-
9:00 ~ 10:00 : ADsP
-
10:00 ~ 12:00 : 태블로 세션
-
15:00 ~ 16:00 : 시계열 세션
-
16:00 ~ 17:00 : 시계열 세션 복습
-
17:00 ~ 18:00 : ADsP
-
19:30 ~ 20:30 : 스트림릿 세션
-
20:30 ~ 21:00 : 오후 스크럼 및 TIL 작성
시계열 세션
너무 딥하게 들어가지 말고 적당히 쳐내기
언제 쓰는지, 해석은 어떻게 하는지 초점을 맞춰서 공부하기
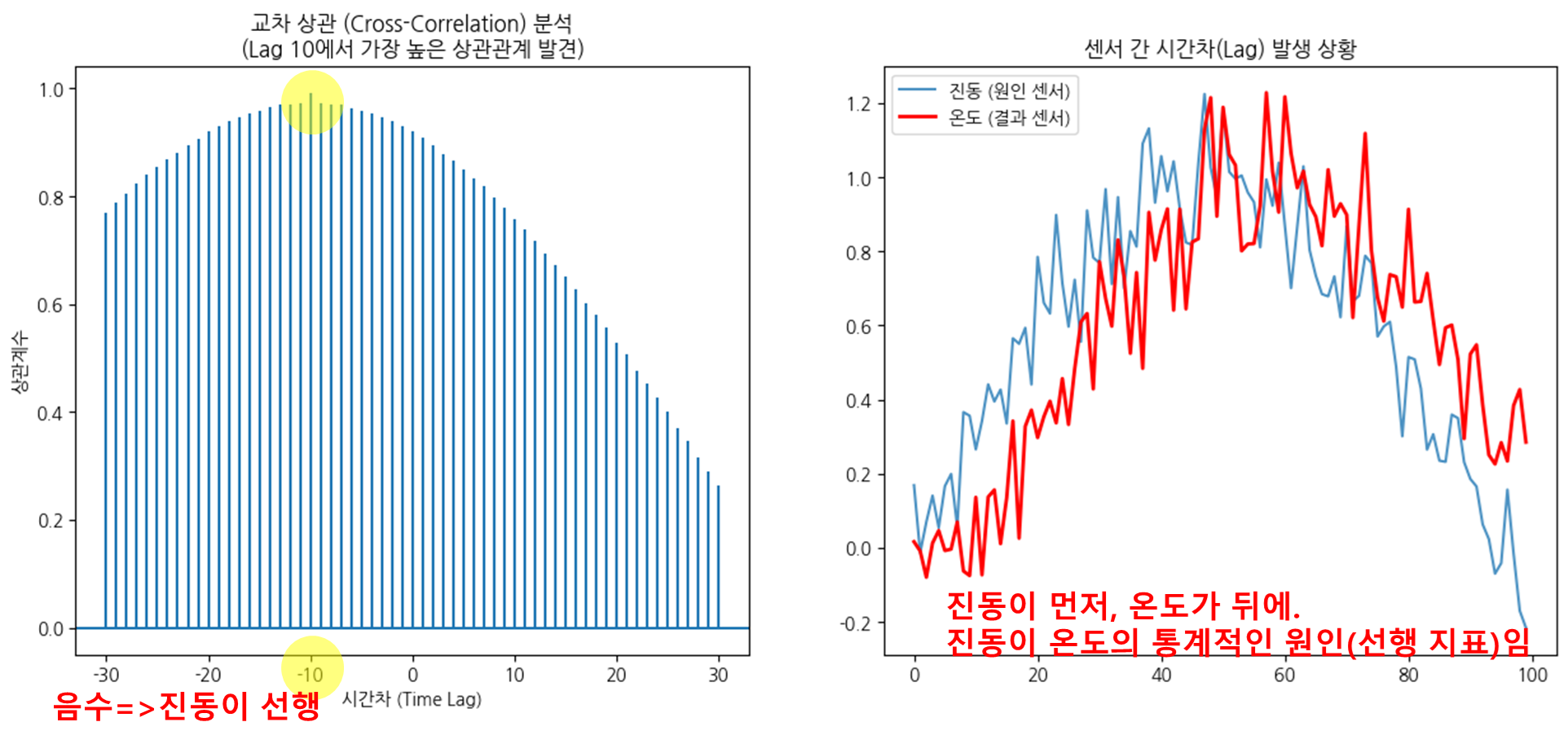
인과관계 및 시차 분석
▶Cross-Correlation 교차 상관
어떤 게 먼저 일어났는가?
시차값(Lag)가 음수 -> X가 선행
0은 동시에
시차값(Lag)가 양수 -> X가 후행
▶Granger Causality 그랜저 인과관계
A 센서가 B 센서를 '선행'하는지 판별.
원인이 뭔지 짚어준다
# 그랜저 인과관계 검정
# 진동이 온도를 예측하는지 확인
granger_result = grangercausalitytests(df[['온도', '진동']], maxlag=15, verbose=False)
p_value = granger_result[10][0]['ssr_chi2test'][1] # Lag 10에서의 p-value
# 이렇게 해서 p value도 확인시계열 예측 모델
예측!!
Prophet, LSTM이 대표적
▶Prophet
가법모델 기반
(가법모델이 수학적으로 더 쉽고 이론을 들이밀기 좋다고 앞에서 얘기하셨음)
와디즈, 쿠팡, LG U+ 등의 기업에서 사용함
장점: 완전 자동화 및 강건성(Robustness), 도메인 지식 주입(Tunable), 속도
파라미터 제어: 추세(Trend) 선택 가능, 유연한 계절성(Seasonality), 휴일 효과(Holidays) 반영 가능
계절성, 공휴일, 매년 반복되는 공휴일이 아니고 대선이라던가 10년 단위 창립기념일이라던가 이런 것도 적용이 가능하다
▶LSTM
딥러닝이긴한데 머신러닝이랑 딥러닝 크게 다르진 않음
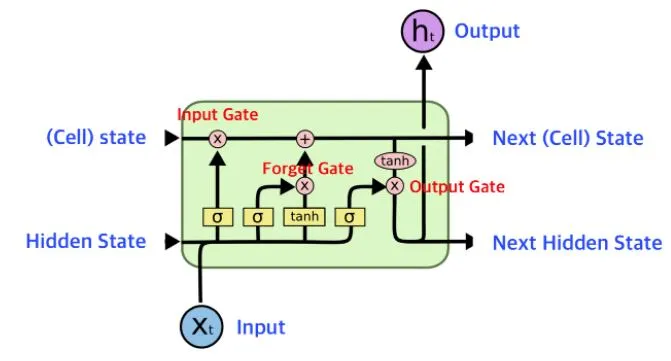
위에 사진에서 forget gate라는 부분이 과거를 잊어버리게 만듦
RNN - 옛날꺼는 망각함
LSTM - 과거를 기억함
GRU - LSTM 만큼의 성능을 원하는데 좀 더 가벼운 걸 원할 때 사용함
XGBoost(정밀)와 LightGBM(빠름)의 관계
# 학습 로그를 시각화하기 위해 history 변수에 할당합니다.
history = model.fit(X, y, epochs=10, batch_size=32, validation_split=0.1, verbose=1)여기서 epochs는 전체 학습 데이터를 몇 번 반복해서 학습하느냐
숫자데이터만 할 때는 300
자연어로 할 때는 30정도만 해도 결과 나온다(모델이 비교적 빨리 패턴을 잡음)
루마니아 데이터셋 활용한 LSTM; 코드돌려보기
val_loss가 봐야하는 부분
이상탐지 Anomaly Detection
미리미리 전조증상 포착해서 대참사 막는다
▶이상탐지 3가지 유형
- Point Anomalies (포인트 이상치)
순간 과전압 - Contextual Anomalies (문맥적 이상치)
불량은 아닌데 뭔가 이상함; 휴무일인데 누가 전기를 쓰고있지? - Collective Anomalies (집단적 이상치)
개별 불량률은 낮지만, 한 시간 동안 연속적으로 작은 불량이 누적되는 경우
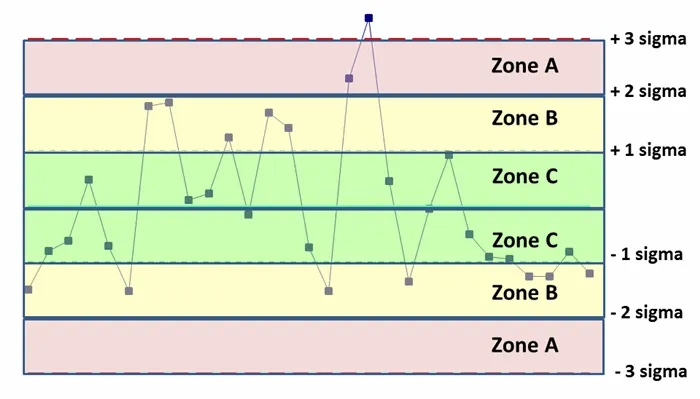
▶이상 판정
관리 상태 (Stable) - Zone A 안에서 노는거
비관리 상태 (Unstable) - Zone A 밖으로 값이 나가거나, 지속적으로 한쪽에 쏠려있거나, 변화추세가 한쪽방향으로 쏠리거나(패턴이 보이는 경우)
이상이 있나 판정하는 규칙이 있음
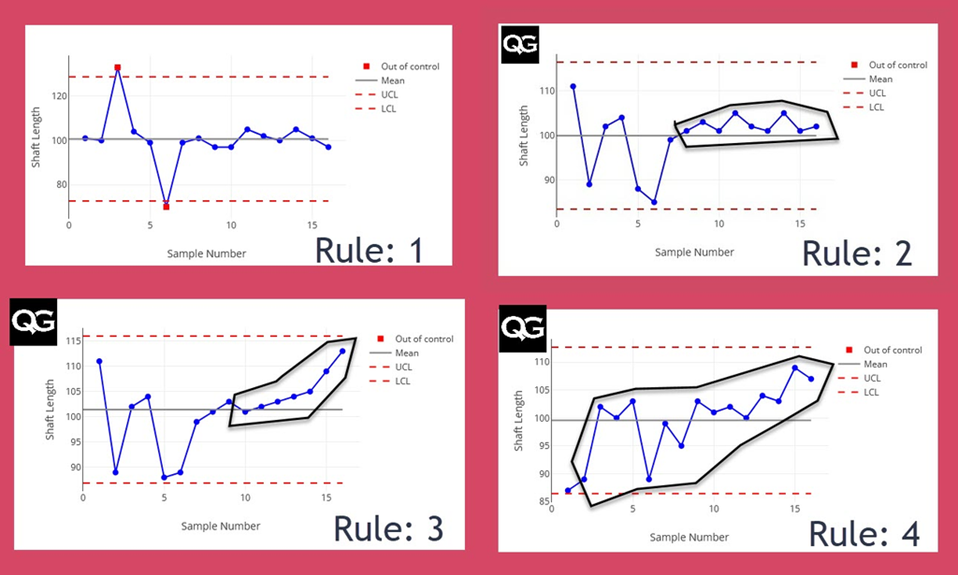
- Rule 1(Beyond Limits): 1개의 점이 3σ를 벗어남 (명백한 이상).
- Rule 2 (Shift): 9개의 점이 연속으로 평균의 한쪽 방향에만 나타남 (공정 편향 발생).
- Rule 3 (Trend): 6개의 점이 연속적으로 상승하거나 하락함 (장비 마모 의심).
- Rule 4 (Alternating): 14개의 점이 번갈아 가며 증감함 (측정 이상 또는 작업자 간섭).
▶X-Bar-R
XBar랑 R 표시해둔 선이 있는데 이 근처에 잘 찍혀있는가를 봄
▶머신러닝(ML) 기반 이상 탐지
다변량 변수일 때는 룰베이스 말고 모델 베이스로
- Elliptic Envelope (타원형 경계 기반 이상치 탐지)
 중심에서 떨어져있느면 이상치
중심에서 떨어져있느면 이상치
.
.
▶CPD (Change Point Detection)
▶생존 분석 (Survival Analysis)
▶Concept drift
.
.
흐름 잡아놓으신거 다시 보기
프로젝트 하기전에 예시 코드로 BMS 시계열 정리해두신거 보면서 흐름 잡기
ADsP

지피티니한테 3과목 요점정리 해달라고 해봄
오늘의 오답정리
1과목
빅데이터 3V: 크기, 다양성, 진실성
프라이버시 보호 3대 권고사항
- 상품개발단계부터 개인정도 보호 방안 적용
- 소비자에게 공유 정보 선택 옵션 제공
- 소비자에게 수집된 정부에 대한 접근권 부여
빅데이터 가치 패러다임: 디지털화-연결-에이전시
빅데이터 등장 배경: 대량 데이터, 인터넷 발전, 분석 기술 발전
데이터베이스 구축은 데이터베이스 아키텍처의 일임. 사이언티스트 아님.
이용자가 원하는 정보 신속하게 획득할 수 있도록 -> 정보 이용 측면
2과목
정확도: 모델-실제 간 차이가 적은 정도
정밀도: 모델 예측값의 편차 수준. 분석 안정성 확보를 위해서는 정밀도각 중요
데이터 분석 조직 구조
- 기능형: 각 부서에서 직접 분석. 업무 이원화 문제
- 집중형: 분석 부서 따로 있음
- 분산형: 분석 담당자를 현업 부서에 배치
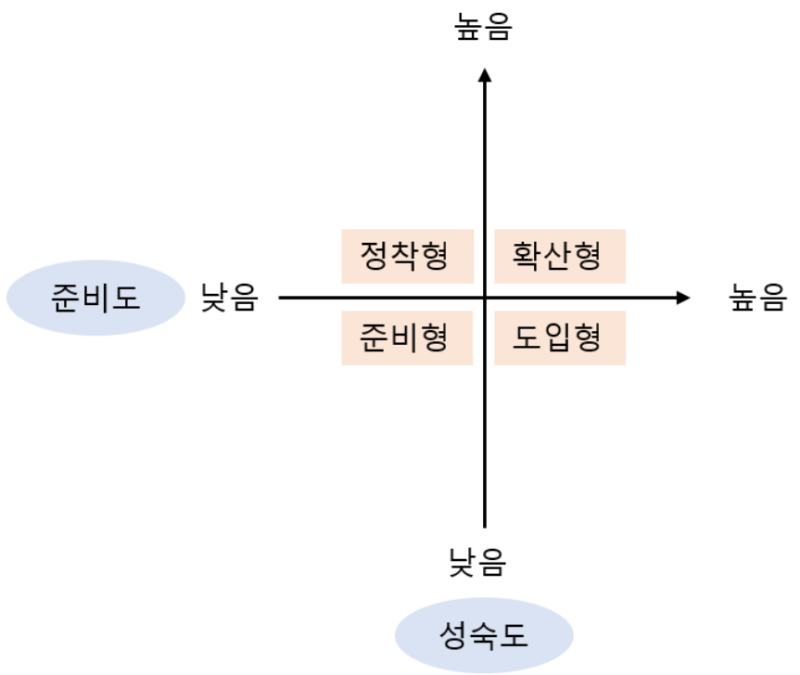
분석 성숙도 평가의 도입단계의 예시 -> 실적 분석 및 통계
분석 업무 체계적인 관리(=분석거버넌스)를 위한 요소: 조직, 프로세스, 시스템, 데이터, 마인드. 분석 기술은 아니삼!!!!
3과목
베이즈 이론: 사전확률, 우도확률 ~~> 사후확률. 귀납추론. 모든 특징 변수 독립
다중 회귀: 독립 2개 이상, 종속 1개
다항 회귀: 2차 함수 이상의 관계
로지스틱 회귀: 종속이 범주형
층화 추출: 모집단 간 이질, 모집단 내 원소 간 동질
인공신경망에서 가중치 목적: 입력 신호의 강도 조절
K평균: 하나의 데이터는 하나의 군집에만 속할 수 있다
의사결정 나무에서 가지치기 이유: 과적합 방지. 가지치기는 적당히 분할해 샤샥!임
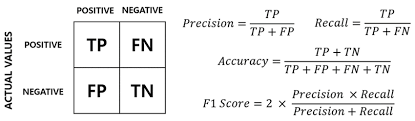
코사인 유사도: 두 벡터 간의 유사도 측정
결측값 대치
완전 대치: 걍 결측이면 삭제
단순 확률 대치: K-NN으로 평균대치 문재 보완
다중 대치: 여러 번 대치해서 n개의 자료
회귀분석 잔차 그래프에서 잔차-독립변수 간의 독립성은 알 수 없다
Apriori 알고리즘 순서
- 최소지지도 값 설정-빈발 항목 선별-상호연관 규칙(신뢰도, 향상도) 도출-반복 수행
중심극한정리
모집단 분포에 상관없이 정규분표를 따르는 것임. 표준정규분포 아님!
모집단이 비대칭인 경우에도 정규분포를 따름
일반화: 특정 표본, 환경에 국한되지 않고 다른 데이터에서도 동일한 결과 도출하는 특성
계층적 군집분석: 유사성 측정해서 유사한 데이터끼리 군집으로 묶는 분석 방법. 하지만 사용자 간 친밀도/관계성 측정이 목적은 아님
K-Means 클러스터링에서 k값 결정을 위해서 집단 내 제곱합 그래프를 이용할 수 있음
주성분 분석은 차원축소를 위한 것. 그 과정에서 상관성이 낮은 변수들의 선형결합으로 주성분을 생성하게 됨. 목적이 선형 관계 파악이 아님
시계열 데이터 정상화에 쓰는 방법: 차분, 이상치 제거, 구간 분할
향상도: X교Y / X x Y
덴드로그램의 군집 크기를 비교하면서 병합 여부를 결정하진 않음
K-NN: 최근접 알고리즘. 주변 k개로 판별. k가 작을수록 이상치에 민감, 과적합. 게으른 학습.
두 데이터 간 거리, 강한 양의 상관관계 -> 마할라노비스
내일 할 거
- 시험 잘치기~
