앞서 DecsionTree에 대해 알아보았는데, 사실 DecisionTree에는 몇가지 단점들이 존재한다.
- 계층적 구조로 인해서 중간에 에러가 발생하면 다음 단계로 계속 전파된다.
- 학습 데이터에 미세한 변동도 크게 영향을 미친다.
- 노이즈에 민감하다
- 깊이를 깊게 하거나 노드 수를 늘리면 과적합 위험이 높다.
앙상블(Ensemble)
앙상블(Ensemble)은 이러한 단점을 보완하기 매우 좋다. 앙상블이란 여러 base 모델들에서 나온 예측을 다수결 혹은 평균을 통해서 통합하여 예측 정확성을 향상시키는 기법을 의미한다. 이러한 앙상블 학습 유형에는 대표적으로 세가지가 있다.
보팅(voting)
말 그대로 투표를 통해서 최종 예측 결과를 결정하는 방법이다. 보팅안에서도 하드보팅과 소프트 보팅으로 나뉘어 질 수 있는데 다수의 분류기가 예측한 결과값으 최종 결과로 선정하면 하드 보팅이고, 모든 분류기가 예측한 레이블 값의 결정 확률 평균을 구한 뒤 가장 확률이 높은 레이블 값을 최종 결과로 선정하면 소프트 보팅이라고 한다.
배깅(Bootstrap Aggregating, Bagging)
데이터 샘플링을 통해 여러개의 모델을 학습시키고 그 결과를 집계하는 방법을 의미한다. 각 모델은 서로 다른 학습 데이터셋을 이용하며, 데이터셋이 생성될 때는 복원 추출을 통해 원래 데이터의 개수만큼 샘플링하게 된다. 이때 이 개별 데이터 셋을 Bootstrap셋이라고 부른다.
부스팅(Boosting)
부스팅은 여러개의 분류기가 순차적으로 학습을 수행하게 되고 배깅과 다른 점은 이전에 시행된 모델의 정보를 통해 더 나음 방향으로 개선을 시켜나간다는 것이다. 즉, 가중치를 부여하면서 학습과 예측이 이루어지는 방식이다. 주로 예측 성능이 뛰어나서 앙상블 자주 쓰인다.
특징
앙상블의 몇가지 특징에 대해 더 적어보자면,
- Base 모델들이 서로 독립적
- Base 모델들이 무작위 예측을 수행하는 모델보다 성능이 좋은 경우
에 Base 모델보다 앙상블 모델이 더 우수한 성능을 보여준다.
또한, 의사결정나무모델은 앙상블 모델의 base 로써 활용도가 매우 높은데 그 이유는 다음과 같다.
- 데이터의 크기가 방대해도 모델을 빠르게 구축 가능하다.
- 데이터 분포에 대한 가정이 필요하지 않다.
랜덤포레스트란?
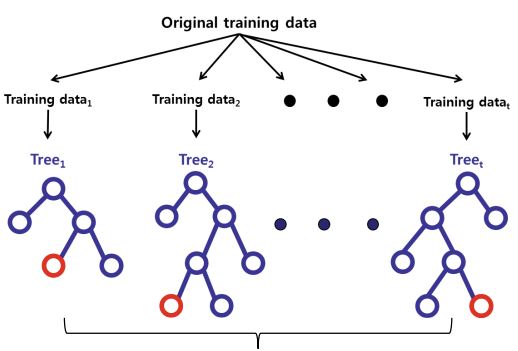
본격적으로 랜덤 포레스트에 대해서 알아보자면 랜덤포레스튼 다수의 의사결정나무모델을 통해 예측을 종합하는 앙상블 방법을 이용한다. 보통 단일 의사결정나무모델보다 높은 예측 정확성을 보여준다. 관측치 수에 비해서 변수가 많은 경우에 중요 변수 선택기법으로 널리 활용되기 도 한다.
즉, 다양성과 무작위성을 특징으로서 가지고 있다.
랜덤포레스트 모델이 진행되는 과정에 대해 요약하자면 다음과 같다.
- Bootstrap으로 다수의 training data 생성
- 생성된 데이터들로 모델 구축 (무작위 변수를 이용)
- 예측 종합
중요변수선택
위에서 잠깐 언급한 중요 변수 선택에 대해 조금 더 설명해보자면 랜덤 포레스튼 linear/logistic regression 모델과 다르게 개별 변수들이 통계적으로 얼마나 유의한지에 대한 정보를 제공하지 않는다. 그렇기 때문에 간접적인 방법으로 변수의 중요도를 결정하는 데 그 과정은 다음과 같다.
step 1. 원래 데이터 집합에 대해 Out of Bag Error(OOB) 구하기
step 2. 특정 변수의 값이 섞인 데이터 집합에 대한 OOB Error 구하기
step 3. 개별 변수의 중요도를 step2와 step1 OOB Error 차이의 평균과 분산을 고려하여 결정
코드와 파라미터
RandomForest를 파이썬 코드로 구축하는 방법은 DecisionTree를 구축할 때와 매우 유사하다.
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import RandomForestRegressor
model = RandomForestClassifier()
model = RandomForestRegressor()다음과 같이 머신러닝 알고리즘을 불러온다.
랜덤포레스트 속에도 역시나 여러 파라미터들이 존재하는데, 주요 파라미터 몇가지에 대해 정리하자면 다음과 같다.
- n_estimators : Decision tree의 수로 보통 Strong law of large numbers를 만족시키려면 2000개 이상의 트리가 필요하다고 한다.
- max_depth: 트리의 최대 깊이를 정한다.
- min_samples_split:내부 노드를 분할하는 데 필요한 최소 샘플 수로 과적합을 제어하는 데 사용한다. Default는 2이다.
- min_samples_leaf: 리프 노드거 되기 위해 필요한 최소한의 샘플 데이터 수로 이 또한 과적합 제어를 위해 쓰인다.
파라미터와 feature들을 잘 조정해가면서 최적의 모델을 찾아보는 방법은 많이 해보면서 경험해보는 수 밖에 없을 거 같다.
