- 9:00 ~ 10:00 : 코드카타
- 10:00 ~ 11:00 : 아티클 읽고 정리
- 11:00 ~ 12:00 : 기초 통계 세션
- 12:00 ~ 15:00 : 세션 내용 복습, 코드필사 (중간에 밥도 먹음🍚)
- 15:00 ~ 15:20 : 아티클 스터디
- 15:20 ~ 18:00 : 강의듣기 (머신러닝 선형 회귀 적용까지)
- 19:00 ~ 19:30 : 오후 스크럼
- 19:30 ~ 20:30 : 머신러닝 세션
- 20:30 ~ 21:00 : TIL 작성
코드카타
없는 숫자 더하기
def solution(numbers):
a = sum(range(10))
b = sum(numbers)
answer = a - b
return answer따봉 많이 받은 풀이.
def solution(numbers):
return 45 - sum(numbers)이 분은 0부터 9까지 더한 값을 얘초에 넣어버리심
그리고 변수 선언도 안하니까 깔끔하게 나옴..!
아티클 스터디
기초 통계 세션
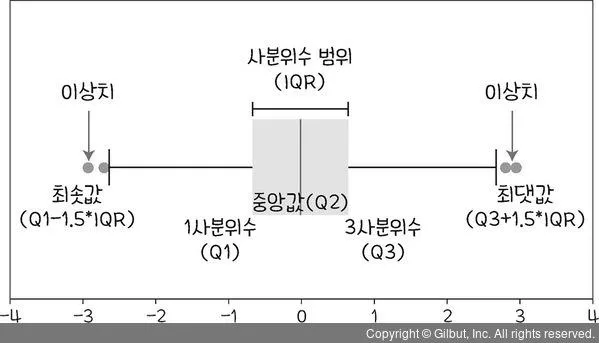
사분위
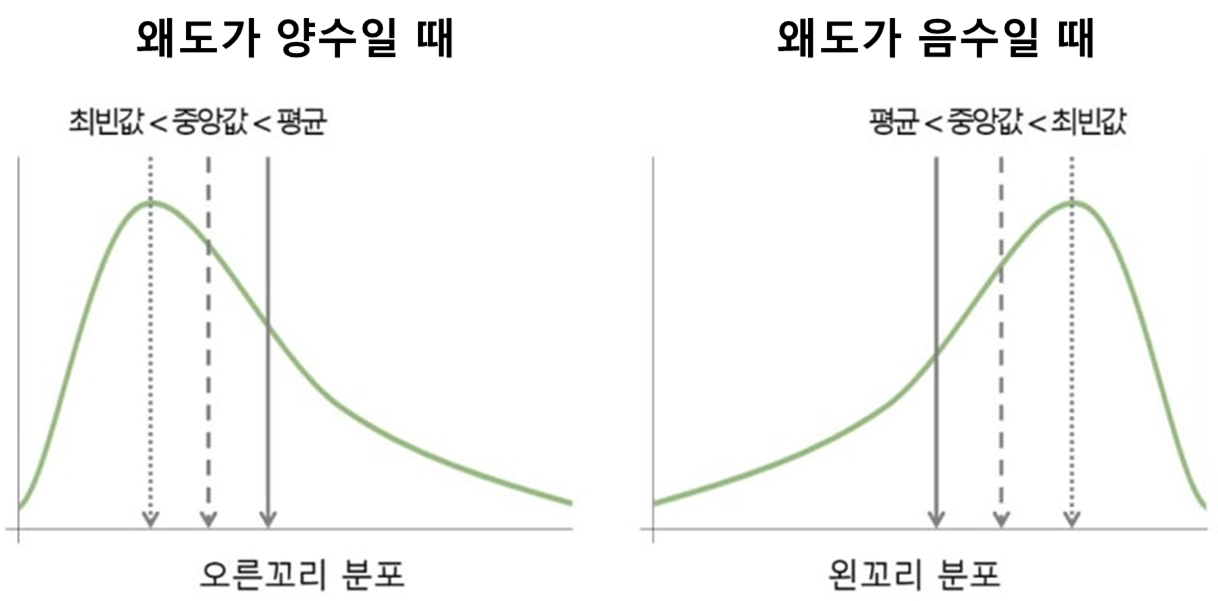
왜도 (Skewness)
좌우로 치우친 정도
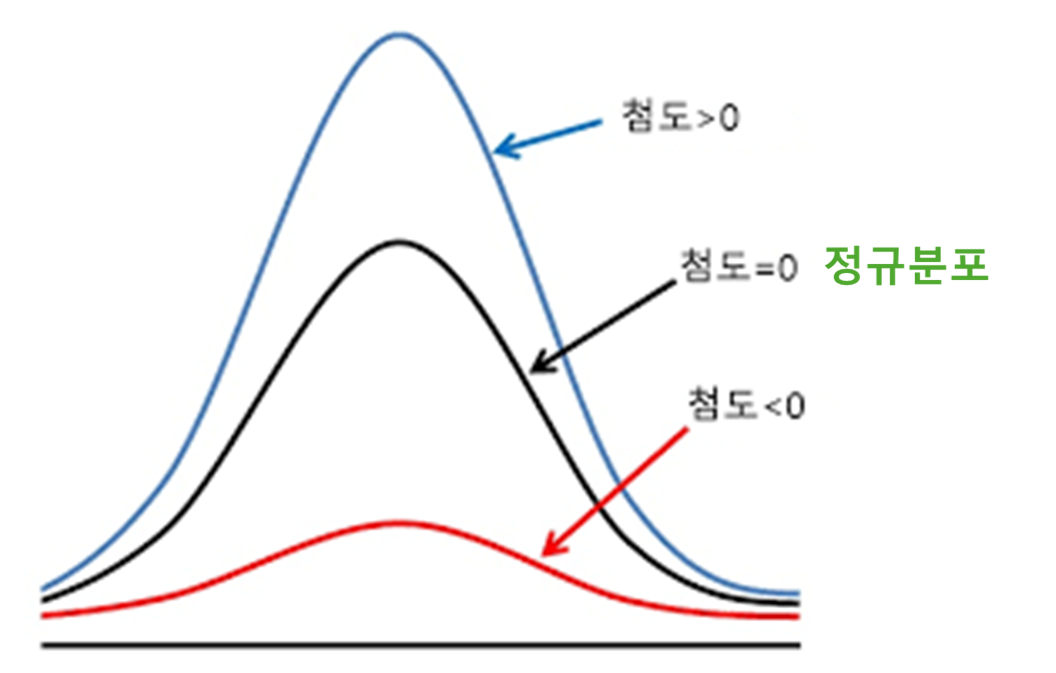
첨도 (Kurtosis)
뾰족한 정도
정규분포를 기준으로 비교함.
정규분포는 첨도 3에 왜도 0임. (근데 엑셀이나 판다스에선 편하게 정규분포를 0으로 잡음..!)
정규분포
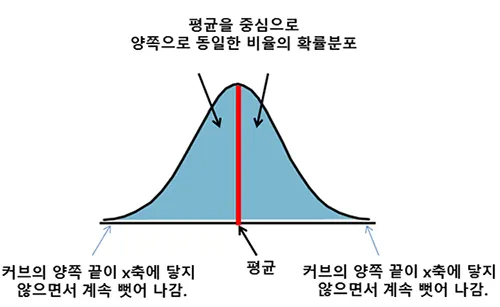
- 평균을 기준으로 좌우 대칭
- y는 확률값, 곡선 아랫부분 다 더하면 1
- 평균, 분산에 따라서 정규분포도 다양한 모양을 가지게 됨
- 평균 0, 분산 1인 경우, 이걸 표준정규분포라고 함
코드필사
퀴즈
Q1. C Q2. C Q3. C Q4. D Q5. D
Q6.
data = [
151, 154, 160, 160, 163, 156, 158, 156, 154, 160,
154, 162, 156, 162, 157, 162, 162, 169, 150, 162,
154, 152, 161, 160, 160, 153, 155, 163, 160, 159,
164, 158, 150, 155, 157, 161, 168, 162, 153, 154,
158, 151, 155, 155, 165, 165, 154, 148, 169, 158,
146, 166, 161, 143, 156, 156, 149, 162, 159, 164,
162, 167, 159, 153, 146, 156, 160, 151, 151, 157,
151, 156, 166, 159, 157, 156, 159, 156, 156, 161
]
#시리즈로 만들기
s = Series(data)
#히스토
plt.figure(figsize=(8,5))
plt.hist(s, bins=6, edgecolor='black')
plt.title('Height Distribution')
plt.xlabel('Height (cm)')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()| 계급 | 도수 | 상대도수 | 누적도수 |
|---|---|---|---|
| 141 ~ 145 | 1 | 0.0125 | 1 |
| 146 ~ 150 | 6 | 0.0750 | 7 |
| 151 ~ 155 | 19 | 0.2375 | 26 |
| 156 ~ 160 | 30 | 0.3750 | 56 |
| 161 ~ 165 | 18 | 0.2250 | 74 |
| 166 ~ 170 | 6 | 0.0750 | 80 |
| 80 |
인사이트
상황에 따라 평균/중앙값/최빈값 적합한 거 사용해야겠다 느꼈고,
ADsP를 준비하고 있는 만큼, 왜도랑 첨도 그래프 보고 바로 판단할 수 있게끔 익혀놔야겠다고 생각함.개인학습시간
머신러닝_1-6~1-9
선형 회귀 -> 제일 최적화된 직선 찾기
Y -> 종속/결과 변수. 알고싶은 값
X -> 독립/원인 변수. y한테 영향을 주는 값

여기서 기울기(편향, 가중치)는 어떻게 구하냐?
추정하거라~ 데이터가 충분히 있다면 추정할 수 있음.
.
MSE -> 회귀 평가지표 중 하나임
Mean Squared Error. 딱 직관적임. 역방향으로 해석하면 됨.
오차(실제값-추정값)를 제곱해서 평균내어라~
오차가 젤 적은 선이 최적화된 회귀선
그래서 오차를 구하고
합산하려니 양수, 음수 섞여있네? 제곱 해버리고
합산하니까 숫자가 넘 크네? 평균내버리기.
R square -> 선형 회귀에서만 평가되는 지표
아ㅏ 이거 이해 못한 듯. 낼 서칭해보기
.
선형회귀 적용 내용은 VS code로 진행했는데
어디서부터 어디까지 정리해야할 지 모르겠음..
!pip install scikit-learn # 요렇게 설치하고
import sklearn # 요렇게 실행함
from sklearn.linear_model import LinearRegression
model_lr = LinearRegression() # 지금부터 선형회귀 모델 쓸거야
model_lr.fit(X=x, y= y) # 명시 안하고 순서만 x,y 지켜서 넣어도 됨. x,y 뭔지는 VS code 드가서 보셈
# 이렇게 하면 지금 모델이 학습되어 있는 상태!
# 가중치(w1) 구하기
print(model_lr.coef_) # 명령어 웃기게 생겼네... 언더바로 끝나는게 말이됨?!
# 편향(bias, w0) 구하기
print(model_lr.intercept_) # intercept가 절편이라는 뜻
# 가중치랑 편향을 구했으니 요걸 잘 조립하면 선형회귀선이 되는거임
w1 = model_lr.coef_[0][0] # 위에 출력값 보면 대괄호 2개 씌워짐 -> 2차원 구조다
w0 = model_lr.intercept_[0] #얘는 1차원
print('y={}x + {}'.format(w1.round(2),w0.round(2)))
# print('y={}x + {}'.format(w1.round(2),w0.round(2)))scikit-learn
사이트에서 코드 예시를 보고 따라 작성하기
메소드에 대한 설명도 잘 나와있음
help(sklearn.linear_model.LinearRegression)인터넷이 안 된다면 입력해서 설명 봐도 됨
머신러닝 세션
머신러닝이란 뭐고 왜 필요한지, 어떤 종류가 있는지 배웠음
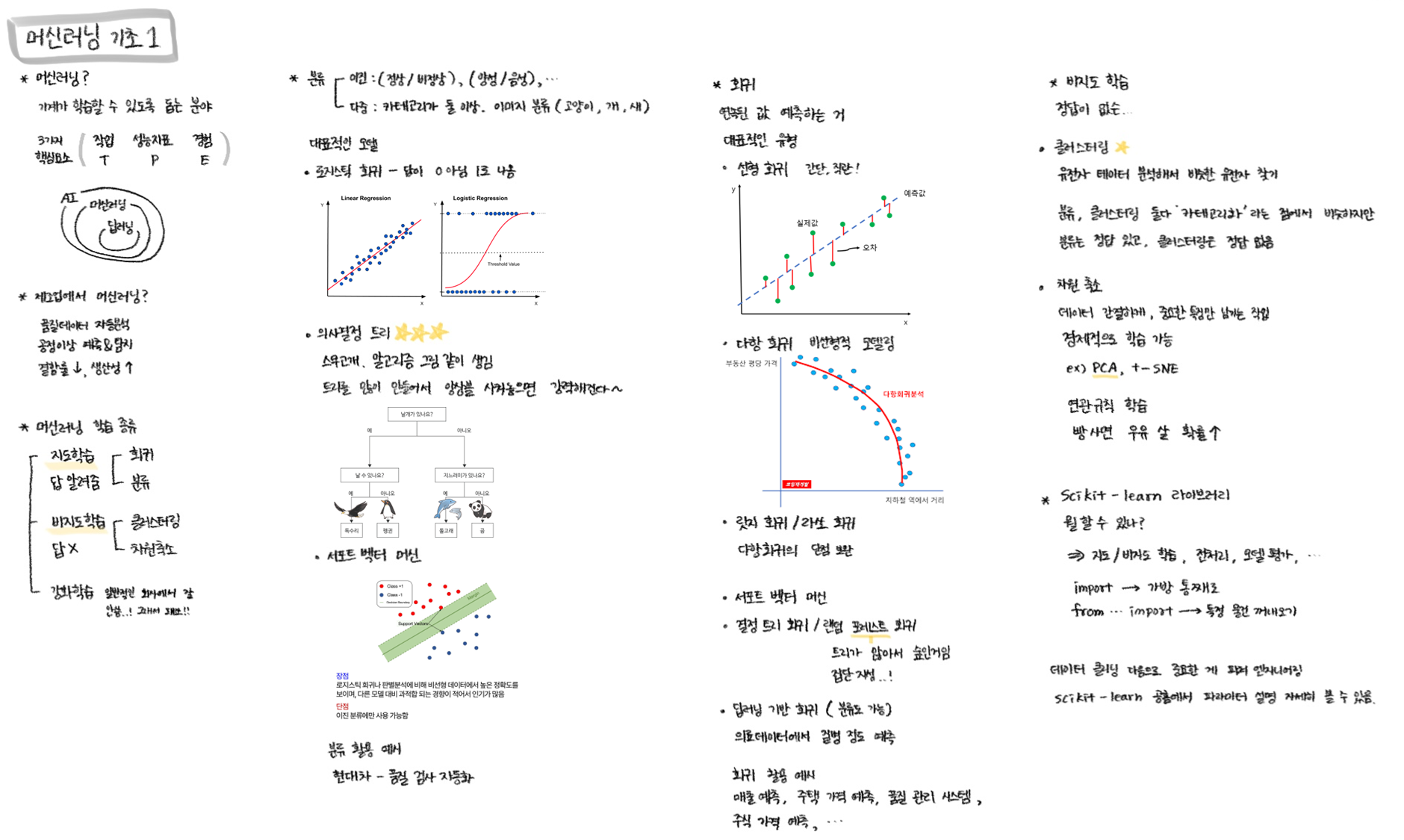
인사이트
머신러닝의 기본 개념과 학습 종류에 대해서 이해할 수 있었고,
QA/QC에서 주로 사용하는 모델들은 어떤 것들인지 알 수 있어 좋았다.
또한, 각 모델들이 실무에서는 어떻게 적용되고 있는지 예시 사례들을 많이 들을 수 있어서 유익했다.회고
통계는 영원히 내곁을 떠나지 않는구나 싶었고, 머신러닝은 아직까진 흥미롭다..!
오늘 생각보다 시간이 없어서 ADsP 기출은 못 풀었는데, 내일은 아티클 스터디도 없고 세션이 하나밖에 없으니 꼭 짬내서 풀어야지
오늘 TIL 마무리하다가 튜터님이 오셨음..!
했던 이야기들...
머신러닝 그래서 왜 필요할까?
머신러닝은 자동화만 해주는 게 아니라
아주 많은 요소들, 복잡한 관계들 속에서 패턴을 추출해주고
(사실 머신러닝이 다해주는 것도 아님)
단순히 불량을 잡아내는 것 뿐만아니라
어떤 요인 때문에 불량이 날 거라는 예측까지 가능해지는 거임
실무에서 어떻게 적용되는지 더 찾아봐야할 듯
뭘 배우던 간에 스스로 도식화 해보는 과정이 꼭 필요하다
이걸 면접에 어떻게 쓸 수 있을까를 항상 생각해보자
이게 진짜 취업에 도움이 될 지 의문을 제기해보자
계속해서 물음표 던지기
내배캠으로 드라마 하나 써야함
어떤 과정을 통해 어떻게 성장했다~내일 할 거
- 머신러닝 1-10 못들은 거 좀 일찍와서 듣기
- 통계 3주차
- 통계 세션 듣고 코드 필사
- ADsP 1,2과목 기출
- 피그마 활용하는 법 살짝 찾아보기
- R square 찾아보고 이해하기(시간 많이 쓰지마!)

내일배움캠프 사전교육 수강중