들어가기
- 배울 내용
문제정의 - 데이터 확인 - 데이터전처리 - AI모델 선정 - 학습 데이터 분할 - 학습 - 성능평가
강의 자료를 따라가보면서 전체적인 흐름 파악이 목적
1. 문제정의
건강에 좋지 않은 수치인 LDL콜레스테롤 수치를 예측하는 모델을 개발
2. 데이터 확인
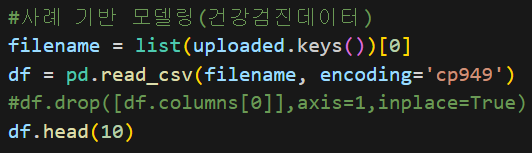
건강검진 데이터 파일을 불러와서 df로 만듬
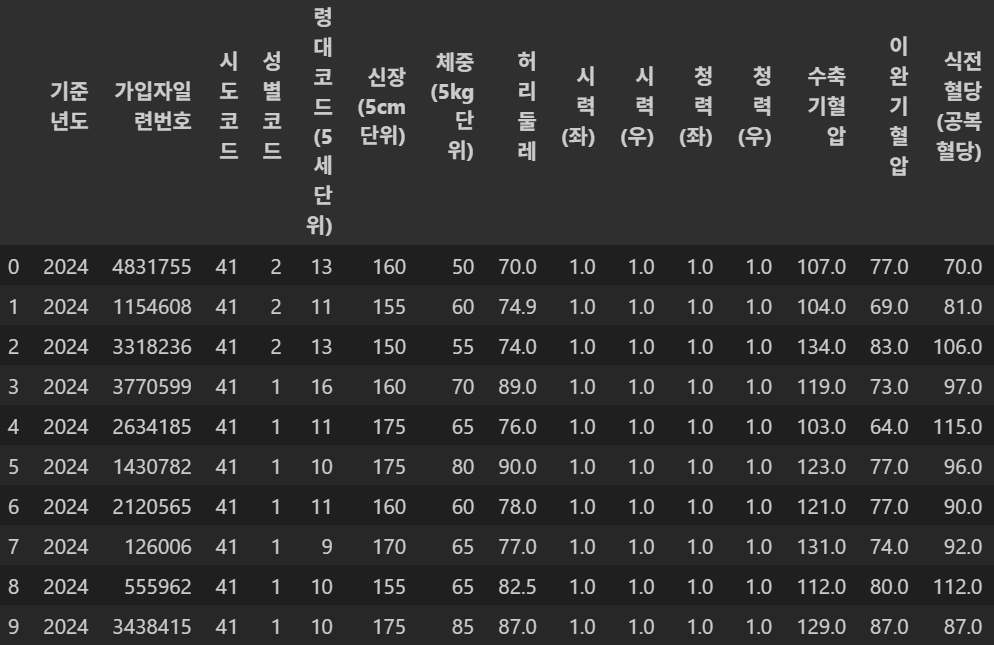
칼럼들만 보면 다음과 같다
Index(['기준년도', '가입자일련번호', '시도코드', '성별코드', '연령대코드(5세단위)', '신장(5cm단위)',
'체중(5kg단위)', '허리둘레', '시력(좌)', '시력(우)', '청력(좌)', '청력(우)', '수축기혈압', '이완기혈압', '식전혈당(공복혈당)', '총콜레스테롤', '트리글리세라이드', 'HDL콜레스테롤', 'LDL콜레스테롤', '혈색소', '요단백', '혈청크레아티닌', '혈청지오티(AST)', '혈청지피티(ALT)', '감마지티피', '흡연상태', '음주여부', '구강검진수검여부', '치아우식증유무', '결손치 유무', '치아마모증유무', '제3대구치(사랑니) 이상','치석'], dtype='object')
3. AI모델 선정
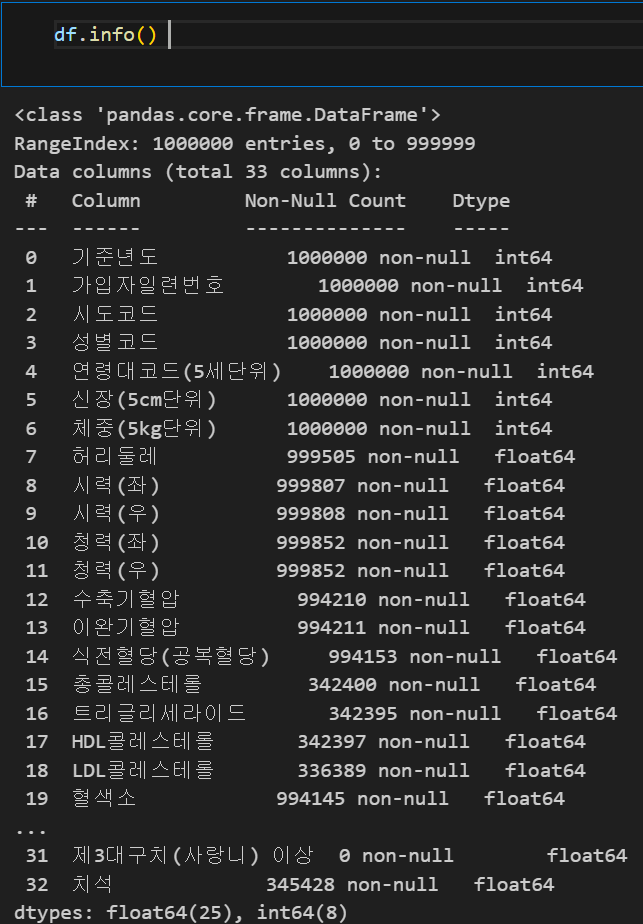
분류가 아니라 회귀를 해야 할 듯 (연속적인 수이기 때문)
4. 데이터 전처리

필요없는 칼럼 제거
5. 학습 데이터 분할

예측 모델을 만들기 위해서 칼럼들 제거 후,
LDL콜레스테롤 값이 비어있는 테스트 테이블, LDL콜레스테롤 값이 있는 트레인 테이블을 만듬 (학습 데이터 분할)
6. 학습
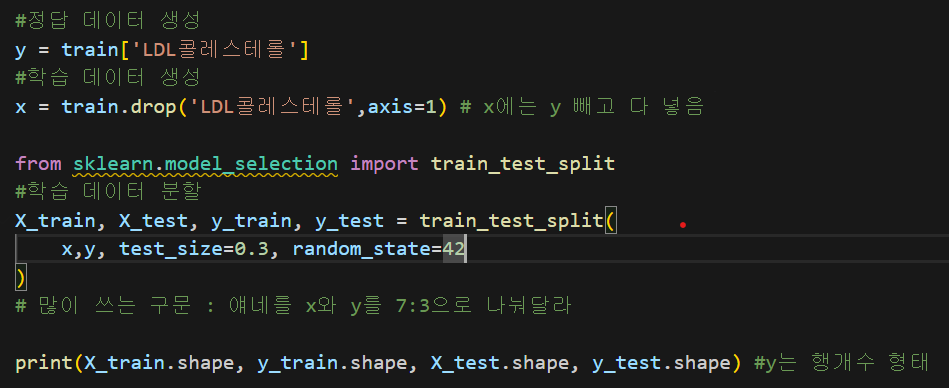
x와 y를 분리하고 학습용과 시험용을 7:3으로 분할함
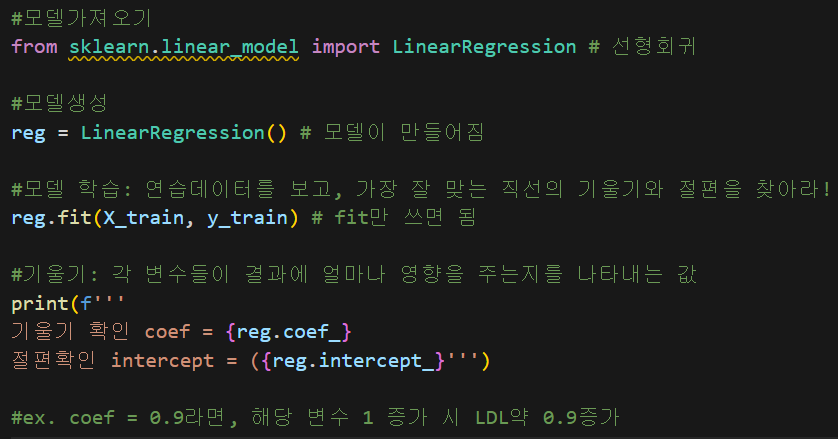
모델을 가져와서 학습 시킴
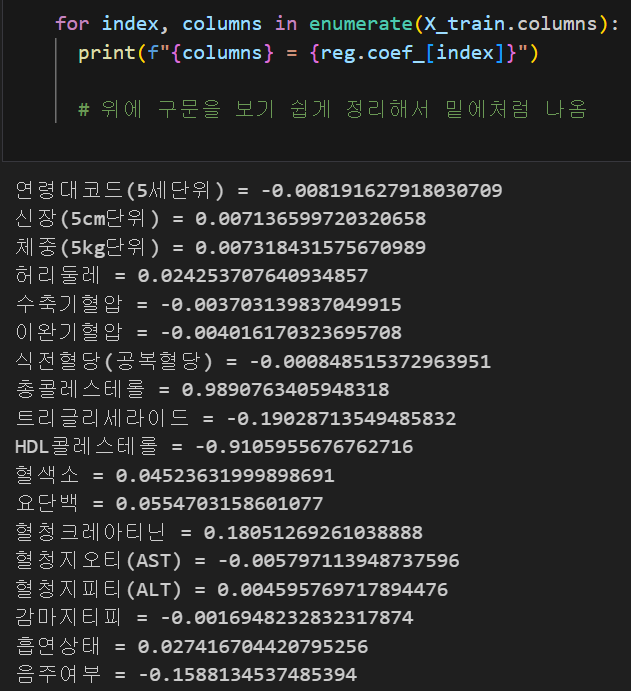
결과 깔끔하게 보기
7. 성능평가
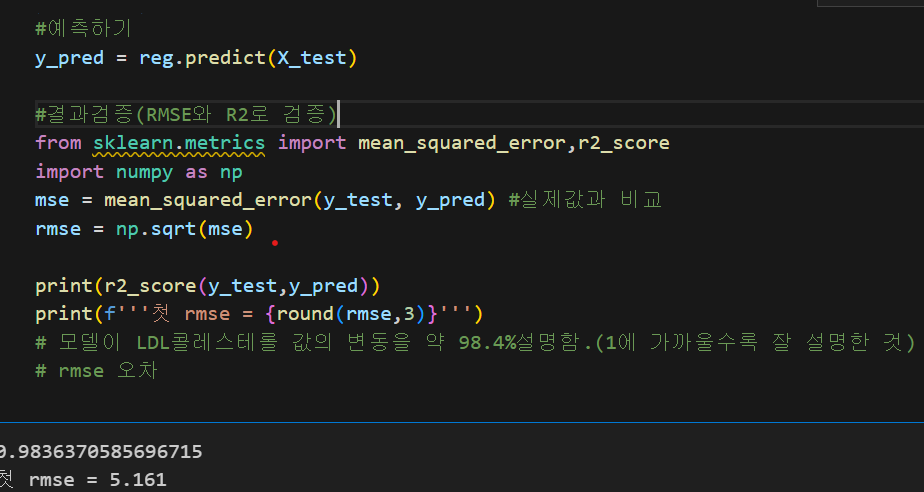
검증하고 오차 평가
8. 그 이후
1) baseline 모델을 사용하여 앞에 오차(rmse)보다는 높아야 의미가 있다고 판단
2) 다중공산성 문제 주의
회고
머리에서 정리가 안 되서 쓰면서 정리해봤다 내일 다시 복습하면서 이해가 잘 안 되는 부분은 튜터님들께 질문해봐야겠다
