You Only Look at Once for Real-Time and Generic Multi-Task
논문을 기반으로 작성하였고 서베이 논문을 포함하여 Multi-Task model 자체에 대한 설명을 하는 글.
이전까지의 딥러닝 모델들은 하나의 입력에 대해 하나의 출력값을 가진다.
Image Classification : 객체의 클래스
Object Detection : 객체의 클래스와 BBox값.
Image Segmentation : 객체의 클래스와 객체의 마스크.
객체의 클래스가 Object Detection과 Image Segmentation에 모두 포함되는 이유는 Head의 구조에 있다.
YOLOv8의 Head는 Decoupled Head를 사용하는데 Classification Branch와 Regression Branch로 구성되어 Classification Branch 에서는 클래스 확률을 예측하고 Regression Branch 에서는 BBox 좌표와 Objectness Score를 예측한다.
각 Head에 대해서 손실 함수의 종류를 선택하고 loss값의 가중치를 조절하는 등의 작업을 통해 균형을 이룬다.
-> YOLOv10의 경우에서는 Classification Branch가 Regression Branch보다 모델의 성능에 덜 영향을 미치는 것을 확인하여 해당
Head에 들어가는 파라미터의 값을 줄이는 작업도 진행한다.
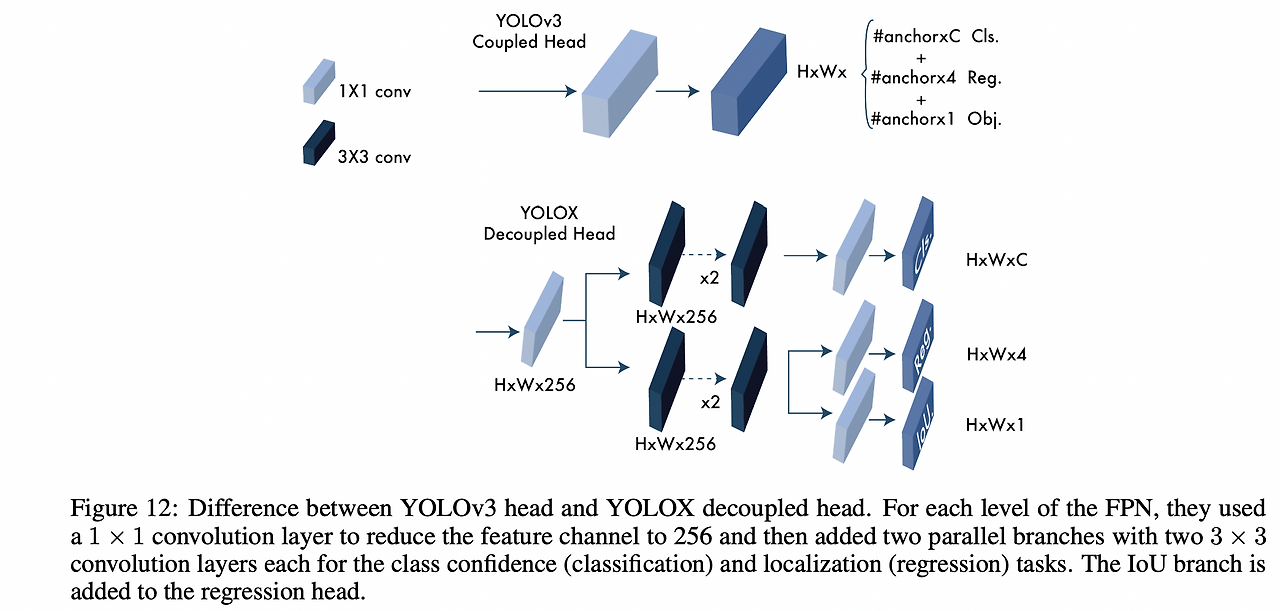
위 단락까지만 보게 된다면 Object detection과 Image Segmentation작업도 하나의 Multi-Task라고 볼 수 있다.(Head라 통칭한 구조 내부에서 Classification과 Detection or Segmentaion작업을 수행하여 출력값이 2개 이상이므로.) 하지만 Detection 작업을 수행하려면 객체가 무었인지부터 파악해야 하는데 이 과정이 Classification 작업이므로 Object Detect과 Image Segmentation작업을 수행할 때 Classification Branch가 존재하는 것에 대하여 Multi-Task Model이라고 엄격히 표시하지는 않는 듯 하다.
(Detection과 Segmentation은 BBox와 Mask 계산에 사용되는 값들이 달라 Multi-task라고 확실히 불린다.)
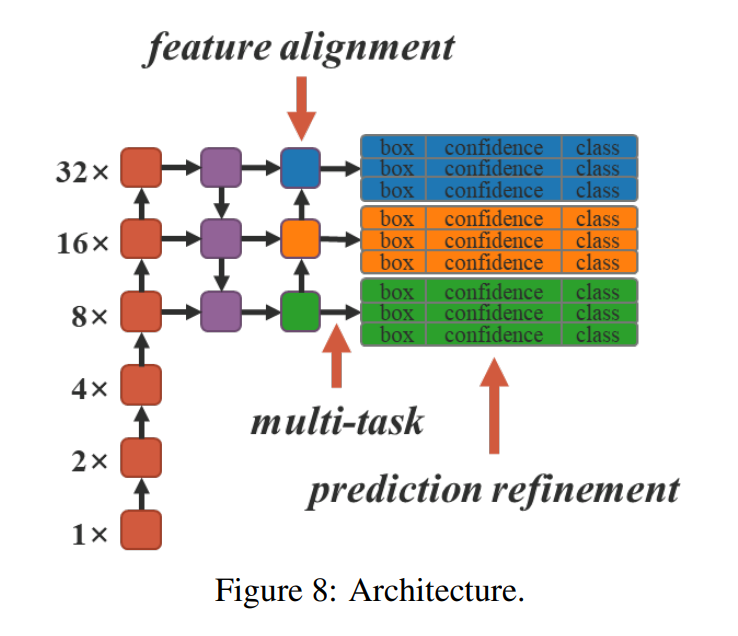 물론 YOLOR의 논문처럼 multi-task라고 표시해주는 경우도 존재한다.
물론 YOLOR의 논문처럼 multi-task라고 표시해주는 경우도 존재한다.
다시 되돌아와 Multi-Task의 본질은 하나의 Input값에 대하여 2개 이상의 output을 출력하는 작업들을 의미한다.
YOLO series의 경우에는 Input이 이미지이고 output이 classfication, detection, segmentation이 된다.
이미지에 대한 Multi-Task를 목적으로 하는 작업들은 대부분 detection과 segmentation 작업을 합치는 것으로 자율주행에서는 차량과 사람 등에 장애물에 대한 BBox를 구하고 Line Lane과 Drivable Area에 대한 Mask들을 추출한다.
결국 중요한 요점은 모델의 구조를 설계할 때 어디까지 공유를 하고 하이퍼 파라미터들을 어떻게 설정하는지가 된다.
A-YOLOM의 경우 Backbone을 공유하고 Neck과 Head를 모두 분리시키는 방법을 사용한다.
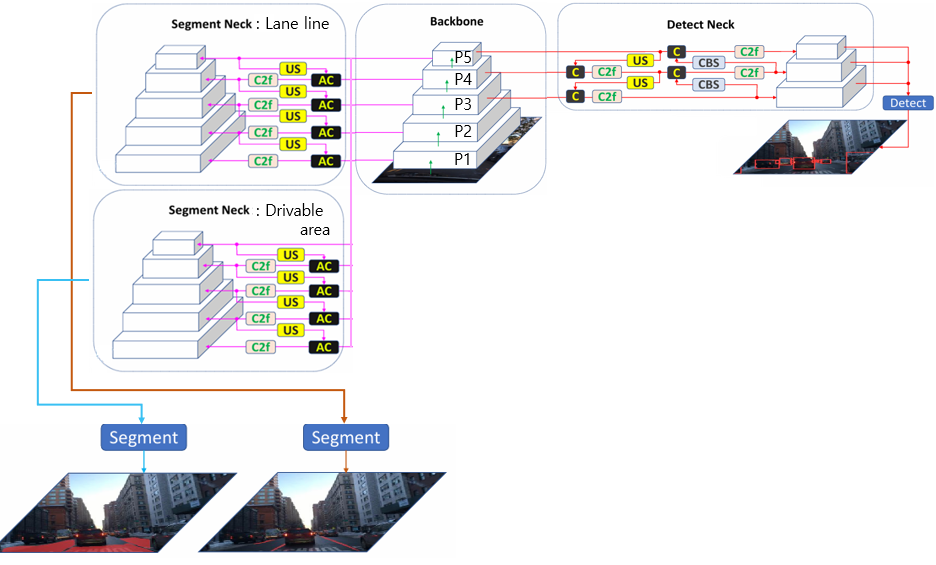
해당 논문에서는 Backbone을 공유하여 특성 추출단계에서의 연산량을 줄이고 AC 블록을 통해 Neck에서의 연산량을 추가적으로 줄임과 동시에 불필요한 특성들을 가져오지 않도록 하였다.
DRMNet의 경우에는 Backbone과 Neck을 공유하고 Head를 분리시켜 사용한다.
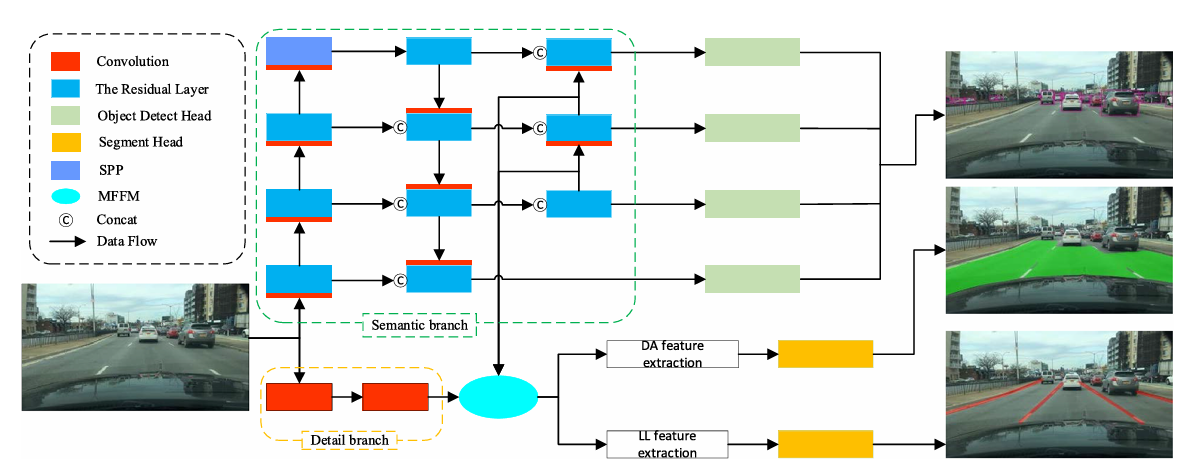
Neck을 공유하지 않는 듯 하지만 Detail Branch(Conv) 이후 Segmentic Branch에서 생성된 Neck의 특성맵을 받은 이후에 Head로 분리되는 것을 확인할 수 있다.
DLT-Net의 경우에는 Traffic Object Decoder라는 추가적인 객체를 검출한다
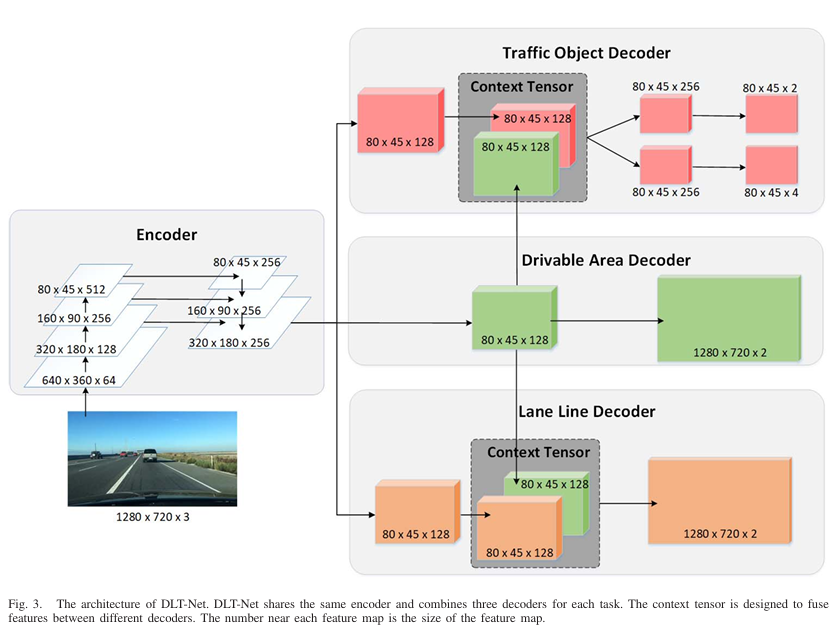
당 논문은 Drivable Area 내부에 Lane Line이 존재하고 Drivable Area로 취급되지 않는 영역에 대해서 Traffic Object가 있는 것에 집중하여 구조를 설계하였다<마지막 특성맵이 차원 수가 256이었으나 128로 줄어든 것은 point-wise conv작업을 진행한 것으로 보인다.(github에서 확인해보려 하였으나 존재하지 않아 확인은 실패.) >. Backbone과 Neck을 공유하고 Context Tensor영역을 추가하여 Drivable Area 내부에 있는 특성맵을 공유하는 형식으로 진행된다. Context Tensor를 통과할 때 Traffic Object는 Concatenation작업을 통해 최종적으로 8045256의 특성맵을 가지게 되고 Lane Line Decoder의 경우에는 Element-wise Addition작업을 수행하여 Drivable Area Decoder와 같은 8045128의 특성맵을 가지게 된다.
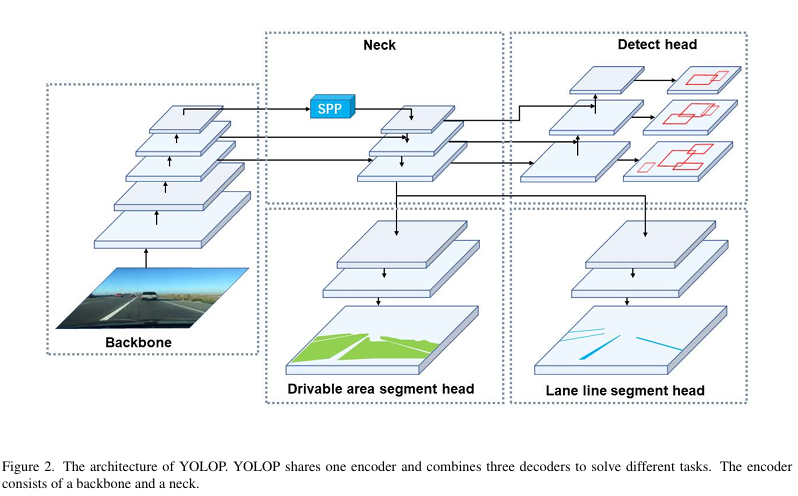
YOLOP는 Neck구조까지 공유를 하지만 Detect Head는 모든 특성맵을 사용하는 반면 Segment Head들은 Neck의 가장 큰 사이즈의 특성맵만을 받아 사용하는 구조를 가진다.(사실 YOLOP만의 특성은 아니고 많이 사용한다.)
위 사례들처럼 Multi-Task작업을 구현하는 방식은 여러가지이다.
- Backbone만을 공유하는 사례.
- Neck까지 공유를 하지만 Segment Head에서는 Neck의 일부분만 추출하여 사용하는 사례.
- Neck까지 모두 공유를 하고 Drivable Area의 특성을 다른 Head에 공유하는 사례.
이 외에도 보지 못한 논문들과 사례들이 많겠지만 기본적으로 Backbone은 공유를 하고 Neck은 선택적으로 공유를 하거나 아에 분리시키는 것을 목표로 한다.
특이한 점은 A-YOLOM처럼 Neck의 단계에서 분리를 시킬 때 Segment Neck과 Detect Neck 2가지로 분리시키지 않고 Segment Neck를 2개를 사용하여 총 3개의 Neck을 사용했다는 것이다.
Loss를 기반으로 생각할 때 Multi-Task의 Loss값은 아래와 같이 계산된다.
(각 모델마다 계산하는 방식이 차이는 있지만 전체적인 프레임은 아래와 같다.)
( Loss_1 : Detection loss, Loss_2 : Drivable area loss, Loss_n : Lane line loss <- 부여된 값 예시 )
[ Total Loss = W_1 Loss_1 + W_2 Loss_2 + ... + W_n * Loss_n ]
계산된 Loss값은 각 Head에 동일하게 부여되어 최적화 과정을 거치게 되는데 Neck을 공유하게 된다면 Head에서 계산되어 나온 Loss값을 합친다.
( w1 : Detection weight, w2 : Drivable weight, w3 : Lane weight )
[ Total Neck Loss = w1 Loss_detection_head + w2 Loss_drivable_head + w3 * Loss_lane_head ]

해당 작업에서 각 작업에 주어지는 Weight값들은 일반적으로 직접 부여하게 된다. (weight값은 영향력, 기여도 등으로 이해해도 좋다.)
이후 Backbone은 Neck이 하나로 이루어져 있다면 하나의 Loss값을 받게 되고 Backbone만을 공유한다면 Neck에서 진행된 과정을 Backbone에서 거치게 된다. 하지만 위에서 언급한 것처럼 Neck을 2개를 사용하고 다시 한번 Neck에서 2개의 Head를 구성하게 되는 경우에는 Loss값을 합치는 과정을 2번 격게 된다. 이 과정에서 각 작업에 대한 Weight값(Neck에서 2번 Backbone에서 2번)을 설정하는 과정도 쉽지 않으며 Head의 수가 달라 절대적인 Gradient값에 대해서도 Head가 많은 경우의 Neck이 높은 값을 가지게 되어 하나의 Head를 가진 Neck의 작업이 낮은 성능을 가지게 되는 경우가 있어 비대칭의 학습이 이루어질 수 있다.
다음과 같은 문제점을 소지하고 있고 해당 작업을 가중치 자동화 작업(Uncertainty-based Weighting)과 중간의 Neck전용 Loss( Auxiliary Loss)값을 추가해주는 방식 등을 통해 완화시킬 수 있지만 다른 구조를 사용하는 편이 더 간편하고 효율성이 높아 Backbone도 공유하고 Neck을 공유함과 동시에 분리시키는 구조는 거의 사용되지 않는다.
종합적으로 평가하였을 때 Multi-Task에서 중요하게 판단하는 부분을 나열하면 다음과 같다.
- Backbone까지 공유할 것인지 Neck까지 공유할 것인가.
- Neck까지 공유하는 경우에 Segmentation 작업에 대해 어느 수준의 정보를 제공할 것인가.
ㄴ Detection작업의 경우 작은 객체에 대한 인식이 필요하여 모든 사이즈 레벨의 특성맵을 모두 사용한다.
ㄴ 위 과정에서 FPN Network뿐만 아니라 PAN Network도 사용하는 경우가 다수이다. - Loss값을 계산할 때 어떠한 방식으로 손실 값을 계산할 것인가.
ㄴ Object detection의 경우 CIoU, DIoU, dfl, softmax cross, L1, L2 등
ㄴ Image Segmentation의 경우 Cross-Entropy, Focal, IoU 등 - 작업을 모두 거쳤을 때 FLOPs값의 크기
- 작업을 모두 거쳤을 때 정확도와 클래스 인식률.
