
의사결정 나무
과정
여느 지도 학습을 하기 위해서와 마찬가지로 의사결정 나무 모델을 구축하기 위해서는 학습과 예측 데이터셋을 만들어주어야한다. 물론 데이터의 전처리를 해주었다는 가정이다.
데이터 분할
데이터를 분할하는 방법에 대해서도 이미 여러가지 방법들이 있다. 몇가지 소개를 하자면 다음과 같다.
방법 1)
label_name="target 변수명"위와 같이 타겟 변수명을 따로 선언을 해준다. 타게 변수 뿐 아니라 학습 및 예측에 사용이 될 컬럼명들 또한 리스트의 형태로 선언을 해준다.
feature_names=df.columns.tolist()
feature_names.remove(label_name)이 때에 당연히 타겟이 될 변수의 이름은 포함되어서는 안된다. 이후의 과정은 매우 쉽다. 대부분 총 네개의 데이터셋으로 분할이 되는데, X_train, y_train, X_test, y_test로 분할을 해주므로 각각에 해당되는 데이터 셋을 생성해주면 된다.
X_train=train[feature_names]
y_train=train[label_name]
X_test=test[feature_names]
y_test=test[label_name]물론 꿀팁으로는 각가의 데이터셋을 생성하고 shape를 이용하여 크기가 잘 맞는지 확인해주면 이후에 오류가 나지 않는 방지턱 역할을 해준다.
방법 2)
위의 경우에는 train과 test 데이터셋이 아예 분리가 되어있을 경우에 가능한 방법이다. 그렇지 않고 하나의 데이터 프레임속에서 train과 test데이터셋을 생성하고자 한다면 슬라이싱을 이용하여 데이터를 나눌 수 있다. 예를 들어서, 행이 총 1000개가 있는 데이터 프레임에서 800개의 행은 train으로 200개는 test로 이용하고자 하면,
split_c=df.shape[0]*0.8
train = df[:split_c]
test = df[split_c:]을 이용하면 된다는 것이다. 이후의 과정은 방법1에서 하는 방법을 그대로 이용해볼 수 있을 것이다.
방법 3)
사실 위의 방법들을 보면 한번에 직관적이긴 하지만 한번에 해결할 수는 없을까? 라는 의문이 든다. 물론 있다. sklearn을 속에 있는 train_test_split을 이용하면 된다. 사용법은 매우 간단하다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.2,
stratify=y,
random_state=42)위와 같이 수행하면 된다. 위의 코드를 보면 갑자기 X와 y가 튀어나오는 것을 확인해 볼 수 있는데, 겁먹지 않아도 된다. 이전에 만들었던 feature_names와 label_name을 그래도 가지고 오면 된다. 즉,
X=df[feature_names]
y=df[label_name]각 X와 y는 위와 같다는 것이다. test_size는 얼마나의 비율로 데이터를 나눌 것이냐를 의미하고 strtify = y는 계층적 데이터 추출 옵션을 의미한다.
머신러닝 알고리즘 가져오기
위에서 데이터를 분리하고 학습과 예측을 위한 데이터셋을 생성하는 방법들에 대해서 알아보았다. 이제 남은 것은 내가 만든 데이셋을 이용하여 머신러닝 알고리즘을 가져와 적용시키는 것인데, 사실 sklearn이 있어 이 과정은 매우 쉽다. 우선 결정트리에 대해 알아보고 있으므로 결정트리를 통해 알아보자!
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import DecisionTreeRegressor분류냐 회귀냐에 따라 내가 필요한 라이브러리를 불러온다. 이후 model이라는 변수에 모델을 선언한다. 편의를 위해 classifier을 통한 예제를 들도록하겠다.
model = DecisionTreeClassifier()이런식으로 모델을 가지고 오면 되는데 사실 이게 끝이 아니고, 이 모델 속에 정말 많은 파라미터들이 있다.
- min_samples_split: 노드를 분할하기 위한 최소한의 샘플 데이터 수로 과적합을 제어하는 데 사용된다.
- min_samples_leaf: 말단 노드(Leaf)가 되기 위한 최소한의 샘플 데이터 수
- max_features: 최적의 분할을 위해 고려할 최대 피처 개수, 디폴트는 None이고 데이터 세트의 모든 피처를 사용해 분할 수행한다
- max_depth: 트리의 최대 깊이를 규정한다.
- criterion='gini' 분할방법으로 "gini"와 "entropy"가 있고, 디폴트는 "gini"이다.
자주 쓰이는 파라미터들만 정리해보았다.
학습과 예측
모델을 설정해주었으니 이제 여기에 맞춰 우리가 셋팅해놓은 데이터셋을 학습시켜야 한다. 이건 사실 딱히 어려운것이 없다.
model.fit(X_train, y_train)을 이용하여 모델을 학습시키면 된다.
학습이 완료되면 X_test를 통해 정답을 예측해봐야 할 텐데, 이 또한 매우 간단하다.
y_predict = model.predict(X_test)위와 같이 수행하면 된다. 이러한 과정이 끝나면 y_predict 안에는 우리가 학습시킨 모델이 예측한 결과값들이 들어가게 된다.
결과 확인하기
정확도를 확인하기 전 의사결정 나무를 구축하였으니 어떤 나무 형태가 나왔는지를 확인해 볼 필요가 있다.
from sklearn.tree import plot_tree
plt.figure('''플롯의 크기도 조절가능''')
plot_tree(model, filled=True, fontsize=14, feature_names=feature_names)
plt.show()을 통해 나무 형태의 플롯을 확인해볼 수 있다. 최상위 노드부터 내가 설정한 깊이까지 확인을 할 수 있는데, 너무 깊게 그리면 전부 겹쳐 제대로 확인을 하기 어려우니 주의하자. 나무 플롯을 그리면 다음과 같은 여러 사각형들을 확인해볼 수 있다.
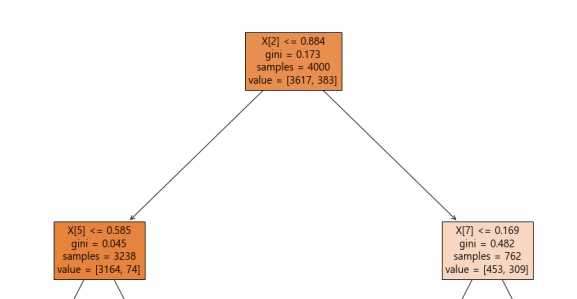
현재 이 이미지의 root 노드를 보면, 총 4000개의 샘플 중에서 X[2]라는 변수가 0.0884보다 작냐에 따라 3617개와 383개로 나뉘어 짐을 확인할 수 있다. True면 왼쪽으로 False면 오른쪽으로 내려가게 된다.
잎사귀 노드 다른 말로, 끝 노드를 살펴보면 다음과 같다.

가장 아래층 노드로써 어느 한쪽으로 샘플들이 전부 몰리게 되면 gini 계수가 0이 됨을 확인할 수 있고, 이는 즉 순수노드라고 할 수 있다. 여기서 유추할 수 있는 점은 지니 지수 는 불순도 측정 지수로서 얼마나 다양한 데이터가 잘 섞여있는지 정도를 나타낸다는 것이다. 그 비슷한 개념 중 하나인 엔트로피는 데이터가 섞여있는 정도 를 나타낸다.
y_test(정답지라고 생각하자!)와 맞춰보아 정확도가 얼마가 나왔는지를 확인해 볼 수 있다.
(y_test == y_predict).mean() * 100물론 이 또한 sklearn에는 한번에 해줄 수 있는 코드가 있다.
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)단순히 정확도만 파악하는 것이 아니라 어떤 변수가 어느정도의 영향력과 중요도를 가지고 있는지를 파악해보는 일은 중요하다.
위에서 처럼 모델을 잘 구현하였으면,
model.feature_importances_을 이용하여 변수들마다의 중요성을 확인해 볼 수 있을 것이다. 추천하는 방법은 바 형식의 그래프로 시각화 보는 것인데, 여러 방법들 중 하나는 다음과 같다.
sns.barplot(x=model.feature_importances_, y=feature_names)