
forwarding : 라우터의 input에서 올바른 output으로 패킷을 전달하는 것 → data plane
routing : 각 패킷의 source에서 destination까지 경로를 결정하는 것 → control plane
network control plane에는 두가지 방식이 있음
- per-router control →
전통적인 방식모든 개별 라우터에서 routing algorithm으로 forwarding table만드는 것
- logically centralized control →
SDN(software defined networking) Remote controller에서 경로를 계산하고 라우터 별로 CA(control agent)가 있어 만들어진 테이블을 받음. 라우터끼리는 통신할 필요가 X
📌 Routing protocol : link state, distance vector
Routing protocol : sender에서 receiver까지의 라우터들을 거쳐가는 최선의 경로를 결정하는 것 → 최선 : 적은 비용, 빠른 속도, 적은 혼잡
경로란 source host에서 destination host까지 거쳐가는 라우터들의 순서를 의미
복잡도가 높으면 → 안좋은거니까 비용 높게 설정(가중치라고 생각하면됨)
대역폭이 크면 → 좋은거니까 비용 낮게 설정

global : 라우터가 모든 라우터들의 정보를 다 알고 있는 것 → link state 알고리즘
decentralized : 라우터들은 서로의 이웃의 정보만 알고 있고 교환해나가면서 정보를 얻는 것 → distance vector 알고리즘
static : 천천히, dynamic : 빠르게
Link state
다익스트라 link state routing 알고리즘
centralized : 모든 라우터가 서로의 정보를 모두 동등하게 알고있음 → broadcast를 통해
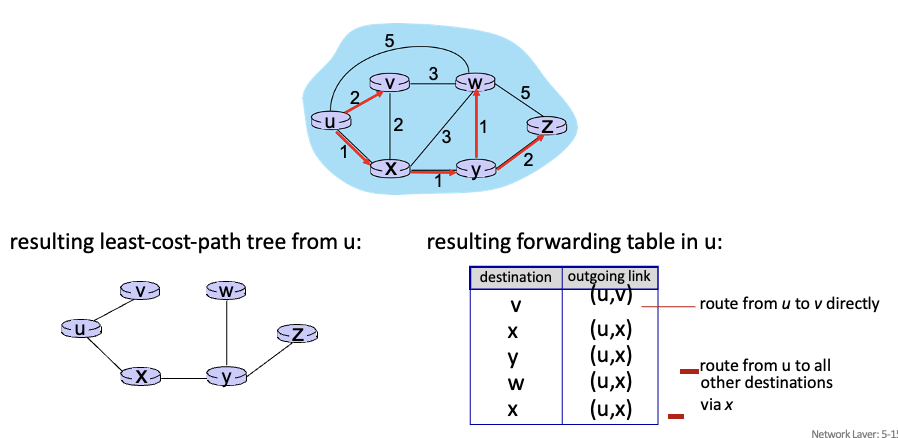
하나의 시작 노드에서 다른 모든 노드로의 최소 비용 경로를 계산 → 이것이 forwarding table
n번 반복하면 최소 비용 경로를 찾을 수 있음

C : x → y로 직접 갈때 비용
D(v) : 목적지 v까지의 현재 최소 비용
P(v) : 이전 라우터
N’ : 현재 최소 비용 경로에 포함되는 노드들 → 계속 변화
다익스트라 알고리즘 예시
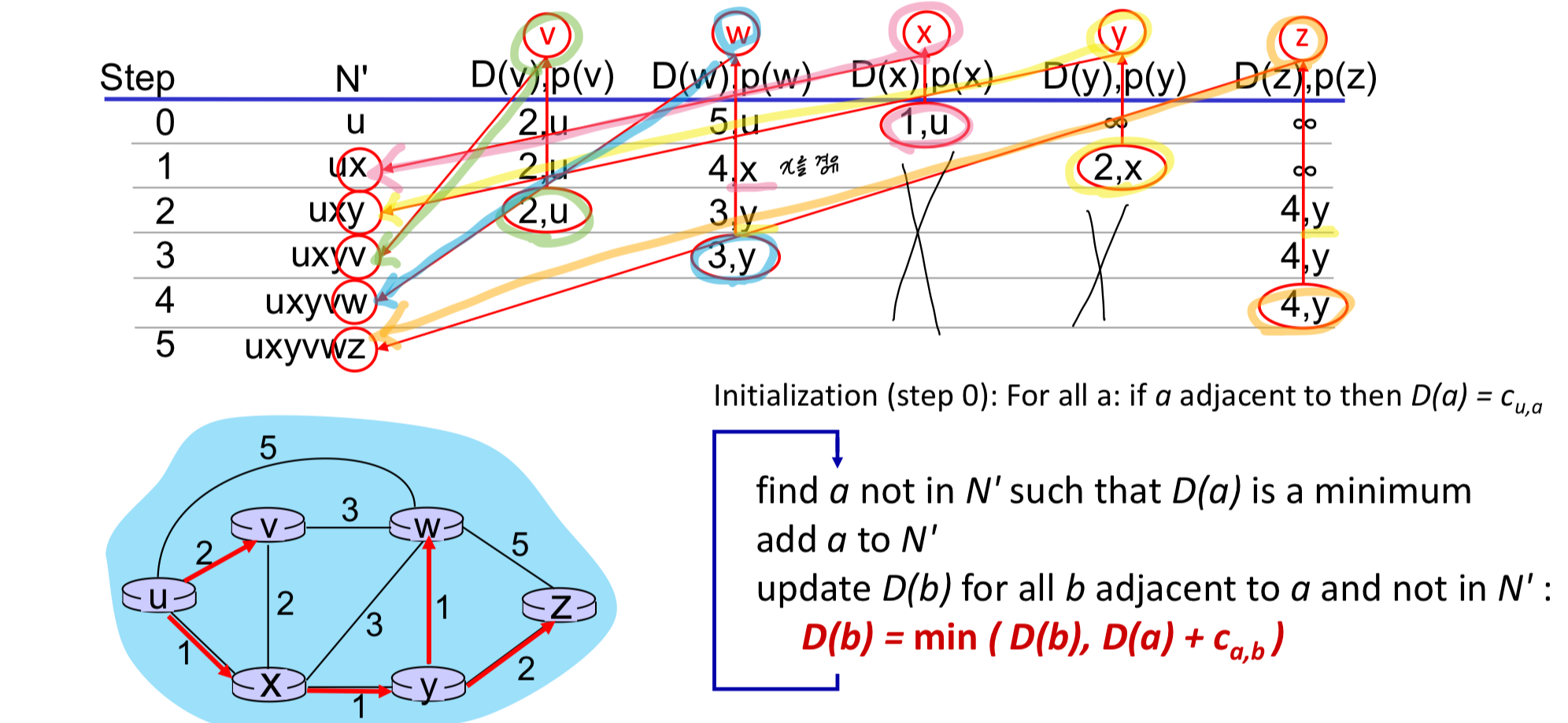
step 0을 보면 u에서 시작하여 갈수있는 경로는 3가지가 있음 : v, x, w
→ x로 가는 경로가 가장 최소임 : 경로 확정
→ x를 포함해서 최소 비용들을 갱신하고 그 중에 또 최소 경로를 확정
→ 이런식을 반복하여 모든 노드까지의 최소 비용을 구함
다익스트라 알고리즘 다른 예시
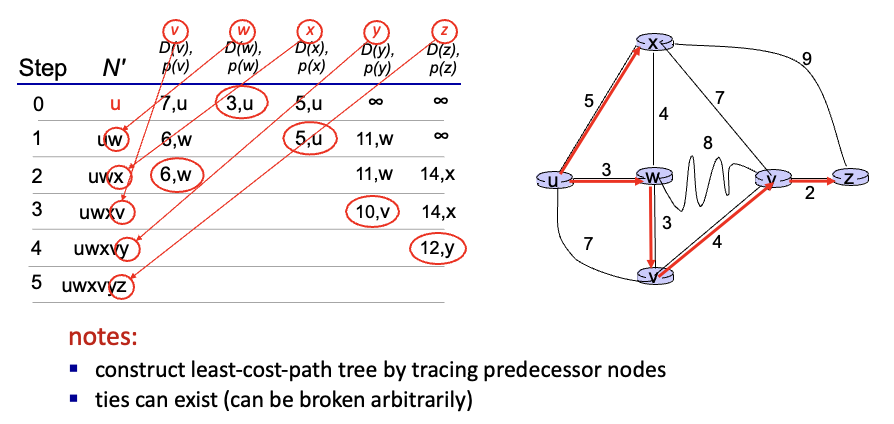
step 0에서 최소 값인 w 확정 : u랑 직접 연결
→ step 1에서 최소인 x 선택 : w 경유 → …
다익스트라 알고리즘 시간 복잡도 : → 더 효율적으로 하면
메세지 복잡도 : 각 라우터들은 자신의 정보를 모든 라우터들에게 broadcast해야함 → O(n^2)
oscillations possible
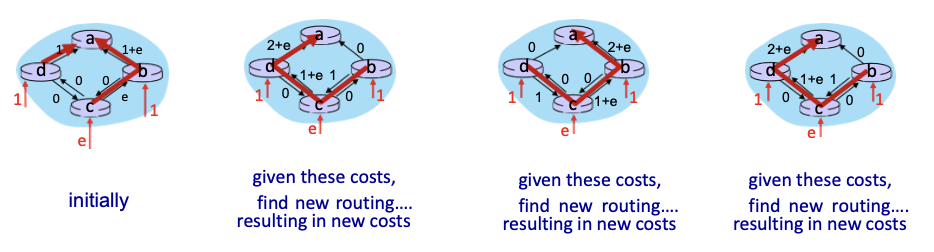
traffic이 많아지면 cost가 높아지고 이것을 토대로 경로 다시 계산
처음엔 a-b 사이가 혼잡해서 이 경로 대신 다른 경로 설정
→ 해당 경로가 다시 혼잡해지면 또 다른 경로 →… 이런식으로 반복
Distance vector
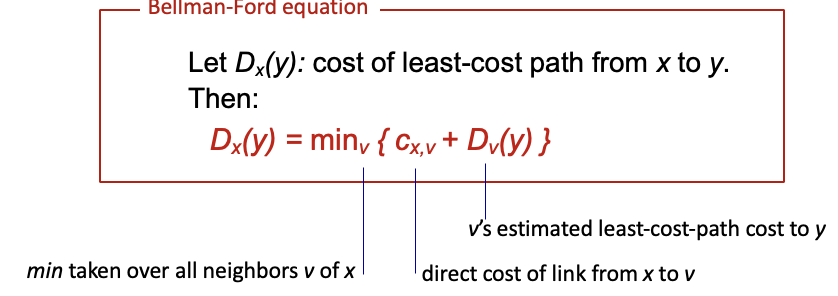
Bellman-Ford 방정식을 토대로함
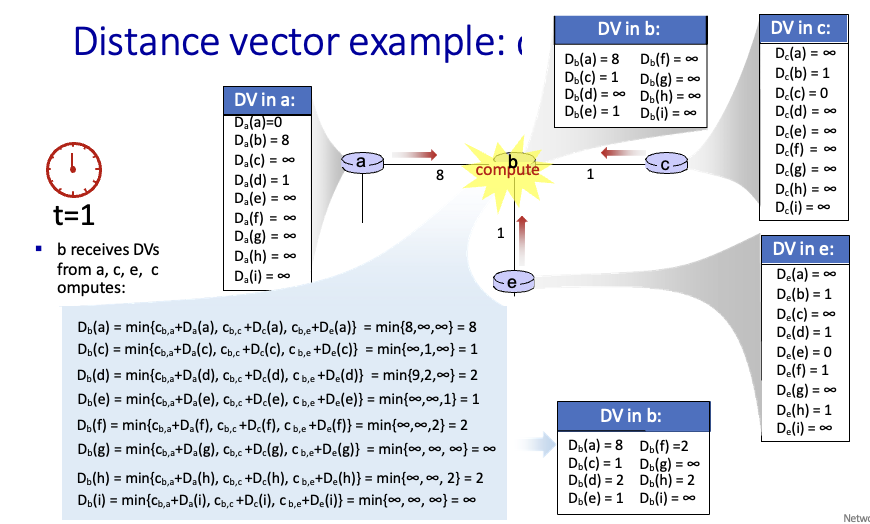
x → y로의 경로를 구할때 각 {x의 이웃까지 비용 + 이웃에서 y까지 비용}를 구해서 최소 값을 선택
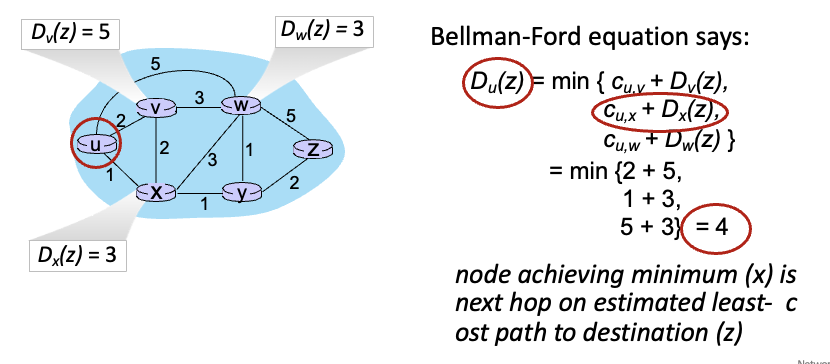
각 이웃에서 목적지까지의 최소 비용은 이미 구해놨다고 치고
위와 같은 방식으로 source → dest까지의 최소 비용을 구하는 것
여기서는 x로가는 경로가 최소로 선택됨
해당 알고리즘은 일정 시간마다 각 노드들은 자기의 이웃들에게만 정보를 보냄
→ 정보를 토대로 최소 비용 경로 업데이트
다익스트라와 다르게 음의 가중치를 가진상황에서도 동작 가능
Distance vector algorithm
각 노드에서 순서
- 일단
wait: 나의 link cost가 변하면 주변에 알리고, 친구 Link cost가 변하면 친구로부터 받음 recompute: 바뀐 link cost를 이용하여 DV를 다시 계산- 만약 경로가 바뀌었다면 이웃들에게
notify - 다시 wait로 감
iterative, asynchronous : 각 노드들에서 iteration은 local link cost가 변했거나, 이웃으로부터 DV update message를 받으면 발생
distributed, self-stopping : 각 노드들은 DV가 바뀌었을때 이웃에게 알리고 이웃은 또 이웃에게 알림(필요할시에만). 이웃으로부터 받은게 없으면 아무것도 안함
아래는 예시
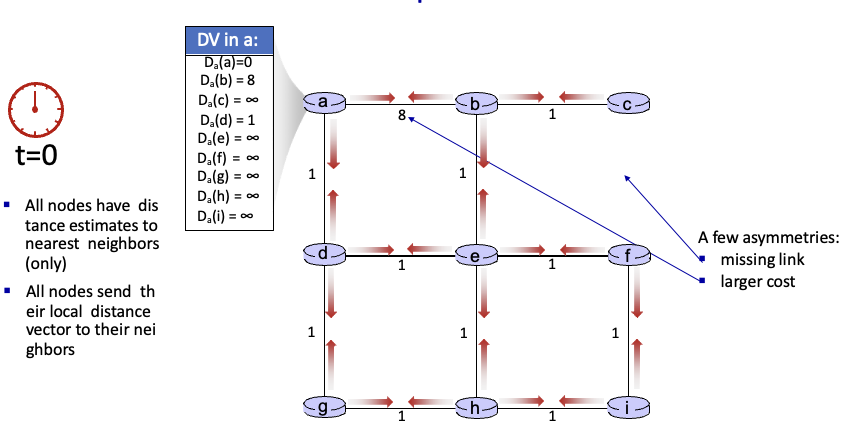
t = 0 처음엔 a는 주변 b,d 정보만 알고 있음
8이라는 큰 값과 missing link로 asymmetries 설정
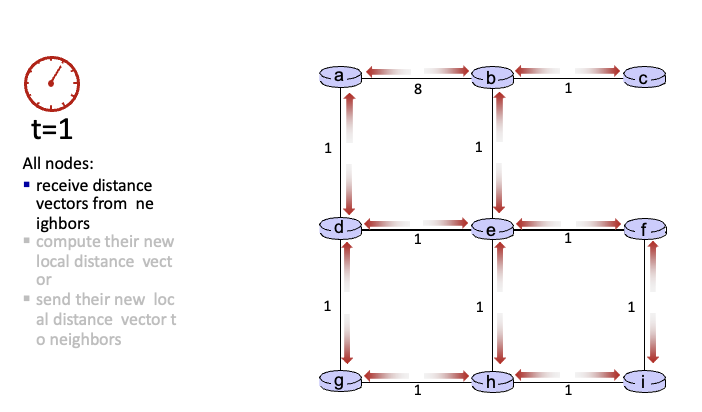
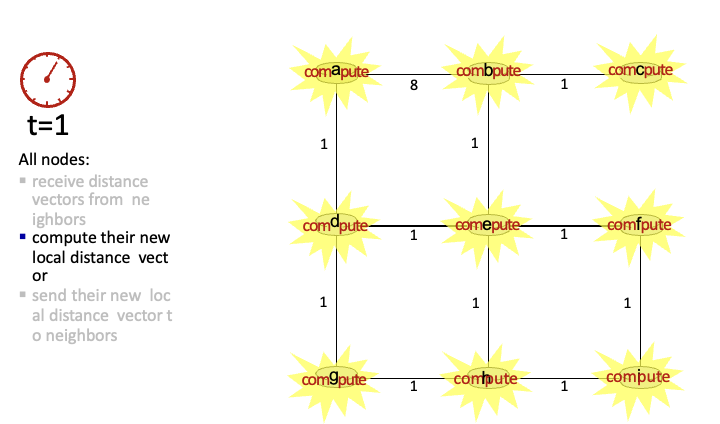
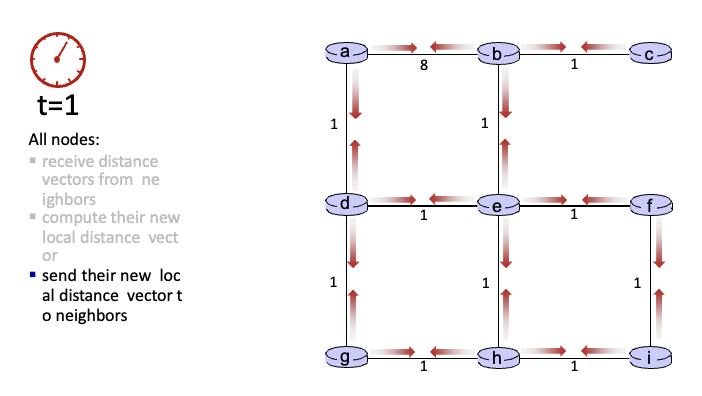
t = 1
각 노드들은 주변의 이웃까지 얼마의 비용으로 갈 수 있는지 알게됨
→ compute
→ 자신의 new local distance vector를 이웃에게 알림
→ t = 2 반복,..
이때 아래와 같이 각 라우터마다 최소 경로를 계산함
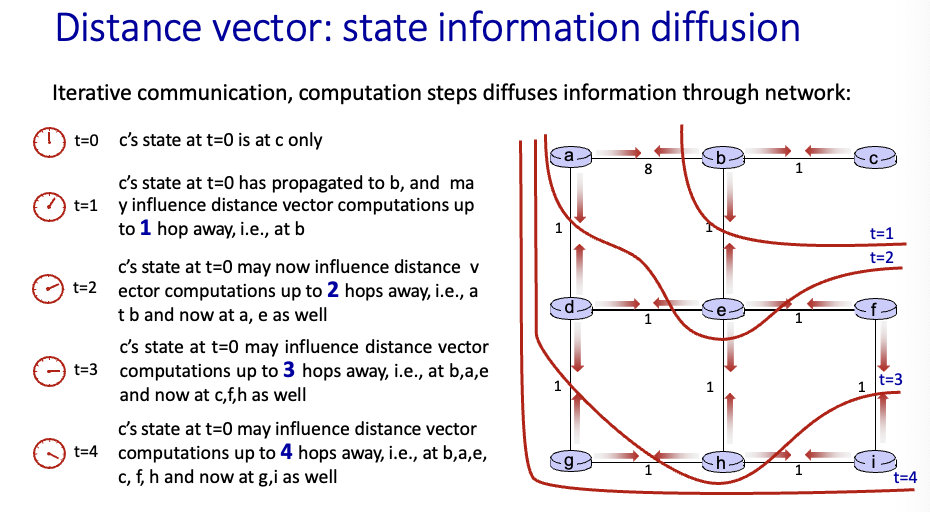
시간이 지나면서 갖고있는 정보가 확산됨 → 시간에 따라 n hop router까지의 정보를 알게됨
link cost changes : link의 값이 변하게 되면 DV를 다시 계산함 → 변한 경우에만 이웃들에게 알림
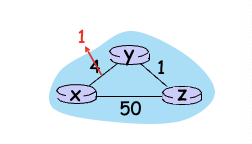
- y가 link cost 변한것을 탐지하고 DV를 update, 이웃들에게 알림
- z가 y로 부터 update된 것을 받고 자신의 테이블을 update. x까지의 최소 경로를 다시 계산해서 이웃들에게 보냄
- y가 z’의 update를 받고 테이블 update. y’의 최소 비용은 변한게 없을것이므로 z에게 메세지 안보냄
⇒ good news travels fast! → 가중치가 작은 쪽으로 변했을때는 크게 문제 없음
그러나 큰쪽으로 변했을때는 count to infinity 문제 발생 → bad news travels slow
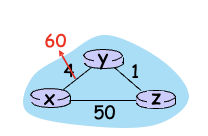
(x,y)의 비용이 60으로 증가한 상황
- y → x의 비용을 수정한다. 이때 z의 DV에 따르면 x → z는 5라는 최소 비용 거리를 갖고 있으므로, y → x는 6이라는 거리를 선택(실제로는 없는 거리이므로 매우 오래걸리게 됨)하고 주변에 알림
- z는 y → x는 6이라는 정보를 얻게되고 x → z는 y → z : 1을 더해 7으로 변경되고 주변에 알림
- y는 이 정보를 토대로 변경… 쓸데없는 반복을 계속 하게됨
해결방법 : x가 y에게 받은 값으로 z → x를 계산했으므로 y에게 값을 돌려줄때는 무한대로 돌려 보내줌
→ y는 z → y가 무한대라는 것을 알게되었으므로 60을 선택하고 이것을 z에게도 알림
→ z도 → y → x로 가는 비용을 61로 갱신하게됨 (원래 5로 알고있던것 버림)
이런 방식을 poisoned reverse로 해결한다고 함
LS vs DV
| LS(Link State) | DV(Distance Vector) | |
|---|---|---|
| message complexity | n개 라우터 O(n^2) | 이웃끼리만 교환 / 받는 시간 다양함 |
| speed of convergence 교환하는데 걸리는 시간 | 알고리즘 O(n^2) / 메시지 O(n^2) / oscillations 발생가능 | 시간 다양함 / loop 발생가능 → 시간 오래걸림 / count-to-infinity 문제 발생 가능 |
| robustness : 견고성 - 라우터 오작동 또는 손상된 경우 | 라우터는 잘못된 link cost를 전파할 수 있음 그러나 라우터마다 계산하므로 크게 문제X | 틀린 path cost를 전파하면 모든 네트워크 오염가능 : black holing → LS보다 보안 취약 |
| 모든 정보 다 알음 / 다익스트라 | 주변 정보만 알음 / 벨먼포드 |
📌 Intra-ISP routing : OSPF
지금까지 배운내용은 매우 이상적인 routing : 모든 라우터는 독립적이고, networks는 flat
→ 현실이랑은 거리가 멀다
scale : 수십억개의 목적지가 존재 → 라우팅 테이블에 모든 목적지 저장 못함
autonomous system (AS) = Domain : 하나의 ISP가 관리하는 자치 구역
intra-AS = intra-domain: 같은 AS 내부에서 routing AS 내부의 모든 라우터들은 같은 intra-domain 프로토콜을 사용 다른 AS간에는 다른 프로토콜 사용 가능gateway router: AS의 edge에 있는 라우터로, 다른 AS와 연결되어 있음
inter-AS = inter-domain: gateway가 하는 것으로 gateway끼리 바깥으로 통신하고 다시 내부로도 알림
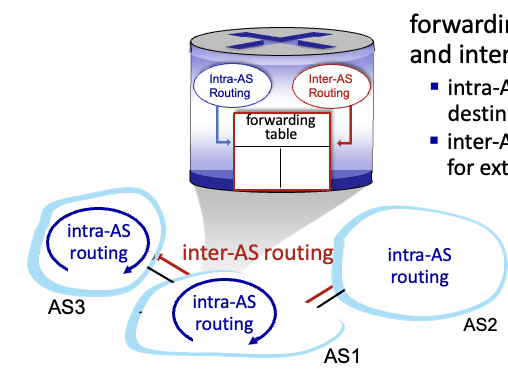
forwarding 테이블은 intra, inter - AS routing 알고리즘을 둘다 적용하여 만들어짐
- intra-AS routing : AS
내부에목적지가 있을 때 - inter-AS, intra-AS routing : AS
외부에목적지가 있을 때
Inter-AS routing
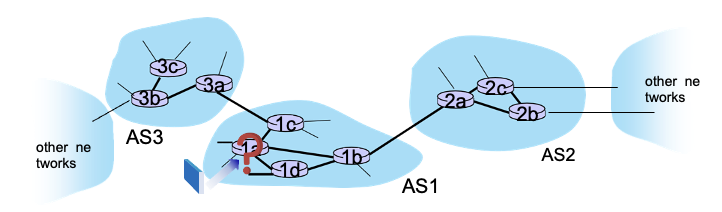
AS1 안에 있는 라우터가 AS1 밖에 있는 datagram을 받는다고 가정
→ AS1 inter-domain rouing이 하는 일
- AS2, AS3를 통해 갈 수 있는 목적지를 확인해보고
- AS1의 모든 라우터들에게 알림
Inter-AS routing의 프로토콜
- RIP : Routing Information Protocol → classic DV, 이제 잘 안씀
- EIGRP : Enhanced Interior Gateway Routing Protocol → DV based
OSPF: Open Shortest Path First → link state routing, IS-IS protocol (둘다비슷)
OSPF : Open Shortest Path First routing
open은 public하게 사용 가능하다는 의미
classic link-state
- 각 라우터들은 link-state를 flood함. AS내의 모든 라우터에게 알린다 → TCP/UDP 사용하지 않고 IP로 direct하게
- 다양한 link 사용 가능
- 각 라우터는 다익스트라 알고리즘 사용해서 forwarding table 만듬
security : 모든 OSPF 메세지는 인증됨
Hierarchical OSPF
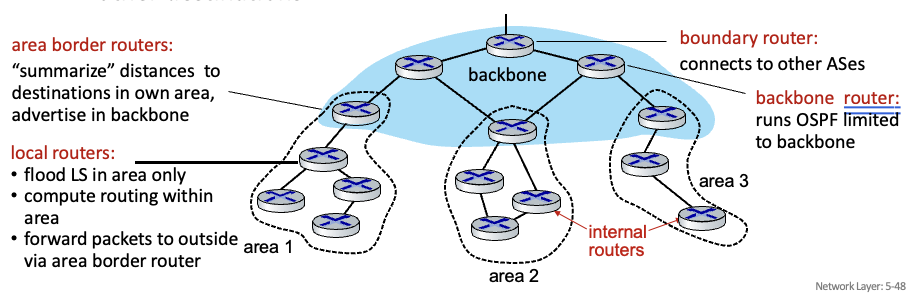
2레벨 계층 : local area, backbone
- link-state는 area내부 또는 backbone 내부에서만 flood
local router : 내부에서만 LS를 flood하고 각자 계싼함. border router를 통해 패킷 내보냄
area border router : area 내의 정보를 backbone에게 advertise
boundary router : 다른 AS와 연결된 라우터
backbone router : backbone 내에서만 OSPF
📌 Routing among ISPs : BGP
BGP : Border Gateway Protocol
사실상 Inter-domain routing protocol. 가장 많이 사용
eBGP:이웃 AS들로부터 reachability information을 받아옴iBGP:AS내부의 라우터들에게 reachability information을 알려줌
경로 결정은 Policy를 통해 좋은 경로를 선택
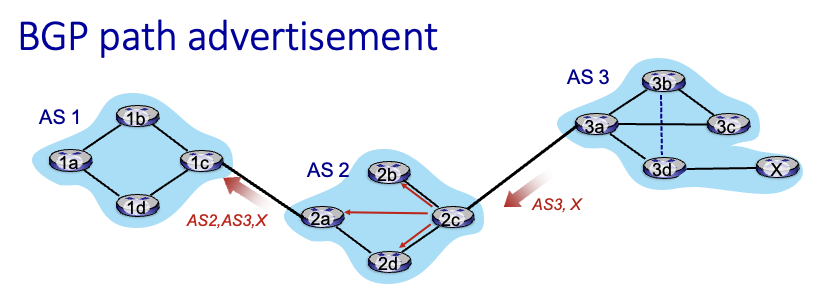
gateway router는 eBGP, iBGP 프로토콜 둘다 사용
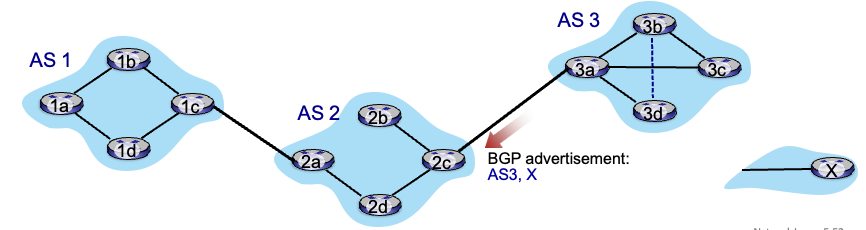
BGP session : 2개의 BGP router끼리 메세지를 교환할때는 반영구적인 TCP connection을 맺어서 어떤 경로를 통해 갈 수 있는지를 알려줌
위에서는 AS3의 3a가 2c에게 자신을 통해서 x에 갈 수 있다는 정보를 알려줌 → AS2에서 또 AS1로 정보 전달
BGP advertised route : prefix + attributes 경로 전달
- prefix : 목적지
- attribute 2종류 (특성)
- AS-PATH : 어떤 AS를 거쳐가야하는지
- NEXT-HOP : AS내부의 어떤 라우터를 거쳐가는지
policy-based routing : policy 정보를 사용해서 path를 사용할지 말지 결정
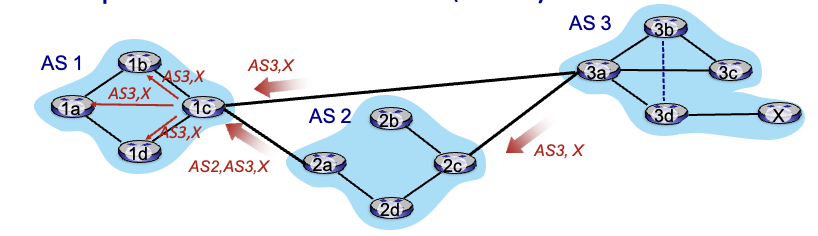
AS2의 2c는 AS3,X라는 정보를 AS3의 3a 라우터를 통해 받음
→ AS2의 policy를 토대로, AS3,X라는 경로를 받고 iBGP로 내부의 모든 라우터들에게 이 정보 전달
→ AS2의 policy를 토대로, AS2,AS3,X라는 정보를 AS1에게 넘김
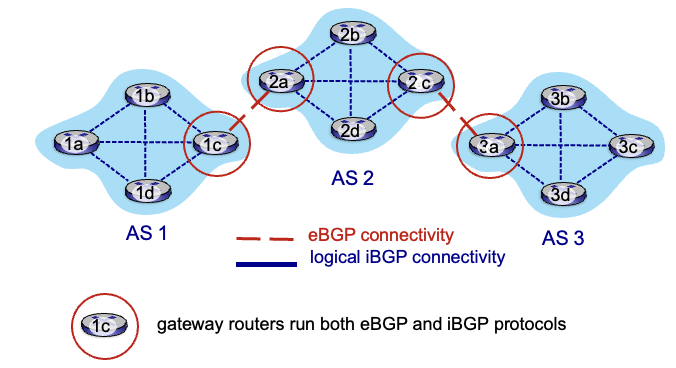
1c가 위와같이 두가지 경로를 모두 받았을 수도 있음 → 이때는 policy에 따라 AS3,X를 택할 것
BGP messages
TCP 연결을 통해 두개의 라우터 사이에 교환되는 메세지
- OPEN : TCP 연결을 open하는 메세지
- UPDATE : 새로운 경로를 advertise
- KEEPALIVE : UPDATE가 없어도 계속 살아있다고 알려주는 것; 또는 OPEN에 대한 ACK
- NOTIFICATION : 에러 있다고 보내는 것; 또는 connection 닫을때
BGP path advertisement
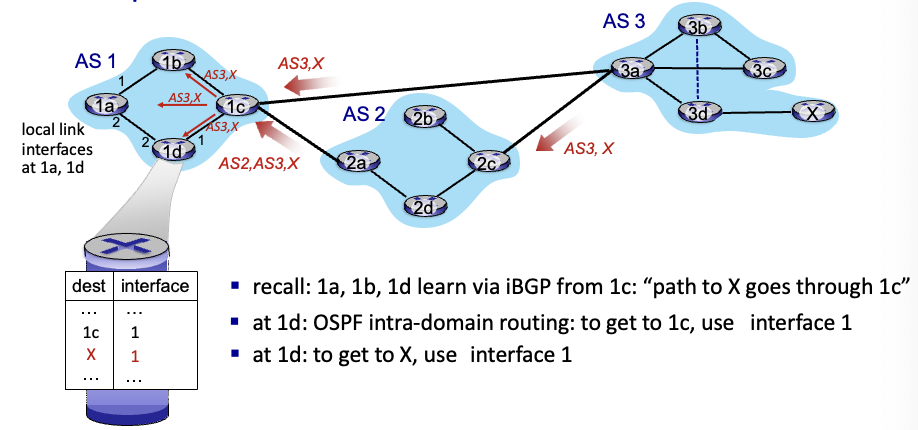
지금 1c가 x로 가는 경로를 AS내부에다가 알려준 상황
→ 1d에서는 1c로 가는 경로도 interface 1, x로 가는 경로도 interface 1임 : x로 가려면 일단 1로 가야됨. 나머지는 1c가 처리
→ 1a에서는 1c로 가는 경로도 2, x로 가는 경로도 2 : 1d한테 보내면 얘가 알아서 또 처리
각자 옆의 라우터에게 전달만 하는 것
intra-, inter- AS routing의 차이점
| inter-AS | intra-AS | |
|---|---|---|
| policy | 관리자가 라우팅 경로나, 누가 라우팅하는지 관리 | 관리자가 하나이므로 policy 의미 X |
| performance | 성능에 초점 | policy에 초점 |
scale : 계층적 라우팅으로 크기나, 트래픽 업데이트를 감소시킴
Hot potato routing
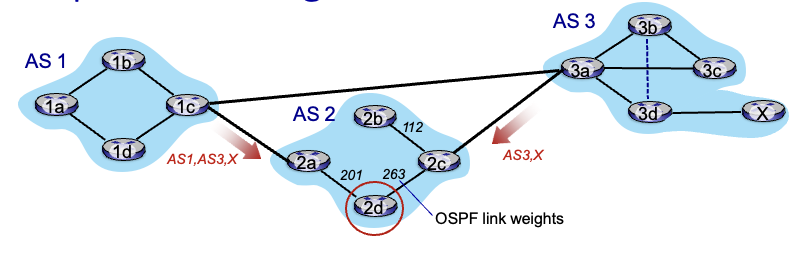
2d는 2a or 2c를 통해 x에 갈 수 있다는 것을 알게됨 (iBGP로)
hot potato running : 자기입장에서 가장 적은 비용이 드는 router 쪽으로 보냄.
→ 여기서는 2a로의 비용이 더 적으므로 여기로 전송. 실제로는 2a로 가면 더 오래걸리겠지만 그래도 자기 입장만 보고 선택
BGP : acheving policy Via advertisement
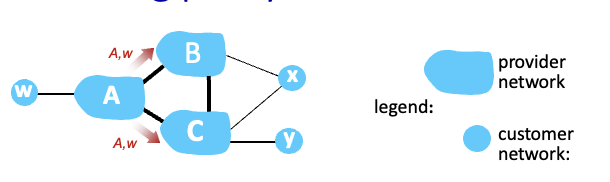
ISP는 자신의 customer network에만 route를 알려주고 싶어함 → 다른 ISP에게는 알려주려고 하지 않음
- A가 경로를 advertise한 상황
- B는 C에게는 자기가 얻은 정보(CBAw) 안 알려줌 : C,A,w 모두 B의 고객이 아님
- C는 CBAw라는 정보를 얻지 못하고 w에 가려면 CAw를 사용하게됨
ISP뿐만 아니라 customer network도 동일함
- X는 B,C 두개에 모두 붙어있지만 BxC경로를 B에게 알려주진 않음
policy는 inter-AS간에만 사용하는 개념.
BGP route selection : 라우터가 여러 경로를 알고있을때 다음 기준에 의해 선택함
- local preference value attribute : policy에 의해
- shortest AS-PATH : 가장 짧은 AS 경로
- closest NEXT-HOP 라우터 : hot potato routing 그냥 자기에게 제일 비용적은거
- 기타 기준
즉 가장 중요한 건 policy임
여기까지는 목적지 기반 forwarding, per-router control plane으로
각 라우터마다 routing algorithm을 돌리는 내용이였음
이후에 알아볼 내용은 SDN에 관한 것
📌 SDN control plane
과거에는 per-router control 방식을 주로 사용했으나 현재는 control plane 분리
Software-Defined Networking (SDN) control plane
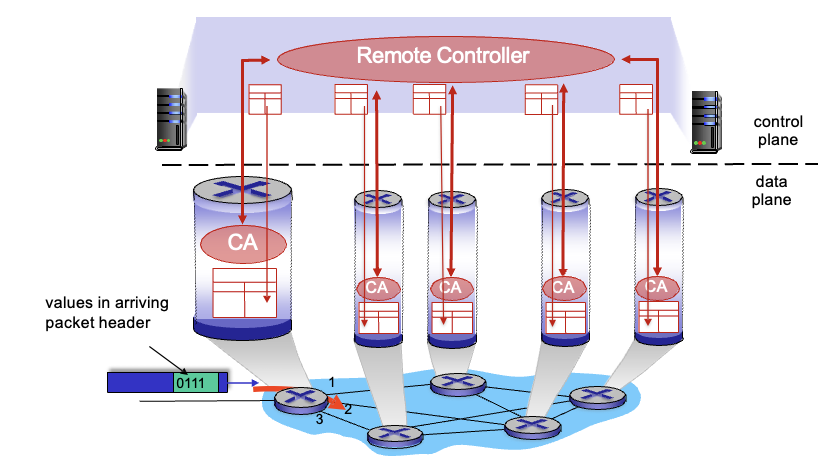
중앙의 remote controller가 계산하고 각 라우터의 CA에 전달해주자
왜 centralized 했는가?
→ 네트워크 관리가 쉬워짐 : 라우터의 misconfiguration 피할 수 있고, traffic에 유연하게 대처
traffic engineering
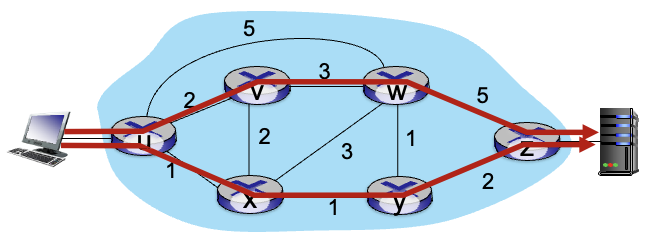
기존 전통적인 방식에서 효율적인 길(여기서uxyz)가 아닌 비효율적인 길(uvwz)로 보내려면 가중치를 수정하여 다시 계산하도록 했어야했음
SDN을 이용하면 두 길을 모두 사용 하여 분산시켜 보낼 수 있어짐 : load balancing
SDN
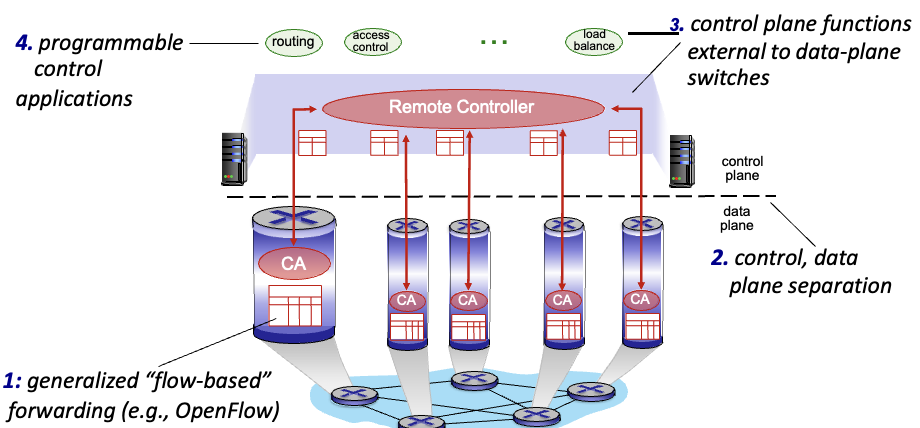
특징
- flow-based 포워딩
- control / data plane이 분리되어 있음
- control plane의 기능들은 data-plane switch 외부에
- routing, access control 등은 programmable
Data-plane switches
 빠르고 간단한 하드웨어 스위치를 data-plane에서 사용
빠르고 간단한 하드웨어 스위치를 data-plane에서 사용
forwarding만 하면됨
table 기반의 switch control API 존재 → OpenFlow
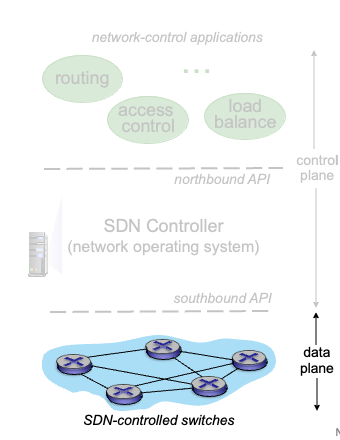
SDN controller (network OS)
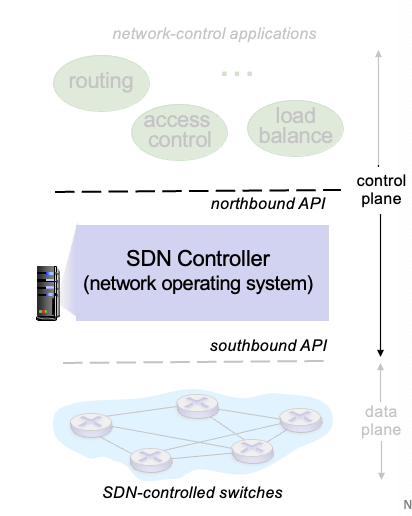 네트워크 상태 정보를 관리
네트워크 상태 정보를 관리
위의 northbound API를 통해 네트워크 control applications와 상호작용함
아래의 southbound API를 통해 네트워크 스위치들과 상호작용
성능, scalability 등의 문제들로 인해 분산된 구조로 구현됨
network-control apps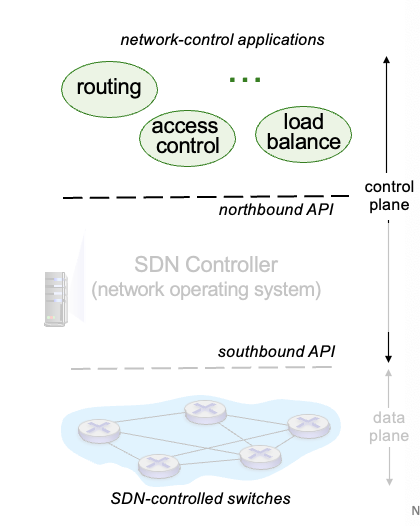
control의 ‘brain’ : control function 구현
routing vendor, SDN controller로 부터 구별됨
OpenFlow protocol
controller와 switch 사이에서 작동하는 Protocol
TCP 사용
controller → switch, switch → controller로 메세지를 보낼 수 있음
- Controller → switch로 보내는 메세지
- features : switch 특징에 대한 쿼리를 보내고 switch가 응답
- configure : switch의 파라미터 설정
modify-state: OpenFlow 테이블에 flow를 추가, 삭제, 수정- packet-out : 특정 port에서 패킷 보내도록
- Switch → controller로 보내는 메세지
- packet-in : 패킷을 컨트롤러에 전달
- flow-removed : flow table의 entry가 삭제됨
- port status : port에 변경이 있음을 알림
SDN : control/data plane 예시
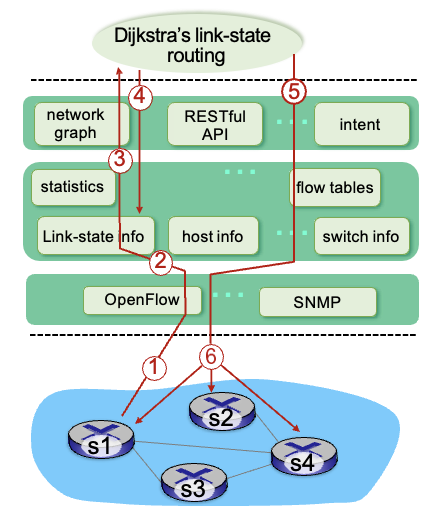
s1-s2 연결이 끊어진 상황
- S1이 OpenFlow port를 이용해서 링크 연결 실패를 알림
- SDN controller는 OpenFlow 메세지를 받고, link-state info를 업데이트
- 다익스트라 link-state routing 호출
- 다익스트라 routing은 graph info, link state등을 보고 루트 다시 계산
- 새로운 flow table을 생성
- controller가 OpenFlow를 이용해서 switch들에게 새 테이블 알려줌
📌 Internet Control Message Protocol
ICMP : internet control message protocol
host, router가 network level의 정보를 통신할 때 사용 → error reporting에 많이 사용
ICMP message : type, code, IP data 8byte
traceroute and ICMP
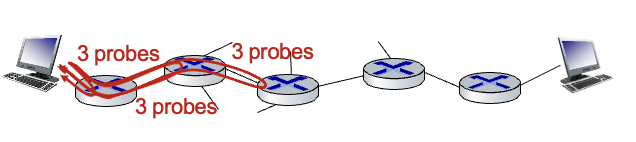
첫번째는 TTL=1, 두번째는 TTL=2로 보냄(라우터를 몇개건널건지)
n번째 라우터까지 가는 과정을 추적
