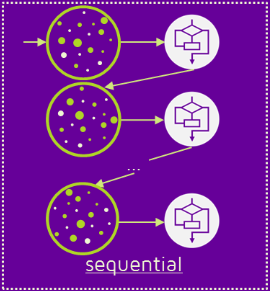
Bagging과 Boosting
앞선 랜덤포레스트 포스팅에서 배깅에 대해 언급한바 있다. 다시한번 복습을 해보자면 배깅은 여러개의 독립적인 모델들을 이용하여 서로의 영향을 받지 않은 선에서 결과를 집계하는 방식이다. 데이터셋이 생성될 때는 복원 추출을 통해 원래 데이터의 개수만큼 샘플링하게 되고, 이 개별 데이터셋(Bootstrap 셋)이라고 한다고 하였다.
그렇다면 부스팅은 무엇일까?
우선 bagging과 마찬가지로 앙상블 기법에 속한다. 여러개의 모델을 이용한다는 뜻이다. 하지만 결정적으로 다른 점이 있는데, 바로 사용되는 여러 모델들이 독립적이지 않다는 것이다. 확실히 이 부분에서부터 배깅보다는 더 복잡한 방식이라는 것을 알 수 있다. 여러개의 모델이 순차적으로 학습을 수행한다.쉽게 말해서 앞선 모델을 통해 피드백을 받아 가중치를 부여하면서 모델 자체를 발전해나간다.
Boosting의 종류
AdaBoost
다른 말로 Adaptive Boosting의 약자이다. AdaBoost는 약한 분류기에 가중치를 부여하여 강한 분류기를 만드는 모델이다. 즉, 뛰어난 하나보다 여러개의 일반적인 것들을 모아 좋은 모델을 만들겠다는 컨셉이란 것이다. 부스팅의 특성에 따라 이전 학습에서 처리하지 못한 샘플들을에 대해 더욱 개선하여 풀 수 있도혹 한다는 특성이 있다.
Gradient Boosting Machine
회귀 분석 혹은 분류 분서을 수행하기 위한 예측 모델로 엄청나게 좋은 성능을 보여주는 알고리즘으로 유명하다.실제로도 머신러닝 알고리즘 중에서도 가장 예측 성능이 높다고 알려져 있다. 이러한 이유로 파이썬 패키지들을 보면 이 알고리즘에 대해 정말 다양한 패키지들이 있다. Adaboost와 비슷하게 GBM 또한 이전까지의 오차를 보정하여 분류기에 순차적으로 추가를 하며 진행된다.
하지만 AdaBoost와 다른 점은 샘플의 가중치를 조정하는 것이 아닌 이전 분류기에서 만들어진 잔여 오차에 대한 새로운 분류기를 학습한다는 것이다. 다시 한번 간단하게 말하자면 Adaboost는 약한 모델을 강화하는 형식이고, Gradient Boosting Machine은 잔차를 예측하는 형식이다.
잔차라고 한다면 뭔가 떠오는 것이 있는데, 선형 회귀가 생각난다. 이전 포스트 선형회귀 부분에서 경사하강법에 대해 언급한바 있는데, 역시나 GBM 또한 경사하강법을 이용하여 최적화된 결과물을 얻는 알고리즘이라고 할 수 있다.
비록 예측 성능이 매우 좋다고는 하나 단점 또한 존재하는데 우선 계산량이 매우 많은 알고리즘이다. 또한 과적합 이슈가 있다는 특징이 있다.
코드
from sklearn.ensemble import GradientBoostingRegressor
model_gbt = GradientBoostingRegressor() #모델 생성하기
model_gbt.fit(X_train, y_train) #모델 학습시키기
model.score(X_train, y_train) #학습데이터에 대한 점수 보기하이퍼 파라미터
loss: default는 deviance이고 비용함수이다.
learning_rate: 약한 학습기가 순차적으로 오류값을 보정하는데 적용하는 계수로 0 ~ 1사이의 값으로 지정한다. 항상 그렇지만 너무 작은 값은 시간이 오래걸리지만 예측 성능이 높아질 수 있고, 너무 큰 값을 지정하면 빠르지만 예측 성능이 낮아질 수도 있다.
n_esstimator: 약한 분류기의 개수, 역시나 많아질수록 오래 걸리지만 성능이 올라갈 수 있다.
subsample: 학습에 사용하는 데이터 샘플링 비율(0 ~ 1)
XGBoost
XGBoost는 Extreme Gradient Boosting의 약자로 GBM의 단점을 어느정도 보완한 형태의 알고리즘이다. 이 알고리즘은 병렬학습이 지원되도록 구현되어 있다. XGBoost가 GBM의 단점을 보완했다고 하였는데, 우선 GBM보다 빠른 수행시간을 가지오 있다. 병렬 처리가 학습, 분류 속도를 바르게 해준다. 또한 과적합을 규제하는데 XGBoost는 자체적으로 과적합을 규제하는 기능을 가지고 있어 강한 내구성을 가지고 있다. 역시 뛰어나 예측 성능을 가지고 있고 Early Stopping 기능이 있다.
코드
import xgboost as xgb
model_xgb = XGBRegressor() #모델 생성하기
model_xgb.fit(X_train, y_train) #모델 학습시키기
model.score(X_train, y_train) #학습데이터에 대한 점수 보기하이퍼 파라미터
아래의 글이 매우 잘 정리되어 있으므로 다음을 참고하면 좋을 거 같다!
출처
LightGBM
일반적으로 GBM은 트리를 분할 할때 균형 트리 분할 방식을 이용한다. 이 방법을 이용하여 균형 잡힌 트리를 생성하면서 깊이를 최소화 할 수 있다. 하지만 계속 말했다시피 과적합에 취약하다는 단점이 있다. 반면에 LightGBM은 균형적인 트리 분할 방식을 이용하지 않고 리프 중심 트리 분할을 한다. 위에서 균형적인 트리 분할을 언급했다는 점에서 이 경우에는 균형적인 분할을 하지 않는다는 것을 추론해볼 수 있을 거 같다. 이 방법의 경우 트리의 균형을 맞추지 않음ㄴ서 최대 손실 값을 가지는 리프 노드를 지속적으로 분할 하면서 비대칭 적인 트리를 만든다. 비대칭적인 방식으로 분할 하다 보면 경국에는 예측 오류 손실이 최소화 된다는 컨셉을 가지고 있는 것이다.
정리를 해서 표현하자면 XGBoost에 비해 더 빠른 학습 시간을 가지고 있고, 메모리 사용량이 더 적다는 특징이 있다.
코드
from lightgbm import LGBMRegressor
model_lgbm = LGBMRegressor() #모델 생성하기
model_lgbm.fit(X_train, y_train) #모델 학습시키기
model_lgbm.score(X_train, y_train) #학습데이터에 대한 점수 보기하이퍼 파라미터
- num_iteration [default=100] : 반복 수행하기 위한 트리의 개수 지정한다.
- learning_rate [default=0.1] : 0~1 사이의 값을 지정해 부스팅 스텝을 반복적으로 수행할 때 업데이트 되는 학습률 값이다.
- max_depth [default=-1]: 최대 깊이를 설정해준다.
- min_data_in_leaf [default=20] : 최종 결정 클래스인 리프 노드가 되기 위해 최소한으로 필요한 레코드 수이다. (과적합 방지용)
- num_leaves [default=32] : 하나의 트리가 가질 수 있는 최대 리프 수이다.
- boosting [default=gbdt] : 부스팅 트리를 생성하는 알고리즘이다. (gbdt:일반적인 그래디언트 부스팅, rf:랜덤포레스트)
- bagging_fraction [default=1.0] : 트리가 커져서 과적합 되는 것을 방지하기 위한 데이터 샘플링 비율이다.
- feature_fraction [default=1.0] : 개별 트리를 학습할 때 무작위로 선택되는 피처의 비율이다.
- lambda_I2 [default=0.0] : L2 regulation 제어를 위한 값이다.
- lambda_I1[default=0.0] : L1 regulation 제어를 위한 값이다.
CatBoost
우선 CatBoost는 XGBoost처럼 Level-wise(균형분할) 트리이다. 그렇다면 다른점은 무엇일까? 일반적으로 부스팅 모델은 일괄적으로 모든 훈련 데이터를 대상으로 잔차 계산을 하는데, CatBoost는 일부만을 가지고 잔차 계산을 한다. 이후 데이터의 잔차는 모델로 예측한 값을 사용하게된다. 즉, x1~x2 까지의 데이터가 있다고 하면, 기존의 부스팅 방법에서는 x1~x2까지 모든 데이터에 대한 잔차를 일괄적으로 계산하는데, Catboost는
- x1의 잔차를 계산하여 모델 생성
- x2의 잔차를 이용하여 위의 모델을 예측
- x1, x2 의 잔차를 가지고 모델 생성
- x3, x4 의 잔차를 이용하여 위의 모델을 예측
- x1,x2,x3,x4를 이용하여 모델을 생성
- x5,x6,x7,x8의 잔차를 이용하여 위의 모델을 예측
- 반복
의 순서를 따라서 과정이 이어진다. 이러한 방식을 Ordered Boosting이라고 부른다.
항상 그렇지만 이런식으로 이어지면 계속 같은 잔차를 예측하는 모델을 만들 수 있기 때문에 순서를 섞어주어야 한다. 그러므로 Random permutation을 해줘야 한다.
코드
from catboost import CatBoostRegressor
# catboost 모델을 생성합니다.
model_cat = CatBoostRegressor() #모델 생성하기
model_cat.fit(X_train, y_train) #모델 학습시키기
model_cat.score(X_train, y_train) #학습데이터에 대한 점수 보기CatBoost도 조절할 수 있는 하이퍼 파라미터가 많으므로 적절하게 조정하면 좋은 성능을 가진 모델을 구축 할 수 있을 것이다.
