개요
Pintos Projects: Threads의 첫 번째 요구사항은 "Alarm Clock"으로 timer_sleep() 함수를 다시 구현하는 것입니다.
/* timer.c */
void
timer_sleep (int64_t ticks)
{
int64_t start = timer_ticks ();
ASSERT (intr_get_level () == INTR_ON);
while (timer_elapsed (start) < ticks)
thread_yield ();
}기존 timer_sleep() 함수는 while문 안에서 요청된 시간이 지났는지 확인을 하고, 지나지 않았다면 실행을 양보하는 방식으로 구현되어 있습니다. 이것을 "busy waiting"이라고 합니다. 이번에는 busy waiting 방식을 사용하지 않고 timer_sleep() 함수를 구현해야 합니다.
구현
스레드 생명주기
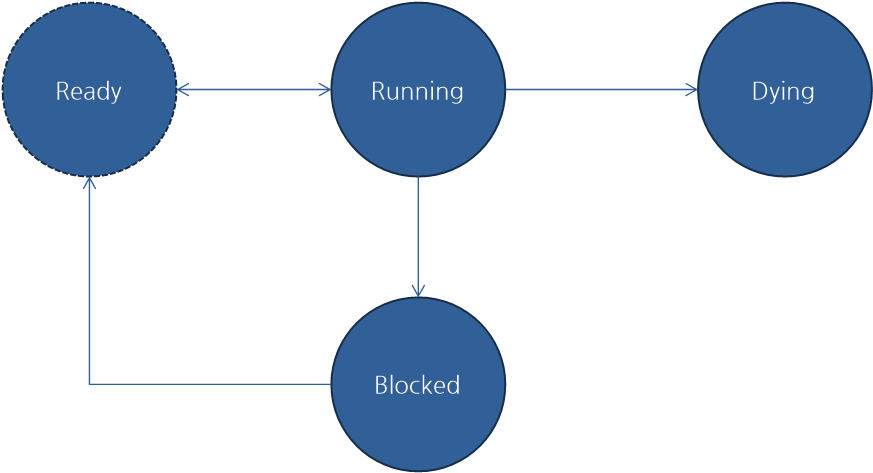
pintos에서 스레드(thread)가 생성되면 Ready 상태에서 시작을 하며, ready_list에 들어갑니다. 그리고 스케줄러(scheduler)가 선택한 스레드는 Running 상태가 되고 실행을 합니다. 일정 시간이 지나면 스케줄러는 다른 스레드를 선택하여 실행하게 되고 이전 스레드는 다시 Ready 상태가 되어 스케줄러에게 선택될 때까지 기다립니다. 그리고 스레드가 종료될 때는 Dying 상태가 되고 이후에 메모리가 해제됩니다.
이때, 스레드가 특정 이벤트가 발생할 때까지 기다리고 싶다면 해당 스레드를 Blocked 상태로 설정합니다. 스레드가 Blocked 상태가 되면 해당 스레드를 스케줄러의 선택에서 제외됩니다. 따라서 스레드는 전혀 실행되지 않습니다.
timer_sleep() 함수를 구현할 때, 이 점을 활용합니다. timer_sleep() 함수를 호출하면 해당 스레드를 블록하여 스케줄러가 선택하지 못하도록 합니다. 그리고 요청된 시간이 지나면 블록을 해제하여 다시 ready_list에 추가합니다. 그런데 이때, 스레드가 요청한 대기 시간이 지났는지를 어떻게 확인할 수 있을까요?
바로 timer interrupt를 통해서 검사합니다. timer interrupt는 타이머에서 주기적으로 발생하는 신호인데, pintos에서는 이 신호가 발생하면 timer interrupt handler를 실행하도록 되어 있습니다. 그래서 여기서 wait_list를 순회하면서 현재 대기 시간이 끝난 스레드를 찾아서 다시 ready_list로 넣어주면 됩니다.
wait_list
/* timer.c */
struct sleep_thread
{
struct list_elem elem;
struct thread *thread;
int64_t end_ticks;
};
static struct list wait_list;대기 중인 스레드를 관리하기 위해서 sleep_thread 구조체와 wait_list 변수를 정의합니다.
timer_sleep()
/* timer.c */
static struct lock sleep_lock;
void
timer_sleep (int64_t ticks)
{
int64_t start = timer_ticks ();
ASSERT (intr_get_level () == INTR_ON);
if (ticks > 0)
{
enum intr_level old_level = intr_disable ();
struct sleep_thread sleeper;
sleeper.thread = thread_current ();
sleeper.end_ticks = start + ticks;
lock_acquire (&sleep_lock);
list_push_back (&wait_list, &sleeper.elem);
lock_release (&sleep_lock);
thread_block ();
intr_set_level (old_level);
}
}timer_sleep 함수를 실행하면 interrupt를 비활성화합니다. 그 이유는 timer_sleep 함수가 실행 되는 도중에 timer interrupt가 호출될 수 있기 때문입니다. timer_sleep 함수가 실행 중에 timer interrupt가 호출될 경우, 경쟁 상태가 발생할 수 있습니다. interrupt를 비활성화하면 timer interrupt가 호출되지 않기 때문에 이 문제를 해결할 수 있습니다. (context switching이 발생하면 interrupt는 다시 활성화 됩니다.) 그리고 wait_list에 원소를 추가할 때는 lock을 사용합니다. 그 이유는 여러 thread가 timer_sleep 함수를 사용할 경우, 경쟁 상태가 발생할 수 있기 때문입니다. lock을 사용하면 이 문제를 해결할 수 있습니다.
timer_interrupt()
static void
timer_interrupt (struct intr_frame *args UNUSED)
{
ticks++;
thread_ticks ();
update_wait_list ();
}
static void
update_wait_list (void)
{
struct list_elem *cursor = list_begin (&wait_list);
while (cursor != list_end (&wait_list))
{
struct sleep_thread *sleeper = list_entry (cursor, struct sleep_thread, elem);
if (sleeper->end_ticks > ticks)
cursor = list_next (cursor);
else
{
cursor = list_remove (&sleeper->elem);
thread_unblock (sleeper->thread);
}
}
}timer interrupt는 특정 시간 간격(TIMER_FREQ)마다 호출됩니다. 여기서 wait_list를 순회하면서 대기시간이 종료한 thread를 다시 깨웁니다. thread가 일어나면 바로 실행되는 것은 아니고, ready_list에 들어가서 scheduler가 선택할 수 있게 됩니다.
문제 및 해결
변수 생성
timer_sleep() 함수를 호출한 스레드를 wait_list에 넣어서 관리하려고 할 때, 처음에는 malloc() 함수를 사용해서 데이터를 생성했습니다. 왜냐하면 데이터가 timer_sleep() 함수 호출이 끝난 후에도 유지되어야 했기 때문이었습니다. 그런데 malloc() 함수를 사용하여 구현하니까 timer_sleep() 함수가 지연되는 현상이 발생하였습니다. malloc() 함수에 오버헤드가 있었기 때문입니다.
이 문제를 해결하기 위해서는 스택 변수를 할당하면 됩니다. 원래라면 스택 변수는 함수 호출이 끝나면 사라지기 때문에 데이터가 유지되지 않지만, 그 다음에 스레드를 블록시키면 pintos에서 중간 상태를 kernel stack에 저장을 시키기 때문에 데이터가 유지됩니다.
Github
- link: https://github.com/chahoseong/pintos
- branch: project/threads
Reference
https://thierrysans.me/CSCC69/projects/WWW/pintos_2.html#SEC26
