📌 Map 이란
map은 자료를 유일한
key와 하나의value쌍으로 저장하는 자료구조이다.
앞서 말했듯 키는 고유해야 하며 중복된 키를 삽입하려 하면 기존 키에 해당하는 값이 업데이트 된다.
Map은 key 값을 오름차순 정렬하여 저장한다는 특징이 있다.
Map의 검색, 삽입, 삭제의 시간 복잡도는 평균 O(log N) 인데
이는 내부적으로 자가 균형 이진 탐색 트리인 레드-블랙 트리를 사용하기 때문이다.
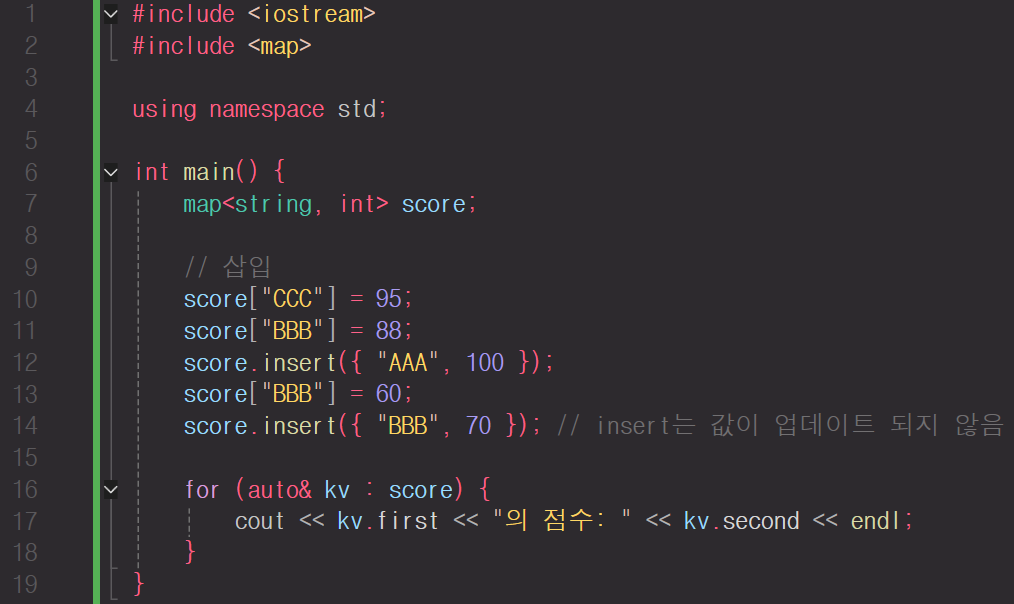
우선 해당 코드를 실행해 보면

이런 결과를 볼 수 있다.
오름차순이 잘 되고 중복 키면 값이 잘 업데이트 된다.
다만 insert의 경우 중복 키면 업데이트가 되지 않는 걸 알 수 있다.
우선 레드-블랙 트리는 자가 균형 이진 탐색 트리이다.
이제 자가 균형 이진 탐색 트리가 뭔지 궁금해질텐데 그전에 이진 탐색 트리 먼저 알아보자
이진 탐색 트리(Binary Search Tree, BST)
이진 트리 중에서도 왼쪽 자식 노드는 현재 노드보다 작고, 오른쪽 자식 노드는 크다는 조건을 가진 트리이다.
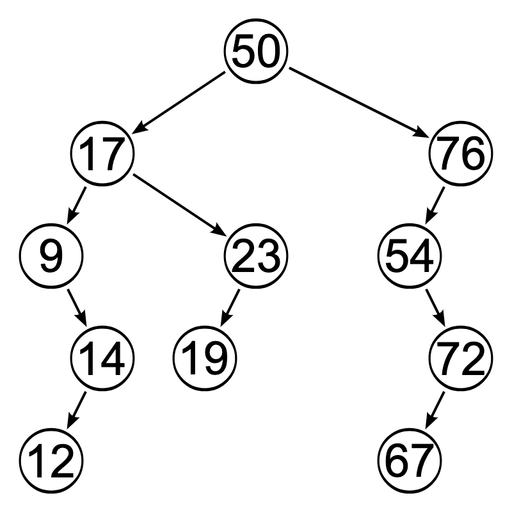
이렇게 예쁘게 정렬 된 경우엔 O(log n)의 시간 복잡도를 가지겠지만
다만 아래 사진처럼 자식 노드가 루트 기준으로 오름차순이라면 어떻게 될까?
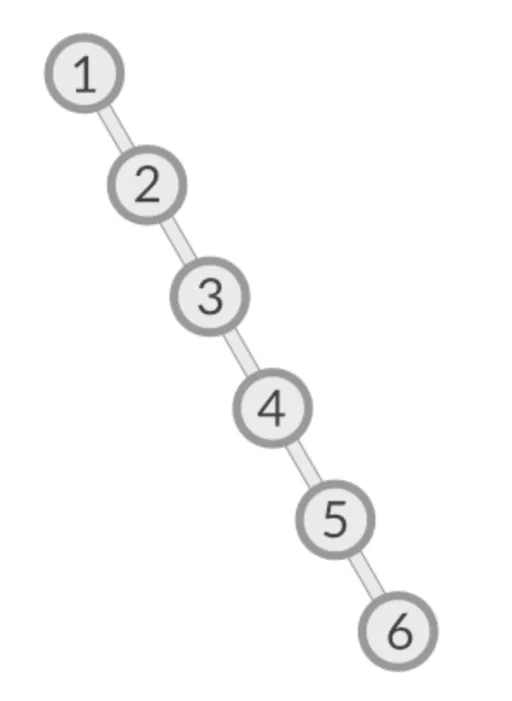
속도를 올리려고 사용한 이진 탐색트리가 그냥 배열과 다름 없어지게 된다.
이처럼 한쪽으로 치우친 편향 트리의 시간 복잡도는 O(n)이 된다.
이러한 상황을 방지하기 위한 트리가 있는데 바로 자가 균형 이진 탐색 트리 이다.
자가 균형 이진 탐색 트리(self-balancing binary tree)
자가 균형 이진 탐색 트리는 데이터를 삽입하거나 삭제할 때, 트리의 높이가 너무 커지지 않도록 자동으로 균형을 맞추는 트리이다.
자가 균형 BST는 삽입/삭제 시 트리 구조를 조정해서 항상 O(log n) 시간복잡도를 유지한다.
자가 균형 이진 탐색 트리의 종류는
-
AVL 트리
-
레드-블랙 트리
-
Splay 트리
-
Treap, Scapegoat Tree, B-tree 등도 존재 (특수 목적)
정도가 있는데 오늘 알아볼 건 레드-블랙 트리이다.
레드-블랙 트리
레드-블랙 트리는 각 노드(데이터를 담고 있는 작은 상자)를 색깔(레드와 블랙)로 구분한다.
여기에 몇 가지 규칙이 더해지는데
- 모든 노드는 레드 아니면 블랙이다.
- 루트 노드는 블랙이다.
- 모든 NIL 노드는 블랙이다.
- 레드 노드는 레드 노드를 자식으로 가질 수 없다. 따라서...
- 모든 레드 노드의 부모는 블랙이다.
- 레드 노드는 연속으로 존재할 수 없다(Double red).
- 임의의 한 노드에서 NIL 노드까지 도달하는 모든 경로에는 항상 같은 수의 블랙 노드가 있다.
nil 노드는 트리에서 존재하지 않는 자식을 나타내기 위해 사용된다. (검은 점)
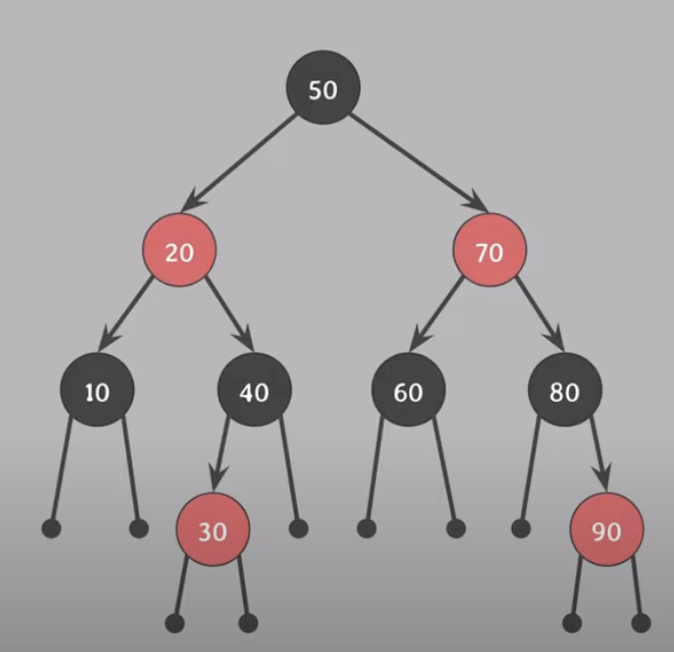
새로 삽입하는 노드는 무조건 레드 노드이기 때문에 5번 규칙을 위배하지 않는다.
만일 삽입과 삭제로 균형이 깨지는 경우 색상 조정과 회전 작업을 통해 균형을 회복시킨다.
이러한 규칙 덕분에 삽입, 탐색, 삭제 모두 최악의 경우 O(log N)의 시간 복잡도를 갖는다.
AVL 트리
AVL 트리의 가장 큰 특징은 모든 노드에 대해 왼쪽 서브트리와 오른쪽 서브트리의 높이 차이(=균형 인수, Balance Factor)**가 1 이하로 유지되도록 하는 것 이다.
AVL 트리도 삽입이나 삭제를 통해 이 균형 조건이 깨질 경우 트리 회전(Rotation)을 통해 다시 균형을 맞춘다.
AVL 트리는 높이에 매우 민감하게 반응하기 때문에 이 과정은 레드-블랙 트리보다 더 자주 회전이 일어날 수 있는 구조이다.
그 결과 AVL 트리는 탐색 속도는 레드-블랙 트리보다 더 빠를 수 있지만, 삽입과 삭제가 자주 발생하는 환경에서는 회전 연산이 부담이 될 수 있다.
C++의 std::map이나 std::set 같은 STL에서는 삽입·삭제 연산의 전체적인 효율을 고려해 레드-블랙 트리를 채택하고 있다.
📌 unordered map 이란
key와 value의 쌍을 저장하고, 정렬된 순서를 보장하지 않는다.
내부 데이터 구조는 해시 테이블을 사용한다.
따라서 key를 기준으로 빠른 검색 (평균 O(1))을 제공한다.
다만 해시 충돌이 일어나는 최악의 경우 O(n) 까지 성능이 저하된다.
해시 테이블(Hash Table)
정리가 잘 되어있는 블로그가 있어 링크를 첨부한다
키(key)를 넣으면, 내부에서 어떤 위치(index)를 계산해서 거기에 값(value)을 저장하는 구조이다.
unordered_map<string, int> map;
map["apple"] = 5;- "apple"이라는 키를 → 해시 함수로 숫자 index 계산
- 예: "apple" → 123
- 배열의 123번째 칸에 5 저장
Index 123: ("apple", 5)이제 "apple"로 검색하면 바로 index 123으로 가서 꺼내오기만 하면 된다 → O(1)!
해시 충돌(Collision)
두 개의 키가 같은 index를 계산해내면 어떻게 할까?
예:
"cat" → 42
"tac" → 42
이걸 충돌(Collision)이라고 합니다.
충돌 해결 방식
-
체이닝 (Chaining)
충돌이 발생한 위치에 연결 리스트(또는 다른 컨테이너)를 만들어 해당 인덱스에 여러 개의 (key, value) 쌍을 저장 -
오픈 어드레싱 (Open Addressing)
빈 칸을 찾아 다른 index에 저장
