- 8:40 ~ 9:20 : 통계 강의 강의자료 읽기 (챕터 3)
- 9:20 ~ 10:00 : 코드카타
- 10:00 ~ 11:00 : 오전 스크럼 및 ADsP 기출
- 11:00 ~ 12:00 : 통계 세션
- 12:00 ~ 12:30 : 세션 복습
- 13:30 ~ 15:30 : 세션 복습
- 15:30 ~ 18:00 : 세션 내용 스터디
- 19:00 ~ 19:30 : 오후 스크럼
- 19:30 ~ 20:40 : 머신러닝 세션
- 20:40 ~ 21:00 : TIL 작성
코드카타
가운데 글자 가져오기
def solution(s):
if len(s)%2 == 1:
num = int((len(s)-1)/2)
answer= s[num]
else:
num = int(len(s)/2)
answer= s[num-1:(num+1)]
return answer.
이거 진짜 천재같음
def string_middle(str):
return str[(len(str)-1)//2 : len(str)//2 + 1]이분은 몫을 이용하셨는데 계산식을 저렇게 만드실 생각을 했다는 게 진짜 똑똑하신 듯
저렇게 하면 조건문으로 홀짝 나눌 필요도 없음
이분은 홀짝을 나누셨는데 -를 붙혀야겠다는 발상이 굿임
def string_middle(str):
a = len(str)
if a % 2 == 0 :
a = (a-2) / 2
else :
a = (a-1) / 2
return str[int(a) : -int(a)]ADsP
통계 세션
모집단, 표본
- 모집단 -> 그리스 문자. 뮤, 시그마, ...
- 표본 -> 알파벳. 엑스바, s
좋은 표본? 대표성을 가지는 표본~ (모집단을 잘 대표하는 표본)
-
표본이 왜 필요함?
예를 들어 내구성 테스트를 한다고 쳤을 때,
전수 조사가 정확하긴 하겠지 근데 그럼 다 뿌셔?
그럴 순 없음.
이럴 때 표본 추출해서 모집단을 추정하는 것~ -
그렇다면 추출은 어떻게 함?
이렇게 4가지가 있음.
-
단순 랜덤 추출(simple random sampling): 무작위 샘플링. 로또 번호 뽑기 (딱히 권장하지 않는 방법)
-
계통 추출(systematic sampling) : 5개당 1개씩 샘플링
-
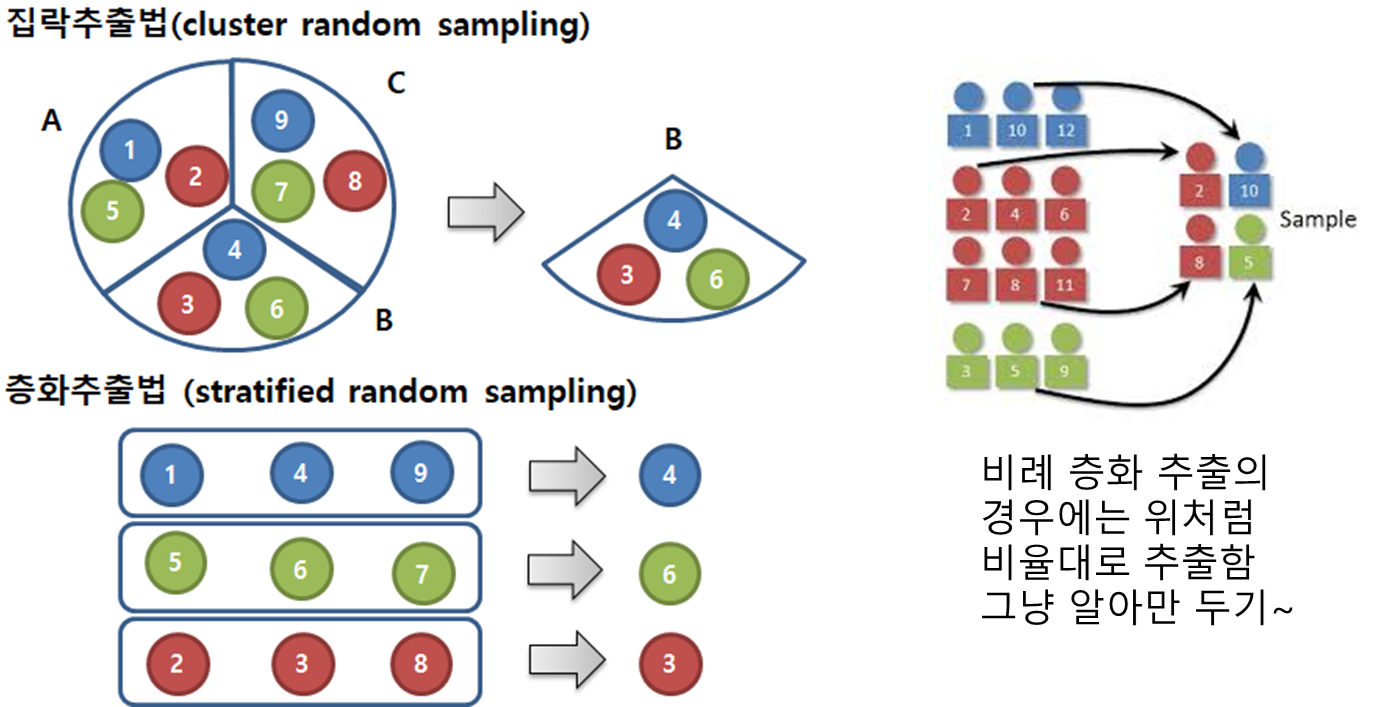
집락 추출(cluster random sampling):
특정 구역에서만 샘플링 : 집단 내 이질적 집단 간 동질적
특성에 따라 나름 분류한 다음에, 하나씩 묶어둠 -
층화 추출(stratified random sampling): 특정 상품군에서 샘플링 : 집단 내 동질적, 집단 간 이질적
특성에 따라 나름 분류한 다음에, 하나씩 뽑아냄
- 표본 분포
추출을 여러 번해서 계산되는 통계량의 분포
.
중심극한정리
Central Limit Theorem, CLT
모집단의 분포랑 상관없이, 표본이 충~분히 크면 정규분포 모양 된다!
충분? 얼마가 충분인데? -> 이론적으로는 30개 이상~
확률을 계산 할 수 있는가 확인하기 위한 목적
분포의 모양이 중요하다~
자바 실험실 <- 공부하다가 뭐가 좀 아리까리 하다? 여기 들어가서 시각화 해둔 거 보기
-
어떻게 활용되고 있나?
- 일/주/월 단위의 품질 평균 비교 시 활용
- X-bar 관리도, t-test, 신뢰구간 적용의 기반 -
큰 수의 법칙 (그냥 참고용)
중요하진 않는데 헷갈린다는 사람이 있어서 넣어두심
표본이 커질수록 표본평균이 모평균에 가까워진다
.
표준오차, 신뢰구간
-
표준오차
표본 커질 수록 오차 작아짐
중요 ㄴㄴ -
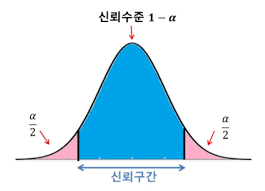
신뢰구간
이 범위 안에 모집단의 평균이 있을 껄~?
표본 데이터로 모집단의 평균이나 비율을 추정
@@대학교의 평균키는 2.0m다 !
ㄴ이거 아님!
표본 500명을 추출해서 재봤을 때, @@대학교의 평균키는 평균은 1.9~2.1m 사이에 있을 것 같아!
95% 확신함~
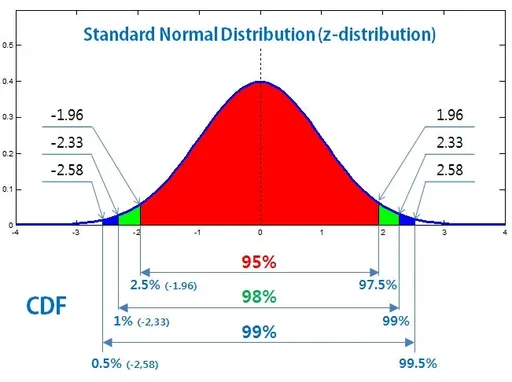
ㄴ이렇게 하는 거임여기서 95%가 신뢰수준임
신뢰 수준은 별 얘기 없으면 95임 (z-score는 1.96)
- 신뢰구간 특징
신뢰구간이 좁을 수록, 샤프해질 수록
모집단의 평균 추정치가 정확해짐
95 빼고 남은 꼬다리 부분을 알파라고 함
.
가설검정
귀무(H0) -> 다~~ 의미 없다. 니말 틀렸다!
대립(H1) -> 니말맞다.
-
가설검정
표본을 바탕으로 모집단이 맞다, 틀렸다를 판단 -
유의수준
알파. 내가 틀렸는데 실수로 맞다고 할 확률 -
p-value
정해둔 유의수준보다 얘가 작으면 귀무 기각
-
가설 검정의 절차
가설 수립 - 유의수준 설정 - 검정 통계량 산출 - 기각/채택 판단 -
예시
신약이 기존 약보다 효과가 있는가?
| 구분 | 가설 | 해석 |
|---|---|---|
| 귀무가설(H₀) | 신약 효과 = 기존 약 효과 | "두 약의 효과는 같다"라고 처음에는 믿는다 |
| 대립가설(H₁) | 신약 효과 > 기존 약 효과 | "신약이 더 낫다"는 주장을 검증하고 싶다 |
| 유의수준(α) | 0.05 | "5% 이하의 확률로 틀린 판단을 허용하겠다" |
| p-value | 예: 0.03 | 실제로 데이터 관측 결과가 귀무가설 하에서 나올 확률이 3%밖에 안 됨 |
| 결론 | p-value < α → 귀무가설 기각 | 신약이 더 낫다고 통계적으로 유의미하다고 판단 |
.
단측 vs 양측 검정
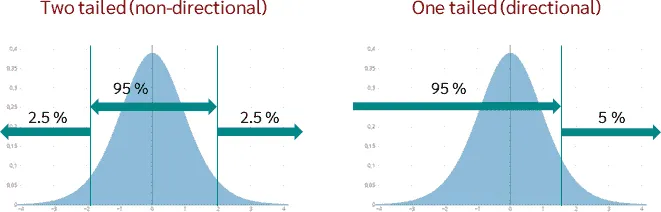
- 단측검정 -> 크다 작다의 방향성이 존재함
신약 효과가 기존보다 크다 - 양측검정 -> 같다 다르다
신약 효과가 기존과 다르다(크거나 작거나)
.
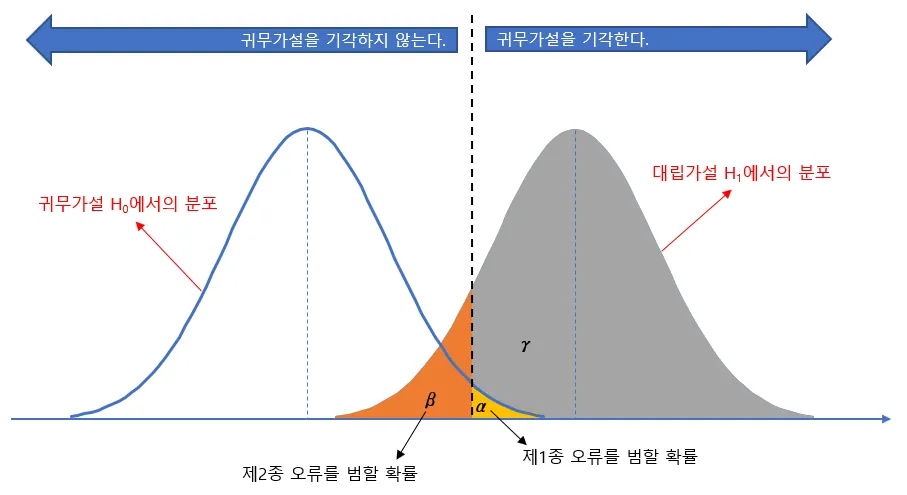
1종 오류 vs 2종 오류
1종 오류, 2종 오류
1종 -> 내가 틀렸는데 맞다고 우겨버림(귀무가설 기각)
2종 -> 내가 맞는데 어라 귀무가설을 채택해버림
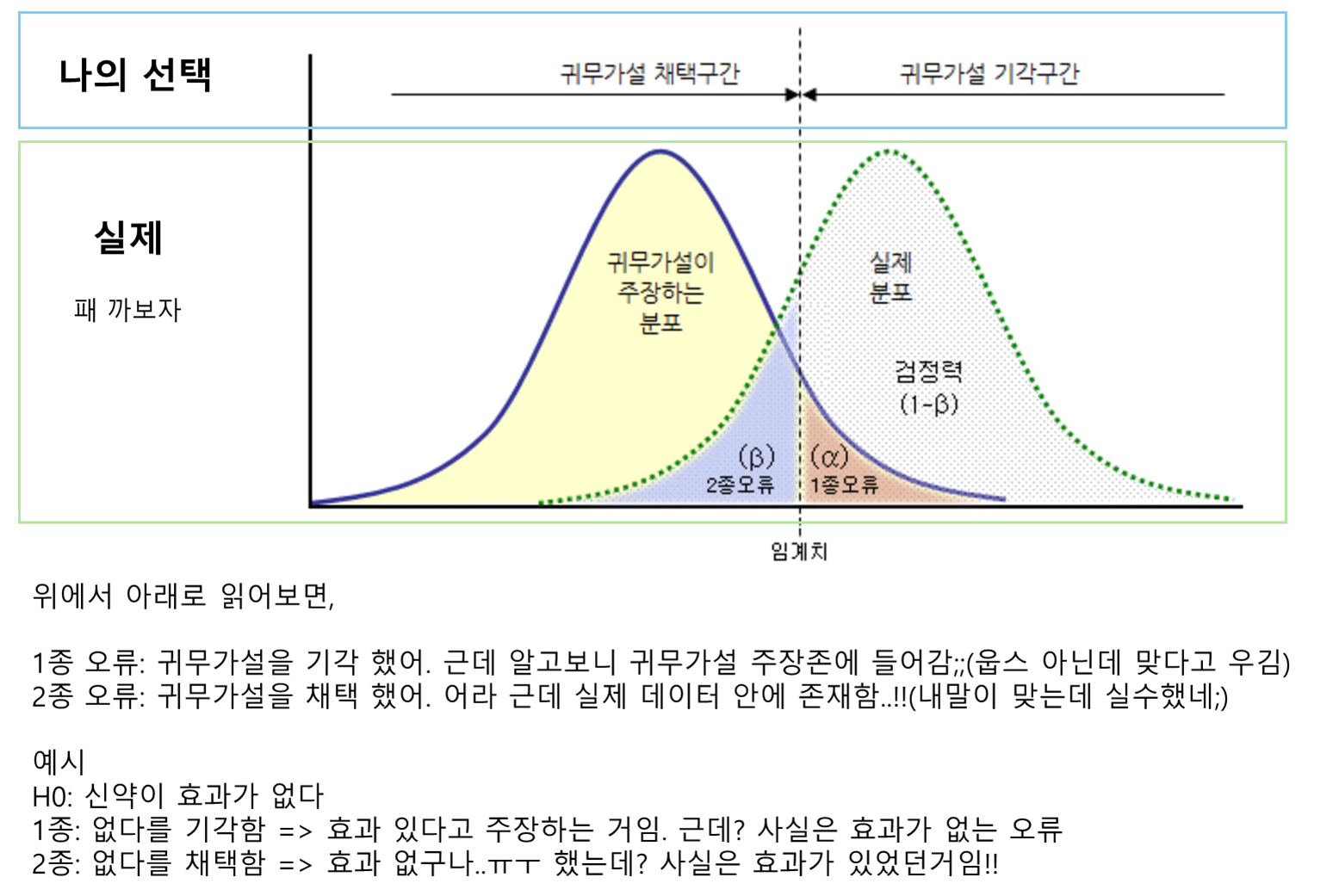
오류를 일으킬 확률
1종 -> 유의수준 α
2종 -> β (검정력 = 1 - β)
.
모수 검정
통계 분석 방법이 이런 거 저런 거 많음
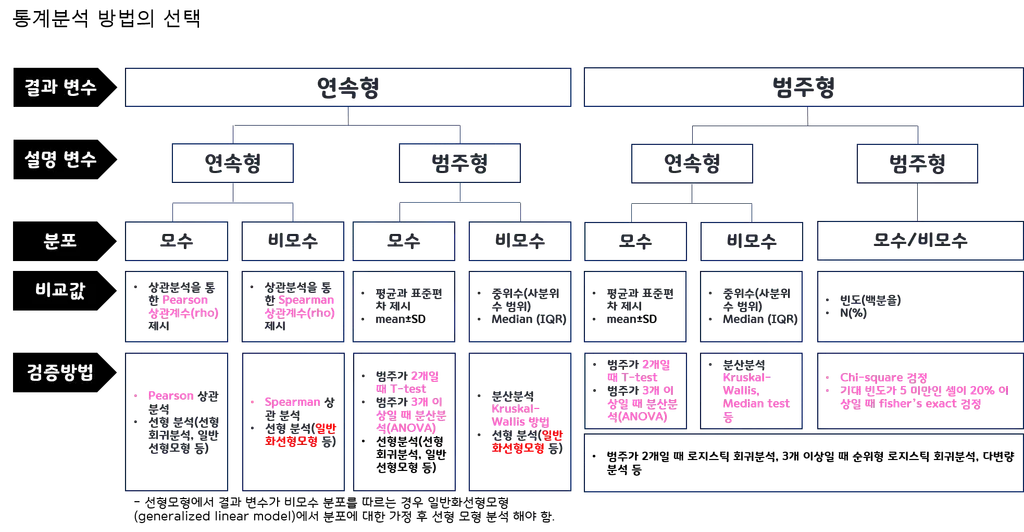
여기서 오늘은 모수 검정을 볼 거임.
모수 검정은?
주로 평균의 차이를 비교할 때 함.
정규성, 등분산성 하나라도 없으면 비모수 검정으로 넘어가야 함...
검정 종류에는 t-test, z-test, anova 등이 있음
- t-test -> 표본 수 작을 때(30보다 작으면 일반적으로 작은 수)
- z-test -> 표본 수 충분히 클 때
- anova -> 3개 이상의 집단의 평균을 비교할 때(위에 애들은 그룹이 2개임)(이원 아노바는 안 씀)
.
t-test
얘를 젤 많이 씀
표본 작아. 모집단 표준편차 몰라. -> 이럴 때 사용한다
여기서도 단측/양측 검정 나옴. 걍 읽어만 보기~
-
단일 표본 t-test
하나는 집단, 하나는 숫자
현재 공정의 평균 온도(집단) vs 기준 온도(숫자) -
독립표본 t-test
집단이 두개
두 집단의 평균이 유의하게 차이나나?
A라인 제품의 평균 강도(집단) vs B라인 제품의 평균 강도(집단) -
대응표본 t-test
한 집단의 비포 애프터를 비교
장비 교체 전 vs 장비 교체 후
.
이해관계가 다른 집단 사이에서 어떻게 절충안을 잘 내서 좋은 결과를 냈는가
1종 오류 2종 오류를 둘다 줄일 수는 없음
그러니까 어느정도 절충을 해야하는 건데, 어떤 근거로 어느 정도 조절할 것인지를 잘 생각해봐야함
우리부서만 일하는 거 아니니까...
의사결정자가 어떤 부분까지 고려를 해야할지 요런 것까지 정리해서 갖다줘야함
그림을 딱 봤을 때 설명할 수 있어야 함인사이트
개념을 확실히 하지 않고 다음 단계로 넘어가면 더 혼란스러울거라고 하셔서 지금 배우는 부분을 충분히 이해하고 넘어가고자 함. 학습 내용 중에서 1종 오류, 2종 오류는 상충관계에 있다는 점이 흥미로웠고, 이러한 특성 때문에 실무에서 내가 목적하는 바만 보고 일처리를 하기 보단 회사의 재정상황, 타부서의 목표 등을 두루 고려하여 임계치를 설정해야겠다고 생각함.머신러닝 세션
지금부터는 꼼꼼히 들어야 함
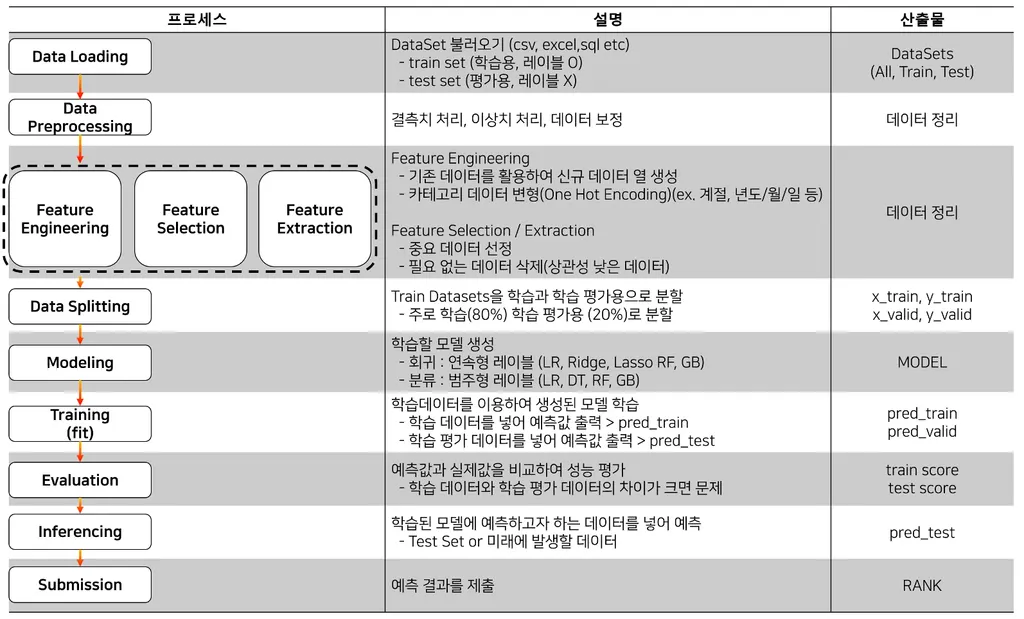
인코딩
범주형 데이터 -> 숫자형
범주형 데이터? 카테고리화 할 수 있는 거. 빨/노/파, 양품/불량품, 양성/음성
인코딩이 왜 필요한데? 문자열 넣으면 모델 학습이 안됨
One Hot Encoding
젤 흔한 방법.
get_dummies
순서가 없는 범주형 데이터를 효과적으로 처리함
예) 빨/노/파, 혈액형
각 범주를 새로운 열로 만들어서 표시
혈액형(A, B, O) → A열(1,0,0), B열(0,1,0), O열(0,0,1)
근데 범주의 수가 많아지면? 복잡성, 메모리 사용량, 모델 학습시간 증가. 과적합 위험.
Label Encoder
간단하고 효율적인 방법(-> 모델 학습 시간 감소)
from sklearn.preprocessing import LabelEncoder
얘는 순서가 있는 범주형 변수를 처리할 때 유용함
에) 상/중/하, 학점
아니면 데이터가 넘 많아서 원핫 쓰기 부담스러울 때도 사용함
각 범주에 고유한 번호를 부여함
만족도(만족, 보통, 불만) → 만족: 2, 보통: 1, 불만: 0
근데 모델이 저 고유번호에 의미 부여를 할 수도 있음...
.
스케일링
수치형 데이터의 단위를 맞추는 과정
왜함?
모델 편향을 방지하려고.
스케일이 크거나 단위가 다른 변수는 모델이 편향되게 학습할 수 있음
키 데이터랑 연봉 데이터 중에 연봉 데이터의 숫자가 크니까 이게 중요하구나~ 할 수도 있다는 얘기
어떻게 함?
- 표준화
데이터가 정규분포에 가깝거나 대칭적일 때 사용
근데 이상치 껴있으면 평균이랑 표준편차가 영향을 받긴해~ - 정규화
범위를 일정크기로 맞추고 싶을 때 사용
근데 이상치 껴있으면 난감해짐(최소값/최대값을 기준으로 압축해서 이상치에 대한 타격이 큼) - SVM (Support Vector Machine)
데이터를 잘 분류하는 선을 찾아줌
스케일링에 민감하게 반응함
.
데이터 분할
데이터를
train : test = 8:2
train : validation : test = 7:2:1
이런 식으로 나누는 거 (데이터 많아질 수록 test 데이터 줄여도 됨)
왜 함?
과적합(overfitting) 방지, 일반화 성능을 객관적으로 평가하기 위해
과적합? 모델이 train 데이터에 너무 핏해져서 test 데이터에선 제대로 예측을 못함.
Modeling & Training & Evaluation
회귀
종속변수 독립변수 사이의 관계성을 모델링 -> 이걸로 예측/통찰 가능
종속: y값. 예측할 값
독립: x값. y에 영향을 미치는 값
- 선형회귀
y = \beta_0 +\beta_1x_1 + \epsilon
- β0: 절편 (모델의 시작점)
- β1: 기울기 (독립변수가 종속변수에 미치는 영향의 크기)
- ϵ: 오차 (모델의 예측값과 실제값 간의 차이)
키-몸무게
- 다중회귀
y = \beta_0 + \beta_1x_1 + \beta_2x_2 + ⋯ + \beta_nx_n + \epsilon
독립변수(x)가 2개 이상. 그래서 여러 영향을 동시에 고려할 수 있음
그치만 정답이 너무 많이 나올 수도 있다는 단점이 있음
회귀 모델 성능평가
- 절대 오차 (MAE, Mean Absolute Error)
오차에 절대값 씌우기 - 평균 제곱 오차 (MSE, Mean Squared Error)
오차를 제곱해서 평균냄 - 평균 제곱근 오차 (RMSE, Root Mean Squared Error)
MSE에 루트 씌우기 - 결정 계수 (R², R-squared)
x축이랑 평행한 선이랑 회귀선이랑 비교한 거
.
분류
데이터를 구분해서 넣는 작업
혼동 행렬(Confusion Matrix)
아이고 1종 오류 2종 오류 또 나왔다
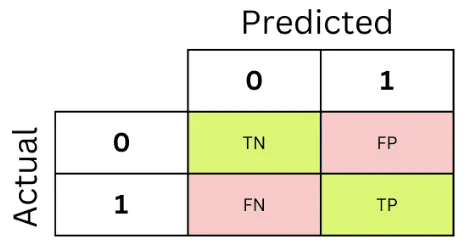
-
정확도: 맞게 분류한 비율
-
정밀도: 참 긍정/예측긍정
-
재현율: 참 긍정/실제긍정
-
F1 Score: 정밀도와 재현율의 조화 평균
-
정밀도 - 재현율
얘네는 마치 1종 오류와 2종 오류 같은 관계
두마리 토끼 잡을 수 없음. 절충해야함.
인사이트
인코딩과 스케일링 같은 데이터 정리 과정에서 대해서 이해할 수 있었고, 스케일링 같은 경우엔 이전에 진행했었던 기초 프로젝트의 데이터에도 적용이 가능했겠다는 생각을 함. 또한 통계에서 배웠던 1종 오류/2종 오류가 혼동 행렬이라는 이름으로 다시 등장하는 걸 보고, 기초를 확실히 잡아놔야겠다고 다짐함.회고
강의를 듣는 게 시간이 너무 많이 걸리나 해서 오늘을 강의 자료를 읽기만 했는데
30분이 걸림...ㅎㅎㅎ
이럴 거면 듣는 게 나은가...
근데 또 듣는 것보다는 좀 더 확실하게 머리에 들어온 것 같기도 하고..
고민이군
통계 3, 4주차
ADsP 1,2과목 43,44회 풀기
세션 2개 복습
세션 코드 필사
통계는 3주차까지 했고 세션 내용은 복습은 했지만 실습은 못 해봤다
오늘 팀원들이랑 스터디를 했는데 가설 검증 파트를 제대로 이해하는데에 시간이 좀 걸렸다
그래도 혼자 하는 것보단 머리에 훨씬 잘 들어왔고, 이해했다고 착각하고 있던 부분도 잡아낼 수 있었다
굿~
.
내일 할 거
- 아티클 읽고 정리
- 세션 2개 듣고 복습
- 아티클 스터디
- 세션 코드필사
강의도 듣고 싶고 ADsP 문제도 풀고 싶은데 현실적으로 위에꺼 다 하기도 시간 빠듯할 듯..
어디서 시간을 줄일 수 있을까..🤔
할 수 있는 건 아티클 초집중해서 후다닥 읽기, 세션 복습을 간략하게 하기
이정도 같은데 타임어택을 해봐야하나
