
📌 Network layer overview : data plane, control plane
segment를 sender → receiver로 전달해주는 역할을 하는 계층
- sender : segment를 datagrams으로 encapsulate해서 2계층으로 전달
- receiver : segment를 4계층으로 전달
network layer는 모든 디바이스에 존대함 → 호스트, 라우터 등..network core에도 존재
라우터 : 지나가는 모든 datagram의 헤더필드 검사, datagram을 전달
network layer의 기능
forwarding: 패킷을 라우터의 input link에서 올바른 output link로 전달routing: 패킷의 source에서 dest까지 경로를 설정해줌 → routing algorithm →forwarding table 생성
Data Plane
- local, 개별 라우터
- datagram이 라우터의 input port로 들어가서 output port로 가가는 것을 결정 :
forwarding
Control Plane
-
network-wide logic
-
datagram의 end-end 경로를 결정 :
routing -
두가지 접근 방식이 존재
traditional routing algorithm: 라우터 내에서 구현
각각의 라우터에서 라우팅 알고리즘 돌려서 테이블 만듬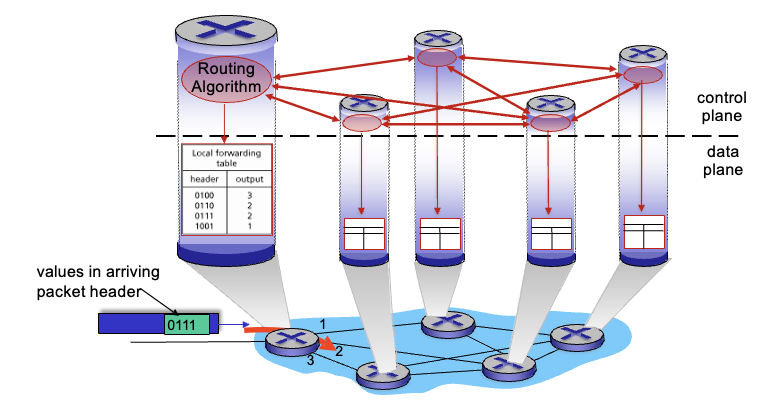
- Software-defined networking(
SDN) : (remote) server에서 구현 remote controller가 경로를 계산해서 forwarding table을 만들어서 router로 보냄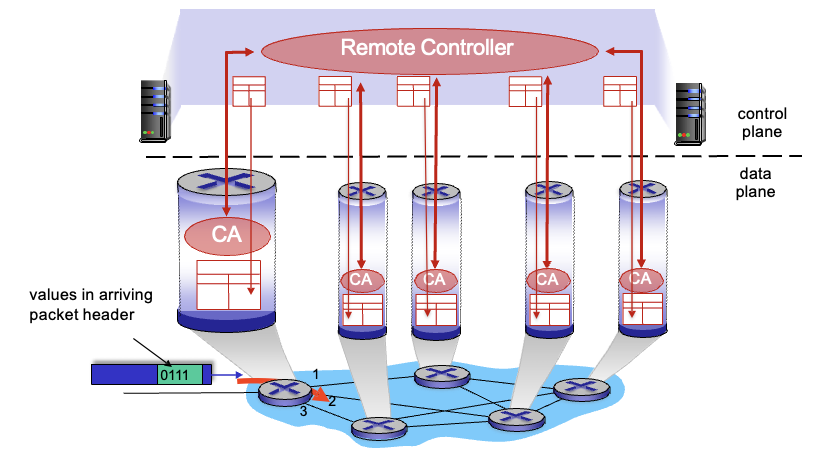
Network layer service model

인터넷의 best effort 서비스 모델
- 목적지까지 성공적인 전송 보장 X
- 시간이나 순서 보장 X
- 대역폭 보장 X
간단한 메커니즘이므로 인터넷이 이렇게 발전할 수 있었던 것
충분한 대역폭만 보장된다면 실시간 앱도 가능함
📌 Inside a router : input ports, switching, output ports, buffer management, scheduling
라우터 구조
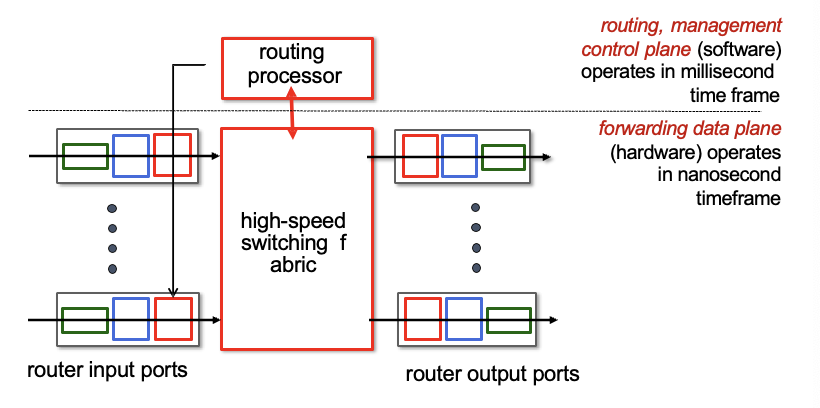
routing processor, high-speed switching fabric, router input ports, router output ports 이렇게 4개로 구성
routing processor는 control plane에 속함. routing해주는 역할. software
그외 나머지 3개는 모두 data plane에 속함. forwarding해주는 역할. hardware
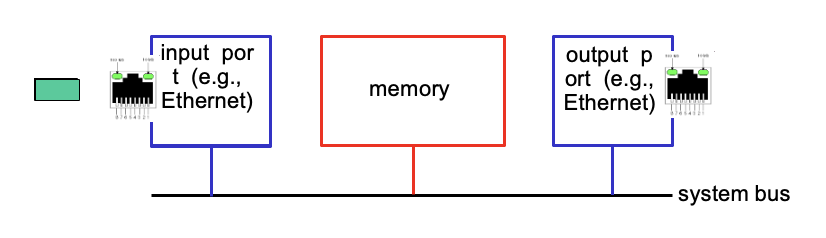
Input port
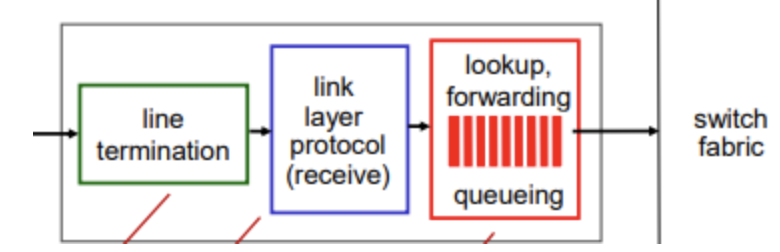
line termination : physical 계층 기능
link layer protocol : link 계층 기능
lookup, forwarding, queueing
- 헤더 값을 보고, forwarding table을 사용하여 나가야할 올바른 output port를 찾음 : forwarding
- 내보내는 속도보나 새로운 datagram이 들어오는 속도가 빠르면 queue에 저장 : queueing
- 두가지 방식 존재
destination based forwarding: 목적지의 IP주소만 보고 forwarding. 전통적인 방법generalized forwarding: 헤더 필드의 어떤 set을 보고 forwarding
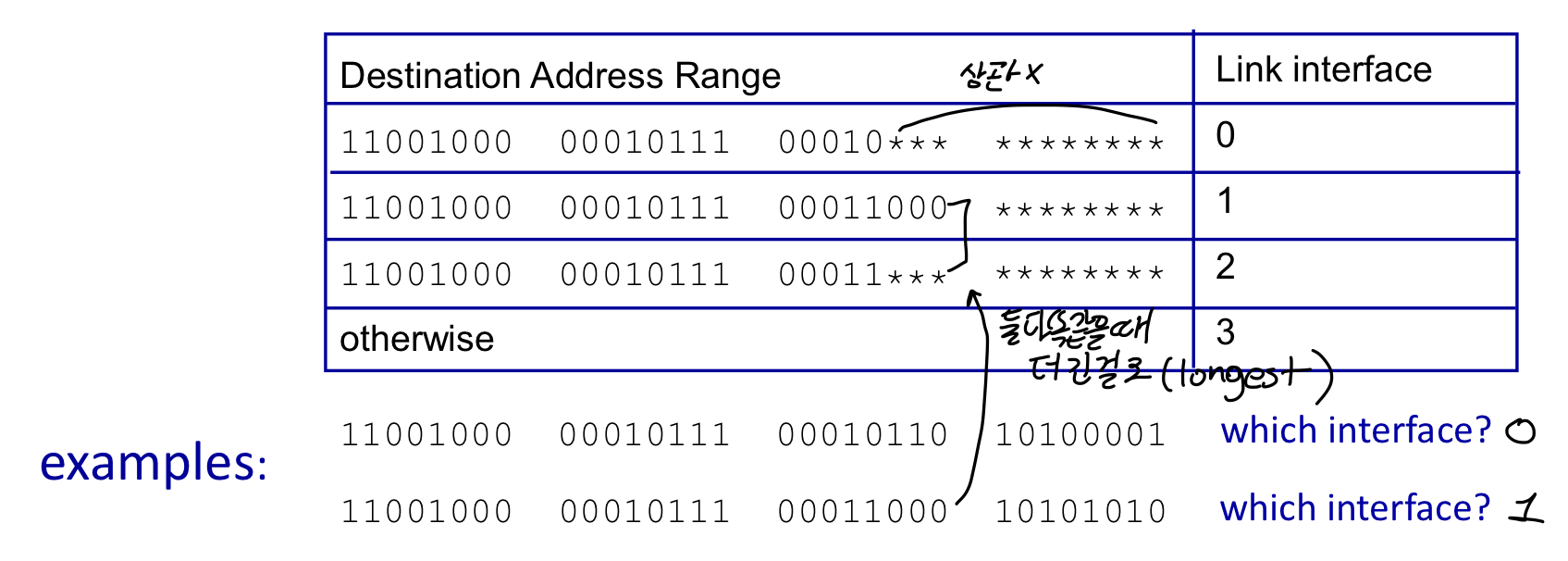
destionation-based forwarding
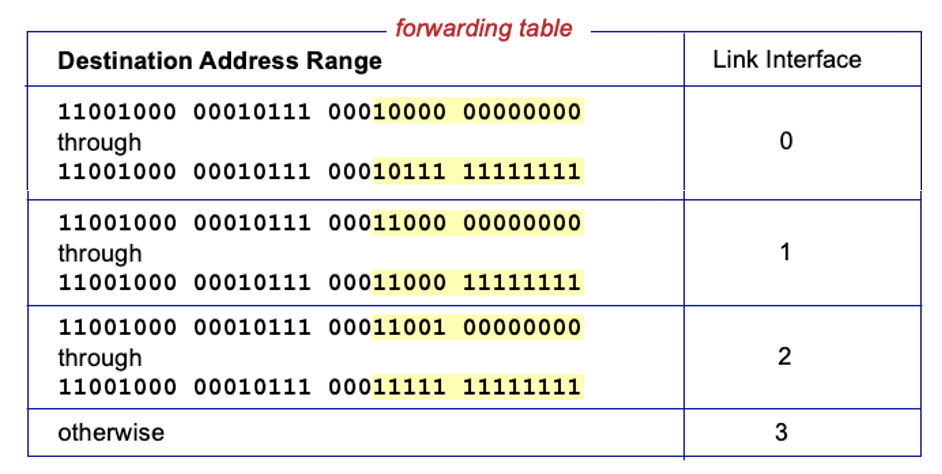
앞의 부분은 신경쓰지 않고 노란색 부분만 보고 판단하여 링크를 정함
헤더 32bit에서 앞의 반은 네트워크 주소, 뒤는 호스트 주소
longest prefix matching : 목적지 주소에서 일치하는 것이 여러개 있다면 가장 길게 매칭된 주소를 사용하는 것
Switching fabrics
패킷을 input link에서 적절한 output link로 전송 → 속도가 빨라야함
switching rate : 패킷이 전달될 때의 전송률
크게 3가지 방식이 있음
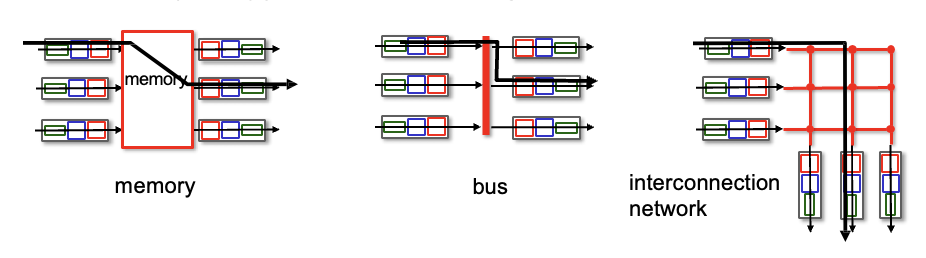
-
Switching via
memory
전통적인 컴퓨터는 CPU가 switching 제어
패킷은 시스템의 메모리에 copy됨
즉, input port → memory → output 경로
메모리의 대역폭에 따라 속도 제한되므로 느림
-
Switching via
busCPU 관여 X
datagram이 shared bus를 통해 input port에서 output port로 이동
→ 동시에 사용할 수 없으므로 버스 차지를 위해 경쟁
→
bus contention: 버스의 대역폭에 따라 switching 속도 제한됨32 Gbps bus 정도면 충분 (Cisco 5600)
-
Switching via
interconnection networkCross bar 이용하여 동시에 데이터를 전송할 수 있어짐 → 속도 빠르다
multistage swtich : 더 작은 크기의 switch들로 쪼갬
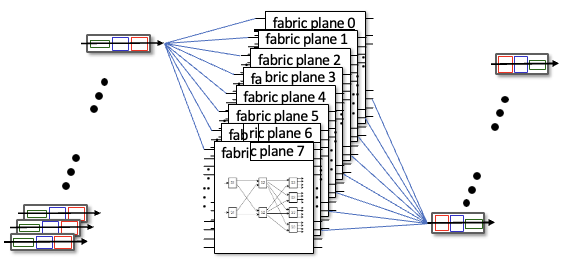
이런식으로 multiple switching도 가능 → parallelism : 속도 향상, 규모 커짐
Input port queueing
만약 switch fabric의 내보내는 속도가 input port에 datagram이 들어오는 속도보다 느리다면 input port에서 queueing 생김 → overflow나면 딜레이와 loss 생길 수 있음
HOL blocking : 맨 앞에 있는 head가 못나가면 그 뒤에것도 못나감
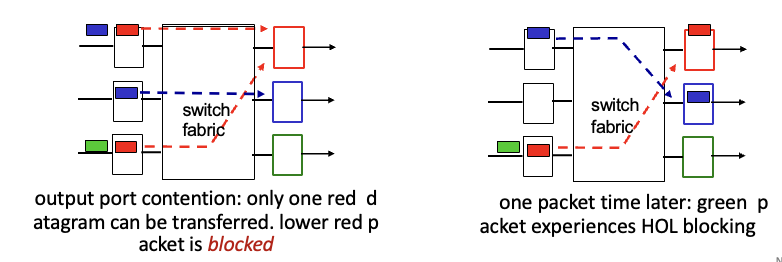
도착지가 같은 패킷은 한번에 2개 동시에 갈 수 없음 → 더 늦었던 red packet은 blocked
2번째 그림에서 red packet이 용량이 크다면 green은 HOL blocking된 상태
Output port queueing
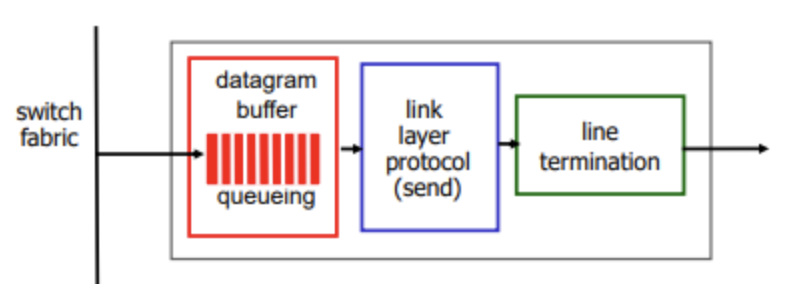
link의 전송 속도보다 datagram이 fabric으로 들어오는 속도가 빠르면 buffering이 발생
→ 버퍼 용량이 부족하거나 congestion이 발생하면 datagram의 loss가 발생할 수 있음 : output port buffer overflow로 인해 queueing(delay) 과 loss 발생
버퍼의 용량 너무 커지면 RTT증가 → delay 증가 (loss는 적게 일어날지라도)
keep bottleneck link just full enough but no fuller!
어떤 datagram이 drop될 것인가?
스케쥴링은 어떤 datagram을 먼저 전송할 것인지 결정함
Buffer Management
drop : 버퍼가 꽉 찼을때 어떤 패킷을 버릴지
- tail drop : 꽉찬상태에서 도착하는 패킷들을 버림
- priority : 우선순위가 낮은 것을 버림
marking : network congestion을 표시하여 보내는 양을 줄이도록 하는 것
Packet Scheduling
packet scheduling : 어떤 패킷을 먼저보내고 어떤걸 드랍해야할지
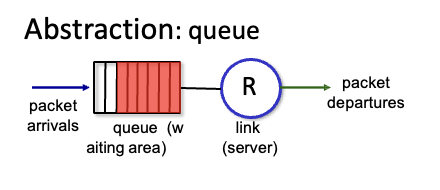
- FCFS
- priority : 헤더에 표시되어서 옴
- Round Robin
- weighted fair queueing : 가중치
-
FCFS: 도착한 순서대로 output link로 나감FIFO(first in first out)이랑 동일
-
Priority Scheduling: 헤더 필드를 보고 우선순위가 높은 것과 낮은것을 구분하여 전송동시에 여러개가 도착하면 우선순위가 높은 것이 우선이며, 우선순위가 같다면 먼저온게 우선
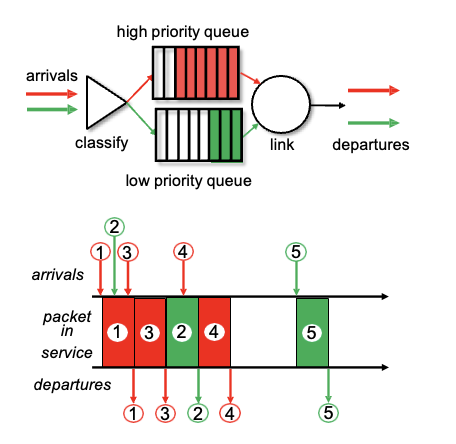
앞의 1,2,3은 FCFS라면 1,2,3 순서로 나가겠지만 여기선 우선순위에 따라 1,3,2가 됨
-
Round Robin: 도착한 패킷들을 여러 개의 class로 나눈다 → 어떤 헤더필드도 기준이 될 수 있음여러 class들에서 돌아가면서 패킷을 보내는 방법
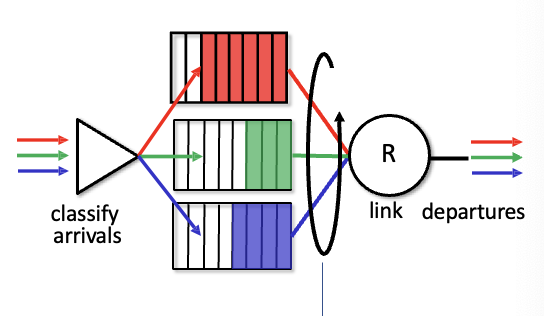
-
**Weighted Fair Queuing (WFQ)**: RR과 비슷한데 각 클래스마다 가중치를 줘서 최소 대역폭을 보장해줌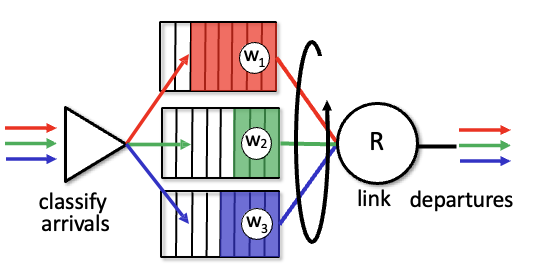
Network Neutrality : 망 중립성
→ 인터넷에 접속하는 모든 사용자가 동등하게 망을 사용할 수 있도록 하는 것.
📌 IP (the Internet Protocol) : datagram format, addressing ,network address translation, IPv6
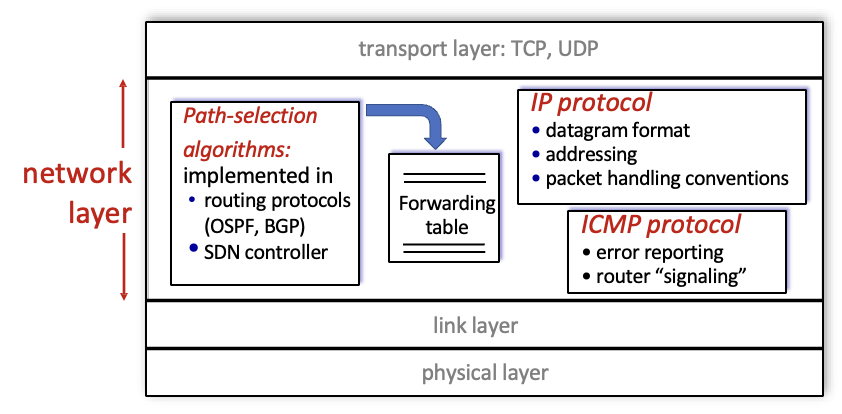
host, router에서의 4계층에서 하는 일들
- 경로 선택 알고리즘 → forwading table 생성 routing protocols, SDN controller 2가지 방법이 있음
- IP protocol : datagram format, addressing, packet handling conventions
- ICMP protocol : 에러 report, router signaling - 패킷이 목적지에 도착할 수 없을때 알림
IP datagram format
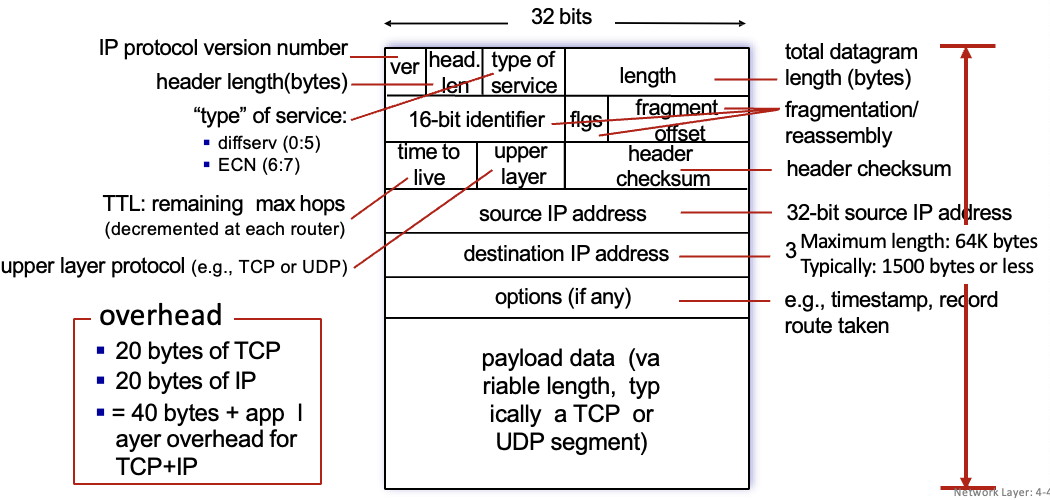
ver : IP 프로토콜 버전 → IPv4 or IPv6
head len : 헤더 길이(byte)
2번째 줄은 IP 자르고 다시 합치는 내용에 대한것 (옛날에) → link 계층 size다 다르므로
source IP 주소, dest IP 주소 중요
option까지가 header 그 아래는 transport layer에게 받은 data부분
IP addressing
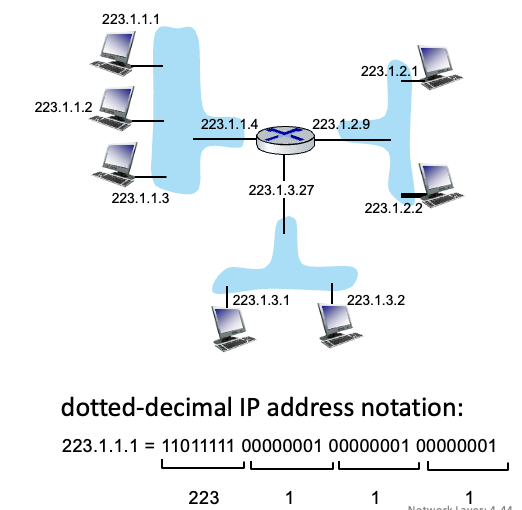
IP 주소 : 각 호스트나 라우터의 interface와 관련된 32bit 주소
interface : 호스트/라우터와 물리적인 링크 사이의 connection
- 하나의 라우터는 여러개의 interface가 있으므로 여러개의 IP주소를 가짐
- host는 대부분 1 or 2개의 interface를 가짐
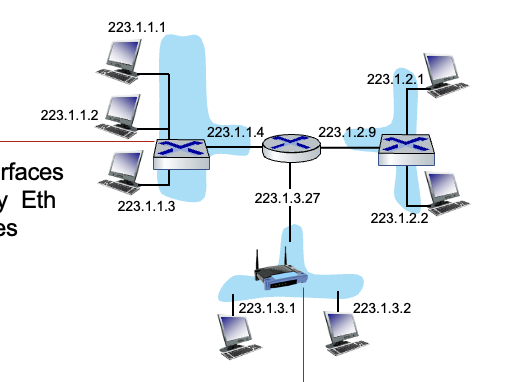
wired Ethernet interface는 switch로 연결되어 router에 연결
wireless WiFi interface는 WiFi base station으로 연결되어 router에 연결
Subnet : router를 거치지 않고도 물리적으로 도달할 수 있는 interface → 위 그림에서 하늘색 부분
IP 주소의 구조
subnet part: 같은 subnet에 있는 기기들끼리는 동일한 high order bits를 가짐 → 예를들어 223.1.1 요부분까지- host part : 남은 low order bits
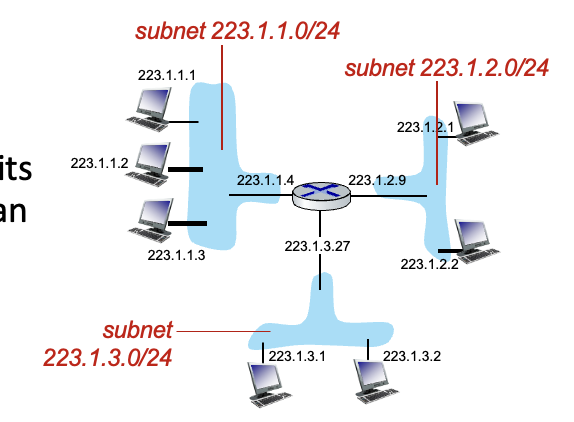
각 interface를 host or router에서 분리해서 독립적인 네트워크 구축
223.1.1.0 subnet이 이 있으면 0앞에까지는 같은 subnet끼리 동일
위 그림은 subnet mask : /24 → 상위 24비트까지 subnet part라는 의미
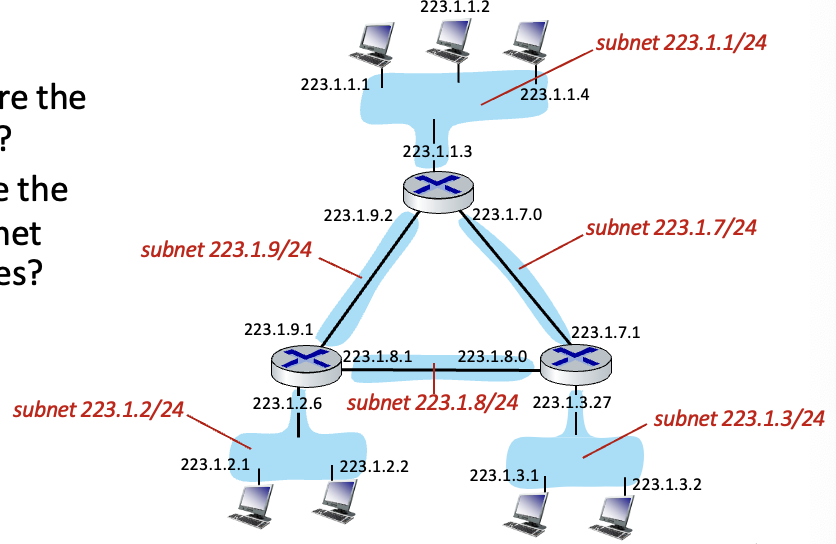
이때 subnet 6개 존재하고 /24 subnet임 → 32bit 중 24가 subnet part, 8bit가 host part
**CIDR** : Classless InterDomain Routing
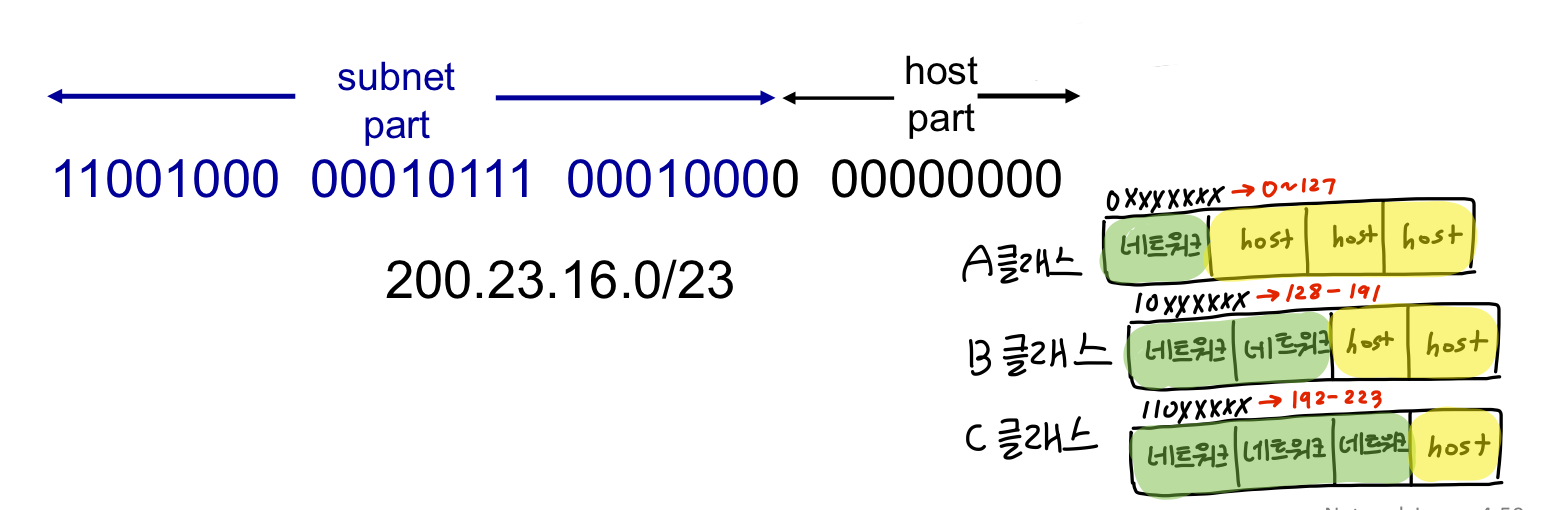
원래는 클래스별로 subnet, host part의 길이가 정해져있었음 → 임의의 길이의 주소에서 subnet part를 정의할 수 있도록 해줌
주소 포맷 : a.b.c.d/x → x가 subnet part의 길이
host가 필요한 만큼만 쓰면서 불필요한 낭비를 줄임
Q. 어떻게 호스트가 자신의 network안에서의 IP 주소를 얻게되는지? → host part
- hard-coded
DHCP: Dynamic Host Configuration Protocol 서버에서 동적으로 주소 받음 plug-and-play
Q. 어떻게 network가 IP 주소를 얻는지 → network part
DHCP : Dynamic Host Configuration Protocol
호스트가 network에 들어왔을때 네트워크 서버로 부터 동적으로 IP 주소를 받을 수 있어야함
- 호스트에게 IP 주소 임대해줌
- 주소의 재사용도 허용
- 모바일 지원
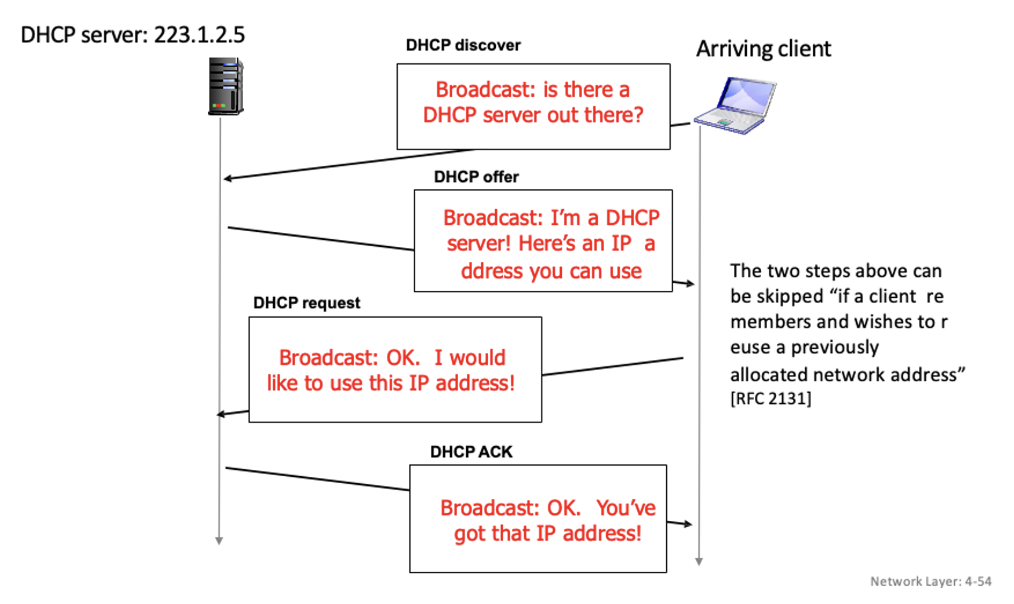
순서
- host는 DHCP discover msg를
broadcast: IP 주소discover - DHCP server가 DHCP offer msg로 응답 :
offer - host는 DHCP request msg 보내면서 IP 주소 요청 :
request - DHCP server는 DHCP ack msg보내면서 주소 보내줌 :
ack
DHCP 서버는 보통 라우터 내에 위치 → 라우터에 붙은 모든 서브넷 지원해주기 위해
위의 2단계는 client가 전에 받은 주소를 기억하고 재사용을 원할 경우에는 스킵 가능 (당연히 아무도 안쓰고 있을때)
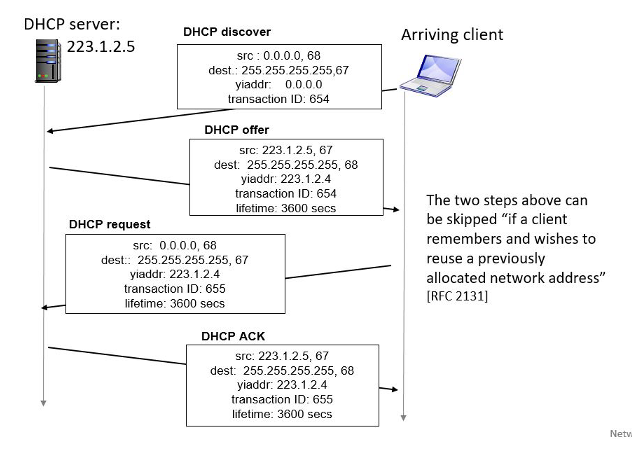
주고받는 내용
- src, dest IP 주소
- yiaddr : 쓸 IP
- life time : 사용할 수 있는 시간
DHCP는 할당된 IP 주소뿐만 아니라 다른 것들도 같이 제공
- client의
first-hop router의 주소: 게이트웨이 DNS 서버의 이름과 IP 주소- network
subnet mask: 받은 IP 중에서 몇 bit가 host이고 몇 bit가 subnet인지 알 수 있어야하므로 → ex) 128.0.0.1이렇게만 오는데 여기서 24bit인지 이런거…
DHCP : example
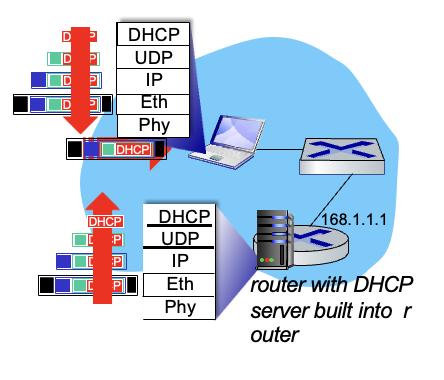
DHCP를 사용하여 노트북을 연결시키려고함 : IP 주소, first-hop-router, DNS 서버의 주소를 받아야함
→ DHCP request mssg는 UDP, IP, Ethernet에 의해 encap 되어 아래 계층으로 내려감
→ 2계층에서 broadcast를 하고 router에 있는 DHCP 서버가 이를 받음
→ 라우터에서 demux 과정을 거침
→ DHCP 서버에서 클라이언트가 사용할 IP 주소, first-hop-router, DNS 서버의 이름과 주소를 담은 ACK를 생성
→ encapsulated해서 클라이언트에게 보내고, 클라이언트는 demux
→ 클라이언트는 필요한 정보들을 모두 알게됨 : IP 주소, DNS서버 주소와 이름, first-hop-router
어떻게 네트워크가 subnet part의 IP 주소를 얻을 수 있는지
→ 밑줄쳐진 부분이 ISP’s block부분임. 마지막 n개 비트로 구역 구분 가능

위에서는 마지막 3비트 (000, 001, 010, …)로 구역 나눔 → 2^3 : 8개 구역 구분 가능
Hierarchical addressing
계층적으로 addressing하는 것이 더 효율적
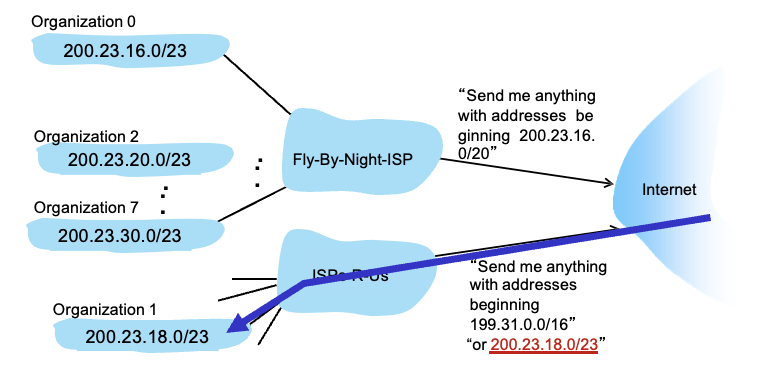
조직 1이 위에서 아래쪽으로 옮겨간 상황이지만 주소를 변경할 필요가 없음
200.23.16.0/20과 200.23.18.0/23중에서 뒤에께 더 longest prefix이므로 어차피 아래쪽으로 가게됨
ISP는 ICANN으로부터 주소 블록 할당 받음
32bit의 IP주소로 충분한가? → 택도 없음 → NAT으로 IPv4보완하지만 이것도 부족하여 IPv6 사용하는 추세
NAT : network address translation
local network안의 모든 디바이스는 밖으로 나갈때는 하나의 IPv4 주소를 공유하도록 함
또한 밖으로 못나가고 내부적으로 사용하는 32bit 주소를 가짐
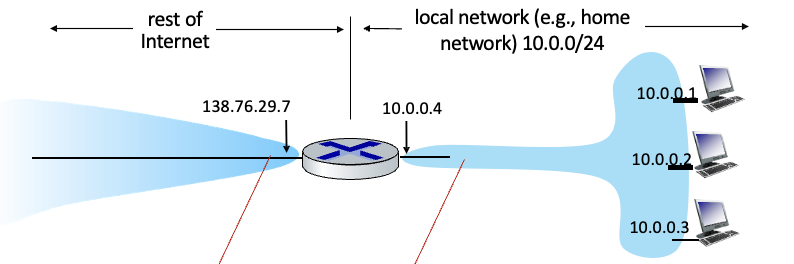
모든 datagram은 local network를 떠날때 같은 source IP address : 138.76.29.7을 사용
장점
- ISP가 하나의 IP 주소만 제공해주면됨 →
나갈때 하나만 있으면됨 - local network 안의 host들의 주소를 밖에 알리지 않고 변경 가능
- ISP 주소를 바꿀때 local network들은 영향 받지 않음
- 보안 : 내부에 직접적으로 연결되지 않음
구현 : NAT router가 있는데 없는 것 같이
- 나가는 datagrams : 밖으로 나갈때 source IP 주소, port # → NAT IP 주소, 새로운 port #으로
변환해줌 - 원래의 IP주소와 포트번호를
NAT translation table에 기록 - 들어오는 datagrams : NAT table 참고하여 다시 바꿔줌
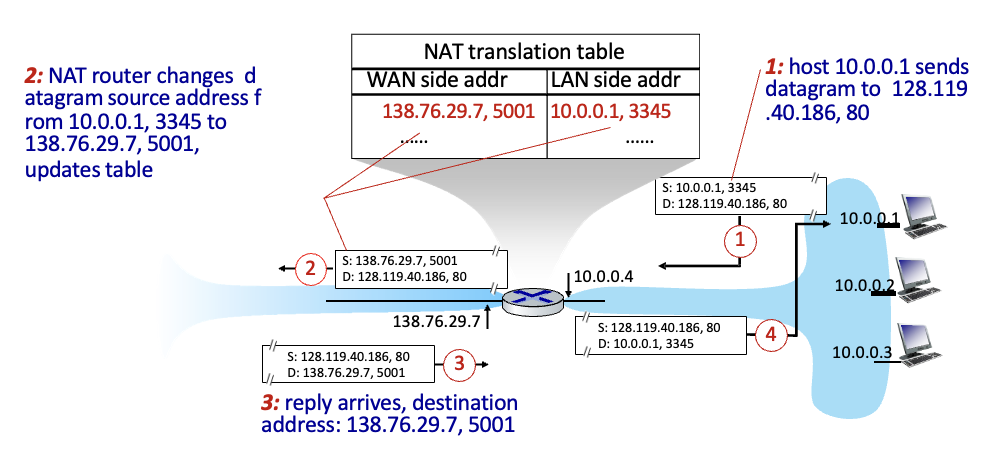
- host가 datagram 전송 : 이때 IP는 10.0.0.1, port는 3345
- 공인 IP 주소와 새로운 port 번호로 바꿔주고 NAT translation table에 기록하여 내보냄
- 답장이 돌아옴
- NAT table을 보고 다시 변환해서 올바른 host에게 전달해줌
이때 IP번호는 다 동일하므로 Port 번호는 다르게 설정해줘야 구분가능
NAT에 대한 논쟁
- 라우터는 3계층까지만 processing해야함
- end-to-end 규칙을 어김 → Port는 4계층이고 계층끼리만 통신해야하는데 위반
- IPv6으로 해결 가능한 문제들임
- NAT 안에 있는 서버랑은 어떻게 통신할건지?
- 그렇지만 IP가 많이 필요하므로 아직 NAT 사용한다
IPv6
32bit의 IPv4 주소들은 이미 다 사용됨
40 byte의 수정된 헤더 → processing/forwarding 빨라짐
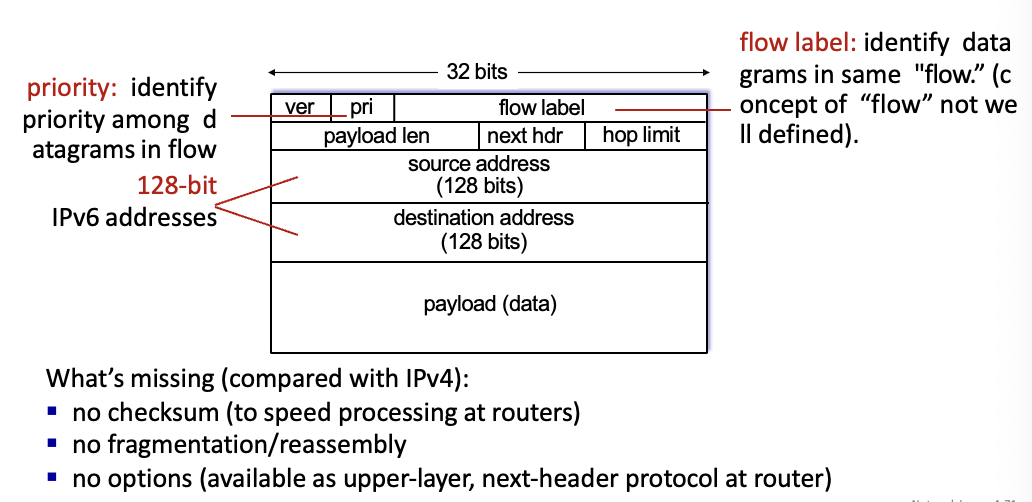
IPv4에 비해 여러가지가 사라짐 → checksum, 자르고 재조합, option 다 필요 X
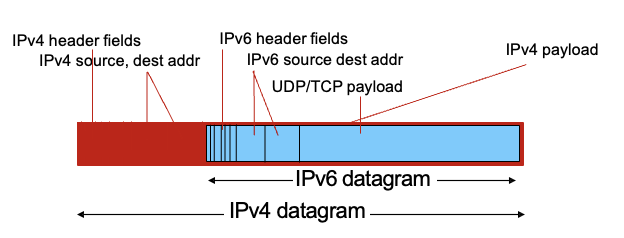
모든 라우터들을 동시에 IPv6으로 업그레이드 할 수는 없음 : 둘다 사용하고 있는 상황
tunneling : IPv6 datagram을 IPv4에 싸서 전달 → 겉에서 봤을땐 IPv4처럼 보임
IPv6/v4 둘다 이해하는 것을 dual stack이라고함
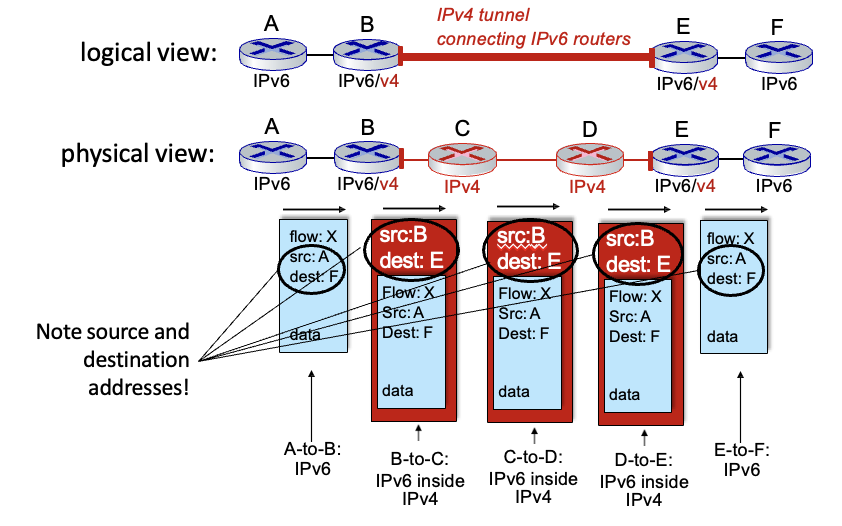
B→C : IPv4 헤더를 붙여서 IPv4 라우터를 통과시킴
D → E : IPv4의 헤더를 확인해서 IPv6을 감싸고 있다는 것을 확인하여 decapsulation
점점 IPv6 사용 늘고있는 추세다
📌 Generalized Forwarding, SDN : Match+action, OpenFlow
Generalized forwarding : match + action
각 라우터 마다 forwarding table(flow table)을 가짐
match + action : 도착한 패킷의 비트를 매치시키고 액션 수행
destination based forwarding : 목적지의 IP주소를 베이스로 forward
generalized forwarding : 여러 헤더 필드가 액션을 결정 가능 → drop / copy / modify / log packet
Flow table abstraction
flow : 헤더 필드의 값에 의해 결정됨 → in link-, network-, transport-layer fields
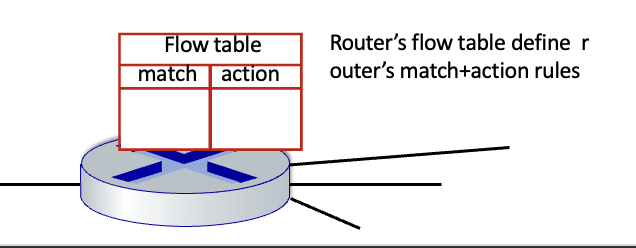
match : 패킷의 헤더에 있는 똑같은 값 찾음
action : 패킷에 대해 drop, forward, modify 등의 액션 수행
priority : 중복되는 패턴이 있을 때 사용
counters : 몇개 이동했는지
중요한건 match : 똑같은 애 찾아서 → action : 행동

src와 dest를 둘다 이용하여 더 유연해짐
*은 아무거나 의미하는 것
OpenFlow
OpenFlow : 네트워크 스위치나 라우터의 forwarding에 접근 권한 제공하는 통신 프로토콜
SDN에서 사용하는 기술
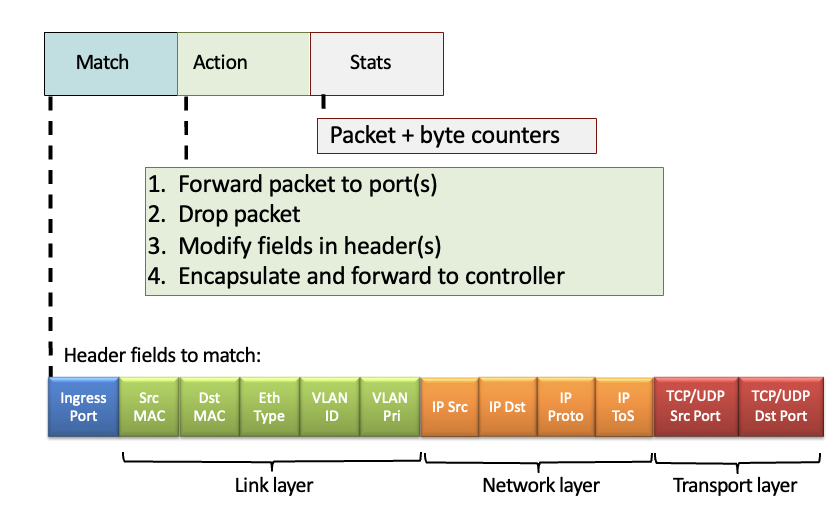
다양한 헤더필드가 있음
OpenFlow 예시


OpenFlow abstraction
- Router
- match : IP 주소 longest prefix
- action : link로 포워딩
- Switch
- match : dest MAC 주소
- action : foward or flood
- Firewall
- match : IP 주소와 포트 넘버
- action : permit or deny
- NAT
- match : IP주소와 포트
- action : 주소와 포트 다시 생성
이런 모든 기능들을 OpenFlow로 정의할 수 있다
OpenFlow 예시
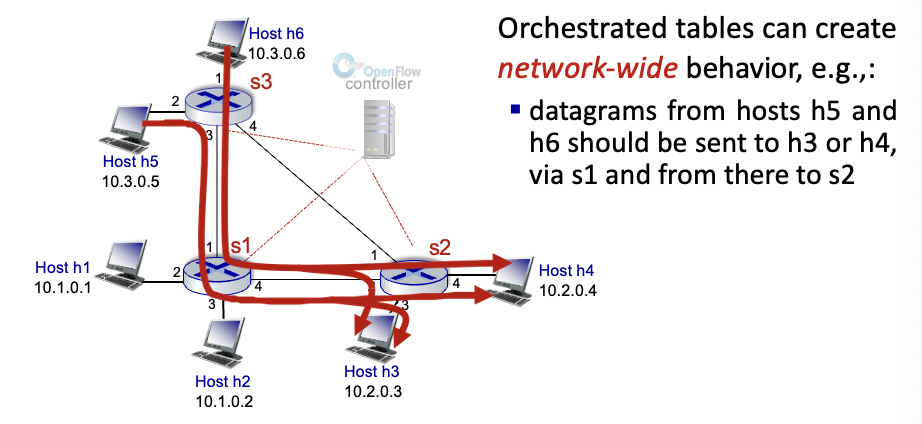
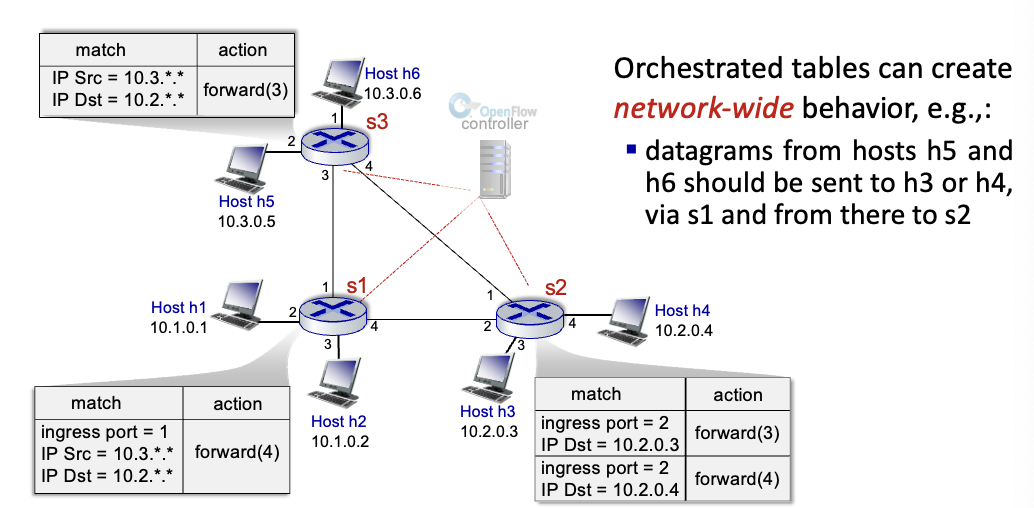
외부의 controller가 계산하여 flow table 생성 ↔ 원래 방식은 router 내부에서
📌 Middleboxes
Middlebox : source host와 dest host 사이의 데이터 경로에서 IP 라우터의 표준 기능 이외의 모든 나머지 기능을 하는 중간 box → 즉 routing, forwarding 제외한 나머지 기능들
ex) NAT
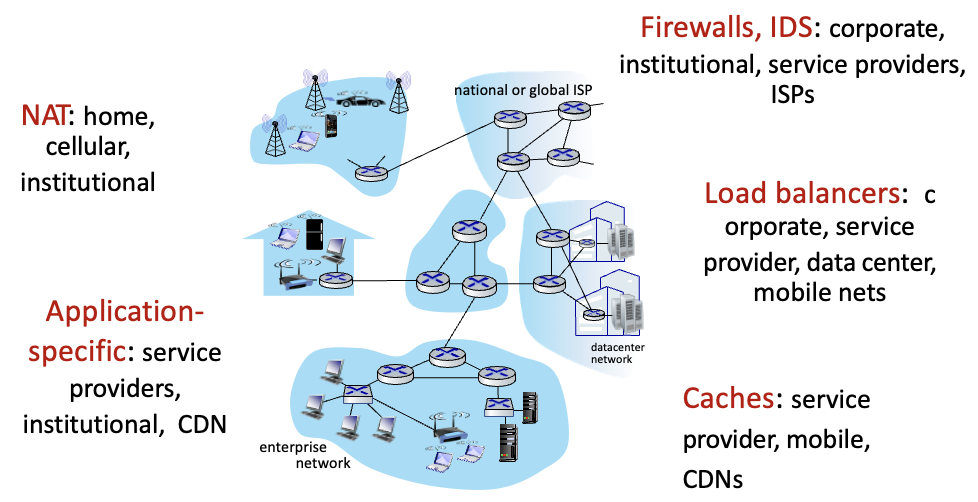
위의 모든것들이 다 middlebox 어디에나 있음
처음에는 hw solution이였는데 white box로 이동 → local action들 programmable
The IP hourglass
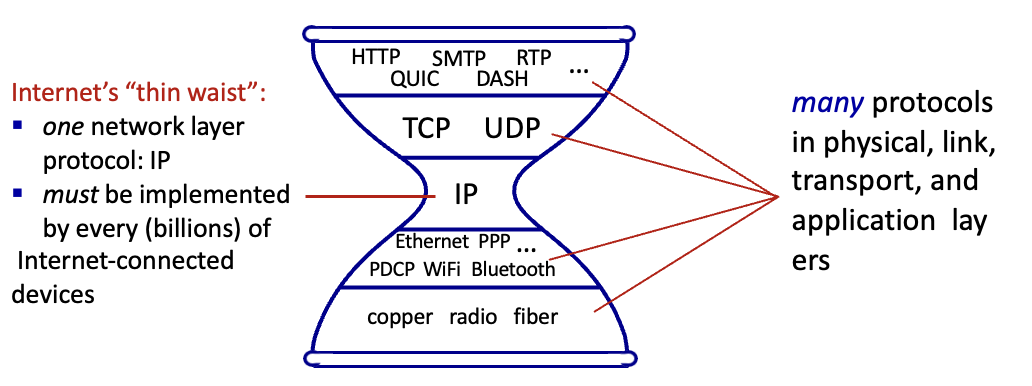
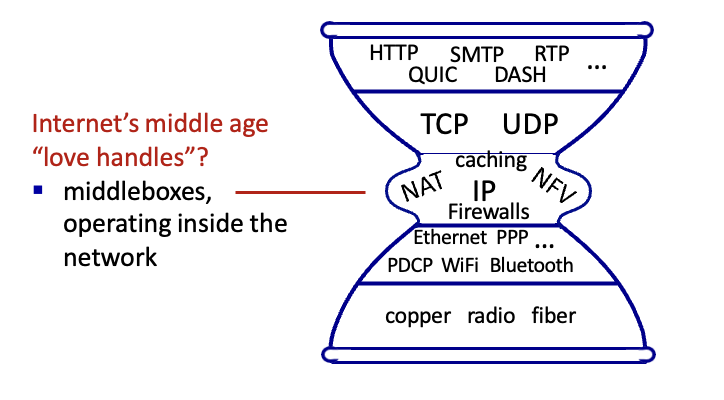
1,2,4,5 계층에는 다양한 protocol이 존재하나 3계층에는 IP만 존재했으나 middle box로 인해 더 많은 것들이 생김
인터넷에서 중요한것들
- simple connectivity
- IP protocol : narrow waist → 중간에는 적은 기능만
- 종단은 더 똑똑하고 복잡하게
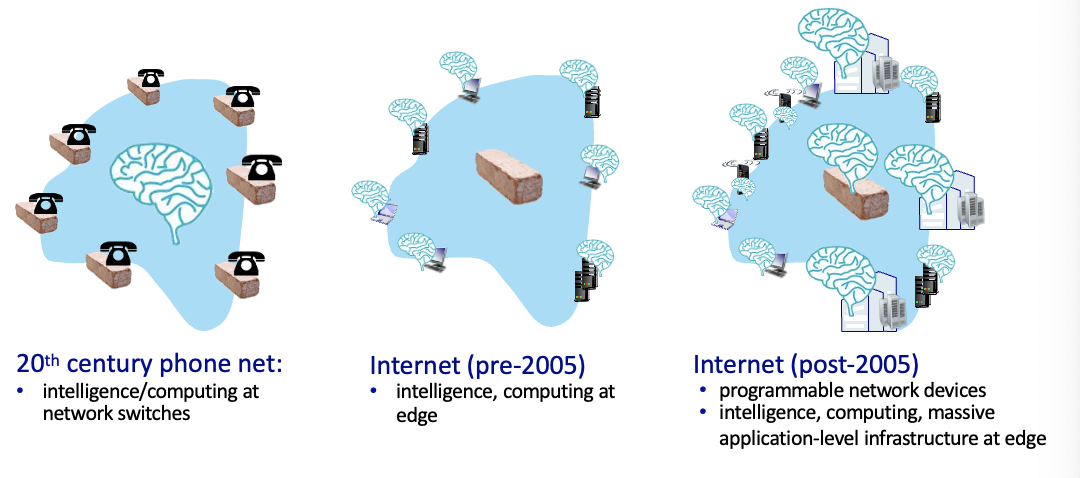
시대에 따라 종단이 똑똑해지도록 발전하고 있음
