데이터베이스 쿼리 성능을 분석할 때 실행계획(Execution Plan) 을 확인하면, DB가 어떻게 데이터를 읽는지 파악할 수 있다.
특히 인덱스를 어떻게 사용하는지에 따라 성능이 크게 달라진다.
📌 1. FULL TABLE SCAN
-
키워드 :
TABLE ACCESS FULL -
동작 : 테이블의 모든 행을 처음부터 끝까지 전부 읽음
SELECT * FROM INDEX_EX WHERE salary > 0;- 특징 : 인덱스가 없거나, 조건이 대부분의 데이터를 반환할 때
대용량 테이블에서 비효율적
📌 2. INDEX UNIQUE SCAN
-
키워드 :
INDEX UNIQUE SCAN -
동작 : 프라이머리 키(PK) 또는 유니크 인덱스를 사용해 정확히 1건을 빠르게 조회
SELECT * FROM INDEX_EX WHERE emp_id = 100;- 특징:유일한 값을 찾을 때 가장 빠름
효율 최고
📌 3. INDEX RANGE SCAN
- 키워드 :
INDEX RANGE SCAN
동작: 인덱스에서 특정 범위에 해당하는 값들을 순차적으로 스캔
SELECT * FROM INDEX_EX WHERE department_id BETWEEN 10 AND 20;- 특징 : 범위 조건, IN, LIKE 조건 등에 사용
흔히 등장하며 효율도 좋음
📌 4. INDEX FULL SCAN
-
키워드 :
INDEX FULL SCAN -
동작 : 인덱스를 처음부터 끝까지 순서대로 전체 스캔
SELECT department_id FROM INDEX_EX ORDER BY department_id;- 특징 : 정렬된 결과가 필요하거나, 인덱스만으로 데이터를 다 가져올 수 있을 때
ROWID 접근 없이 인덱스만으로 처리
📌 5. INDEX FAST FULL SCAN
-
키워드:
INDEX FAST FULL SCAN -
동작 : 인덱스를 병렬로 빠르게 읽음 (순서 X)
SELECT department_id FROM INDEX_EX;
(단, department_id 인덱스가 존재하고, 해당 컬럼만 조회할 때)- 특징 : 정렬이 필요 없고, 테이블 접근 없이 인덱스만으로 결과 가능할 때 사용
INDEX FULL SCAN과 비슷하지만 정렬은 보장하지 않음
✅ 요약 비교표
| 접근 방식 | 순서 보장 | 테이블 접근 (ROWID) | 효율성 | 주요 사용 상황 |
|---|---|---|---|---|
| FULL TABLE SCAN | ✗ | O | ❌ 낮음 | 인덱스 없음, 조건 무의미하거나 전체 조회 |
| INDEX UNIQUE SCAN | ✅ | O | ✅ 최고 | 프라이머리 키, 유니크 조건 (PK = 값) |
| INDEX RANGE SCAN | ✅ | O | 👍 좋음 | 범위 조건, BETWEEN, IN, LIKE 등 |
| INDEX FULL SCAN | ✅ | ✗ | 중간 | 정렬된 결과 필요, 인덱스만으로 처리 가능 |
| INDEX FAST FULL SCAN | ✗ | ✗ | 👍 좋음 | 정렬 불필요, 인덱스만으로 결과 처리 가능 |
🧪 실습 예제: 인덱스 생성 전후 실행 계획 비교
📌 1. 인덱스 예시 테이블 생성
CREATE TABLE INDEX_EX (
emp_id INT PRIMARY KEY,
emp_name VARCHAR(50),
department_id INT,
salary INT
);📌 2. 더미 데이터 삽입 (100,000건)
BEGIN
FOR i IN 1..100000 LOOP
INSERT INTO INDEX_EX (emp_id, emp_name, department_id, salary)
VALUES (
i,
'Employee_' || i,
MOD(i, 100), -- department_id 0~99 반복
TRUNC(DBMS_RANDOM.VALUE(3000, 9000))
);
END LOOP;
COMMIT;
END;📌 3. 인덱스 생성
CREATE INDEX idx_department_id ON INDEX_EX(department_id);
emp_id는 PRIMARY KEY이므로 자동으로 유니크 인덱스가 생성됨📌 4. 조건이 너무 많은 경우 → 인덱스 미사용
EXPLAIN PLAN FOR
SELECT * FROM INDEX_EX WHERE department_id = 42;
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);🔍 실행계획: TABLE ACCESS FULL INDEX_EX
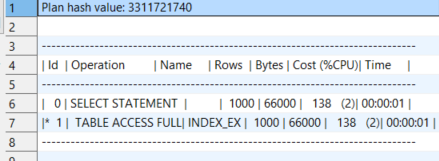
📌 해석: 조건이 많은 행을 반환할 경우 옵티마이저는 인덱스 사용보다 전체 스캔이 더 효율적이라 판단함
📌 5. 좁은 범위 조회로 인덱스 유도
EXPLAIN PLAN FOR
SELECT * FROM INDEX_EX WHERE emp_id >= 99 AND emp_id <= 199;
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);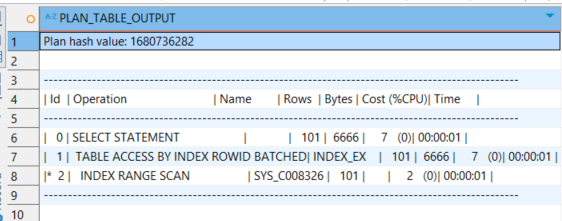
📌 해석
-
INDEX RANGE SCAN: emp_id 범위 조건에 따라 인덱스를 사용하여 101건을 추출
-
TABLE ACCESS BY INDEX ROWID BATCHED: 인덱스에서 가져온 ROWID를 통해 실데이터에 접근 (Batch 처리)
-
SYS_C008326: emp_id 프라이머리 키 인덱스 이름 (시스템 생성)
✅ 이처럼 범위 조건 + 프라이머리 키 인덱스 조합은 효율적인 INDEX RANGE SCAN을 유도할 수 있음
✅ 실행계획 비교 요약 (TABLE ACCESS FULL vs INDEX RANGE SCAN)
| 항목 | TABLE ACCESS FULL | INDEX RANGE SCAN + TABLE ACCESS BY ROWID |
|---|---|---|
| 접근 방식 | 테이블 전체를 처음부터 끝까지 스캔 | 인덱스를 통해 필요한 범위만 조회 |
| 사용 인덱스 | ❌ 인덱스 미사용 | ✅ 인덱스 사용 (프라이머리 키 or 일반 인덱스) |
| 예상 행 수 | 1000건 (전체) | 101건 (범위 내 일부) |
| Cost | 138 | 7 (2 + 5 정도로 분리됨) |
| CPU 사용량 | 높음 | 낮음 |
| Disk I/O | 높음 (모든 데이터 블록 접근) | 낮음 (필요한 블록만 접근) |
| 성능 | ❌ 느림 | ✅ 빠름 |
| 사용 시점 | 조건이 많은 데이터를 반환할 때 | 조건 범위가 좁고 선택도가 높을 때 |
✅ 실행계획 요약 정리 (실습 결과 기반)
| 조건 예시 | 실행 계획 | 설명 |
|---|---|---|
department_id = 42 | TABLE ACCESS FULL | 조건에 해당하는 행이 많아 전체 테이블 스캔 수행 |
emp_id = 99 | INDEX UNIQUE SCAN | 프라이머리 키 조건 → 유일값 조회, 유니크 인덱스 사용 |
emp_id BETWEEN 99 AND 199 | INDEX RANGE SCAN | 범위 조건 → 인덱스를 통한 순차 조회로 성능 최적화 |

초보 개발자의 기술 블로그