YOLOv8 코드를 기반으로 작성
DATASET.YAML
YOLO model에서 데이터셋 호출을 위해서 설정하는 파일
위치 : ultralytics/ultralytics/cfg/dataset/custum.yaml
데이터셋이 포함되어있는 전체 데이터셋 폴더 위치, path와 내부 학습, 검증, 테스트 데이터셋의 세부 경로를 포함.
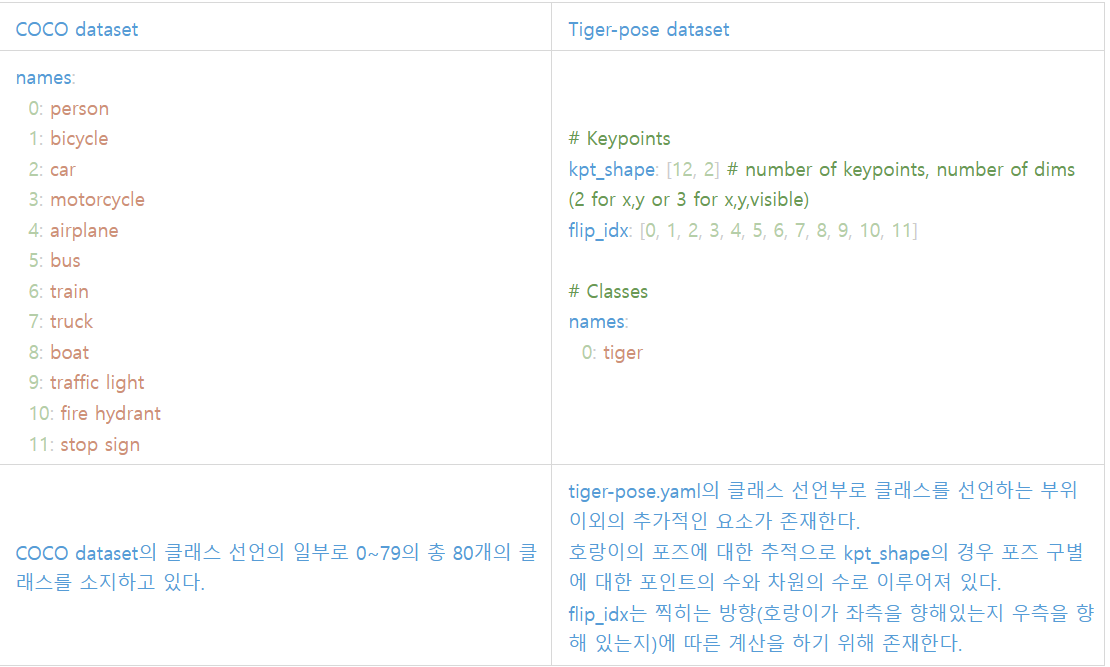
ultralytics의 coco8.yaml.
# Train/val/test sets
# 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco8 # dataset root dir
train: images/train # train images
val: images/val # val images
test: # test images경로를 지정하는 방법으로는 3가지가 존재한다.
(경로를 지정할 떄 lables가 기준이 아닌 images가 기준이 된다.)
1) 경로 : 데이터셋이 들어가 있는 디렉토리의 경로를 지정. (절대경로와 상대경로 모두 가능하다.)
2) 파일 : 이미지의 경로를 나열한 파일을 지정하는 것으로 train의 경우 ../dataset/train/img1.jpg, ../dataset/train/img2.jpg처럼 하나의 txt파일 내부에 각 이미지의 경로를 나열하는 방식으로 저장 후 txt의 경로를 지정한다.
3) 리스트 : 이미지 하나하나의 경로를 직접 적어주는 방식 ["/dataset/train/img1.jpg", "dataset/train/img2.jpg"]를 train:이후 적어주어 이미지 각각을 선택한다.
GlobalWheat2020.yaml 파일이 동일 dataset경로에 있는데 해당 데이터셋은 아래와 같이 하나의 dataset폴더에 모든 데이터셋을 넣고 내부 폴더로 분할시켜주었다.
path: ../datasets/GlobalWheat2020 # dataset root dir
train: # train images
- images/arvalis_1
- images/arvalis_2
- images/arvalis_3
- images/ethz_1
- images/rres_1
- images/inrae_1
- images/usask_1
val: # val images
- images/ethz_1
test: # test images
- images/utokyo_1
- images/utokyo_2
- images/nau_1
- images/uq_1해당 방식은 리스트를 이용한 방식으로 yaml형식의 파일은 ' : ' 이 변수 명 이후에 적혀있다면 이후 ' - '를 통해 리스트를 생성할 수 있다.
train을 python형식으로 고친다면 train["images/arvalis_1", "images/arvalis_2", "images/arvalis_3"] 과 동일하게 볼 수 있다.
데이터셋 클래스 설정
데이터셋의 경로 설정 이후 해당 데이터셋에 대한 클래스를 지정해줘야 한다.
'names'의 변수 명을 가진 리스트 형태로 작성되며 일반적으로는 해당 클래스 선언 이후 yaml 파일이 끝이난다.
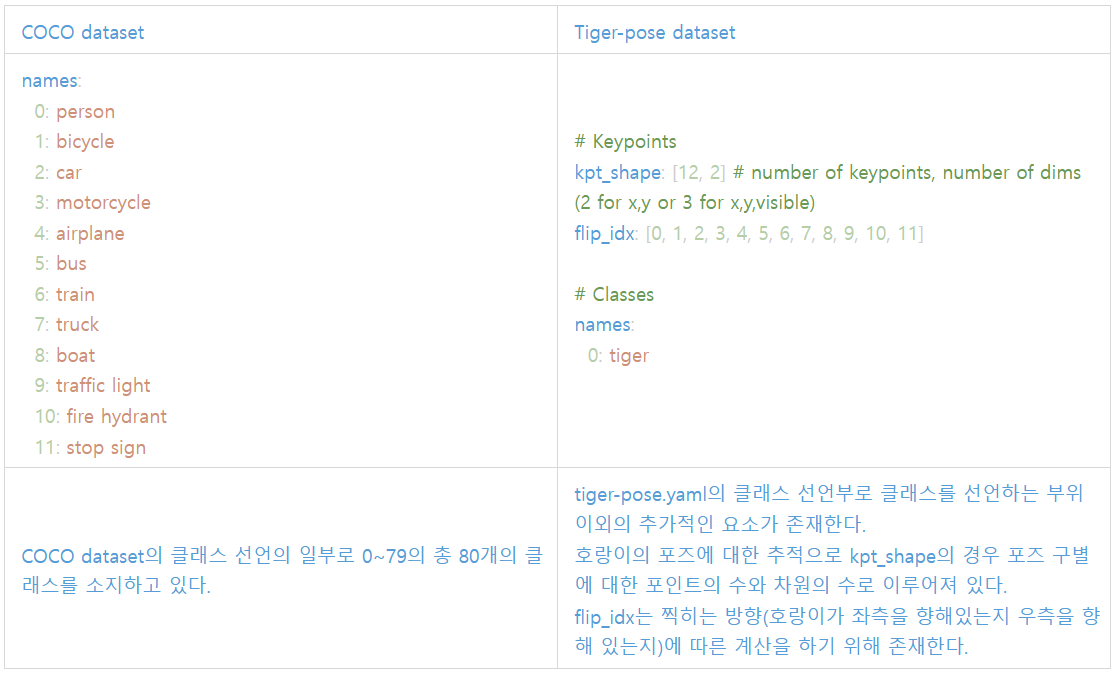
eypoint는 Classes의 일부로 객체 탐지에서 "호랑이"로 추측되는 객체가 존재한다면 해당 객체에 대해 신체 부위 포인트를 지정하기 위해서 Keypoint가 추가적으로 사용되는 데이터이다.
데이터셋 다운로드
대부분의 유저들은 처음 공부하거나 기존 코드를 사용하려 할 때 데이터셋을 미리 구현해두고 코드를 다운받지 않고 코드를 다운로드 받고 이에 해당하는 데이터셋을 찾기 때문에 대중적이거나 공개된 데이터셋의 경우 yaml파일을 읽어들이면서 존재하지 않는다면 파일을 다운로드 받을 수 있게 한다.
내부에 형식이 잘 정리되어있는 경우에는 아래와 같이 링크 하나만 존재하기도 하며
{ data8.yaml }
내부에 형식이 추가적으로 필요한 데이터셋의 경우 추가적인 작업을 진행해주기도 한다
# Download script/URL (optional)
download: https://github.com/ultralytics/assets/releases/download/v0.0.0/dota8.zip```
```# Download script/URL (optional) ------------------------------------------------------------------
download: |
from ultralytics.utils.downloads import download
from pathlib import Path
# Download
dir = Path(yaml['path']) # dataset root dir
urls = ['https://zenodo.org/record/4298502/files/global-wheat-codalab-official.zip',
'https://github.com/ultralytics/assets/releases/download/v0.0.0/GlobalWheat2020_labels.zip']
download(urls, dir=dir)
# Make Directories
for p in 'annotations', 'images', 'labels':
(dir / p).mkdir(parents=True, exist_ok=True)
# Move
for p in 'arvalis_1', 'arvalis_2', 'arvalis_3', 'ethz_1', 'rres_1', 'inrae_1', 'usask_1', \
'utokyo_1', 'utokyo_2', 'nau_1', 'uq_1':
(dir / 'global-wheat-codalab-official' / p).rename(dir / 'images' / p) # move to /images
f = (dir / 'global-wheat-codalab-official' / p).with_suffix('.json') # json file
if f.exists():
f.rename((dir / 'annotations' / p).with_suffix('.json')) # move to /annotationsDATALOADER
DATALOADER-dataset.py
YOLO는 데이터셋 호출시 공통적으로 class YOLODataset을 사용한다.
해당 관련 코드는 ultralytics/ultralytics/cfg/data/dataset.py에 있다.
생성자에 대한 초기화는 다음과 같이 이루어진다.
def __init__(self, *args, data=None, task="detect", **kwargs):
self.use_segments = task == "segment"
self.use_keypoints = task == "pose"
self.use_obb = task == "obb"
self.data = data
assert not (self.use_segments and self.use_keypoints), "Can not use both segments and keypoints."
super().__init__(*args, **kwargs)
head의 속성에 따라 'segment', 'keypoint', 'obb'에 대한 속성을 파악하고 data는 자체적으로 받아들인다.
head의 속성을 입력하지 않는다면 'detect'으로 자동 설정된다.
다음 cache_lables 함수는 데이터셋 중 labeles 정보를 읽을 때 쓰이는 함수로 txt파일을 인덱스 형식으로 처리하여 정보를 읽는 방식을 설정한다.
| 일반 | multitask(A-YOLOM) |
|---|---|
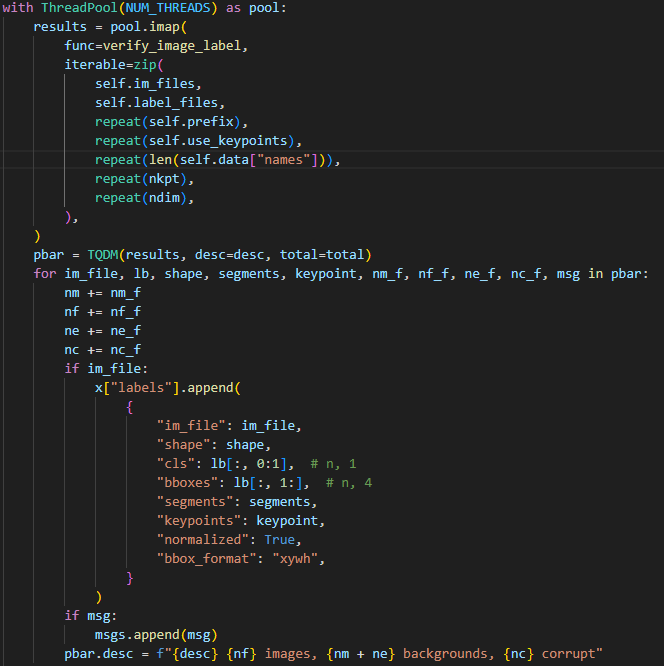 | 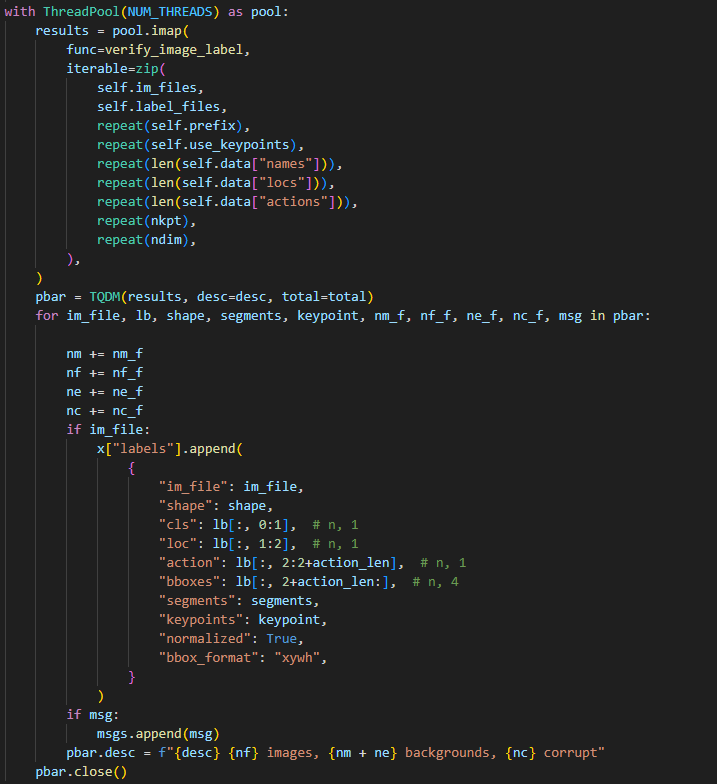 |
우측의 그림은 detection과 segmentation작업을 모두 수행하는 A-YOLOM코드에 대한 정보이다.
DATALOADER-augment.py
(프로젝트 코드로 진행 - loc와 action만 제거하면 원본 코드와 거의 동일하다, 다른 부분은 체크하고 넘길 예정.)
데이터 증식 관련된 함수들과 클래스가 모여있는 장소로 mosaic와 mixup 데이터 증식 기법부터 포함하여 픽셀을 건드리는 수준의 데이터 증식 기법과 공간적 측면을 건드리는 데이터 증식 기법을 가지고 있다.
데이터 증식에 대해서 직접적으로 건드리는 클래스는 class Albumentations이고 이 클래스가 가지고 있는 데이터 증식 기법들은 아래 하단의 사이트에 정리되어있다.
Albumentations Documentation
Albumentations는 공간적 속성을 변경하는 spatial_transforms과 pixel에 대해 값 똑은 색상 등을 변환하는 데이터 증식 기법들에 대해 Compose 클래스에 정리한다.
spatial_transforms에 나열되어있는 집합의 원소들은 사용 가능한 데이터 증식 기법들을 나타낸것이다.
def __init__(self, p=1.0):
"""Initialize the transform object for YOLO bbox formatted params."""
self.p = p
self.transform = None
prefix = colorstr("albumentations: ")
try:
import albumentations as A
check_version(A.__version__, "1.0.3", hard=True) # version requirement
# List of possible spatial transforms
spatial_transforms = {
"Affine",
"BBoxSafeRandomCrop",
"CenterCrop",
"CoarseDropout",
"Crop",
"CropAndPad",
"CropNonEmptyMaskIfExists",
"D4",
"ElasticTransform",
"Flip",
"GridDistortion",
"GridDropout",
"HorizontalFlip",
"Lambda",
"LongestMaxSize",
"MaskDropout",
"MixUp",
"Morphological",
"NoOp",
"OpticalDistortion",
"PadIfNeeded",
"Perspective",
"PiecewiseAffine",
"PixelDropout",
"RandomCrop",
"RandomCropFromBorders",
"RandomGridShuffle",
"RandomResizedCrop",
"RandomRotate90",
"RandomScale",
"RandomSizedBBoxSafeCrop",
"RandomSizedCrop",
"Resize",
"Rotate",
"SafeRotate",
"ShiftScaleRotate",
"SmallestMaxSize",
"Transpose",
"VerticalFlip",
"XYMasking",
} # from https://albumentations.ai/docs/getting_started/transforms_and_targets/#spatial-level-transforms
# Transforms
T = [
A.Blur(p=0.01),
A.MedianBlur(p=0.01),
A.ToGray(p=0.01),
A.CLAHE(p=0.01),
A.RandomBrightnessContrast(p=0.0),
A.RandomGamma(p=0.0),
A.ImageCompression(quality_lower=75, p=0.0),
]
# Compose transforms
self.contains_spatial = any(transform.__class__.__name__ in spatial_transforms for transform in T)
self.transform = (
A.Compose(T, bbox_params=A.BboxParams(format="yolo", label_fields=["class_labels"]))
if self.contains_spatial
else A.Compose(T)
)
LOGGER.info(prefix + ", ".join(f"{x}".replace("always_apply=False, ", "") for x in T if x.p))
except ImportError: # package not installed, skip
pass
except Exception as e:
LOGGER.info(f"{prefix}{e}")사용자는 T로 설정되어 있는 리스트에 원하는 증식 기법을 설정해줄 수 있다.
# Transforms
T = [
A.Blur(p=0.01),
A.MedianBlur(p=0.01),
A.ToGray(p=0.01),
A.CLAHE(p=0.01),
A.RandomBrightnessContrast(p=0.0),
A.RandomGamma(p=0.0),
A.ImageCompression(quality_lower=75, p=0.0),
]이후 해당 클래스에서 Compose내역을 확인하게 되는데 Compose 즉 기본 데이터 증식(변환)을 제외하고 사용자가 설정하는 T 리스트를 읽어 적용되는 증식 기법을 확인하게 된다.
# Compose transforms
self.contains_spatial = any(transform.__class__.__name__ in spatial_transforms for transform in T)
self.transform = (
A.Compose(T, bbox_params=A.BboxParams(format="yolo", label_fields=["class_labels"]))
if self.contains_spatial
else A.Compose(T)
)self.contains_spatial은 any내부의 for in문을 통해 T의 리스트중 spatial_transfoms와 동일한 이름을 가진 데이터 증식 기법이 있는지 확인하게 되고 존재한다면 contains_spatial값을 True로 반환하고 존재하지 않다면 False를 반환한다.
이후 self.transform에서 공간적 변환이 포함된 경우에는 BboxParams를 통해 labels 데이터셋에 있는 segmentation 픽셀의 값이나 Rounding Box의 위치 정보를 이미지와 동일하게 변환해준다. (공간적 증식 이후 픽셀값관련 데이터 증식 진행.)
이후 호출문으로 Compose내역에 따라 데이터 증식을 적용시킨 이후 labels 데이터를 반환한다.
def __call__(self, labels):
"""Generates object detections and returns a dictionary with detection results."""
if self.transform is None or random.random() > self.p:
return labels
if self.contains_spatial:
cls = labels["cls"]
loc = labels["loc"]
action = labels["action"]
if len(cls):
im = labels["img"]
labels["instances"].convert_bbox("xywh")
labels["instances"].normalize(*im.shape[:2][::-1])
bboxes = labels["instances"].bboxes
concatenated_labels = np.concatenate([cls[:, None], loc[:, None], action[:, None]], axis=1)
# TODO: add supports of segments and keypoints
new = self.transform(image=im, bboxes=bboxes, class_labels=concatenated_labels) # transformed
if len(new["class_labels"]) > 0: # skip update if no bbox in new im
labels["img"] = new["image"]
transformed_labels = np.array(new["class_labels"])
labels["cls"] = transformed_labels[:, 0]
labels["loc"] = transformed_labels[:, 1]
labels["action"] = transformed_labels[:, 2:]
bboxes = np.array(new["bboxes"], dtype=np.float32)
labels["instances"].update(bboxes=bboxes)
else:
labels["img"] = self.transform(image=labels["img"])["image"] # transformed
return labels인덱스 영역에 대해서 이야기를 하자면 넘파이 형식으로 되어있는 2차원 행렬이 있는 상태를 기반으로 했을 때 다음과 같은 형태를 가지고 있다. transformed_lables가 2차원 행렬 형태이며 {0, 1, 2 : }는 각각에 대한 정보를 가지고 있는 형태.
 |  |
객체검출 외 분할작업과 추가적으로 위치와 후미등 상태 여부도 파악하는 action의 경우 transformed_labels에 넘파이 형태로 넣은 다음 인덱스 형태로 적용시켰으나 원본 코드에서는 Rounding Box정보와 클래스의 정보만 있기에 바로 적용시킨 것을 확인할 수 있다.
if self.transform is None or random.random() > self.p:
return labels
if self.contains_spatial:
cls = labels["cls"]
if len(cls):
im = labels["img"]
labels["instances"].convert_bbox("xywh")
labels["instances"].normalize(*im.shape[:2][::-1])
bboxes = labels["instances"].bboxes
# TODO: add supports of segments and keypoints
new = self.transform(image=im, bboxes=bboxes, class_labels=cls) # transformed
if len(new["class_labels"]) > 0: # skip update if no bbox in new im
labels["img"] = new["image"]
labels["cls"] = np.array(new["class_labels"])
bboxes = np.array(new["bboxes"], dtype=np.float32)
labels["instances"].update(bboxes=bboxes)
else:
labels["img"] = self.transform(image=labels["img"])["image"] # transformed
return labels위처럼 구현된 Albumentation 클래스는 같은 모듈의 v8_transforms 클래스를 통해 Mosaic, CopyPaste, RandomPerspective, 등과 함께 Compose 로 구성되어 반환되고 v8_transforms 클래스는 dataset.py의 YOLODataset클래스 내부의 build_transforms 함수에서 선언되어 구현된다.
def build_transforms(self, hyp=None):
"""Builds and appends transforms to the list."""
if self.augment:
hyp.mosaic = hyp.mosaic if self.augment and not self.rect else 0.0
hyp.mixup = hyp.mixup if self.augment and not self.rect else 0.0
transforms = v8_transforms(self, self.imgsz, hyp)
else:
transforms = Compose([LetterBox(new_shape=(self.imgsz, self.imgsz), scaleup=False)])
transforms.append(
Format(
bbox_format="xywh",
normalize=True,
return_mask=self.use_segments,
return_keypoint=self.use_keypoints,
return_obb=self.use_obb,
batch_idx=True,
mask_ratio=hyp.mask_ratio,
mask_overlap=hyp.overlap_mask,
bgr=hyp.bgr if self.augment else 0.0, # only affect training.
)
)
return transformsyaml
yaml은 YAML Ain't Markup Language로 마크업 단어가 아니라는 정직한 이름을 가지고 있다.
yaml은 기존의 xml이나 json처럼 역할은 같지만 보다 사용자 친화적임에 중점을 두고 있다.
기존의 xml이나 json은 중괄호 대괄호 등에 각각의 역할이 주어지는 반면 yaml은 들여쓰기 하나로 해결해주어 구조 파악 등에 도움을 주고 주석 추가 여부도 다양한 사람이 입문하기 좋은 역할을 하여 YOLO에서 쓰이는 것으로 추정된다.
json같은 경우 labels의 역할도 이미지의 경로와 함께 저장하여 특정 YOLO모델에서 쓰이나 yaml을 사용하는 모델의 대부분인 것은 편의성과 기존 라이브러리 호출에 있어 용이하기 때문에 yaml을 주로 사용한다.
데이터셋의 입력 사이즈의 경우 ultralytics/cfg/default.py에서 설정할수 있다.(명령행인자로 직접 줄 수도 있다.)
# Ultralytics YOLO 🚀, AGPL-3.0 license
# Default training settings and hyperparameters for medium-augmentation COCO training
task: segment # (str) YOLO task, i.e. detect, segment, classify, pose
mode: train # (str) YOLO mode, i.e. train, val, predict, export, track, benchmark
# Train settings -------------------------------------------------------------------------------------------------------
model: # (str, optional) path to model file, i.e. yolov8n.pt, yolov8n.yaml
data: # (str, optional) path to data file, i.e. coco8.yaml
epochs: 100 # (int) number of epochs to train for
time: # (float, optional) number of hours to train for, overrides epochs if supplied
patience: 100 # (int) epochs to wait for no observable improvement for early stopping of training
batch: 32 # (int) number of images per batch (-1 for AutoBatch)
imgsz: 640 # (int | list) input images size as int for train and val modes, or list[w,h] for predict and export modes해당 모듈을 들여다보면 imgsz라는 변수가 존재하는데 해당 자료형에는 하나의 int형 변수와 list를 넣을 수 있다.
int형 변수를 넣게 된다면 해당 설정한 값이 가장 큰 치수를 기준으로 기존의 이미지의 크기를 변경하여 데이터셋을 구성하고 list 자료형을 넣게 된다면 해당 리스트에 맞게 규격을 맞춰준다.
예시를 들어 원본 1280720에 대해 imgsz를 640으로 넣는다면 데이터셋은 640360으로 이미지를 전처리하여 구성한다.
imgsz를 리스트 형태로 [640*480]으로 구성한다면 원본 이미지가 해당 규격(w,h)에 맞게 설정된다.
만일 이미지의 크기를 정사각형 형태로 640x640으로 구성하고 싶다면 리스트를 [640x640]으로 입력하여도 가능하지만 또 다른 변수 rect를 False에서 True로 변환시켜주는 방법도 있다 해당 변수가 True라면 640으로 입력하여도 정사각형 형태로 변환한다.
rect: False # (bool) rectangular training if mode='train' or rectangular validation if mode='val```