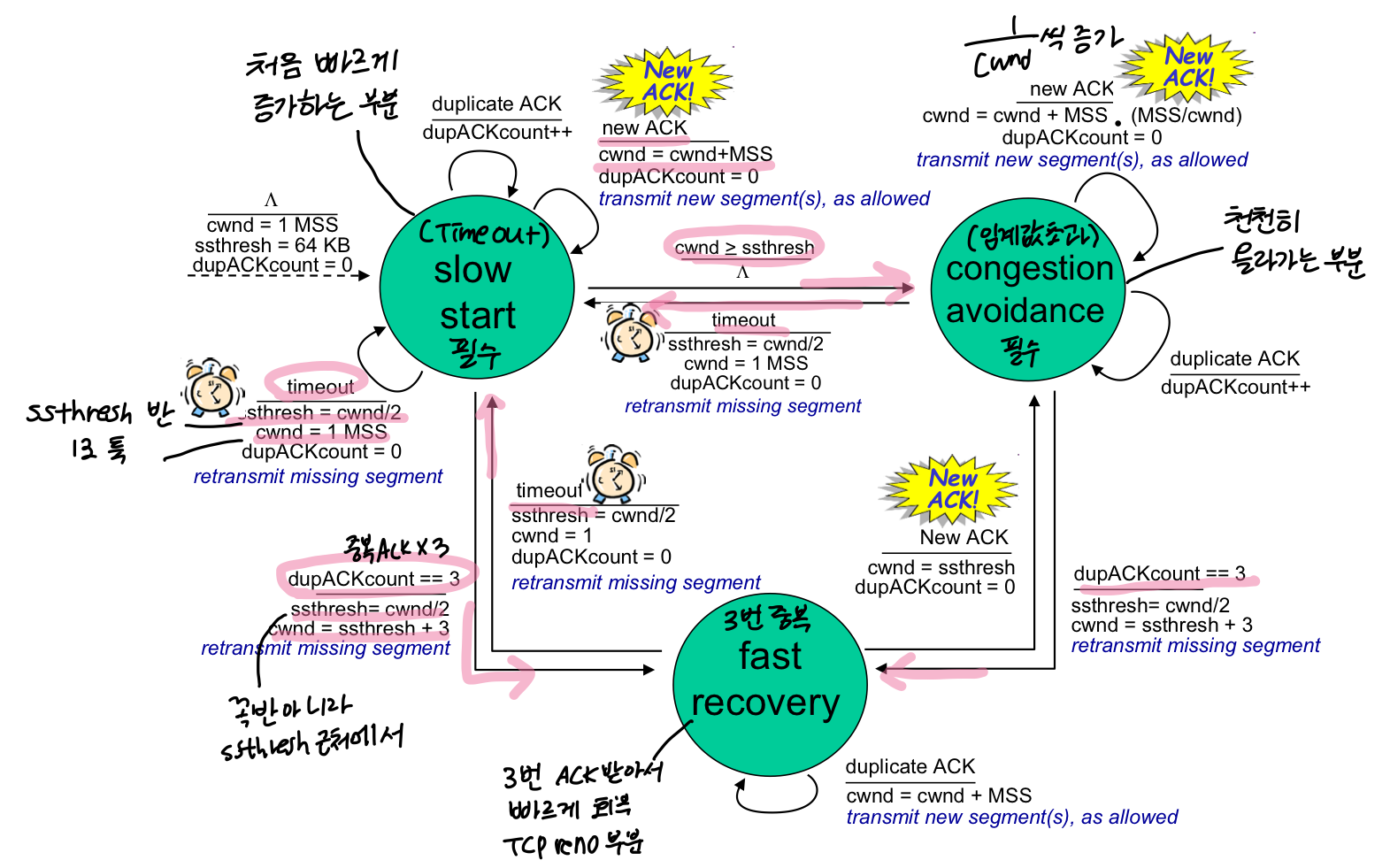
slow start : 처음 빠르게 올라가는 부분
- 임계값 초과 : congestion avodance로 → 천천히 증가
- timeout : 반으로 줄이고 다시 slow start로(어디든)
- 중복 ACK : fast recovery로 → 빠르게 회복
TCP CUBIC
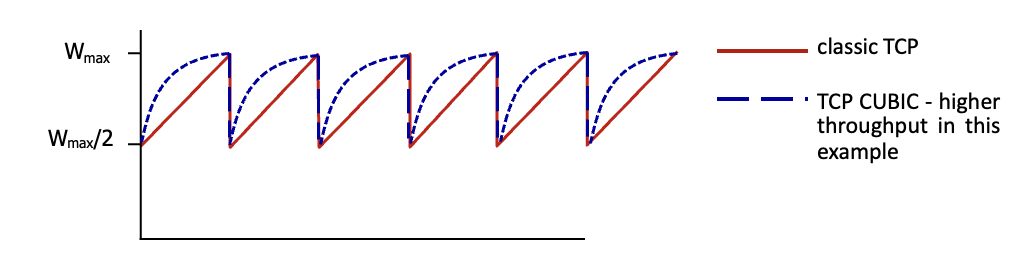
AIMD를 더 효율적으로 쓰기 위한 방법
Wmax는 loss가 발생하는 지점으로 Wmax에서 멀수록 빠르고, 가까울수록 느리게 증가
Delay-based TCP congesiton control
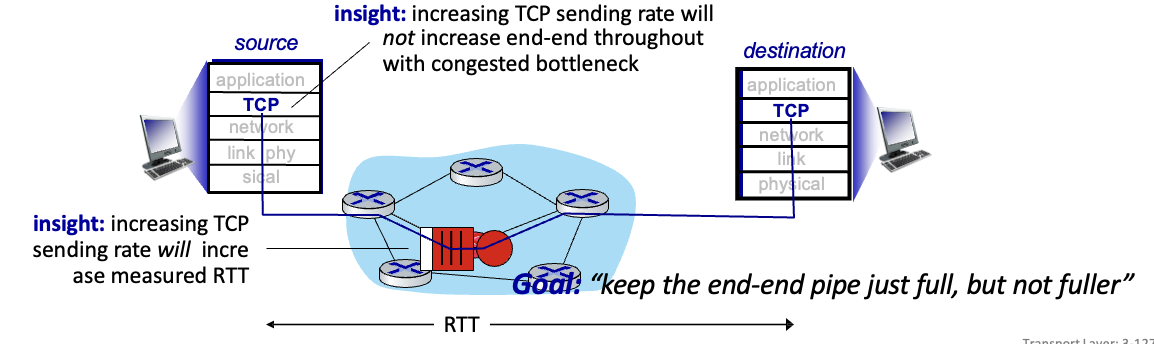
혼잡이 발생하기 전 RTT와 throughput을 계산해놓고 데이터를 보낼때마다 확인
→ 측정한 throughput이 혼잡발생 전 throughput과 비슷하면 윈도우 증가시키고 반대일시 감소시킴
Explicit congesiton notification (ECN)
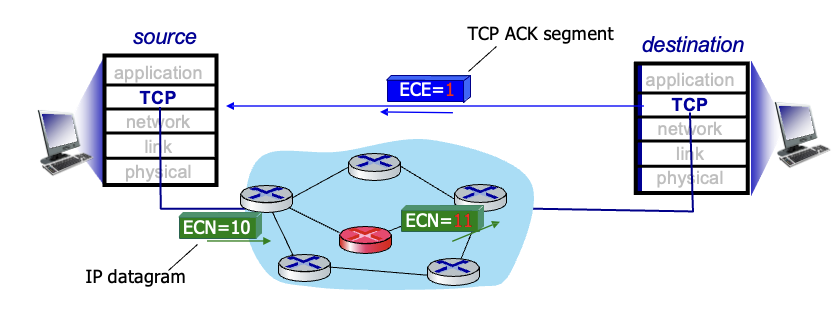
라우터의 도움을 받아서 혼잡 발생한것을 알림
ECN = 10 → ECN = 11로 바꿔서 혼잡하다는 것을 표시
TCP fairness
같은 bottleneck link를 사용하는 세션끼리 같은 사용률을 만들도록 하는것이 fairness 목표
두 상황이 정확히 같으면 fair하나 사실상 불가능
멀티미디어 앱들은 TCP 사용하지 않기도함 → UDP 사용하기도 하는데 이는 혼잡제어를 하지 않으므로 fair하지 않음
📌 Evolution of transport layer functionality
QUIC : Qucik UDP Internet Connection
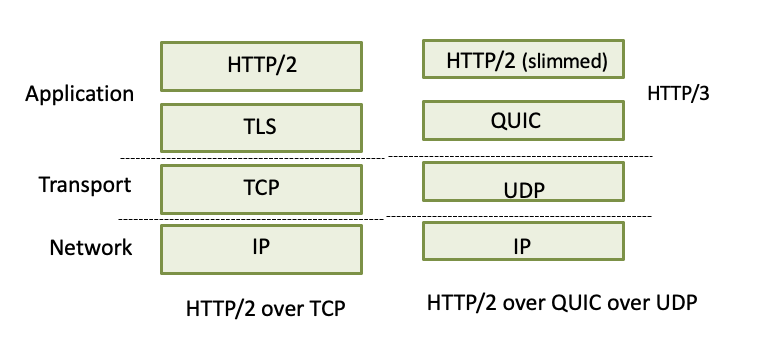
5계층에 있는 프로토콜로 UDP위에 위치
→ 3계층 : IP / 4계층 : UDP / 5계층 : QUIC, HTTP/2(둘을 합친것이 HTTP/3)
TCP로 HTTP를 작동시키니 너무 느려서 UDP를 사용하고 추가적인 것들은 5계층으로 올려버림
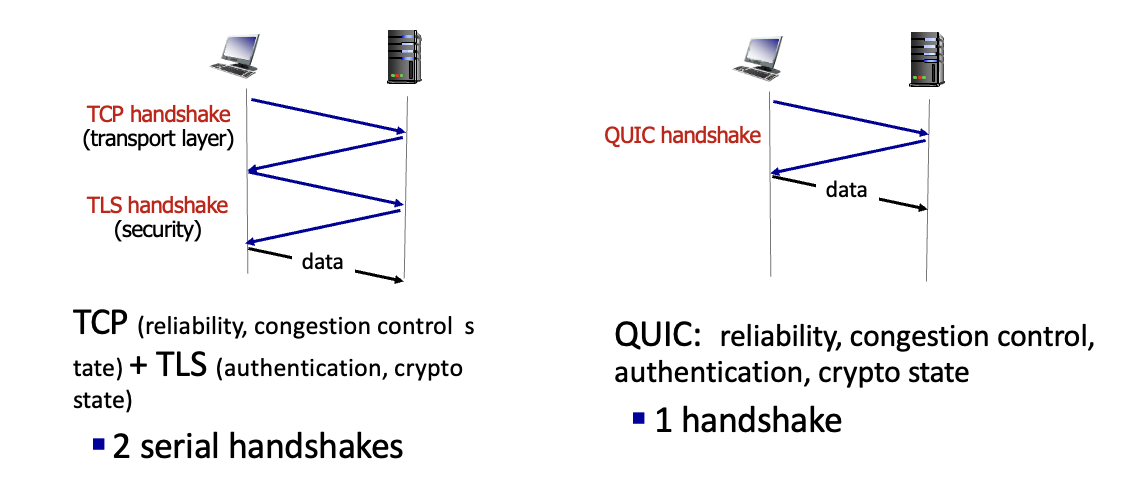
원래 2번의 handshake를 1번으로 줄여서 한번에 보안 + 연결설정
