DDRNet 학습.
DDRNet 코드 학습
환경 구성.
중요 환경에 대한 버전.
Package Version
------------------- --------------------
numpy 1.24.1
opencv-python 4.12.0.88
thop 0.1.1.post2209072238
torch 2.3.1+cu118
torchaudio 2.3.1+cu118
torchvision 0.18.1+cu118ㅇㅇ
진행 작업
- BaseLine code Train 코드 개선 및 수행.
학습된 Epoch까지의 데이터에 대해서 추론 및 mIoU 계산.- Backbone을 freeze하여 Backbone의 가중치를 그대로 가진 상태로 추론 작업을 수행 가능하도록 개선.
- 다중 GPU작업에 맞춰진 환경을 단일 GPU 환경으로 개선.
- DataLoader나 학습 파라미터 등의 인자를 parser로 받아 조절 가능하게 개선.
- 학습이 길어지는 경우(중간에 끊어야 하는 경우)를 대비해서 CheckPoint model을 받아 학습을 이어 받을 수 있도록 개선
- 데이터셋의 일부(20%)를 Validation작업에 수행하기 위해서 데이터를 이동.
- train에 대해서 eval의 과정이 없는 코드에 eval DataLoader를 사용하여 train 중간에 eval과정을 거치도록 개선.
train.py
import os
import argparse
import torch
from torch.utils.data import DataLoader
from tqdm import tqdm
from collections import OrderedDict
from DDRNet import DDRNet
from functions import *
from pathlib import Path
def train_and_validate(args):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"Initialized single GPU training on device: {device}")
train_dataset = SegmentationDataset(args.dataset_dir, args.crop_size, 'train', args.scale_range)
val_dataset = SegmentationDataset(args.dataset_dir, args.crop_size, 'val', args.scale_range)
print(f"DataLoader settings: num_workers={args.num_workers}, pin_memory={args.pin_memory}, shuffle={args.shuffle}, drop_last={args.drop_last}")
train_dataloader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=args.shuffle, num_workers=args.num_workers, pin_memory=args.pin_memory, drop_last=args.drop_last)
val_dataloader = DataLoader(val_dataset, batch_size=args.batch_size, shuffle=False, num_workers=args.num_workers, pin_memory=args.pin_memory)
model = DDRNet(num_classes=args.num_classes).to(device)
criterion = CrossEntropy(ignore_label=255)
if args.freeze_backbone:
print("❄️ Freezing backbone layers...")
backbone_layer_names = ['conv1', 'layer1', 'layer2', 'layer3', 'layer4', 'spp']
for name, param in model.named_parameters():
if any(name.startswith(layer_name) for layer_name in backbone_layer_names):
param.requires_grad = False
params_to_update = [p for p in model.parameters() if p.requires_grad]
print(f"Total parameters: {len(list(model.parameters()))}, Trainable parameters: {len(params_to_update)}")
optimizer = torch.optim.SGD(params_to_update, lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay)
scheduler = WarmupPolyEpochLR(optimizer, total_epochs=args.epochs, warmup_epochs=args.warmup_epochs, warmup_ratio=5e-4)
start_epoch = 0
min_val_loss = float('inf')
if args.loadpath is not None:
print(f"Loading checkpoint from: {args.loadpath}")
checkpoint = torch.load(args.loadpath, map_location=device)
try:
new_state_dict = OrderedDict()
for k, v in checkpoint['model_state_dict'].items():
name = k[7:] if k.startswith('module.') else k
new_state_dict[name] = v
model.load_state_dict(new_state_dict, strict=False)
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
scheduler.load_state_dict(checkpoint['scheduler_state_dict'])
start_epoch = checkpoint['epoch'] + 1
min_val_loss = checkpoint.get('loss', float('inf'))
print(f"Resuming training from epoch {start_epoch}, with min_val_loss: {min_val_loss:.4f}")
except KeyError:
print("Old checkpoint format. Loading model state_dict only.")
new_state_dict = OrderedDict()
for k, v in checkpoint.items():
if k.startswith('module.'): name = k[7:]
elif k.startswith('model.'): name = k[6:]
else: name = k
new_state_dict[name] = v
model.load_state_dict(new_state_dict, strict=False)
os.makedirs(args.result_dir, exist_ok=True)
log_path = os.path.join(args.result_dir, "log.txt")
mode = 'a' if start_epoch > 0 else 'w'
with open(log_path, mode) as f:
if start_epoch == 0: f.write("Epoch\t\tTrain-loss\t\tVal-loss\t\tlearningRate\n")
for epoch in range(start_epoch, args.epochs):
model.train()
total_train_loss = 0.0
loop = tqdm(train_dataloader, desc=f"Train [{epoch+1}/{args.epochs}]", ncols=100)
for i, (imgs, labels) in enumerate(loop):
optimizer.zero_grad(set_to_none=True)
imgs, labels = imgs.to(device), labels.to(device)
outputs = model(imgs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_train_loss += loss.item()
loop.set_postfix(loss=loss.item(), avg_loss=total_train_loss/(i+1), lr=scheduler.get_last_lr()[0])
avg_train_loss = total_train_loss / len(train_dataloader)
scheduler.step()
avg_val_loss_str = "N/A"
if (epoch + 1) % 5 == 0 or (epoch + 1) == args.epochs:
model.eval()
total_val_loss = 0.0
with torch.no_grad():
loop_val = tqdm(val_dataloader, desc=f"Val [{epoch+1}/{args.epochs}]", ncols=100)
for i, (imgs, labels) in enumerate(loop_val):
imgs, labels = imgs.to(device), labels.to(device)
outputs = model(imgs)
loss = criterion(outputs, labels)
total_val_loss += loss.item()
avg_val_loss = total_val_loss / len(val_dataloader)
avg_val_loss_str = f"{avg_val_loss:.4f}"
print(f"\nEpoch {epoch+1}: Train Loss = {avg_train_loss:.4f}, Validation Loss = {avg_val_loss:.4f}")
if avg_val_loss < min_val_loss:
min_val_loss = avg_val_loss
ckp_path = os.path.join(args.result_dir, "model_best.pth")
state_to_save = {
'epoch': epoch, 'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(), 'scheduler_state_dict': scheduler.state_dict(),
'loss': min_val_loss,
}
torch.save(state_to_save, ckp_path)
print(f"Best model saved at epoch {epoch+1} with val loss {min_val_loss:.4f}")
ckp_path = os.path.join(args.result_dir, f"model_epoch{epoch+1}.pth")
state_to_save = {
'epoch': epoch, 'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(), 'scheduler_state_dict': scheduler.state_dict(),
'loss': avg_val_loss,
}
torch.save(state_to_save, ckp_path)
lr = scheduler.get_last_lr()[0]
with open(log_path, "a") as f:
log_entry = f"\n{epoch + 1}\t\t{avg_train_loss:.4f}\t\t{avg_val_loss_str}\t\t{lr:.8f}"
f.write(log_entry)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="DDRNet Training Script")
parser.add_argument("--dataset_dir", type=str, default="./data", help="Path to dataset root")
parser.add_argument("--loadpath", type=str, default=None, help="Path to checkpoint for resuming training")
parser.add_argument("--result_dir", type=str, default="output", help="Directory to save results")
parser.add_argument("--epochs", type=int, default=400, help="Total number of training epochs")
parser.add_argument("--num_classes", type=int, default=19, help="Number of segmentation classes")
parser.add_argument("--lr", type=float, default=1e-2, help="Initial learning rate")
parser.add_argument("--batch_size", type=int, default=8, help="Training batch size")
parser.add_argument("--momentum", type=float, default=0.9, help="Momentum for SGD optimizer")
parser.add_argument("--weight_decay", type=float, default=5e-4, help="Weight decay for SGD optimizer")
parser.add_argument("--warmup_epochs", type=int, default=5, help="Number of warmup epochs for scheduler")
parser.add_argument("--crop_size", default=[512, 1024], type=arg_as_list, help="Crop size (H W)")
parser.add_argument("--scale_range", default=[0.75, 1.5], type=arg_as_list, help="Resize input scale range")
parser.add_argument("--num_workers", type=int, default=os.cpu_count(), help="Number of workers for DataLoader")
parser.add_argument("--no_pin_memory", action="store_false", dest="pin_memory", help="Disable pin_memory for DataLoader")
parser.add_argument("--no_shuffle", action="store_false", dest="shuffle", help="Disable shuffling for training data")
parser.add_argument("--no_drop_last", action="store_false", dest="drop_last", help="Disable drop_last for training data")
parser.set_defaults(pin_memory=True, shuffle=True, drop_last=True)
parser.add_argument("--freeze_backbone", action='store_true', help="Freeze backbone layers for fine-tuning")
args = parser.parse_args()
result_dir = Path(args.result_dir)
result_dir.mkdir(parents=True, exist_ok=True)
train_and_validate(args)DDRNet23s_imagenet.pth파일의 가중치를 받아서 진행.
Backbone을 freeze하고 학습을 진행하는 경우 전체 파라미터의 1/3정도만 학습이 되고 학습 진행에 있어서 Train의 Loss값이 너무 느리게 학습되는 현상이 발견되어 Backbone freeze작업을 수행하지 않고 전체적으로 모두 수행하기로 함.
Backbone을 imagenet과 cityscape로 모두 학습을 수행했으나 유의미한 차이를 발견하지 못함.

학습 실행 최종 명령어.
python backbone_freeze_train.py --loadpath ./DDRNet_cityscape.pth --batch_size 16
학습 Epoch은 200Epoch으로 진행하였을 때 계속해서 Loss값이 낮아지는 경향이 있어 CheckPoint로 이어서 학습하기로 하고 크게 500으로 설정.
학습 결과
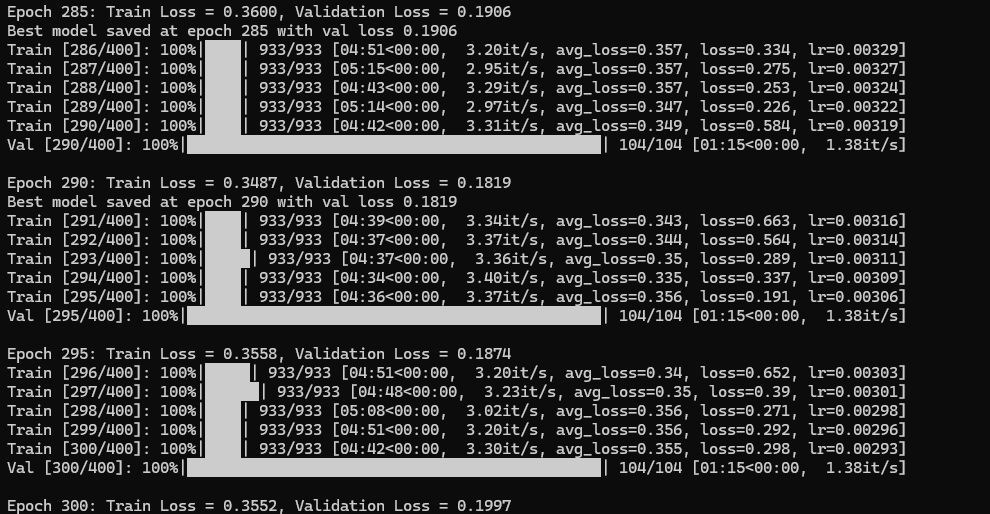
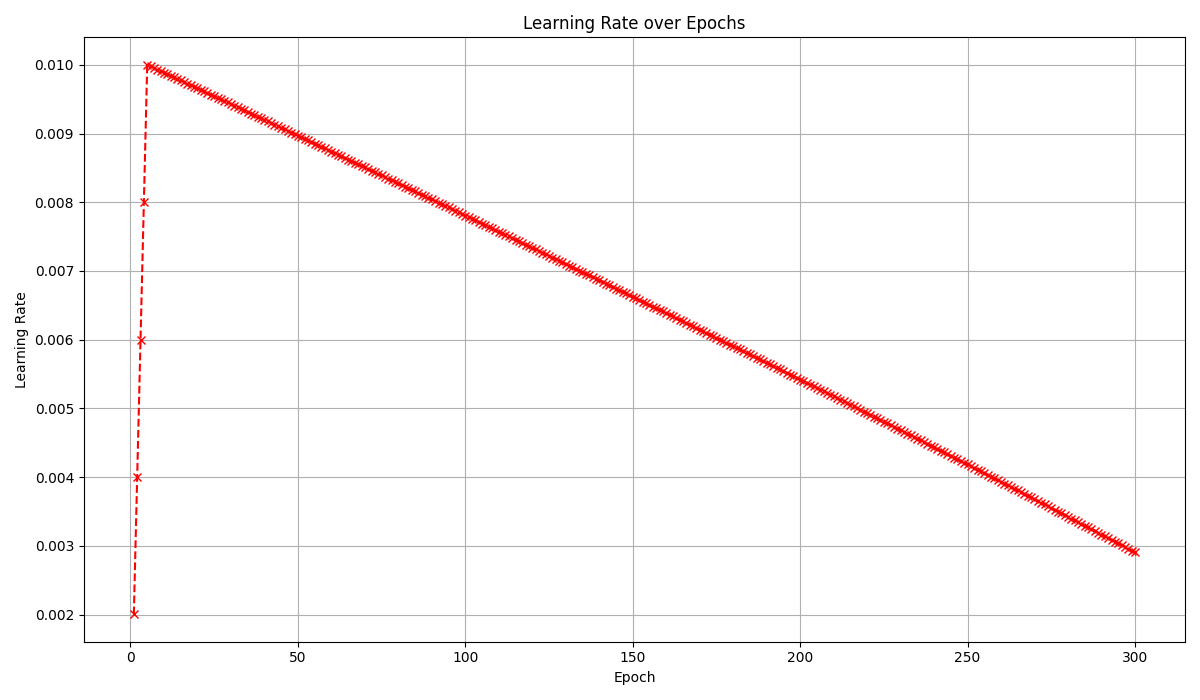
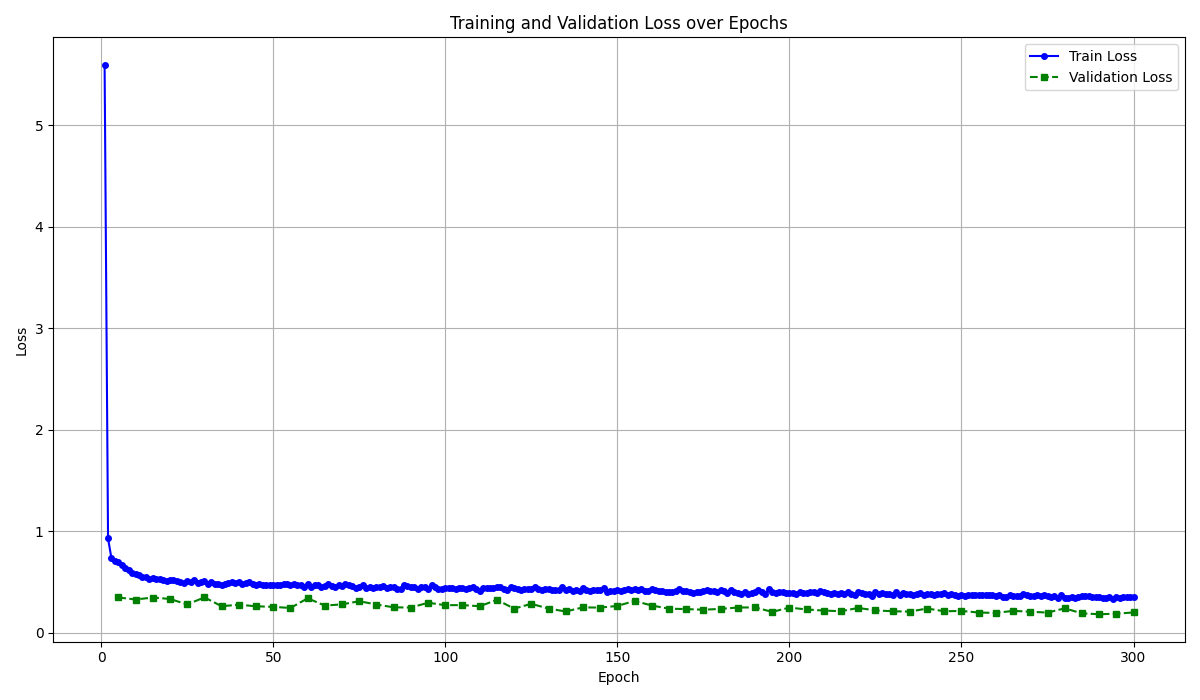
낮게나마 낮아지던 loss값이 300Epoch가까이 진행되었을 때 무의미하다고 판단하여 학습을 종료
test dataset predict 결과 (200Epoch에 대한 추론)
 |  |
|---|---|
 |  |
mIoU값 계산.
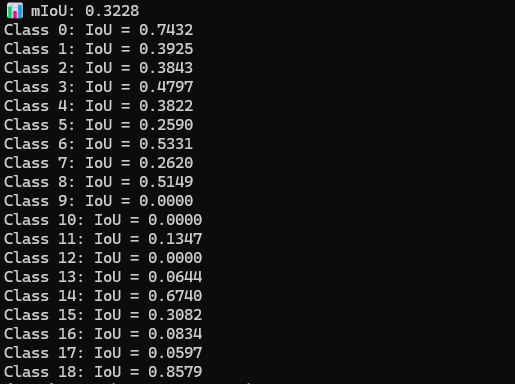 클래스가 없는 경우를 포함하였을 때 클래스가 없는 경우를 포함하였을 때 | 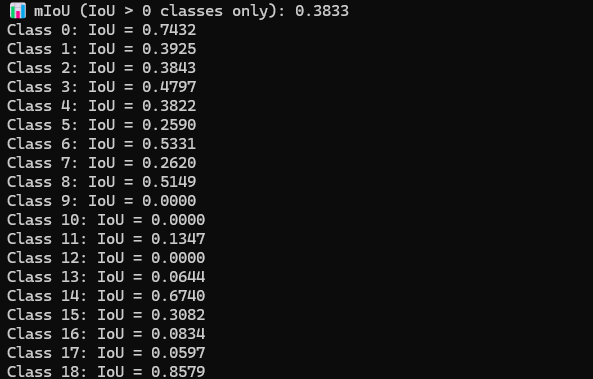 클래스가 없는 경우를 제외하였을 때 클래스가 없는 경우를 제외하였을 때 |
|---|---|
| 0(주행가능영역) | 0.7432 |
| 1(인도) | 0.3925 |
| 2(도로노면표시) | 0.3843 |
| 3(차선) | 0.4797 |
| 4(연석) | 0.3822 |
| 5(벽,울타리) | 0.2590 |
| 6(승용차) | 0.5331 |
| 7(트럭) | 0.2620 |
| 8(버스) | 0.5149 |
| 9(바이크, 자전거) | N/A |
| 10(기타 차량) | N/A |
| 11(보행자) | 0.1347 |
| 12(라이더) | N/A |
| 13(교통용 콘 및 봉) | 0.0644 |
| 14(기타 수직 물체) | 0.6740 |
| 15(건물) | 0.3082 |
| 16(교통 표지) | 0.0834 |
| 17(교통 신호) | 0.0597 |
| 18 (기타) | 0.8579 |
- 차량 객체 중 트럭의 가중치 낮음.
- 바이크, 기타 차량, 라이더 등에 대해 test로 넣은 이미지에 없는 지 0으로 mIoU결과값 추론
- 교통용 콘, 봉, 교통 표지, 교통 신호 등 작은 객체에 대한 정확도 낮음.
- loss값에 비교하여 mIoU값이 불안정. 18번 클래스 기타에 대해 loss값이 맞춰진 것으로 추측
inference time

모델 구조에 대해서 현재 환경에 약 9.3ms
DDRNet에 대한 개선 방향
- 폴더와 클래스별로 가중치를 다르게 개선
- 폴더별로 클래스 분포를 확인
- 증강 기법 추가(우천, 강한 강원 등에 대비) - 색상에 제한되는 객체(신호등의 경우 Red, Blue, Green)를 신경쓸 필요가 없으니 색상 변환 등도 추가할 예정.
- inference time을 개선할 방법 모색
모델 비교
| Model | DDRNet | Deeplabv3 | YOLOv11_m |
|---|---|---|---|
| inference time | 9.3ms | X | 7.3ms |
| mIoU | 0.3228 | 0.6 | X |
| loss | 0.355 | 0.18 | 1.55 |
mIoU값에 대해서는 Deeplabv3가 가장 높게 나오는 중이나 모델의 크기와 추론 시간에 대한 정확한 정보 필요.
YOLOv11_m은 YOLOv11_s 학습 결과가 나온 이후에 해당 값에 대해서 비교.
추론 시간이 모델의 사이즈가 낮아짐에 따라서 추론 시간에 장점이 있을 것으로 보임.
DDRNet은 추론 시간과 mIoU 값 등 여러 개선이 필요.
주의 요소 : 추론 시간 계산 시 장비에 따라 차이가 있음을 주의
(RTX 4070 super, RTX 5070(컴퓨터실))
Deeplabv3는 학습 진행 중이므로 설정한 Epoch이 진행된 모델 기준으로 mIoU값과 loss값 다시 정리 예정.
