- 9:00 ~ 10:00 : 코드카타
- 10:00 ~ 11:00 : 오전 스크럼, 통계학 기초 강의듣기
- 11:00 ~ 12:00 : 통계 세션
- 12:00 ~ 13:00 : 세션 내용 복습
- 14:00 ~ 16:30 : 세션 내용 복습
- 16:30 ~ 18:00 : 세션 코드 필사
- 19:00 ~ 20:00 : ADsP 기출 풀기
- 20:00 ~ 21:00 : 오후 스크럼 및 TIL 작성
코드카타
def solution(arr):
list_a = []
for num in arr:
list_a.append(num)
list_a.remove(min(list_a))
if len(list_a) == 0:
answer = [-1]
else:
answer = list_a
return answer세션
확률변수, 확률분포
확률변수 --> 이산형/연속형 변수
이산형(Discrete) -> 셀 수 O
연속형(Continuous) -> 온도, 무게처럼 연속적인 값
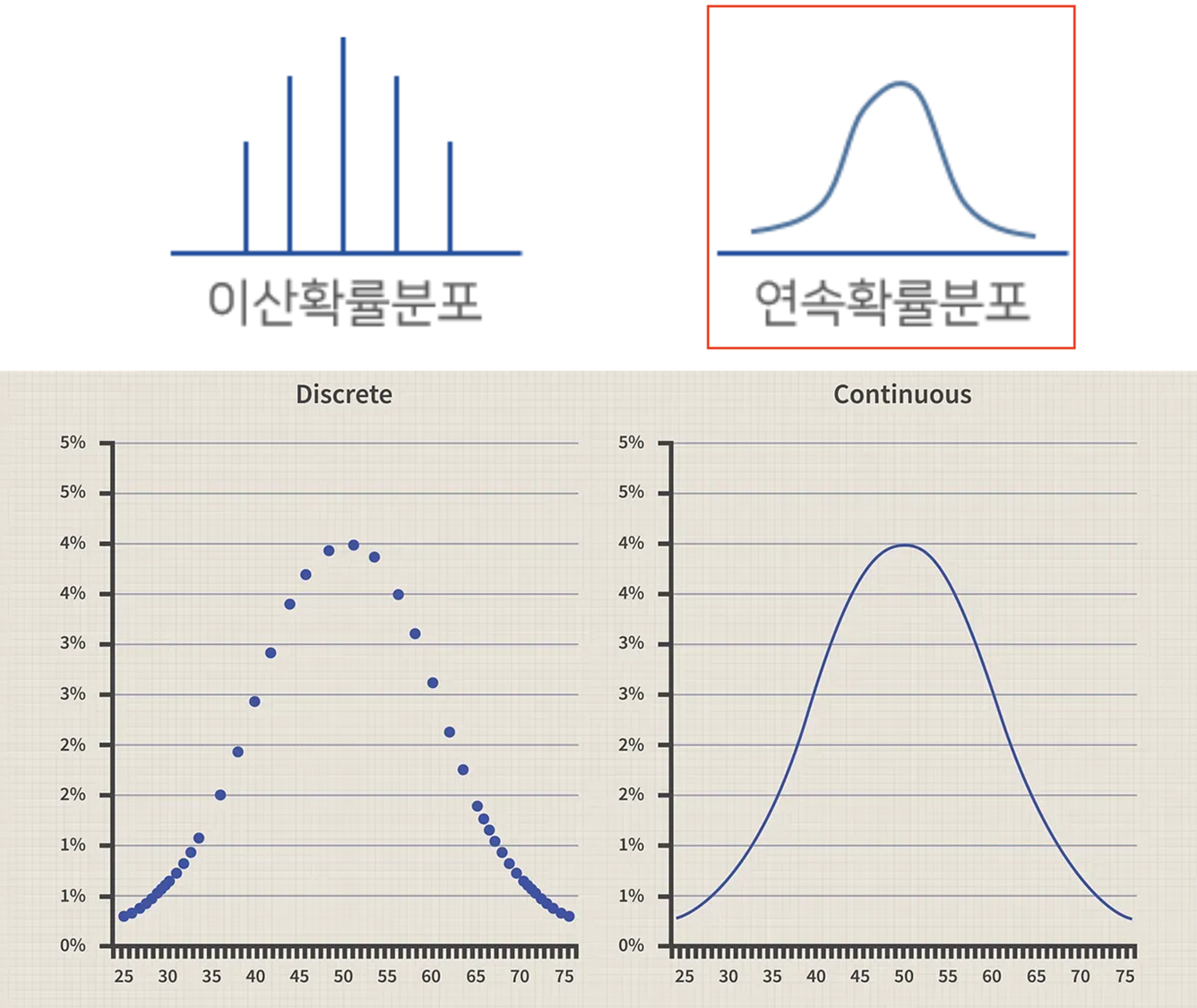
.
확률분포
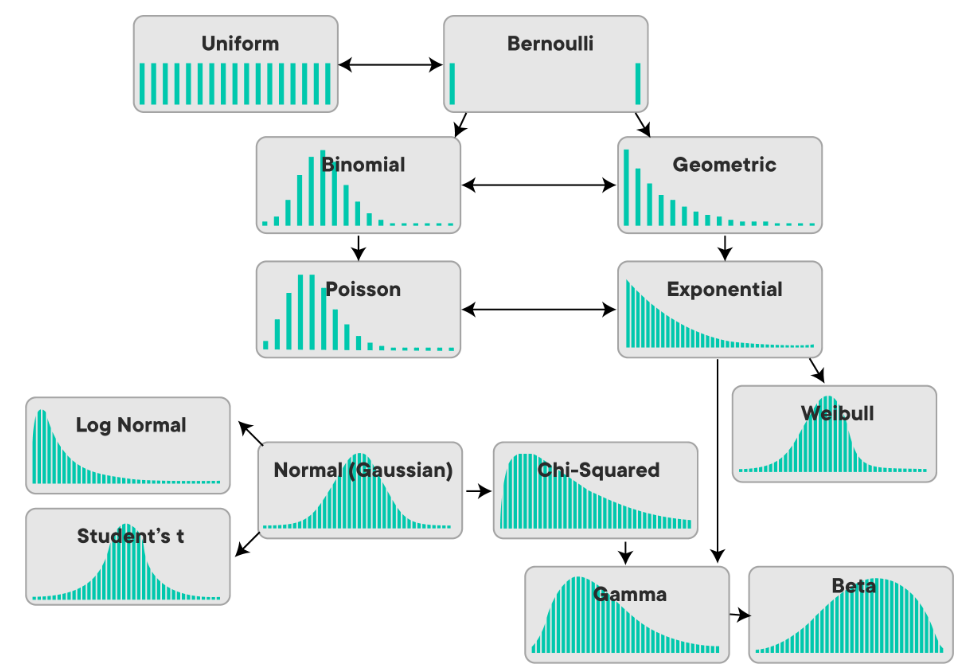
종류 엄청 많음. 하지만 공통적으로 모든 확률의 합은 1이다~
.
PMF vs PDF
PMF -> Probability Mass Function. 확률질량함수
이산 확률 변수가 특정 값(x)을 가질 확률
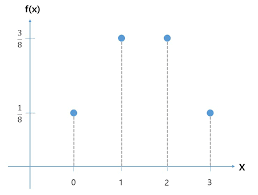
주사위/동전 던지기. 이항분포
PDF -> Probability Density Function. 확률밀도함수
연속형 확률변수의 확률
CDF(누적 분포 함수) -> 곡선 아래 면적을 누적함
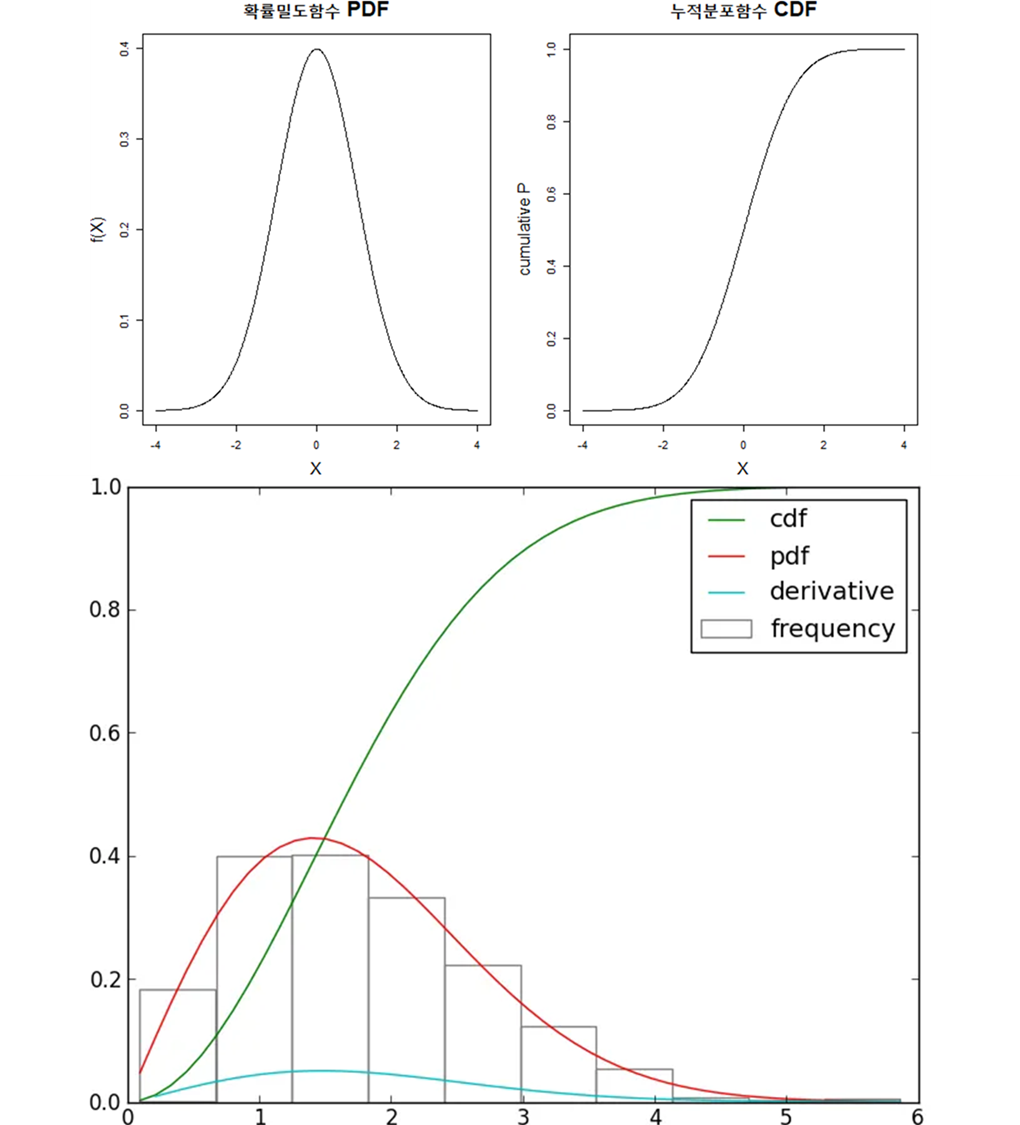
KDE
Kernel Density Estimation. 커널 밀도 추정
PDF 없을 때, 샘플 데이터를 PDF 추정하는 방법
PDF를 알려면 데이터가 많이많이 필요함. 근데 항상 그럴 순 없잖아? 그럴 때 추정하는 거임
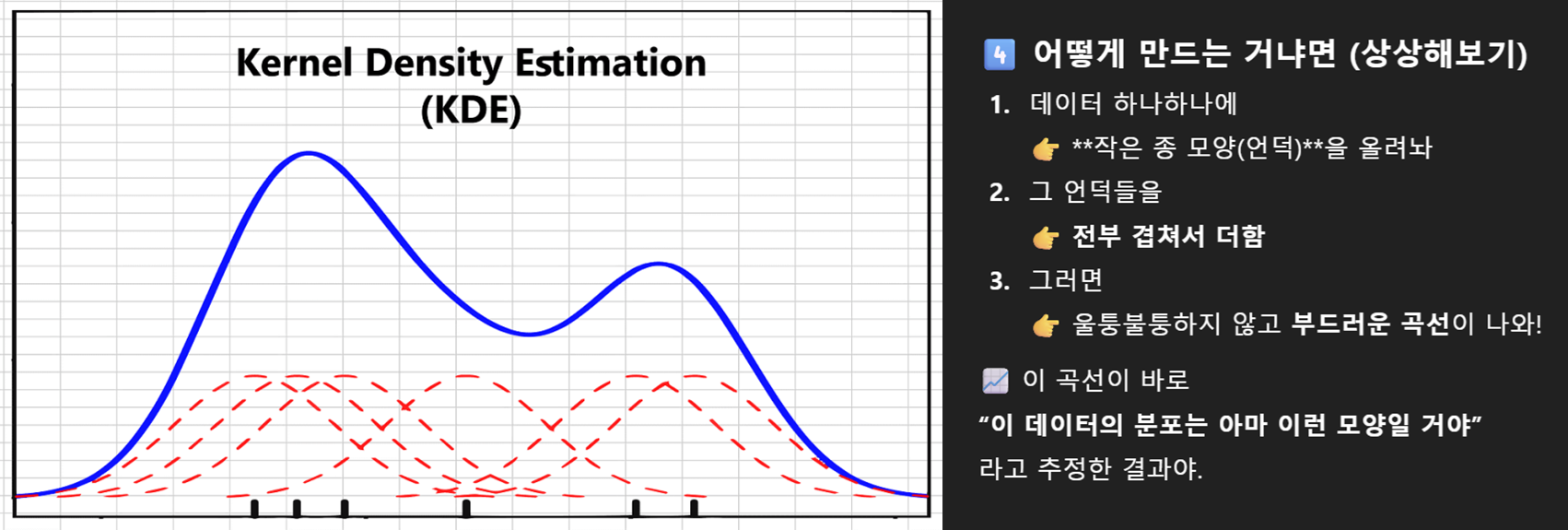
.
정규분포
- 이항분포 -> 정상/불량 같은 양자택일
- 포아송분포 -> 조건 제한
- 정규분포 -> 평균을 중심으로 좌우대칭.
대체로 무게, 길이, 온도, 압력 이런 애들은 정규분포를 따름.
SPC의 USL&LSL, Z-점수 해석, 3시그마 개념의 기반
제조업에서 정규분포를 어떻게 활용하나?
- 품질 편차 관리
- 이상치 제거
- 불량률 예측
.
3시그마 법칙. 68–95–99.7 규칙
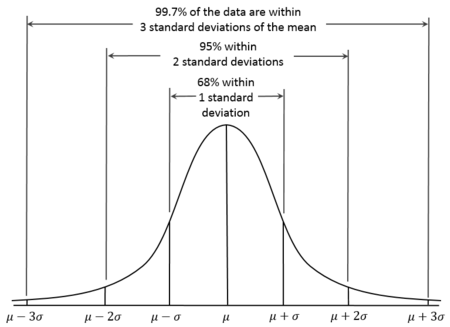
이 개념이 실무에선 어떻게 활용되고 있나?
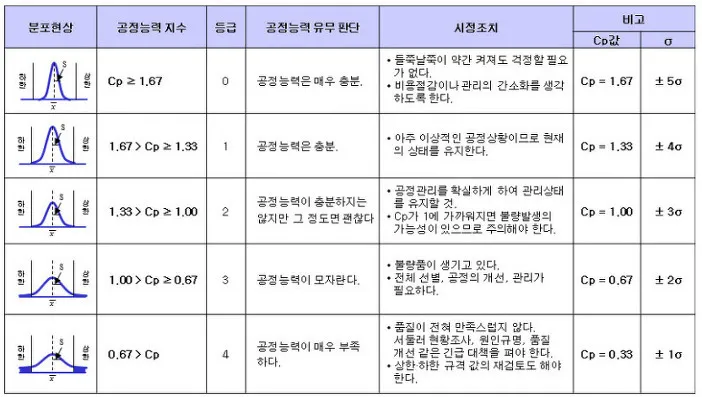
시그마를 품질 기준으로 두고, 기준치 안에 얼마나 많은 데이터가 포함되나 봄
위에 표에서 3시그마면 그만하면 됐다~인데, 여기서 그치지 않고 완벽주의 추구하는 게 6시그마
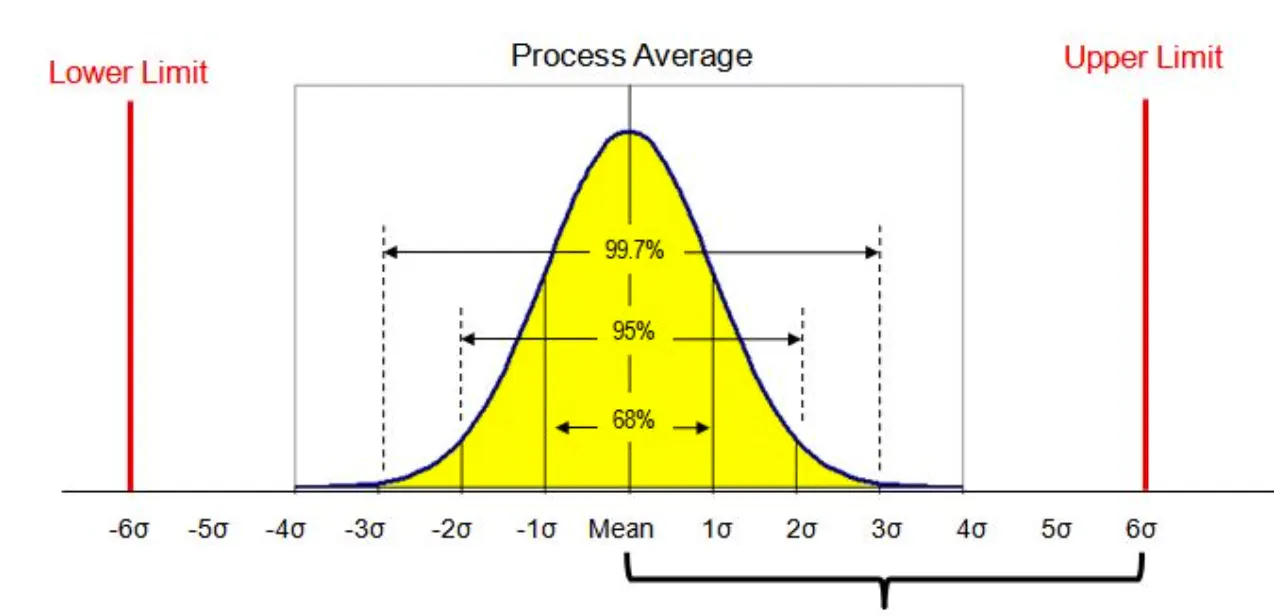
불량? 어 그런거 없어~~
±6σ 범위 안에 99.99966% 포함 (매우 높은 품질 수준 요구될 때 사용한다)
.
Cp. 공정 능력 지수
규격 안에서 얼마나 안정적으로 만들 수 있는가? 를 수치화한거
규격이라 함은 --> USL(상한 허용값)랑 LSL(하한 허용값) 사이
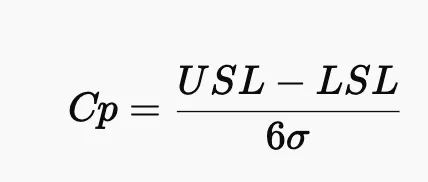
이게 계산식임. 여기서 6시그마가 어디서 나온거냐? ±3σ 범위인거임.
편차가 커진다? Cp 값 작아진다~
- Cp > 1.33 → 공정이 허용 범위 내에 안정적으로 들어감. 굿~
- Cp = 1 → 간당간당임. 살짝 방심하면 바로 불량발생
- Cp < 1 → 공정이 허용 오차를 자주 벗어남. 기강 잡아야 함;
.
Cpk. 공정 성능 지수
얘는 평균값까지 따짐.
실제 공정 평균이 허용 기준 내에서 얼마나 중앙에 있느냐를 따져볼 수 있음
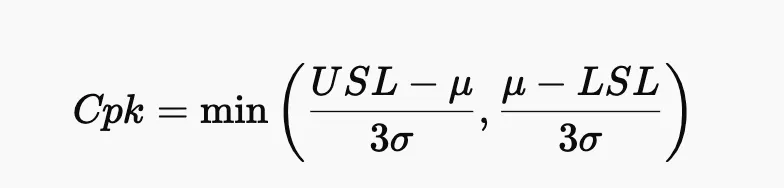
얘도 1은 간당하고 1.33 이상은 안전적인 값.
근데 이런 경우가 있음 Cp 값은 괜찮은데, Cpk값이 떨어지네..?
이거는 편차는 적게 나오는데 평균값이 중앙에 안 있는거임. 밑에 그림보고 이해해라
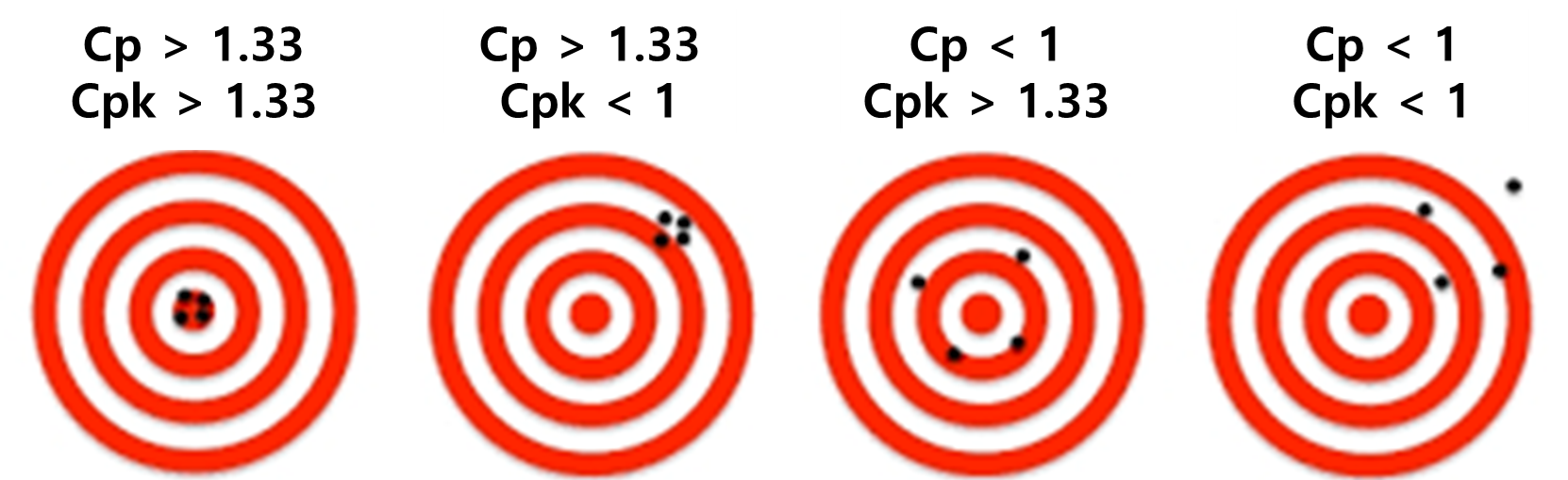
제조업에서는 이 값들을 기준으로 'Cp 향상(산포 ↓), Cpk 향상(중심화 ↑)' 요런 목표를 세운다~
.
표준정규분포 -> 평균 0. 표준편차 1
같은 스케일로 통일할 수 있다는 이점이 있고, 이상치 탐지나 모델 성능 개선에 유용함
.
기계는 큰 숫자를 더 중요하게 보는 경향이 있음
그래서 이런 오해를 방지하고자 스케일 맞추는데 그 방법이 --> 정규화 / 표준화
| 구분 | 정규화 (Normalization) | 표준화 (Standardization) |
|---|---|---|
| 목적 | 값의 범위를 0~1로 압축 | 평균 중심으로 데이터 표준화 |
| 공식 | (x - min) / (max - min) | (x - mean) / std |
| 특징 | 극단값에 민감함 | 이상치에 상대적으로 강건함 |
| 주 사용처 | KNN, SVM 등 거리 기반 알고리즘 | 선형회귀, 로지스틱 회귀 등 통계 기반 모델 |
정규화는 최소값이 0 최대값이 1. 이런 식임. 그래서 여기에 이상치가 껴있다? 난감해지는거임~ 몸무게 데이터인데 이상치로 1000이 들어가서 최대값이 1로 잡힌다고 생각하면 왜 난감한지 이해될 듯
표준화는 평균이 0. 평균에서 얼마나 떨어져있나를 보는 거임. -> Z-score
제조업 응용:
- 정규화: 센서데이터를 0~1 범위로 압축해서 모니터링 대시보드에 표시할 때 유용함
예: 진동센서 범위(020)를 시각적으로 0~1로 표시 - 표준화: 품질지표(Defect rate, 온도, 습도 등)를 통합 모델에서 동등한 중요도로 처리할 때 사용. (예) 다변량 공정관리(MVA)에서 변수 간 단위 차이를 제거함)
.
이상치 탐지
보통 Z-score 또는 IQR 기법으로 탐지
Z-score
Z = 0 → 평균
Z = 1 → 평균보다 조금 큼
Z = 3 → 평균에서 매우 멂 --> 이거 넘어가면 이상치!
IQR
아래 한계: Q1 − 1.5 × IQR
위 한계: Q3 + 1.5 × IQR
이 범위 밖이면 이상치~
.
이거말고도 이상치 탐지할 수 있는 게 더 있을텐데?
- MAD (Median Absolute Deviation) -> IQR처럼 중앙값을 기준으로 하는데 Z-score처럼 숫자로 판단 가능함
- LOF (Local Outlier Factor) -> 주변값들이랑 비교해서 좀 동떨어져있나?를 봄
- Isolation Forest -> 주어진 데이터를 고립시킬 때까지 의사결정 트리로 분리한다...는데 아직 이해 못함..;; 담에 다시 읽어보도록.
제약, 바이오에서는 경우에따라 이상치가 아니고 의미있는 신호일 수도 있으니 생각하고 제거하기..!
.
데이터의 분포, 이상치를 어떻게 시각화함?
아래와 같은 차트들로 분포, 이상치나 대표값들을 볼 수 있음~
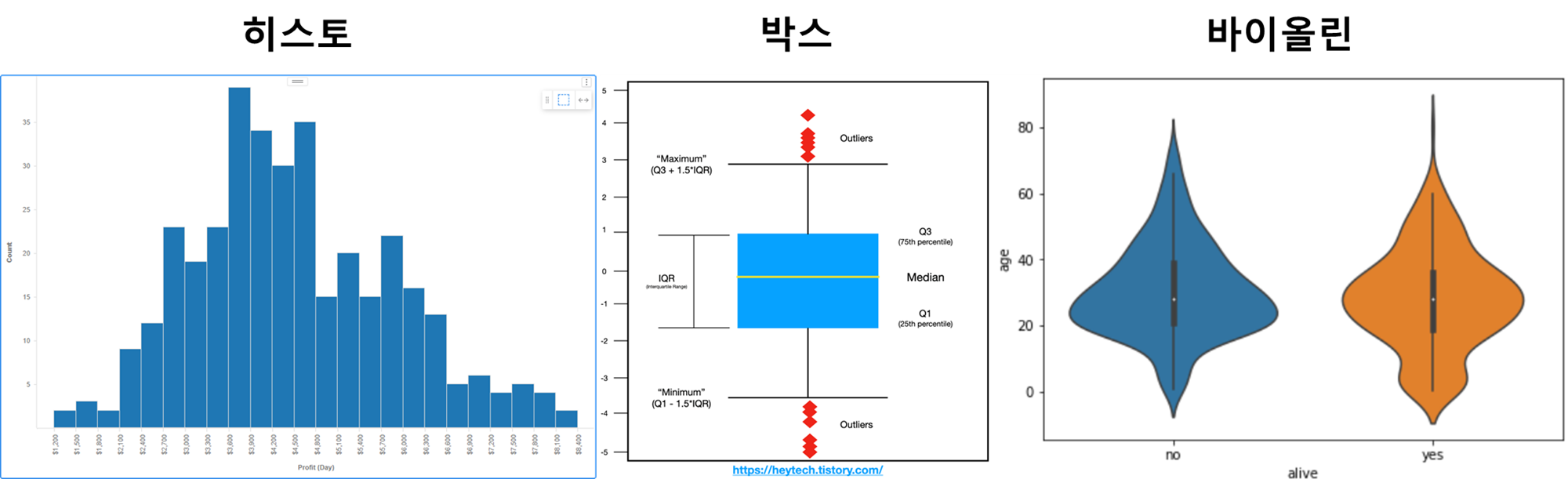
제조업 응용:
- 제품 무게 분포 확인: 박스플롯으로 공정별 품질 차이 분석
- 바이올린플롯으로 생산 시간대별 품질 편차 분석
- 이상치 존재 여부 시각적으로 파악하여 불량 패턴 추적
도메인, 직무 말고도 기업규모에 따라서도 하는 일이 달라짐.
그러니 목표로하는 곳에 대해서 잘 이해하고 뭐가 더 필요할지를 계속해서 고민해봐야 함.
그리고 어떤 게 필요한지 좀 알 것 같다하면 튜터님들한테 가서 말씀드리고 도움받기
인사이트
Cp, Cpk 값에 따라 공정 개선의 방향성과 목적이 달라져야한다는 것을 알았고,
정규화와 표준화도 특징을 잘 이해하고 목적에 맞게 활용해야겠다고 느꼈다.
또한 Z-score, IQR 외의 이상치 탐지 방법들을 찾아보면서 흥미로움을 느낄 수 있었다.ADsP 기출
45, 46회 1,2과목만
https://velog.io/@chaen_99/ADsP-오답-모음
개인학습시간
어제 이해못한 R square
R square? 회귀분석 평가 지표 중 하나임.
0과 1 사이 값을 가지며, 1일수록 완벽하게 설명. 0일수록 설명 못함
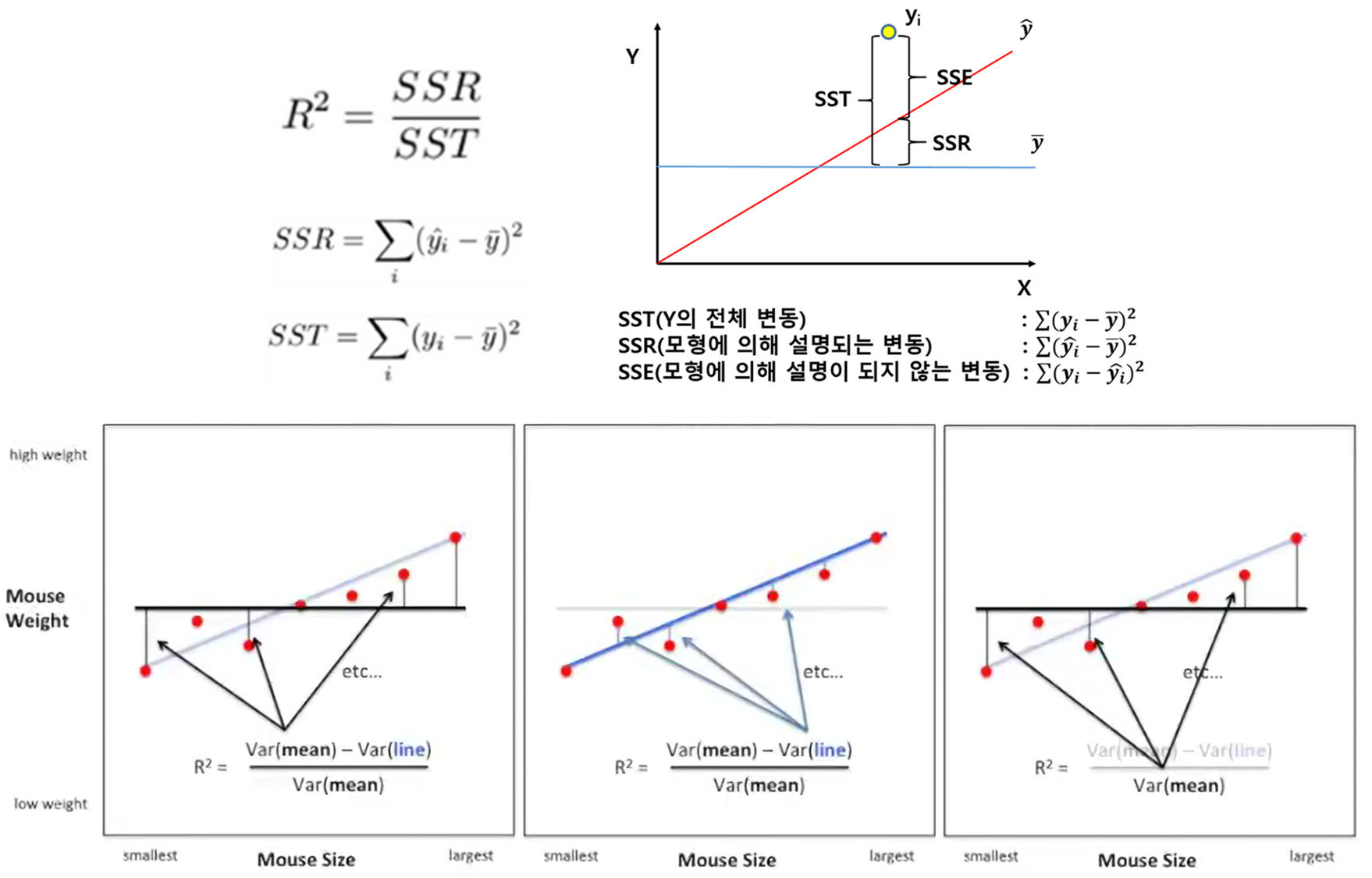
먼가 얼추 이해된 듯.
분모 분자 차이가 덜 나야 1에 가까워짐
분자가 작아지려면? 파란색 라인 기준으로 나온 오차가 작아야 함
그 말은? 회귀선이 잘 들어맞다는 거임
회고
어제 계획한 것들.....
머신러닝 1-10 못들은 거 좀 일찍와서 듣기
통계 3주차
통계 세션 듣고 코드 필사
ADsP 1,2과목 기출
피그마 활용하는 법 살짝 찾아보기
R square 찾아보고 이해하기(시간 많이 쓰지마!)
통계 강의는 시간이 없어서 다 못들음...
.
내일 할 거
- 통계 3, 4주차
- ADsP 1,2과목 43,44회 풀기
- 세션 2개 듣고 코드 필사
내일도 일찍 와서 강의듣기 도전....!
