
정렬
원소들을 순서대로 배열하는 것- 크기가 작은 순으로 정렬하기도 하고,
- 크기가 큰 순으로 정렬하기도 한다.
- 정렬은 그 자체로도 매우 중요한 주제이지만 알고리즘의 설계와 분석, 생각하는 방법 등을 훈련하기에 좋은 구성 요소를 많이 갖고 있다.
정렬의 종류
기본 정렬- 선택 정렬
- 버블 정렬
- 삽입 정렬
고급 정렬- 병합 정렬
- 퀵 정렬
- 힙 정렬
- 셸 정렬
특수 정렬- 계수 정렬
- 기수 정렬
- 버킷 정렬
기본 정렬
선택 정렬
알고리즘
selectionSort(A[], n): for last <- n-1 downto 1 A[0...last] 중 가장 큰 수 A[k]를 찾는다. A[k] <-> A[last]
설명
1. 리스트에서 가장 큰 수를 찾는다.
2. 가장 큰 수를 맨 오른쪽 수와 자리를 바꾼다.
3. 맨 오른쪽 수를 제외한 나머지에서 가장 큰 수를 찾는다.
4. 3번에서 찾은 수를 맨 오른쪽에서 두번째 수와 자리를 바꾼다.
5. 계속 반복
수행 시간- 모든 경우에 Θ(n²)
버블 정렬
알고리즘
bubbleSort(A[], n): for last <- n-1 downto 1 for i <- to last-1 if (A[i] > A[i+1]) A[i] <-> A[i+1]
설명

수행 시간- 최악의 경우에 Θ(n²)
- 최선이 경우에 Θ(n)
삽입 정렬
알고리즘
insertionSort(A[], n): for i <- 1 to n-1 A[0...i]의 적합한 자리에 A[i]를 삽입한다.
설명

- 선택 정렬과 버블 정렬과 정반대로 착상한 정렬
수행 시간- 최악의 경우에 Θ(n²)
- 리스트가 거의 정렬된 상태로 입력된다면 가장 매력적인 알고리즘
고급 정렬
병합 정렬
알고리즘
mergeSort(A[], p, r): if (p < r) q <- |(p+r)/2| mergeSort(A, p, q) mergeSort(A, q+1, r) merge(A, p, q, r) merge(A[], p, q, r): 정렬된 두 리스트 A[p...q]와 A[q+1...r]을 합쳐 정렬된 하나의 리스트 A[p...r]을 만든다. i <- p; j <- q+1; t <- 0 while (i <= q and j <= r) if (A[i] <= A[j]) tmp[t++] <-A[i++] else tmp[t++] <- A[j++] while (i <= q) tmp[t++] <- A[i++] while (j <= r) tmp[t++] <- A[j++] i <- p; t <- 0 while (i <= r) A[i++] <- tmp[t++]
설명
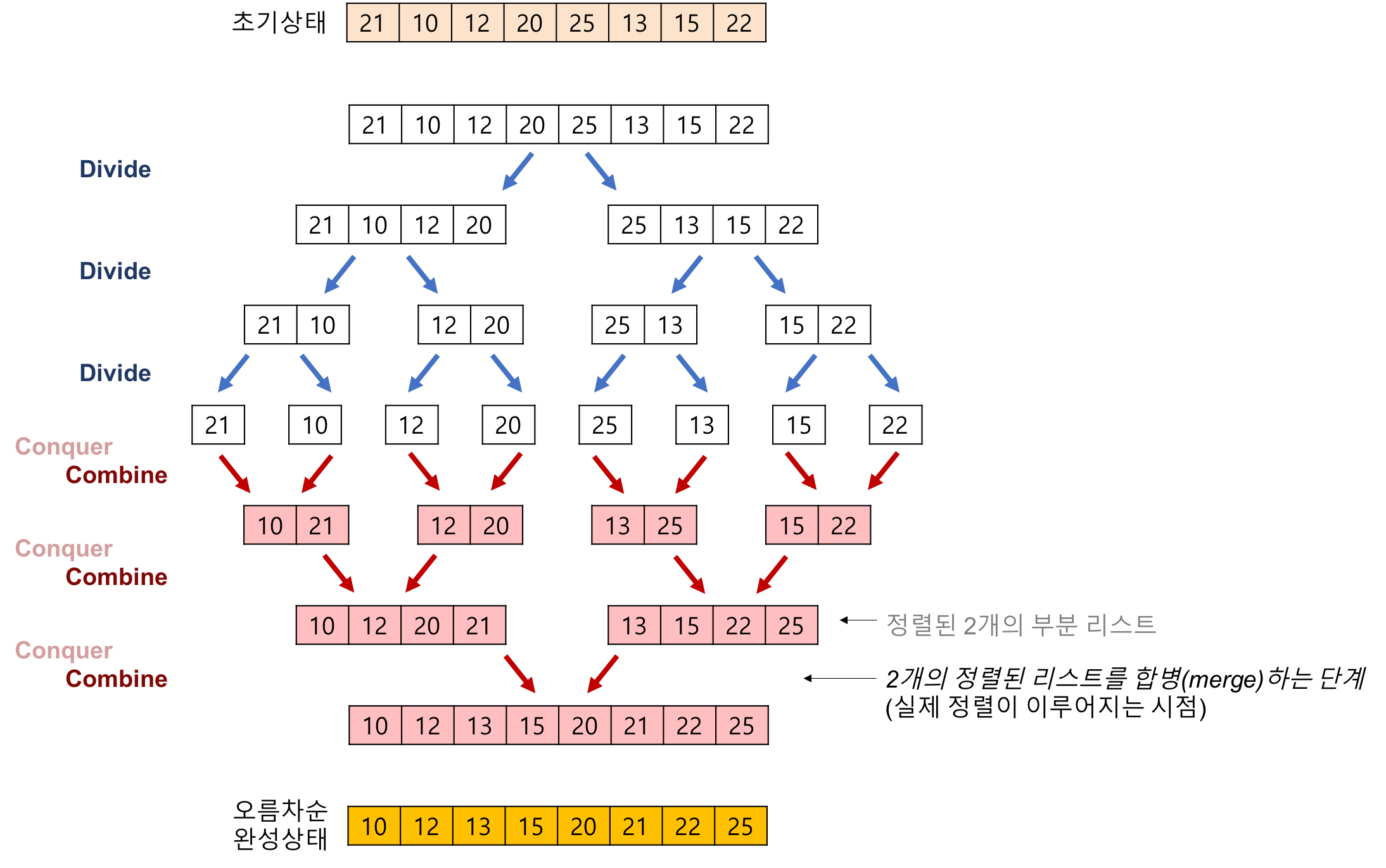
수행 시간- 모든 경우에 Θ(nlogn)
약점- 이론적으로 완벽한 Θ(nlogn)을 보장하지만 병합과정에서 보조 리스트 tmp[]가 필요하다.
- 이로 인한 시간적, 공간적 낭비가 발생한다.
퀵 정렬
알고리즘
quickSort(A[], p, r): if (p < r) q <- partition(A, p, r) quickSort(A, p, q-1) quickSort(A, q+1, r) partition(A[], p, r): 리스트 A[p...r]의 원소들을 기준 원소인 A[r]과의 상대적 크기에 따라 양쪽으로 재배치하고, 기준 원소가 자리한 위치를 리턴한다. x <- A[r] i <- p-1 for j <- p to r-1 if (A[j] < x) A[++i] <-> A[j] A[i+1] <-> A[r] return i+1
설명

- 병합 정렬이 먼저 재귀적으로 작은 문제를 해결한 다음 후처리를 하는 데 반해, 퀵 정렬은 선행 작업을 한 다음 재귀적으로 작은 문제를 해결하면서 바로 끝난다.
수행 시간- 평균 Θ(nlogn)
- 최악의 경우 Θ(n²)
아주 나쁠 경우- 입력이
이미 정렬되어 있거나거의 정렬되어 있는 경우에만 일어난다. - 역순으로 정렬되어 있을 때도 마찬가지다.
분할에서 항상 최악의 경우이다.- 또한
동일한 원소가 많이 존재하는 경우
- 입력이
힙 정렬
알고리즘
heapSort(): buildHeap() for i <- n-1 downto 1 A[i] <- deleteMax()
설명
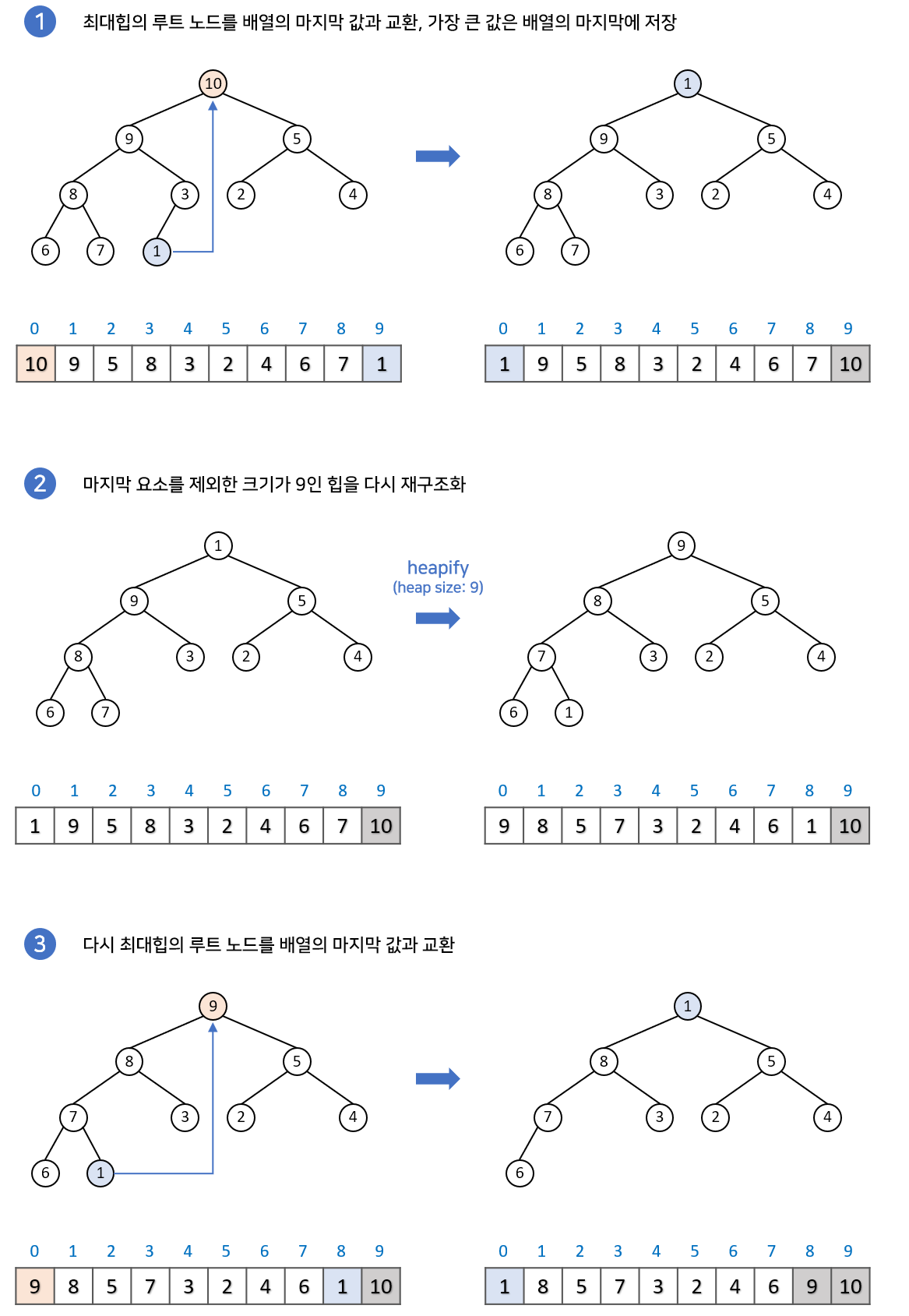
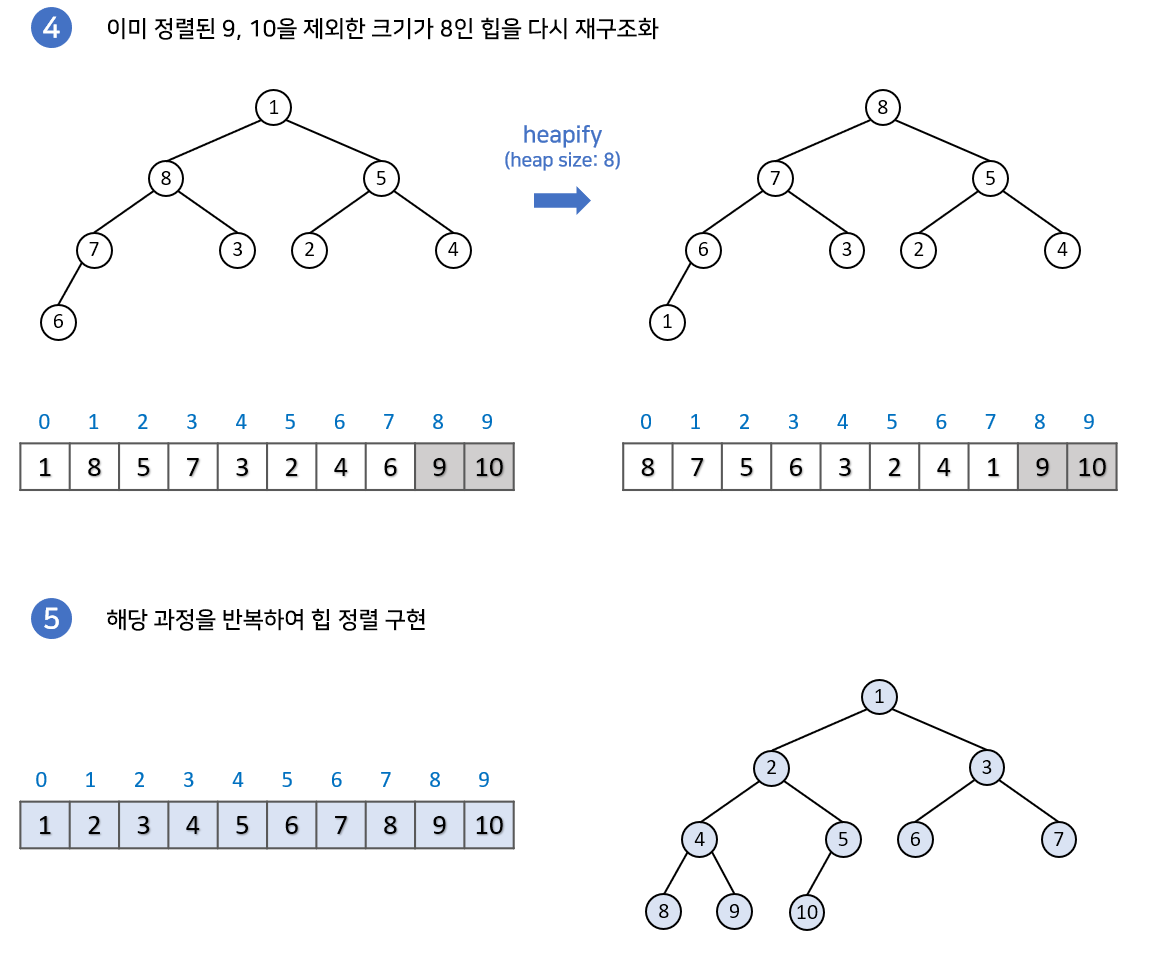
수행 시간- 평균 O(nlogn)
- 최악의 경우 Θ(nlogn)
- 가장 운이 좋은 경우 : 모든 원소가 동일한 경우 : Θ(n)
셸 정렬
알고리즘
shellSort(A[]): for h <- h₀, h₁, ..., 1 for k <- 0 to h-1 stepInsertionSort(A, k, h) stepInsertionSort(A[], k, h): for (i <- k+h; i <= n-1; i <- i+h) newItem <- A[i] for (j <- i - h; 0 <= j and newItem < A[j]; j <- j - h) A[j+h] <- A[j] A[j+h] <- newItem
설명
- 삽입 정렬을 개선한 것
데이터 특성을 잘 이용한 정렬
평균 또는 최악의 경우 Θ(n) 시간이 드는 정렬 알고리즘은 없는가?
계수 정렬
알고리즘
countingSort(A[], n): for i <- 0 to k C[i] <- 0 for j <- 0 to n-1 C[A[j]]++ for i <- 1 to k C[i] <- C[i] + C[i-1] for j <- n-1 downto 0 B[C[A[j]]-1] <- A[j] C[A[j]]-- return B
설명

-O(n) ~ O(n)의 범위에 있는 정수인 경우에 사용할 수 있다.
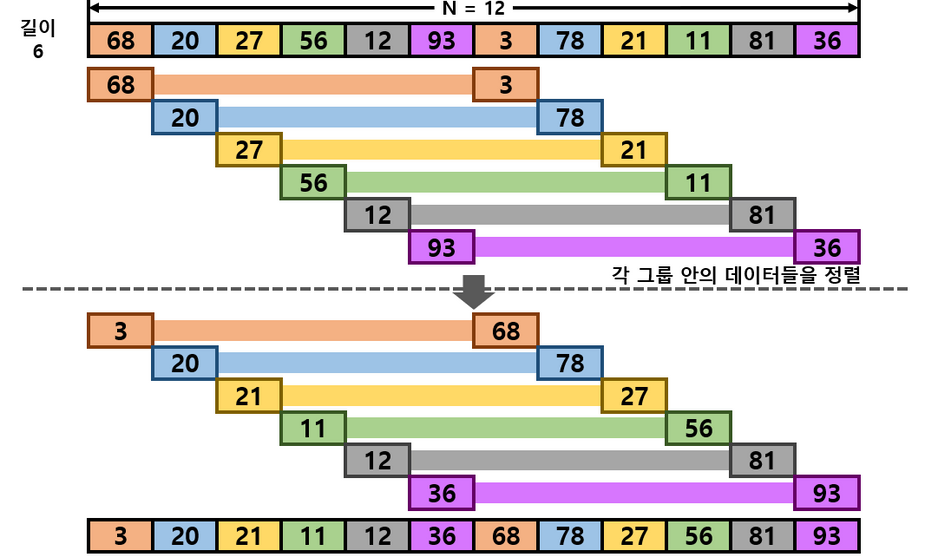
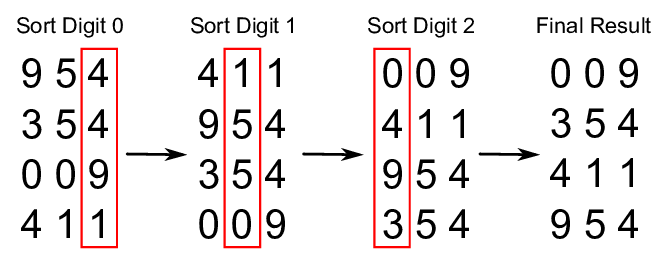
기수 정렬
알고리즘
radixSort(A[], n, k): 원소들이 최대 k 자리수인 A[0...n-1]을 정렬한다 가장 낮은 자리수를 1번째 자릿수라 하자 for i <- 1 to k i번째 자릿수에 대해 A[0...n-1]을 안정성을 유지하면서 정렬한다.
설명
버킷 정렬
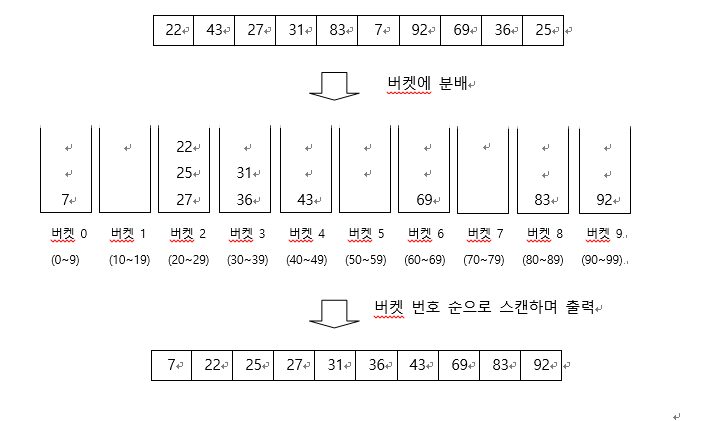
알고리즘
bucketSort(A[], n): A[0...n-1] : [0, 1) 범위의 균등 분포를 한 실숫값 리스트 for i <- 0 to n-1 A[i]를 리스트 B[n*A[i]]에 삽입한다. (B[0...n-1]: 각각이 리스트인 리스트) for i <- 0 to n-1 리스트 B[i]에 있는 원소들을 정렬 B[0], B[1], ... B[n-1]의 원소들을 차례대로 A[0...n-1]로 복사한다.
설명
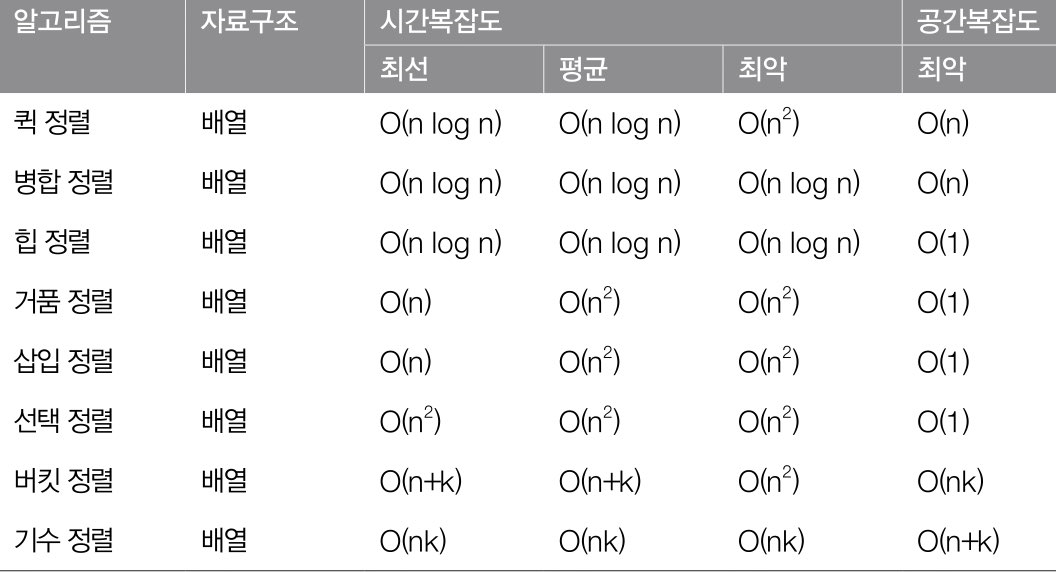
성능 비교
Code
이미지 출처

클라우드, 데이터, DevOps 엔지니어 지향 || 글보단 사진 지향