# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv10 object detection model. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nagent: 2 #number of total
nloc: 5 #number of locations
nact: 4 #number of actions
nc: [2,5,4] # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
s: [0.33, 0.50, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Multi_v10Segment, [nc, 32, 256]] # Detect(P3, P4, P5)multitask에 대한 YOLO model 구조도 yaml파일
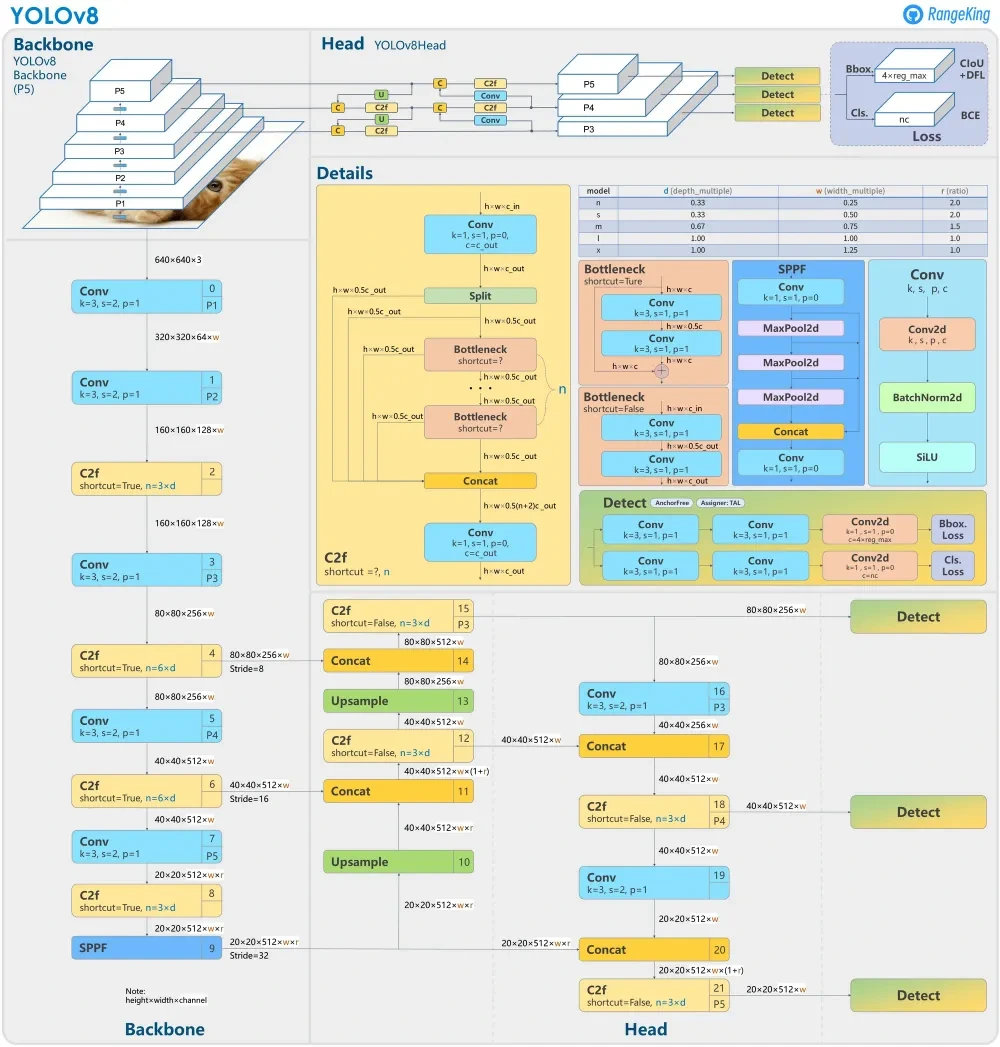
Backbone : 모델을 사용할 때 사전에 학습되어있는 딥러닝 모델에서 특징을 추출할 때 사용되는 기반 신경망 구조.
Backbone영역에 들어가는 Layer 목록
< Conv, C2f, SPPF>
Conv(Convolution Layer)
합성곱 레이어로 이미지의 특징(feature)을 추출하는 기초 레이어.
[ k (kernel) : 커널 크기, s (stride) : 스트라이드, p (pading) = 패딩 ]
kernel에 들어가는 값들에 대해서는 초회차에 무작위로 생성된 이후 다음 학습에 대해 최적화된다.
Conv Layer는 크게 Conv2d, BatchNorm2d, SiLU로 구성되어 있다.
Conv2d
합성곱을 진행하는 파트로 사진의 원본 이미지 혹은 합성곱이 진행된 특성 맵을 입력으로
받아 합성곱을 진행하여 출력으로 내보낸다.
BatchNorm2d
Conv2d로 진행된 특성 맵을 입력으로 받고 각 채널에 대하여 평균과 분산을 계산한 후 정규화를 진행한다.
이후 정규화 된 값에 특정 Scale과 이동 값을 각각 곱하고 더한 이후 특성 맵을 출력으로 내보낸다.
(미니배치 단위로 정규화를 진행하여 Batch + Norm으로 이름이 지어졌다. 2D는 차원(이미지에 대한.))
SiLu
활성화 함수 중 하나로 특성 맵을 입력으로 받아 활성화 값을 곱해준 이후 출력으로 특성맵을 내보낸다.
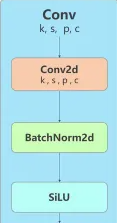
Conv
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
#c1 : 입력 채널, c2 : 출력 채널, k : kernel_size, s : stride, p : padding, g : group, d : dilation(필터 간격), act = bias
#default_act는 활성화 함수
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
#BatchNorm2d 노드가 bn으로 저장
self.bn = nn.BatchNorm2d(c2)
#act == True이면 default_act 사용, 아니라면 act로 명시된 활성화함수를 사용. act에 ReLU를 사용하면 ReLu활성화 함수 사용.
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))Conv2
class Conv2(Conv):
"""Simplified RepConv module with Conv fusing."""
#c1 : 입력 채널, c2 : 출력 채널, k : kernel_size, s : stride, p : padding, g : group, d : dilation(필터 간격), act = bias
#Conv를 상속하여 대부분의 파라미터 값을 이어 받는다.
def __init__(self, c1, c2, k=3, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__(c1, c2, k, s, p, g=g, d=d, act=act)
self.cv2 = nn.Conv2d(c1, c2, 1, s, autopad(1, p, d), groups=g, dilation=d, bias=False) # add 1x1 conv
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor.
두 개의 합성곱(conv와 cv2)의 결과를 더한 이후 활성화 함수를 적용."""
return self.act(self.bn(self.conv(x) + self.cv2(x)))
def forward_fuse(self, x):
"""Apply fused convolution, batch normalization and activation to input tensor.
병합된 단일 합성곱의 결과를 활성화 함수에 전달 ->forward와 차이점 : """
return self.act(self.bn(self.conv(x)))
def fuse_convs(self):
"""Fuse parallel convolutions.
병렬 합성곱(conv, cv)을 병합하여 최적화하고 병합 이후 forward_fuse만 수행 -> 연산량 감소 효과"""
w = torch.zeros_like(self.conv.weight.data)
i = [x // 2 for x in w.shape[2:]]
w[:, :, i[0] : i[0] + 1, i[1] : i[1] + 1] = self.cv2.weight.data.clone()
self.conv.weight.data += w
self.__delattr__("cv2")
self.forward = self.forward_fuse해당 코드를 보면 Conv2와 Conv 클래스 내부에 활성화 함수를 적용시키는 것을 확인할 수 있는데 위 클래스를 각 파트별로 분해시킨 것이 Conv과 Conv2 블록이다. 사용자가 편하게 볼 수 있도록 분할하여 그린 것으로 추정.
C2f(Coordinates-To-Features)
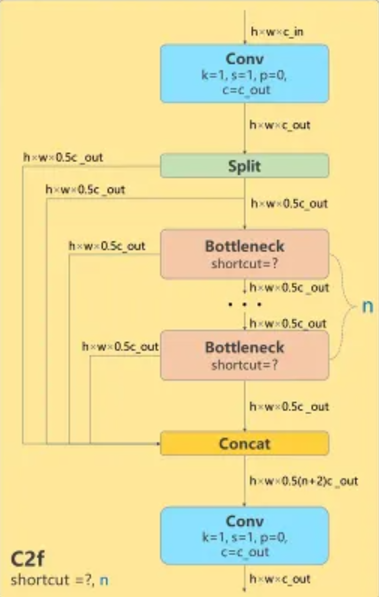
특성맵 처리와 성능 향상 레이어.
multi-scale object detection에 대한 성능을 상향.
Conv, Split, Bottleneck, Concat 블록으로 이루어져 있다
Conv(Convolution Layer)
이전의 k, s, p에 이어 c가 새로 생겼는데 이는 c_out으로 출력 채널의 수를 의미.
코드의 클래스에서는 c2라는 파라미터 이름으로 들어가 있다.
(특성 맵들이 서로 다른 병)
Split
특성 맵 전체를 받아 5 : 5 비율로 특성 맵을 분리시켜주는 블록.
전체 특성 맵(차원)이 128이면 64 : 64로 특성맵을 분리시켜 출력한다.
Split이후 라에서 h w 0.5c_out으로 표현되는 것을 확인 할 수 있다.
C2f의 일부 레이어에서 n = 6d, n = 3d로 나와있는 것이 있는데
이는 후의 bottleneck의 횟수를 정하는 변수이다.
Bottlenect
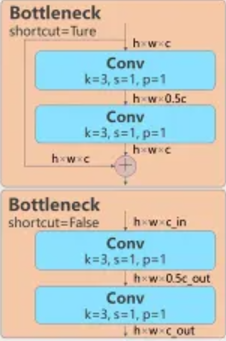
특성 맵 처리를 담당하는 블록.
입력 특징 맵을 압축하고 확장하는 방식을 통해 연산 결과를 병합한다.
내부 shortcut이라는 파라미터를 확인할 수 있는데 이는 Bottleneck 블록을 수행할 때 사용하는 파라미터로 shortcut이 True이면 입력 값을 따로 보관한 Conv 블록을 거친 특성맵과 Concat블록에서 합쳐지고(이어짐) shortcut이 False면 원본을 보관하지 않고 바로 Conv 블록을 거쳐 특성 맵을 출력한다.
처음 Conv 블록에서 채널 수를 축소하여 출력하는 이유는 모델의 계산에 있어 간결하게 하기 위함이며 불필요하다고 판단되는 특성들을 줄이고 중요하다고 판단되는 특징맵의 수를 늘리는 작업을 수행한다.
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))Backbone의 4번 6번 9번 레이어를 보게 된다면 같은 출력값을 가지고 있으나 Concat으로 연결되며 Stride가 추가적으로 적힌 블록도를 확인할 수 있다.

해당 블록도에서 Stride는 일반적인 의미로 사용되는(필터간 간격) Stride가 아닌 다운샘플링이 진행된 총 비율로 4번 레이어에서는 총 8배의 다운샘플링이 진행되었다는 의미이다.
원본 이미지 640640에 대해서 1/2의 다운샘플링 과정이 총 8배가 되었다는 의미로 Conv레이어를 총 3번 거치며 22*2에 대해 640 / 8 = 80이 출력되었다는 것을 확인시켜주는 보조의 의미를 가진다.
이후에 각각 Conv 레이어를 거치며 Stride의 값이 222*2로 6번 레이어에서는 총 16배의 다운샘플링이 진행되었고 9번 레이어에서는 32배의 다운샘플링이 진행되었다는 것을 확인할 수 있다.
6번 레이어 -> 640 / 16 = 40, 8번 레이어 -> 640 / 32 = 20
from ultralytics import YOLO
import multiprocessing
from ultralytics import settings
import matplotlib.pyplot as plt
model = YOLO("yolov10s-seg.yaml")
print("4번 레이어")
print(model.model.model[4])
print("6번 레이어")
print(model.model.model[6])
print("9번 레이어")
print(model.model.model[9])
import torch
model = YOLO("yolov10s-seg.yaml")
dummy_input = torch.randn(1, 3, 640, 640)
x = dummy_input
for idx, layer in enumerate(model.model.model):
x = layer(x)
if idx in [4, 6, 9]: # C2f layers
print(f"Layer {idx}: Output shape {x.shape}")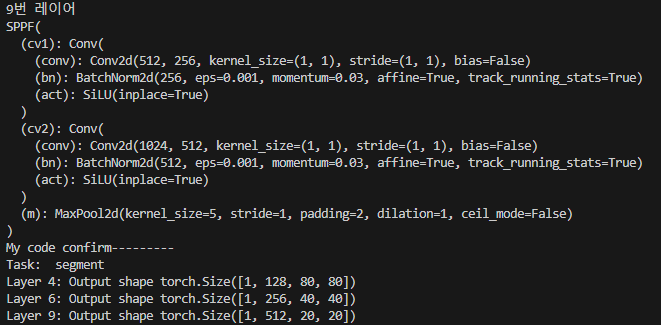
Concat
여러개의 레이어를 하나로 합치는 과정으로 같은 채널 크기의 특성맵들을 입력으로 받아 특성맵끼리 이어 하나의 특성 맵을 출력으로 내보낸다.
SPPF(Spatial Pyramid Pooling - Fast)
Conv, MaxPool2d, Concat 블록으로 이루어진 블록.
여러 크기의 특성들에(작은 특성, 중간 특성, 큰 특성) 대해 정보를 결합하여 일반화 된 특성 맵을 제공.
MaxPool2d : Pooling작업을 수행할 때 사용하는 기법
YOLO에서는 AveragePooling이 아닌 MaxPooling기법을 사용함.
Pooling작업을 수행하면 사이즈가 달라져서 Concat 블록에서 합칠 수 없다고 생각할 수 있지만 코드 내부에서 진행할 때 padding작업을 진행해줌으로서 크기에 대한 문제를 해결한다.
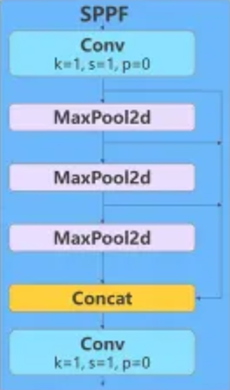
class SPPF(nn.Module):
"""Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher."""
def __init__(self, c1, c2, k=5):
"""
Initializes the SPPF layer with given input/output channels and kernel size.
This module is equivalent to SPP(k=(5, 9, 13)).
레이어 초기화 등등. k는 MaxPooling을 진행할 때 사용하는 커널의 크기.
"""
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
"""Forward pass through Ghost Convolution block. 순전파"""
y = [self.cv1(x)]
y.extend(self.m(y[-1]) for _ in range(3))
return self.cv2(torch.cat(y, 1))
class SPPF(nn.Module):
"""Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher."""
def __init__(self, c1, c2, k=5):
"""
Initializes the SPPF layer with given input/output channels and kernel size.
This module is equivalent to SPP(k=(5, 9, 13)).
레이어 초기화 등등. k는 MaxPooling을 진행할 때 사용하는 커널의 크기.
"""
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
"""Forward pass through Ghost Convolution block. 순전파"""
y = [self.cv1(x)]
y.extend(self.m(y[-1]) for _ in range(3))
return self.cv2(torch.cat(y, 1))관련 글
https://github.com/ultralytics/ultralytics/issues/9042
https://github.com/ultralytics/ultralytics/issues/15596
https://blog.roboflow.com/what-is-yolov8/#anchor-free-detection
https://github.com/ultralytics/ultralytics/issues/3678
https://github.com/ultralytics/ultralytics/issues/13441
