-
9:00 ~ 11:00 : 태블로 강의
-
11:00 ~ 12:30 : 시계열 세션
-
12:30 ~ 13:00 : 태블로 강의
-
14:00 ~ 15:00 : 시계열 복습
-
15:00 ~ 17:00 : 태블로 세션
-
17:00 ~ 18:00 : 태블로, 시계열 관련 레퍼런스 찾기
-
19:00 ~ 20:00 : ADsP
-
20:00 ~ 21:00 : 오후 스크럼 및 TIL 작성
코드카타
이상한 문자 만들기
def solution(s):
words = s.split(' ')
result_words = []
for word in words:
converted_word = ""
for index, char in enumerate(word):
if index % 2 == 0:
converted_word += char.upper()
else:
converted_word += char.lower()
result_words.append(converted_word)
return ' '.join(result_words)시계열 세션
정상성 검정 및 차수 결정
▶정상성 Stationarity
시간에 따라 통계적 성질이 변하지 않는 상태
정상성이 없다? 예측이 안됨. 뭐랑 뭐가 상관이 있는건지 알 수가 없으셈
정상성의 3조건
=> 평균, 분산, 고분산
여기서 평균이랑 분산만 맞춰주면 공분산은 보통 따라옴
▶단위근 Unit Root
자기회귀 계수 Φ가 1인 경우
Φ = 과거를 얼마나 잊어버리는가. 망각의 계수
Φ < 1 : 잊어버림. 정상성
Φ = 1 : 안 잊어버림. 비정상성
애가 있으면 인과관계를 잘못 해석할 가능성이 높음
▶평활법 및 시계열 분해
평활법: 최근 데이터에 가중치
시계열 분해: 추세, 계절성, 잔차 분리
승법모델보다는 가법모델이 좀 더 이론에 잘 들어맞음
그래서 가법모델 적용할라고 로그 변환해서 가법 모델로 분해하는듯▶정상성 검정 및 차수 결정
ADF로 검정하고 ACF, PACF로 차수 정하기
▶ADF Augmented Dickey-Fuller 검정
H0: 단위근 존재. 시계열이 비정상성을 띤다
H1: 단위근 없다. 시계열이 정상성!
여기서 p value가 0.05보다 작아서 정상성을 확보해야한다~
0.05보다 크다? 그러면 차분을 하든 어쩓든 다른 처리가 필요햐다~
▶ACF, PACF
모델의 차수 결정에 힌트를 주는 친구들
차수? -> p(AR)와 q(MA)
뚝뚝 끊긴 부분을 보고 차수를 결정함
근데 이건 솔직히 사람마다 다르게 볼 수 있는 부분이긴 함....
▶시계열 Feature Engineering
아무거나 다 만들어서 영향력을 훑어봐야함
난사하기 일단 양치기 하는거임
그 다음에 유의미한 거 추려서 쓰는 거임최적 모델 탐색 및 모델 검증
▶최적 모델 탐색 오토 아리마
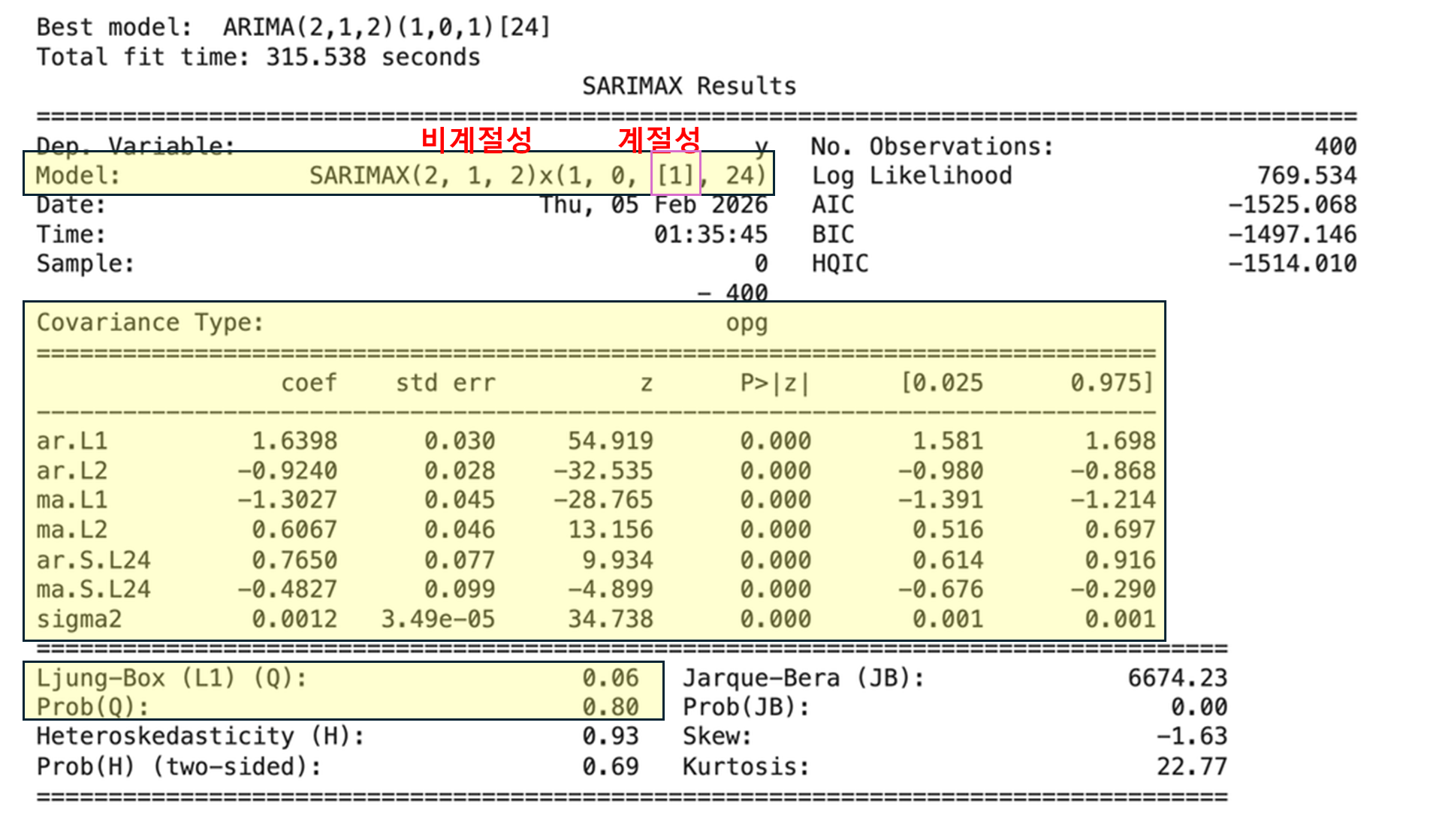
일단 지금은 노란색 표시된 부분만 보기
보라색 네모부분이 [] 빈 대괄호다? 아리마, 사리마 모델이 더 적합
채워져있으면 아리맥스, 사리맥스가 더 적합
▶모델 검증
잔차 진단 & 융박스
잔차 진단 - 눈으로 보고 판단
융박스 - p-value > 0.05 면 성공
이상적인 잔차 형태
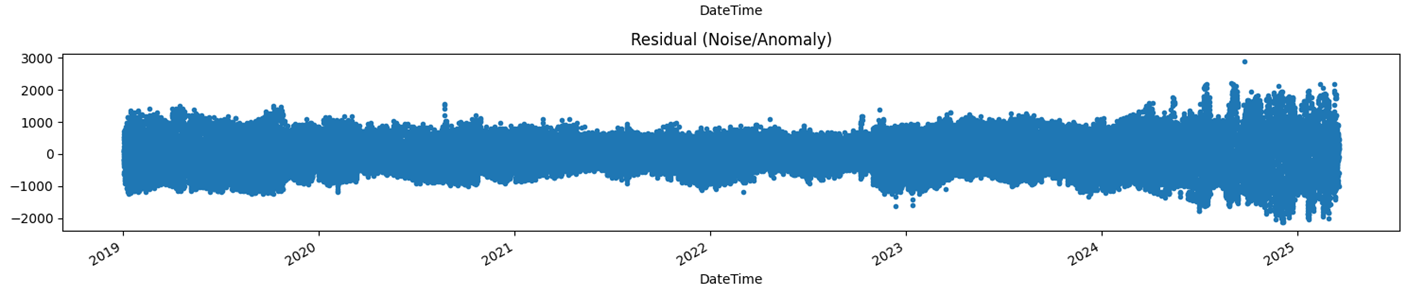
일정한 패턴이 보이면 안됨
▶예측 및 성능지표 확인
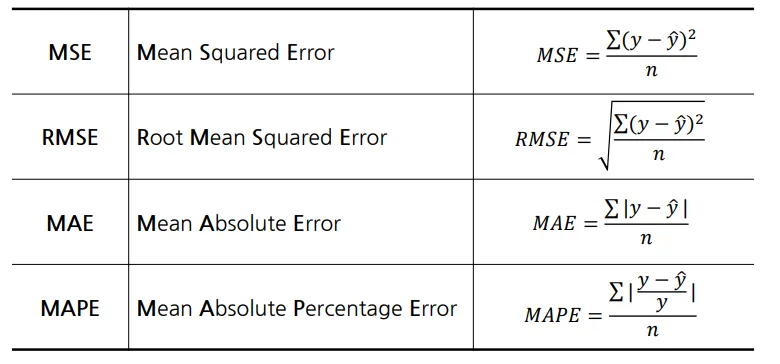
무조건 0에 가까울 수록 좋음
스마트 팩토리
스마트 팩토리, 푸리에 변환(어렵다고 하심...)
피지컬 AI까지 다 적용이 많이 된다면 공장에 아예 사람이 없어질지도..
▶현장 주요 센서와 데이터 종류
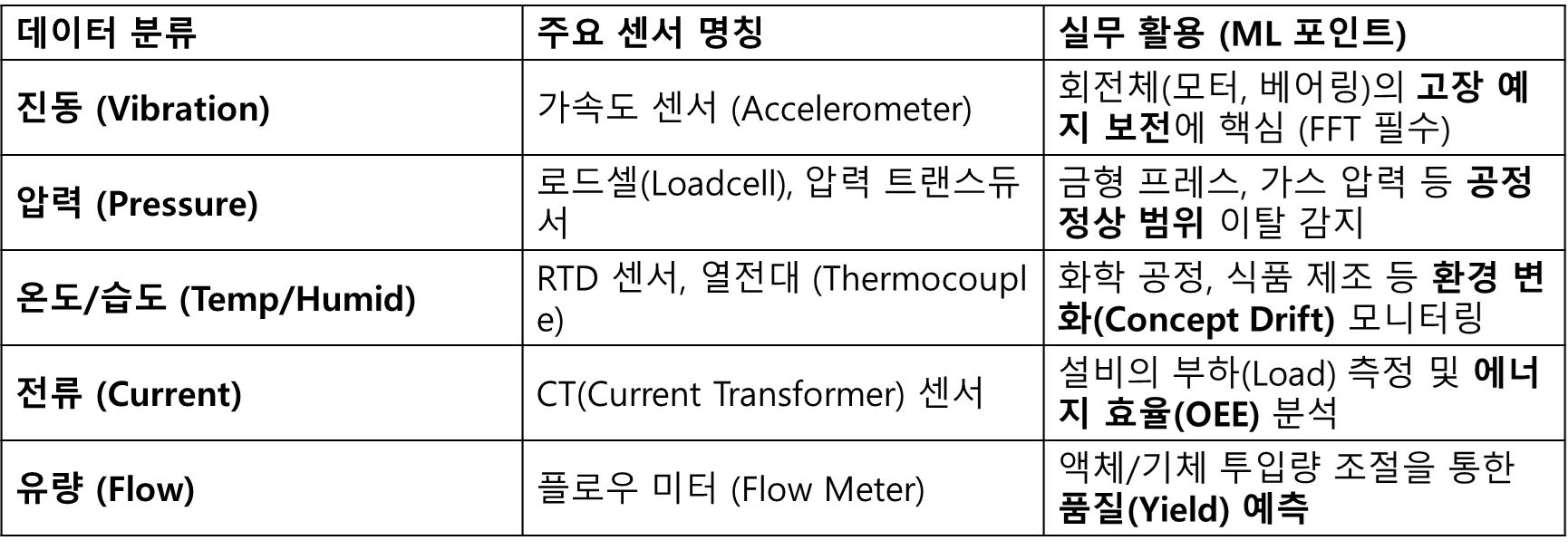
도메인마다 어떤 데이터가 수집되는지, 어떤 데이터가 중요한지 다름
알아서 찾아보기
▶스마트 팩토리의 데이터 흐름
디지털 트윈 - 아직까지 제대로 구축된 곳은 없긴함
사용 용이성을 생각할 줄 알아야함
내가 만든 결과를 회사에 판다고 생각해야함
ERP에서도 대시보드 굉장히 많이 만든다고 함
▶현장의 변수
어려운 부분임.
내가 가려는 분야에서는 어떤 데이터가 많이 수집이 되는지 파악해야함
데이터에 맞게 적용할 줄 알아야 한다~
1) 다중 샘플링 레이트 (Multi-rate Sampling)
2) 하드웨어 의존적 데이터 노이즈 (EMI/Spike)
3) 비정상성(Non-stationarity)과 Concept Drift
4) 타임스탬프 불일치 (Time Synchronization)
이런 변수들이 있다~~
프로젝트 할 때 적용해보라고 하심
시계열 전처리
▶데이터 리샘플링
다운 샘플링: 높은 빈도의 데이터를 낮은 빈도로 줄이는 과정
업샘플링: 낮은 빈도의 데이터를 높은 빈도로 늘리는 과정
어떻게 늘리느냐? 포워드 필, 백워드 필
앞뒤 데이터를 고대로 가져와서 복제하기~
다운 샘플링을 휠씬 많이 씀
▶주파수 영역 변환
FFT & Wavelet Transform
둘 차이?
FFT - 이상치가 감지 됐다는 것만 알려줌. 언제는 모름
DWT - 언제 일어났는지 시간까지 알려줌
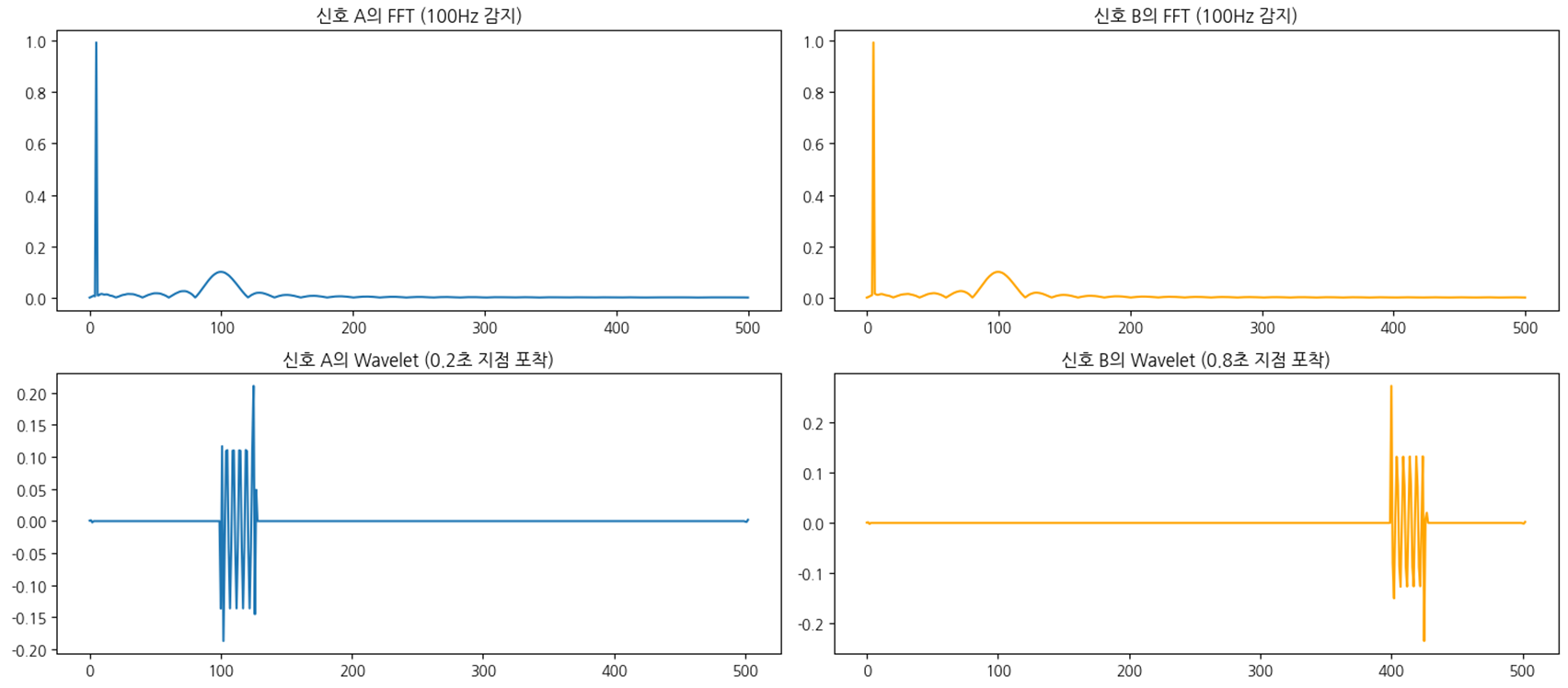
사진에서 윗줄이 FFT, 아랫줄이 DWT
FFT - 오왼 차트 거의 똑같음. 뭐가 발생했구나~만 알 수 있다
DWT - 지지직 지점이 다름. 시간대도 같이 알려주더라
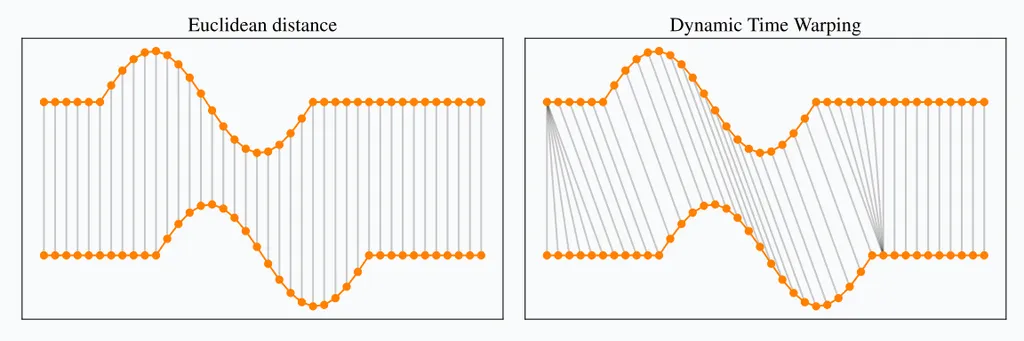
▶시계열 유사도 분석 (DTW: Dynamic Time Warping)
기계가 항상 똑~같은 속도로 도는 게 아님
-> 미세하게 느려지거나 빨라질 수 있음
이럴 때
유클리디안 거리는 시간 밀림을 보정하지 않음
DTW는 융통성 시간 밀린 거 반영해줌
ADsP
오늘의 오답~
통계적 추론에서 표본으로 계산한 표본평균은 모평균의 추정량일 뿐,
기댓값 E(X)로 모수 판단 X
결정계수 구하기
SSR / (SSR+SSE)
summary에서 binomial이라고 적혀있으면 이항 로지스틱 회귀
인공신경망 가중치 구하기(인접한 두 노드를 곱한 후 합계)
(입력층 노드 수 x 은닉층 노드수) + (은닉층 노드 수 x 출력층 노드수)
시그모이드 함수의 출력값은 항상 0과 1 사이 (먼가 투바투 노래 제목같음)
시그모이드 - 이진분류. 다범주 문제에는 부적절
탄젠트 - -1~1. 확률 해석 불가능. 주로 은닉층에 사용
렐루 - 음수는 0, 양수는 그대로 출력. 확률 해석 불가능
소프트맥스 - 0~1. 다범주 분류 문제의 출력층 함수에 적절
트랜잭션 집합 문제....
연관규칙에서 지지도랑 신뢰도 둘다 중요하다..!
절대적 기준 0이 존재 -> 비율척도. 무게, 길이
계통 추출 -> 모집단 각 개체에 번호를 부여. k 간격마다 추출
단순회귀분석에서 오차항의 분산 추정량(MSE) -> n-k-1로 나눠야함
개별 변수 중 하나가 유의하지 않다고 단순하게 그 변수 빼고 식 만들면 안됨
정상성 = 시간이 흘러도 변하지 않는 특성
소프트맥스 함수의 수식
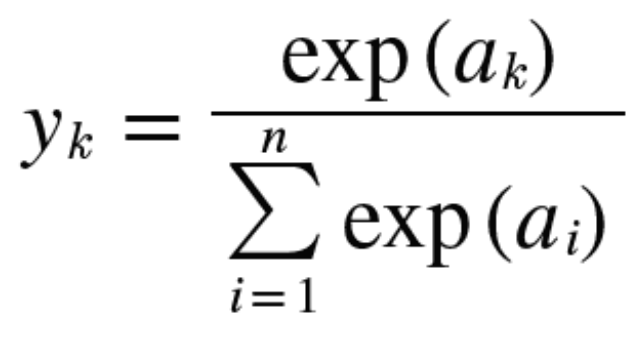
앙상블은 지도학습
혼합분포군집 - EM
SOM - 입력 노드들이 일정하게 군집에 속하도록 하는 거 X. 경쟁학습으로 가장 유사한 노드가 승자가 됨
와드연결법 - 군집 합병 시 전체 군집 내 제곱오차합의 증가를 최소화
내일 할 거
- 래퍼런스 찾기
- 세션 3개인 날임
- 세션 예복실습
- ADsP 마무리 정리

이거 튜터님께 여쭤보기 - 오토 아리마, 오토 인코더 찾아보기
