DDRNet 가중치 조절
DDRNet 가중치 조절
환경 구성.
중요 환경에 대한 버전.
Package Version
------------------- --------------------
numpy 1.24.1
opencv-python 4.12.0.88
thop 0.1.1.post2209072238
torch 2.3.1+cu118
torchaudio 2.3.1+cu118
torchvision 0.18.1+cu118진행 작업
- 폴더별 가중치 조절 코드 추가.
- 클래스별 가중치 조절 코드 추가.
- 기초 데이터 증식 코드 추가.
class SegmentationTransform:
def __init__(self, crop_size=[1024, 1024], scale_range=[0.5, 1.5]):
self.crop_size = crop_size
self.scale_range = scale_range
self.mean = [0.485, 0.456, 0.406]
self.std = [0.229, 0.224, 0.225]
self.bilinear = transforms.InterpolationMode.BILINEAR
self.nearest = transforms.InterpolationMode.NEAREST
# Color Jitter
self.color_jitter = transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.3, hue=0.1)
# Gaussian Blur
self.gaussian_blur = transforms.GaussianBlur(kernel_size=(5, 9), sigma=(0.1, 5))
def __call__(self, image, label):
scale_factor = random.uniform(self.scale_range[0], self.scale_range[1])
width, height = image.size
new_width, new_height = int(width * scale_factor), int(height * scale_factor)
image = TF.resize(image, (new_height, new_width), interpolation=self.bilinear)
label = TF.resize(label, (new_height, new_width), interpolation=self.nearest)
pad_h = max(self.crop_size[0] - new_height, 0)
pad_w = max(self.crop_size[1] - new_width, 0)
if pad_h > 0 or pad_w > 0:
padding = (0, 0, pad_w, pad_h)
image = TF.pad(image, padding, fill=0)
label = TF.pad(label, padding, fill=255)
# 크롭
i, j, h, w = transforms.RandomCrop.get_params(image, output_size=self.crop_size)
image = TF.crop(image, i, j, h, w)
label = TF.crop(label, i, j, h, w)
# 좌우 반전
if random.random() > 0.3:
image = TF.hflip(image)
label = TF.hflip(label)
# 회전
if random.random() > 0.5:
angle = random.uniform(-5, 5)
image = TF.rotate(image, angle, interpolation=self.bilinear, fill=0)
label = TF.rotate(label, angle, interpolation=self.nearest, fill=255)
# 색상 변환
if random.random() > 0.4:
image = self.color_jitter(image)
if random.random() > 0.3:
image = self.gaussian_blur(image)
image = TF.to_tensor(image)
image = TF.normalize(image, mean=self.mean, std=self.std)
label = torch.from_numpy(np.array(label, dtype=np.uint8)).long()train.py
import os
import argparse
import torch
from torch.utils.data import DataLoader, WeightedRandomSampler
from tqdm import tqdm
from collections import OrderedDict
import json
from pathlib import Path
from DDRNet import DDRNet
from functions import *
def arg_as_dict(s):
try:
return json.loads(s)
except Exception as e:
raise argparse.ArgumentTypeError(f"Argument must be a JSON-formatted dictionary string. Error: {e}")
def train_and_validate(args):
device = torch.device(f"cuda:{args.gpu_id}" if torch.cuda.is_available() else "cpu")
print(f"Initialized training on device: {device}")
# 데이터셋 폴더별 가중치를 위한 설정
train_sub_folders = ['cam0', 'cam1', 'cam2', 'cam3', 'cam4', 'cam5', 'set1', 'set2', 'set3']
val_sub_folders = ['cam0', 'cam1', 'cam2', 'cam3', 'cam4', 'cam5', 'set1', 'set2', 'set3']
train_dataset = SegmentationDataset(args.dataset_dir, args.crop_size, 'train', args.scale_range, sub_folders=train_sub_folders)
# --- 폴더별 가중치에 따른 샘플링 확률 계산 ---
if args.folder_weights:
print("Applying folder-wise weights for sampling...")
folder_indices = [sample[1] for sample in train_dataset.samples]
folder_names_per_sample = [train_sub_folders[i] for i in folder_indices]
sample_weights = [args.folder_weights.get(name, 1.0) for name in folder_names_per_sample]
print(f"Sample weights will be based on folder weights: {args.folder_weights}")
sampler = WeightedRandomSampler(weights=sample_weights, num_samples=len(sample_weights), replacement=True)
shuffle = False
else:
sampler = None
shuffle = True
val_dataset = SegmentationDataset(args.dataset_dir, args.crop_size, 'val', args.scale_range, sub_folders=val_sub_folders)
train_dataloader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=shuffle, sampler=sampler, num_workers=args.num_workers, pin_memory=True, drop_last=True)
val_dataloader = DataLoader(val_dataset, batch_size=args.batch_size, shuffle=False, num_workers=args.num_workers, pin_memory=True)
model = DDRNet(num_classes=args.num_classes).to(device)
class_weights = None
if args.class_weights:
if len(args.class_weights) != args.num_classes:
raise ValueError(f"Number of class_weights ({len(args.class_weights)}) must match num_classes ({args.num_classes})")
print(f"Applying class weights: {args.class_weights}")
class_weights = torch.tensor(args.class_weights, dtype=torch.float).to(device)
if args.use_ohem:
print("Using OhemCrossEntropy Loss.")
criterion = OhemCrossEntropy(ignore_label=255, weight=class_weights)
else:
print("Using standard CrossEntropy Loss.")
criterion = CrossEntropy(ignore_label=255, weight=class_weights)
optimizer = torch.optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay)
scheduler = WarmupPolyEpochLR(optimizer, total_epochs=args.epochs, warmup_epochs=args.warmup_epochs)
start_epoch = 0
min_val_loss = float('inf')
if args.loadpath:
print(f"Loading checkpoint from: {args.loadpath}")
checkpoint = torch.load(args.loadpath, map_location=device)
try:
# DDP 학습 가중치('module.' 접두사) 호환을 위한 처리
new_state_dict = OrderedDict()
for k, v in checkpoint['model_state_dict'].items():
name = k[7:] if k.startswith('module.') else k
new_state_dict[name] = v
model.load_state_dict(new_state_dict, strict=False)
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
scheduler.load_state_dict(checkpoint['scheduler_state_dict'])
start_epoch = checkpoint['epoch'] + 1
min_val_loss = checkpoint.get('loss', float('inf'))
print(f"Resuming training from epoch {start_epoch}, with min_val_loss: {min_val_loss:.4f}")
except KeyError:
print("Old checkpoint format. Loading model state_dict only.")
load_state_dict(model, checkpoint)
os.makedirs(args.result_dir, exist_ok=True)
log_path = os.path.join(args.result_dir, "log.txt")
with open(log_path, 'a' if start_epoch > 0 else 'w') as f:
if start_epoch == 0:
f.write("Epoch\t\tTrain-loss\t\tVal-loss\t\tlearningRate\n")
for epoch in range(start_epoch, args.epochs):
model.train()
total_train_loss = 0.0
loop = tqdm(train_dataloader, desc=f"Train [{epoch+1}/{args.epochs}]", ncols=100)
for i, (imgs, labels) in enumerate(loop):
optimizer.zero_grad(set_to_none=True)
imgs, labels = imgs.to(device), labels.to(device)
outputs = model(imgs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_train_loss += loss.item()
loop.set_postfix(loss=loss.item(), avg_loss=total_train_loss/(i+1), lr=scheduler.get_last_lr()[0])
avg_train_loss = total_train_loss / len(train_dataloader)
scheduler.step()
avg_val_loss_str = "N/A"
if (epoch + 1) % 5 == 0 or (epoch + 1) == args.epochs:
model.eval()
total_val_loss = 0.0
with torch.no_grad():
loop_val = tqdm(val_dataloader, desc=f"Val [{epoch+1}/{args.epochs}]", ncols=100)
for imgs, labels in loop_val:
imgs, labels = imgs.to(device), labels.to(device)
outputs = model(imgs)
loss = criterion(outputs, labels)
total_val_loss += loss.item()
avg_val_loss = total_val_loss / len(val_dataloader)
avg_val_loss_str = f"{avg_val_loss:.4f}"
print(f"\nEpoch {epoch+1}: Train Loss = {avg_train_loss:.4f}, Validation Loss = {avg_val_loss:.4f}")
if avg_val_loss < min_val_loss:
min_val_loss = avg_val_loss
best_path = os.path.join(args.result_dir, "model_best.pth")
torch.save({'model_state_dict': model.state_dict()}, best_path)
print(f"Best model saved at epoch {epoch+1} with val loss {min_val_loss:.4f}")
lr = scheduler.get_last_lr()[0]
with open(log_path, "a") as f:
f.write(f"\n{epoch + 1}\t\t{avg_train_loss:.4f}\t\t{avg_val_loss_str}\t\t{lr:.8f}")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="DDRNet Weighted Training Script")
parser.add_argument("--dataset_dir", type=str, default="./data")
parser.add_argument("--result_dir", type=str, default="output")
parser.add_argument("--loadpath", type=str, default=None)
parser.add_argument("--epochs", type=int, default=400)
parser.add_argument("--num_classes", type=int, default=19)
parser.add_argument("--gpu_id", type=int, default=0)
parser.add_argument("--lr", type=float, default=1e-2)
parser.add_argument("--batch_size", type=int, default=8)
parser.add_argument("--momentum", type=float, default=0.9)
parser.add_argument("--weight_decay", type=float, default=5e-4)
parser.add_argument("--warmup_epochs", type=int, default=5)
parser.add_argument("--crop_size", default=[512, 1024], type=arg_as_list)
parser.add_argument("--scale_range", default=[0.75, 1.5], type=arg_as_list)
parser.add_argument("--num_workers", type=int, default=os.cpu_count())
# 폴더 가중치 조절. (1.0이 기본 가중치)
parser.add_argument("--folder_weights", type=arg_as_dict, default={"cam0":1.0, "cam1":1.0, "cam2":1.0, "cam3":0.8, "cam4":1.0, "cam5":1.0, "set1":1.5, "set2":1.8, "set3":1.5},
help='{"cam0": 1.0, "set1": 2.0}')
# 클래스 가중치 조절 (1.0이 기본 가중치로 픽셀 수에 따라서 조절.)
parser.add_argument("--class_weights", type=arg_as_list, default=[2.0166, 3.481, 4.0911, 3.9912, 3.9619, 2.0864, 1.8396, 4.3168, 3.79, 6.4674, 5.7661, 5.642, 8.4116, 5.9525, 2.2137, 5.2137, 6.1661, 4.195, 1.0],
help='List of weights for each class. "[1.0, 1.5, 0.8]"')
parser.add_argument("--use_ohem", action='store_true', help="Use OHEM Cross Entropy loss")
args = parser.parse_args()
result_dir = Path(args.result_dir)
result_dir.mkdir(parents=True, exist_ok=True)
train_and_validate(args)
# 학습 시작 명령어 기본.
python train.py \
--dataset_dir "./data" \
--result_dir "./output_001" \
--loadpath "./DDRNet23s_cityscape.pth" \
--epochs 300 \
--batch_size 16 \
--lr 1e-2 \
--folder_weights '{"cam0":1.0, "cam1":1.0, "cam2":1.0, "cam3":1.0, "cam4":1.0, "cam5":1.0, "set1":1.5, "set2":1.5, "set3":1.5}' \
--class_weights '[0.5, 1.0, 1.0, 1.0, 1.0, 1.5, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]' \
--use_ohem
학습 실행 최종 명령어.
python train_weight.py --loadpath ./output/model_best.pth --epoch 300 --batch_size 16
학습 loss값이 일정해지는 수준까지 학습 진행을 예측하고 300Epoch까지 진행.
추가 학습을 진행하였으나 loss값이 정체되어 정지.
학습 결과
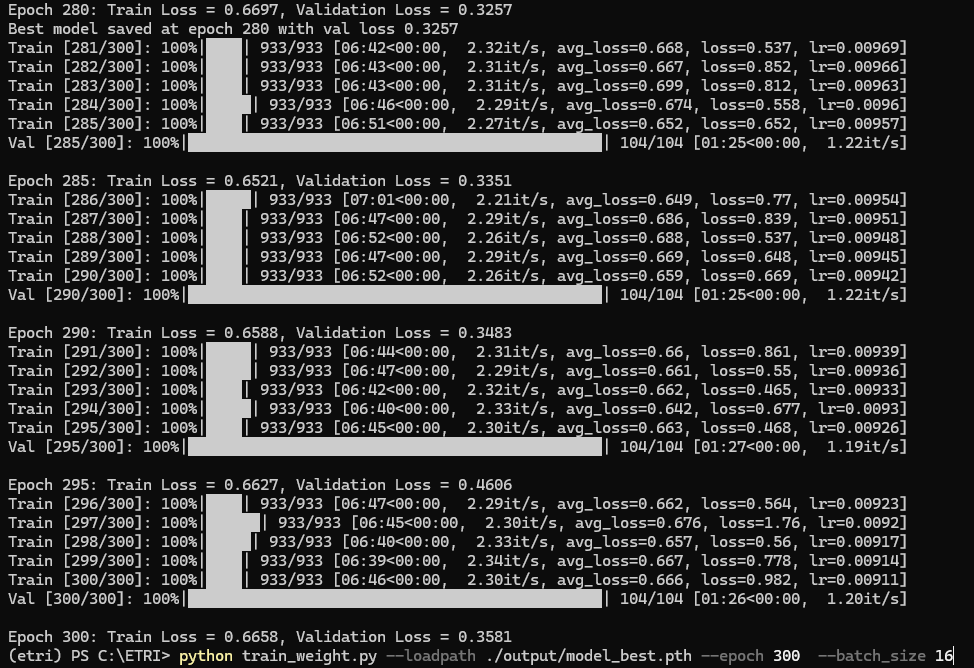
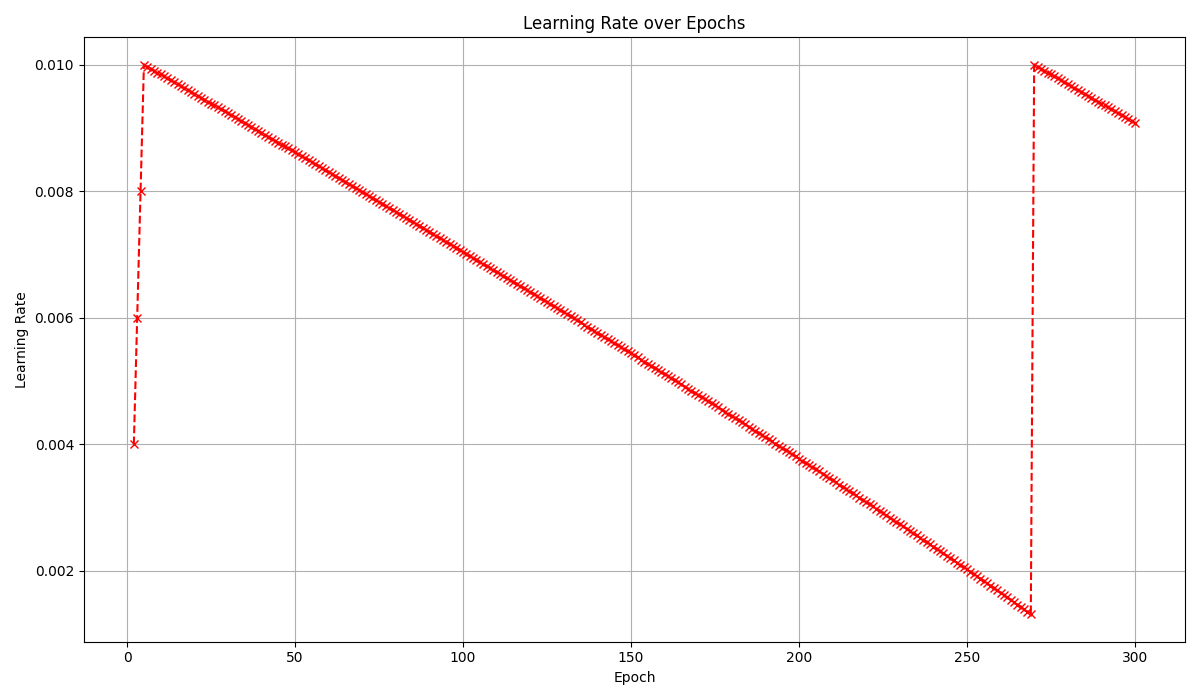
학습이 중간에 끊겨서 다시 시작하는 과정에서 LR값이 초기화
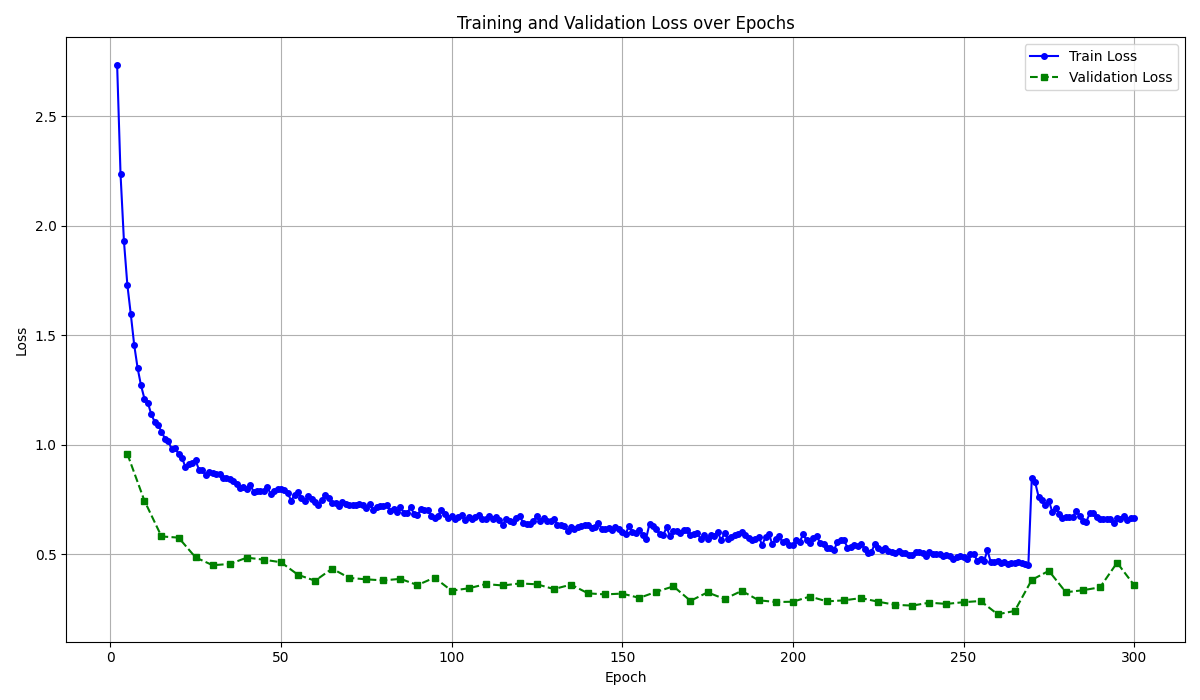
학습이 끊기며 LR값이 초기화 되는 과정에서 잠시 loss값에 변동이 존재.
test dataset predict 결과
 |  |
|---|---|
 |  |
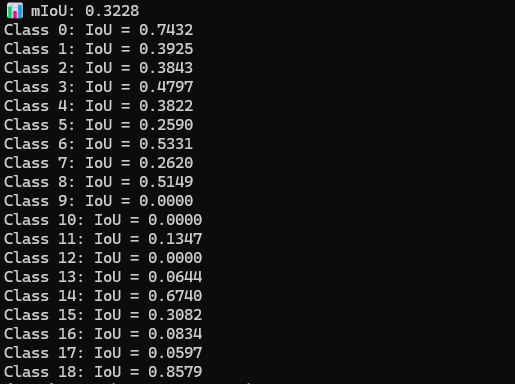
mIoU값 계산.
 클래스가 없는 경우를 포함하였을 때 클래스가 없는 경우를 포함하였을 때 | 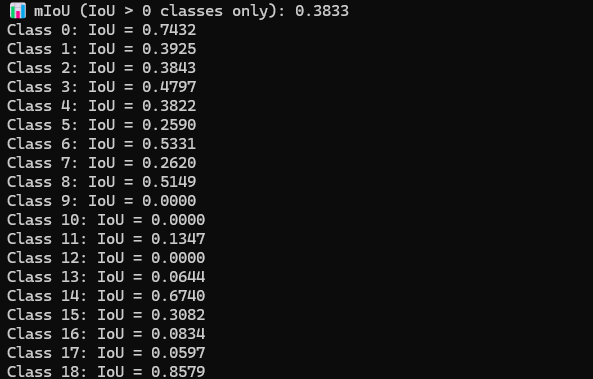 클래스가 없는 경우를 제외하였을 때 클래스가 없는 경우를 제외하였을 때 |
|---|
| 클래스 | IoU | 증감 |
|---|---|---|
| 0(주행가능영역) | 0.6299 | ▼ |
| 1(인도) | 0.4093 | ▼ |
| 2(도로노면표시) | 0.2963 | ▼ |
| 3(차선) | 0.4273 | ▼ |
| 4(연석) | 0.3830 | ◆ |
| 5(벽,울타리) | 0.2677 | ▲ |
| 6(승용차) | 0.5337 | ◆ |
| 7(트럭) | 0.3242 | ▲ |
| 8(버스) | 0.5340 | ▲ |
| 9(바이크, 자전거) | 0.0747 | ▲ |
| 10(기타 차량) | N/A | ◆ |
| 11(보행자) | 0.3924 | ▲ |
| 12(라이더) | N/A | ◆ |
| 13(교통용 콘 및 봉) | 0.1015 | ▲ |
| 14(기타 수직 물체) | 0.6785 | ◆ |
| 15(건물) | 0.4426 | ▲ |
| 16(교통 표지) | 0.2713 | ▲ |
| 17(교통 신호) | 0.1287 | ▲ |
| 18 (기타) | 0.7875 | ▼ |
픽셀 수가 낮은 데이터들은 확실히 데이터가 증가함. (0.1 단위로 증가한 값들도 존재)
픽셀 수가 다수인 0, 2, 3, 18번 같은 경우에는 정확도가 감소하는 현상 발견.
클래스와 폴더의 가중치를 동시에 준 결과로 클래스와 폴더의 가중치 값들이 각각 어느정도 IoU값에 영향을 주는지 확인이 필요.
inference time

모델 구조에 대해서 현재 환경에 약 9.3ms소요
결과 종합
모델명: DDRNet
데이터셋 : 제공된 데이터셋 7 : 2 : 1로 분할시켜 학습 및 테스트 진행
import os
import shutil
from pathlib import Path
def split_dataset(base_dir):
main_folders = ['colormap', 'image', 'labelmap']
source_base_path = Path(base_dir) / 'image' / 'train'
if not source_base_path.exists():
return
# train 폴더 내의 하위 폴더들(cam0, cam1, set1 등) 목록 가져오기
try:
sub_folders = [d.name for d in source_base_path.iterdir() if d.is_dir()]
except OSError as e:
print(f"문제가 발생했습니다")
return
print("데이터셋 분할을 시작")
for sub_folder in sub_folders:
print(f"\n📁 [{sub_folder}] 폴더 처리 중...")
source_sub_folder_path = source_base_path / sub_folder
try:
files = sorted([f.name for f in source_sub_folder_path.iterdir() if f.is_file()])
except FileNotFoundError:
print(f" '{source_sub_folder_path}' 폴더를 찾을 수 없습니다..")
continue
if not files:
print(f" '{sub_folder}' 폴더에 파일이 없습니다.")
continue
for main_folder in main_folders:
for split_type in ['train', 'val', 'test']:
dest_path = Path(base_dir) / main_folder / split_type / sub_folder
dest_path.mkdir(parents=True, exist_ok=True)
moved_counts = {'train': 0, 'val': 0, 'test': 0}
for i in range(0, len(files), 10):
chunk = files[i:i+10]
# 10개 미만이면 train으로 이동
if len(chunk) < 10:
split_map = {'train': chunk}
# 10개이면 7:2:1로 분할
else:
split_map = {
'train': chunk[0:7],
'val': chunk[7:9],
'test': chunk[9:10]
}
for split_type, files_to_move in split_map.items():
if not files_to_move:
continue
for file_name in files_to_move:
moved_counts[split_type] += 1
for main_folder in main_folders:
source_file = Path(base_dir) / main_folder / 'train' / sub_folder / file_name
dest_file = Path(base_dir) / main_folder / split_type / sub_folder / file_name
if source_file.exists():
shutil.move(str(source_file), str(dest_file))
print(f" - ✅ Train: {moved_counts['train']}개 파일 이동 완료")
print(f" - ✅ Validation: {moved_counts['val']}개 파일 이동 완료")
print(f" - ✅ Test: {moved_counts['test']}개 파일 이동 완료")
if __name__ == '__main__':
base_directory = 'C:/etri/data'
split_dataset(base_directory)테스트 코드
prediction
import os
import argparse
from glob import glob
from PIL import Image
import numpy as np
from tqdm import tqdm
import torch
import torch.nn.functional as F
from torchvision import transforms
from DDRNet import DDRNet
from torch.utils.data import Dataset, DataLoader
import matplotlib.cm as cm
from collections import OrderedDict
class TestSegmentationDataset(Dataset):
def __init__(self, root_dir, subset='test'):
self.image_dir = os.path.join(root_dir, "image", subset)
self.image_paths = sorted(glob(os.path.join(self.image_dir, "*", "*.*"), recursive=True))
self.to_tensor = transforms.ToTensor()
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
img_path = self.image_paths[idx]
img = Image.open(img_path).convert("RGB")
tensor = self.to_tensor(img)
return tensor, img_path
# 단일 GPU
def load_model(weight_path, num_classes, device):
model = DDRNet(num_classes=num_classes)
checkpoint = torch.load(weight_path, map_location=device)
if 'model_state_dict' in checkpoint:
state_dict = checkpoint['model_state_dict']
else:
state_dict = checkpoint
new_state_dict = OrderedDict()
for k, v in state_dict.items():
name = k[7:] if k.startswith('module.') else k # 'module.' 접두사를 제거
new_state_dict[name] = v
model.load_state_dict(new_state_dict)
model = model.to(device)
model.eval()
return model
# 예측 결과를 이미지 파일로 저장
def save_prediction(pred, save_path, colormap_root, num_classes):
pred_np = pred.squeeze().cpu().numpy().astype(np.uint8)
os.makedirs(os.path.dirname(save_path), exist_ok=True)
Image.fromarray(pred_np).save(save_path)
normed = pred_np.astype(np.float32) / (num_classes - 1)
cmap = cm.get_cmap('turbo')
colored = cmap(normed)
rgb = (colored[:, :, :3] * 255).astype(np.uint8)
rgb_img = Image.fromarray(rgb)
try:
rel_path = os.path.relpath(save_path, start=os.path.dirname(save_path))
cmap_path = os.path.join(colormap_root, os.path.dirname(os.path.relpath(save_path, start=args.result_dir)), rel_path)
except ValueError: # 다른 드라이브에 있을 경우 대비
rel_path = Path(save_path).name
cmap_path = os.path.join(colormap_root, rel_path)
os.makedirs(os.path.dirname(cmap_path), exist_ok=True)
rgb_img.save(cmap_path)
# 전체 테스트
def test(args):
# 단일 GPU 사용
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
dataset = TestSegmentationDataset(args.dataset_dir, subset=args.subset)
if not dataset.image_paths:
print(f"Error: No images found in '{dataset.image_dir}'. Please check the path and subset.")
return
dataloader = DataLoader(dataset, batch_size=1, shuffle=False, num_workers=2)
model = load_model(args.weight_path, args.num_classes, device)
colormap_root = os.path.join(args.result_dir, "colormap")
with torch.inference_mode():
for img_tensor, img_path_tuple in tqdm(dataloader, desc="Predicting..."):
img_path = img_path_tuple[0]
img_tensor = img_tensor.to(device)
output = model(img_tensor)
if isinstance(output, tuple):
output = output[0]
pred = torch.argmax(output, dim=1)
rel_path = os.path.relpath(img_path, start=os.path.join(args.dataset_dir, "image"))
save_path = os.path.join(args.result_dir, rel_path)
save_prediction(pred, save_path, colormap_root, args.num_classes)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--dataset_dir", type=str, default="./data", help="Path to dataset root directory")
parser.add_argument("--weight_path", type=str, default="./output/model_best.pth", help="Path to model weight (.pth)")
parser.add_argument("--result_dir", type=str, default="./result", help="Directory to save results")
parser.add_argument("--num_classes", type=int, default=19, help="Number of segmentation classes")
parser.add_argument("--subset", type=str, default="test", help="Which subset to run prediction on (e.g., 'test', 'val', 'train')")
args = parser.parse_args()
os.makedirs(args.result_dir, exist_ok=True)
test(args)mIoU 계산
import os
import argparse
import numpy as np
from PIL import Image
from glob import glob
from tqdm import tqdm
from sklearn.metrics import confusion_matrix
from pathlib import Path
def load_image(path):
return np.array(Image.open(path)).astype(np.uint8)
def compute_miou(confusion, num_classes):
"""
1. mIoU (All): NaN을 제외한 모든 클래스(IoU=0 포함)의 평균
2. mIoU (>0): IoU가 0보다 큰 클래스들만의 평균
"""
ious = []
for cls in range(num_classes):
TP = confusion[cls, cls]
FP = confusion[:, cls].sum() - TP
FN = confusion[cls, :].sum() - TP
denom = TP + FP + FN
if denom == 0:
iou = float('nan')
else:
iou = TP / denom
ious.append(iou)
# mIoU (All Classes) 계산
# NaN 값을 무시하고 평균을 계산.
miou_all = np.nanmean(ious)
# mIoU (IoU > 0 Classes Only) 계산
# IoU가 NaN이 아니고 0보다 큰 값들만 계산.
positive_ious = [iou for iou in ious if not np.isnan(iou) and iou > 0]
# 0이 제거된 iou 값들의 평균을 계산
if not positive_ious:
miou_positive = 0.0
else:
miou_positive = np.mean(positive_ious)
return miou_all, miou_positive, ious
def evaluate(result_dir, label_dir, num_classes):
pred_paths = sorted(glob(os.path.join(result_dir, "**", "*_leftImg8bit.png"), recursive=True))
print(f'Found {len(pred_paths)} segmentation result images in {result_dir}')
if not pred_paths:
print("Error: No prediction files found. Please check the 'result_dir' path and file names.")
return
all_confusion = np.zeros((num_classes, num_classes), dtype=np.int64)
for pred_path in tqdm(pred_paths, desc="Evaluating"):
sub_folder = Path(pred_path).parent.name
file_id = os.path.basename(pred_path).replace("_leftImg8bit.png", "")
label_path = os.path.join(label_dir, sub_folder, f"{file_id}_gtFine_CategoryId.png")
if not os.path.exists(label_path):
print(f"Label not found at {label_path}, skipping.")
continue
pred = load_image(pred_path).flatten()
label = load_image(label_path).flatten()
mask = label != 255
pred = pred[mask]
label = label[mask]
pred = np.clip(pred, 0, num_classes - 1)
label = np.clip(label, 0, num_classes - 1)
conf = confusion_matrix(label, pred, labels=list(range(num_classes)))
all_confusion += conf
miou_all, miou_positive, ious = compute_miou(all_confusion, num_classes)
print("\n--- Evaluation Results ---")
print(f"📊 mIoU (All Classes, IoU=0 포함): {miou_all:.4f}")
print(f"📊 mIoU (Positive Classes, IoU>0 제외): {miou_positive:.4f}")
print("--------------------------")
for i, iou in enumerate(ious):
print(f"Class {i}: IoU = {iou:.4f}" if not np.isnan(iou) else f"Class {i}: IoU = NaN (ignored in mean)")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Calculate mIoU for semantic segmentation results.")
parser.add_argument("--result_dir", type=str, default="C:/ETRI/result/test",
help="Predicted *_leftImg8bit.png files가 있는 상위 디렉토리")
parser.add_argument("--label_dir", type=str, default="C:/ETRI/data/labelmap/test",
help="정답 레이블 *_gtFine_CategoryId.png files가 있는 상위 디렉토리")
parser.add_argument("--num_classes", type=int, default=19, help="세그먼테이션 클래스 수")
args = parser.parse_args()
evaluate(args.result_dir, args.label_dir, args.num_classes)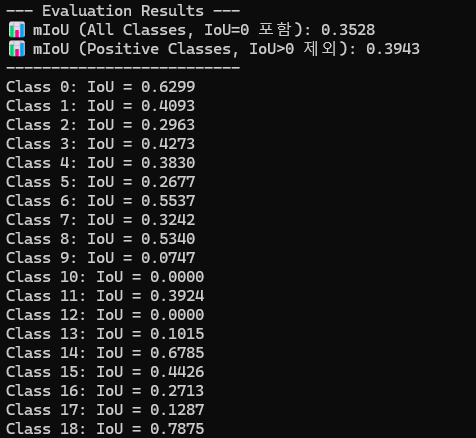
개선방법 1 : 폴더별 가중치 조절
개선방법 2 : 클래스별 가중치 조절
개선방법 3 : 데이터 증식 추가
| baseline | DDRNet_weight | |
|---|---|---|
| mIoU | 0.3228 | 0.3528 |
| inference time | 9.375ms | 9.375ms |
DDRNet에 대한 개선 방향
- 데이터 증식 방법 추가
- 폴더에 가중치를 주는 방향과 클래스별로 가중치를 주는 방향에 대해 효율적인 방향 탐구 필요.
- Train dataset(set1) 중 일부 데이터가 차량 본넷의 클래스가 잘못 라벨링이 되어있는것을 확인, 해당 데이터를 6번(차량) 클래스에서 18번(기타) 클래스로 변경
- 모델 구조에서 반복된 연산으로 인해서 연산량은 늘어나나 효율은 낮은 구조에 대해 개선.
