1. Database

사용자에게 트랜잭션 데이터를 저장하고 회수할 수 있게 해주는 기술
데이터 저장 오브젝트를 제공한다.- Table
- 단일 주제에 관해 행과 열로 구성되는 정보 모음
- View
- 데이터베이스 작업 시 기본 테이블에서 유도된 가상 테이블
- Schema
- 스키마(schema)는 데이터베이스에서 자료의 구조, 표현 방법, 자료 간의 관계를 형식 언어로 정의한 구조
- Table
- Contraints (제약)을 통해 테이블 간의 관계를 강화할 수 있는 수단을 갖추고 있다.
- SQL이라는 쿼리 언어를 제공한다.
- 함수나 축적 절차를 작성할 수 있는 절차적 능력을 제공한다.
- 이를 통해 비즈니스적 문제를 해결할 수 있다.
- 데이터베이스는 기술적으로 거래적 (Transactional)이다.
- 즉, 데이터의 업데이트를 취소할 경우, 데이터는 이전 상태로 돌아갈 수 있다.
- 데이터베이스는 저장소, 메모리 엔진, 처리 엔진이 포함된다.
- 처리 속도가 빠르다.
- 높은 수준의
무결성과가용성을 갖추고 있다.
- 다만, 데이터의 양이 매우 많아지면, 비용이 급격히 증가한다.
- 데이터 양이 많거나 빅데이터를 다룰 경우에 경제적이지 못하다.
2. Data Warehouse
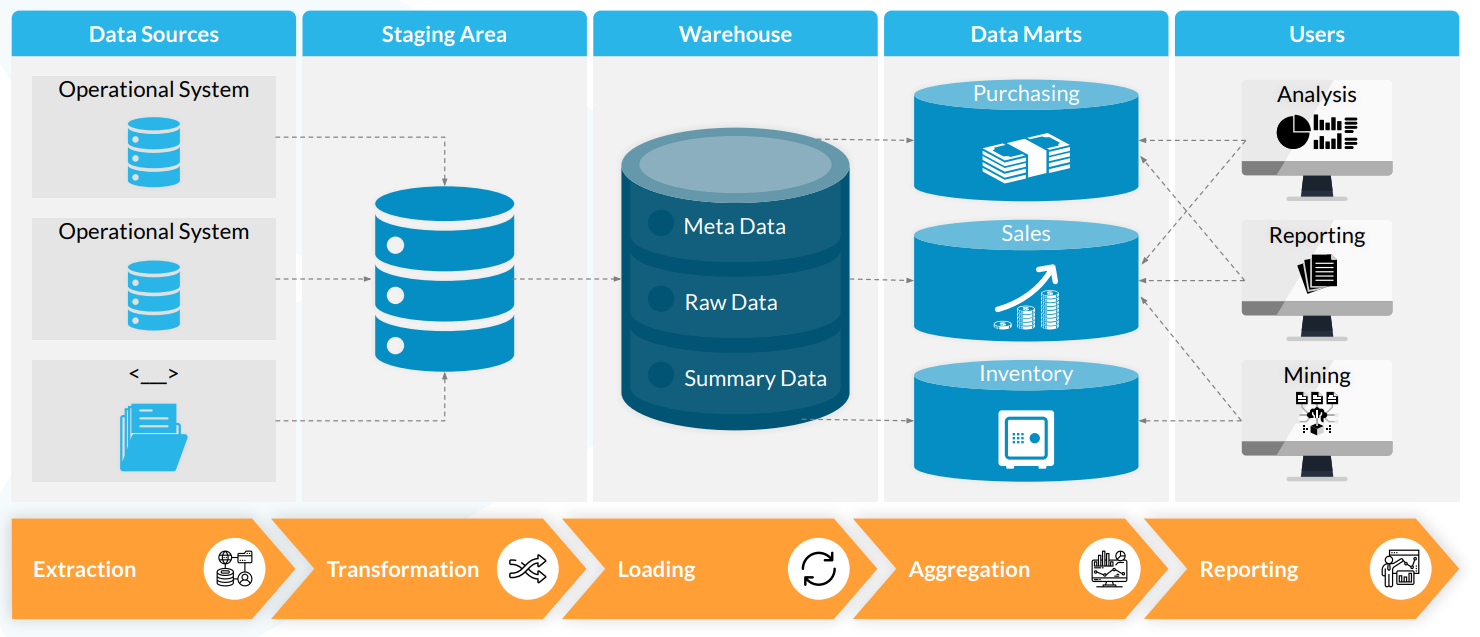
처리에 사용된 과거 데이터를 저장하는 기술이며,
그 데이터로부터 유의미하고 활용 가능한 지식을 추출한다.
- 다른 출처로부터 데이터를 가져오는 다양한 DB들은 데이터 웨어하우스에 로딩된다.
- 주기적인 백업 작업을 통해서,
- Loading 절차 : ETL
- Extract (추출)
- 다양한 출처로부터 데이터를 받아들인다.
- Transformation (변환)
- 비즈니스에 필요한 방식으로 데이터를 변형시킨다.
- Loading (적재)
- 이후, 보고 테이블에 입력되는 것
- Extract (추출)
- 종합 레이어 (Abbreviation Layer)
- 보고에 필요한 요건들에 맞게 최종적으로 여러 테이블을 생성한다.
- 해당 테이블을 통해서 데이터 분석가들이 분석 보고서를 작성한다.
- 보고에 필요한 요건들에 맞게 최종적으로 여러 테이블을 생성한다.
- 다만, 데이터의 양이 매우 많아지면, 비용이 급격히 증가한다.
- 데이터 양이 많거나 빅데이터를 다룰 경우에 경제적이지 못하다.
- 구조화되지 않은 데이터를 처리하지 못한다.
2.1 Data Mart
일부 회사들은 데이터를 부분 집합 으로 나누고 싶어 하는데,
이를 위해 여러 개의 데이터 마트로 나눈다.
이를 통해 **데이터에 대한 접근과 관리를 용이하게 한다
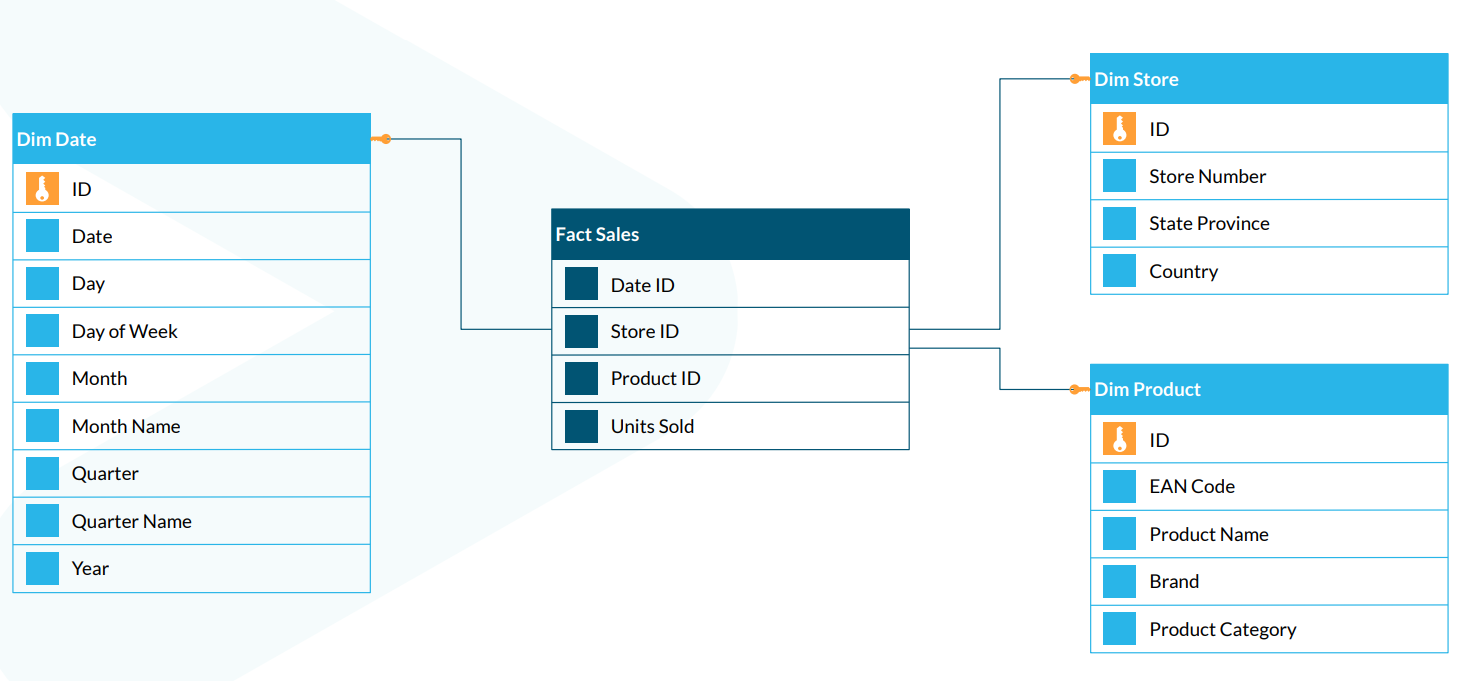
예시)
- Fact와 Dim 테이블로 나눠져 있다.
- Fact : 요약 테이블
- Dim : 주요 데이터와 일차 키 포함
3. Data Lake

등장 배경
기업들은 소비자의 마음을 읽고 그들의 수요를 파악하고자 한다. 따라서 클릭 동향이나 이벤트 데이터를 수집하고자 한다. 왜? 사용자들이 웹사이트 상에서 무엇을 원하는지를 이해하고 싶기 때문이다. 소비자가 어떤 부분을 사용하고 있고 사용자들이 어떤 기능을 가장 자주 이용하며 좋아하는지를 파악하고 싶은 것이다. 또한 IoT 데이터도 처리하고 싶기도 하다. 비디오, 이미지 파일을 처리하여 데이터를 추출하고 사용자에게 이용 경험을 제공하고자 한다.
그렇기 때문에 데이터는 복잡해지고 또한 백만, 억 단위를 넘어설 정도로 방대해진다.
또한 이 데이터는 CSV처럼 구조적 데이터일 수도 있다. 또는 JSON과 같이 반구조적 데이터일 수도 있다. 아니면 이미지 파일처럼 비구조적일 수도 있다.
그렇기에 이러한 데이터를 전통적인 방식의 데이터베이스에 저장하는 것은 막대한 비용을 발생시키고 기업 입장에선 현실적으로 감당하기 어려울 수 있다.
또한 이토록 막대한 데이터베이스로부터 데이터를 회수하는 것은 엔지니어에게 악몽과 같은 일이다.따라서, 새로운 분산형 파일 시스템이 등장하게 되었다.
- 처리는 MapReduce를 통해 이루어진다.
- MapReduce?
- 구글에서 대용량 데이터 처리를 분산 병렬 컴퓨팅에서 처리하기 위한 목적으로 제작하여 2004년 발표한 소프트웨어 프레임워크
- 간단하게 설명하자면, 한명이 4주 작업할 일을 4명이 나누어 1주일에 끝내는 것
- 이 개념이 하둡에서 사용하는 병렬 처리 개념이고, 4명의 작업자를 클러스터라고 합니다.
- MapReduce?
- 저장은 통상적인 기기들을 사용한다.
- 수평적으로 확장될 수 있다.
- 구조적, 반구조적, 비구조적 데이터까지 전부 한 곳에 유입될 수 있다.
- 예시
- HDFS
- Google Cloud Storage
- MS Azure Blob
- Amazon S3
- 다만, 데이터 레이크의 등장으로 모든 문제가 해결되지 않는다.
- 새로운 문제가 도출
- 방대한 양의 데이터를 더 저렴하게 저장할 수 있다는 점은 동의
- 이를 어떻게 회수할 것인가에 대한 문제
- 값비싼 연산력 또는 처리력 요구
- 충분히 속도가 빠른지
- 고도로 발전된 기술이 요구된다.
- Kafka, Spark, 데이터를 회수하기 위한 API
즉, 데이터 파이프라인을 개발하기 위해 고도로 숙련된 엔지니어들이 복잡한 코드를 작성해야 한다.
출처
The RED : Snowflake를 활용한 클라우드 데이터 엔지니어링
