1. sort_values
값을 정렬해주는 함수이고 아무런 옵션이 없으면 오름차순
(내림차순은 ascending = False 입력하면 됨)
df.sort_values('displacement').head()displacement 칼럼 기준으로 오름차순 정렬
인덱스로도 정렬 가능
2. rename
칼럼 이름 다시 지정
df = df.rename(columns= {'acceleration':'velocity'})'acceleration'를 'velocity'로 칼럼이름을 바꿈
3. melt
데이터를 펼칠 때 사용
melted_df = pd.melt(df, id_vars=['A'], value_vars=['B'])id_vars=['A'] : 녹이지 않고 그대로 유지할 열을 지정
value_vars=['B']: 녹여서 하나의 열로 합칠 열을 지정
-
df

-
melted_df
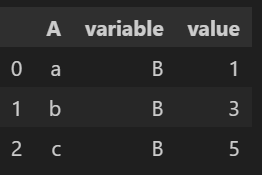
4. pivot
파이썬으로 피벗테이블 만들기
df2 = df.pivot(index='foo', columns='bar', values='baz')원본 DataFrame
df에서foo컬럼의 고유 값을 행 인덱스로,bar컬럼의 고유 값을 열 이름으로 지정하여 각 교차점에 해당하는baz값을 채운 새로운 피벗 테이블을 생성
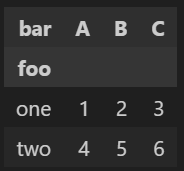
bar랑 foo 두 줄이라서 보기 애매함 이럴 때 밑에처럼
pivoted_baz = df.pivot(columns='bar')['baz']원본 DataFrame df를 사용하여 인덱스는 그대로 두고 (기본 인덱스 유지) bar 컬럼의 고유 값을 새로운 열 이름으로 만들고, 각 열에 대응하는 baz 컬럼의 값을 채운 피벗 테이블을 생성함 그런 다음 생성된 피벗 테이블에서 baz 값만 선택
5. concat
데이터를 세로로 붙임
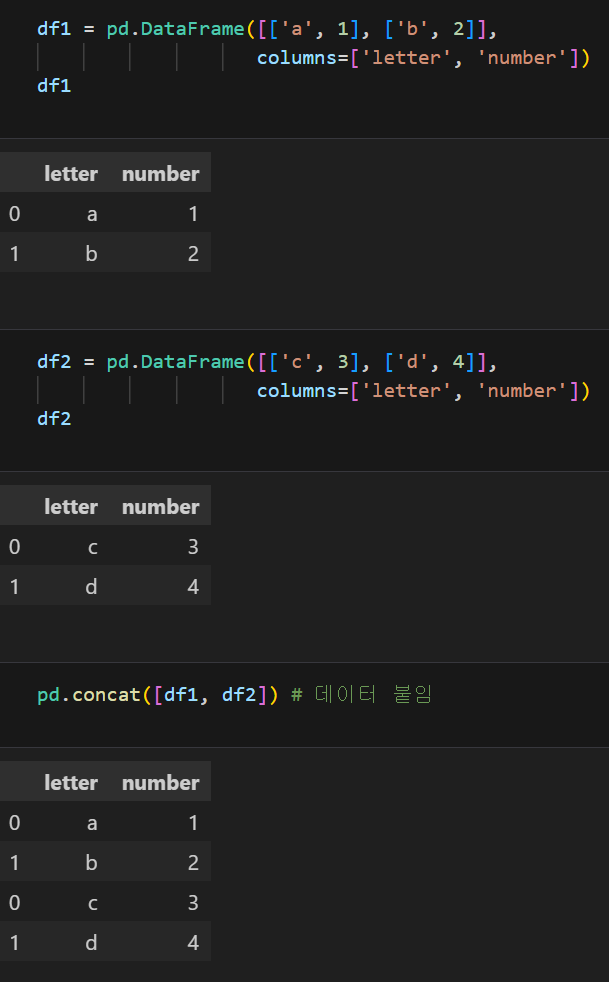
df1, df2를 붙인 것을 알 수 있음
6. merge
SQL의 join
pd.merge(adf, bdf, how='left', on='x1')adf, bdf를 lef join으로 붙이고 join은 테이블은 x1
7. shift
값을 이동
df2['b'].shift(2)b 열의 값을 2행 아래로 이동시키고, 앞부분은 NaN으로 채움
8. cumsum
한 칸 위에 수랑 합한 값 나옴
(다른 집계함수도 가능)
df.cumsum()