논문의 전체적인 내용은 YOLO model을 사용하여 Multi-Task작업을 수행하는 것이다.
Multi-Task란 직역하면 다중 작업을 의미하며 목적은 3개의 model을 사용하여 진행할 작업을 하나의 model 내에서 작동하도록 하는 것이다.
기본적으로 YOLO model은 하나의 작업(Classification, Detect, Segmentaion, Pose 등)을 목표로 만들어진 모델로 두가지 이상의 작업을 수행하기 위해서는 각각의 작업을 수행하는 모델을 학습시킨 이후 얻은 데이터를 조합하여 최종적인 알고리즘을 구현한다.
이번 논문에서는 하나의 YOLO model에서 여러개의 작업을 수행하여 연산량과 모델의 전반적인 크기를 줄이는 방식을 목표로 한다.
Abstract
-
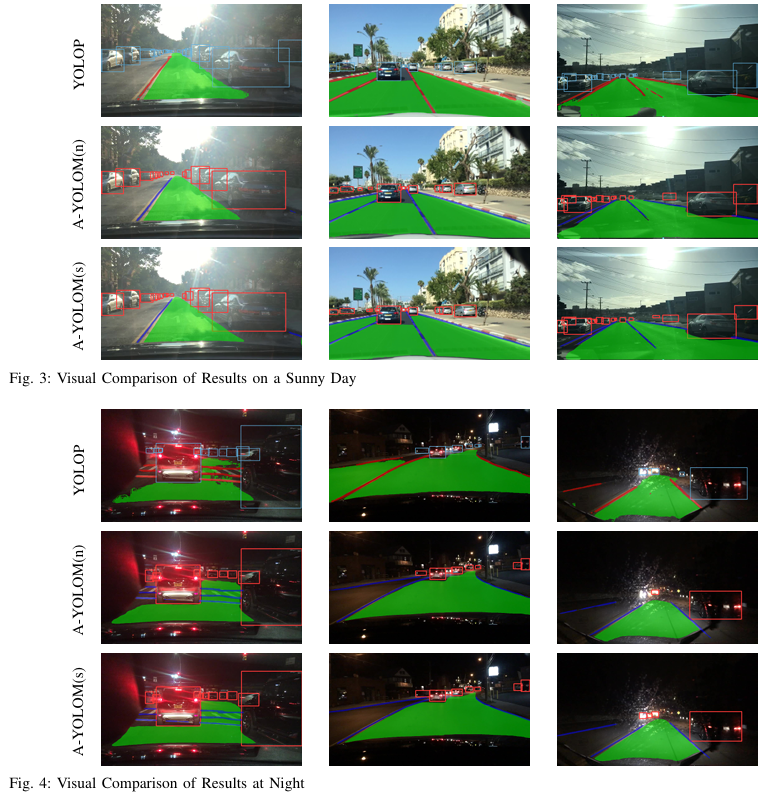
자율주행 관련 연구에서 High precision, lightweights, real-time responsiveness는 필수 요건으로 Detection, Segmentation작업을 동시에 처리하는 A-YOLOM 모델을 설계하였다.
-
Neck과 Backbone 사이의 특징에 대해 능동적(논문에서는 적응적 연결로 소개-adaptively concatenates)으로 특징을 연결하여 학습 가능한 매개변수(가중치)를 사용하고 모든 Segmentation 작업에 대해 동일한 손실 함수를 사용한다.
ㄴ 동일한 손실 함수를 사용한다는 것은 2개의 Segmentation model로 구성되어 손실함수 선택에 대한 고민을 제거하는 것과 동시에 일관된 학습으로 전체적인 모델들에 대한 안전성을 보장함. -
Segmentation Head를 Convolutional layer로만 구성되게 하여 파라미터 수와 추론 시간을 줄였다.
-
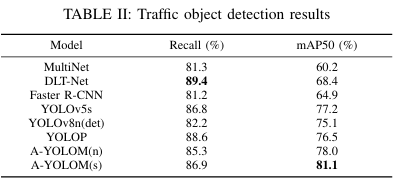
BDD100K dataset을 사용하여 기존 모델과 비교하여 긍정적인 결과를 이끌어 내었다.
Introduction
ADS(Autonomous driving systems)은 딥러닝의 발전과 함께 집중을 받았고 lane line segmentation, Drivable area segmentation, Object detection 3개의 작업은 ADS에서 핵심 요소로 평가된다.
카메라로 위 3개의 작업을 수행하는 것은 여러가지 자원과 비용면에서 이점이 있으며 자율 주행이라는 특성상 위 작업은 30 FPS를 초과하는 값을 유지하는 것을 기본으로 한다.
경량 모델과 높은 정밀도를 목표로 하는 작업은 Fast R-CNN(two-stage 방식)과 YOLO(one-stage 방식)에서 진행되었고 YOLO에서는 Object Detection에 중점을 두어 발전해 Segmentation Head가 존재하나 사용되는 손실함수나 평가 방식(loss값 계산)들은 Object Detection작업에 최적화된 값들을 사용해왔다. YOLOv8은 하나의 모델에 대해 하나의 작업만을 구현할 수 있으며 여러 모델을 이용하여 알고리즘을 구현하는 것은 학습 시간과 추론 시간 등의 문제점이 존재한다.
Segmentation 작업 특징
lane line segmentation작업과 Drivable area segmentation에 있어 Drivable area segementation은 이미지의 넓은 영역을 차지하고 주변 상황과 같이 판단하여 High level feature을 필요로 하지만 lane line segmentation은 특징이 길고 단순하게 구성되어 있어 low level feature를 필요로 한다. 이 두 작업을 동시에 하기에는 서로의 정확도에 있어 악영향을 미친다.

Object detection과 Imege segmentation에 대해서도 Detect작업은 Grid Cell 방식을 사용하고 NMS를 통해 결과를 내보내고 Segmentation 작업은 pixel 단위에서 작동하도록 Decoder를 사용하는 방식을 사용한다.
중점은 두 작업 모두 이미지에서 특징을 추출하는 Backbone단계의 구조는 공유할 수 있는 형태를 가진다는 것이다.
해당 논문에서는 하나의 Backbone과 3개의 Neck, Head를 가지는 Architecture를 사용한다.
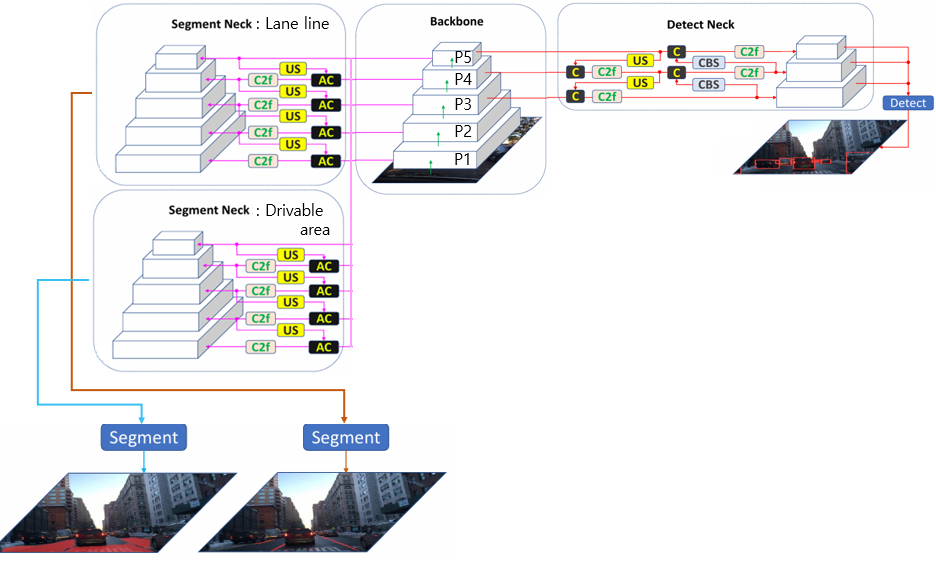
하나의 Backbone에서 분할되어 나오는 여러개의 Neck사이에 능동적(P1, P2, P3, P4, P5 각 특징을 원하는 대로 Neck에 연결)으로 모듈을 적용하는 방식으로 하여 서로 다른 레벨의 특징을 연결할지 여부를 결정할 수 있다.
Methodology
A-YOLOM 모델은 Encoder-Decoder Architecture를 가진 one-stage 네트워크로 Encoder는 Backbone과 Neck로 구성되었으며 Decoder는 Head로 구성된다.
하나의 Backbone과 세 가지 작업을 위한 3개의 Neck, Head를 단일 모델로 통합한다.
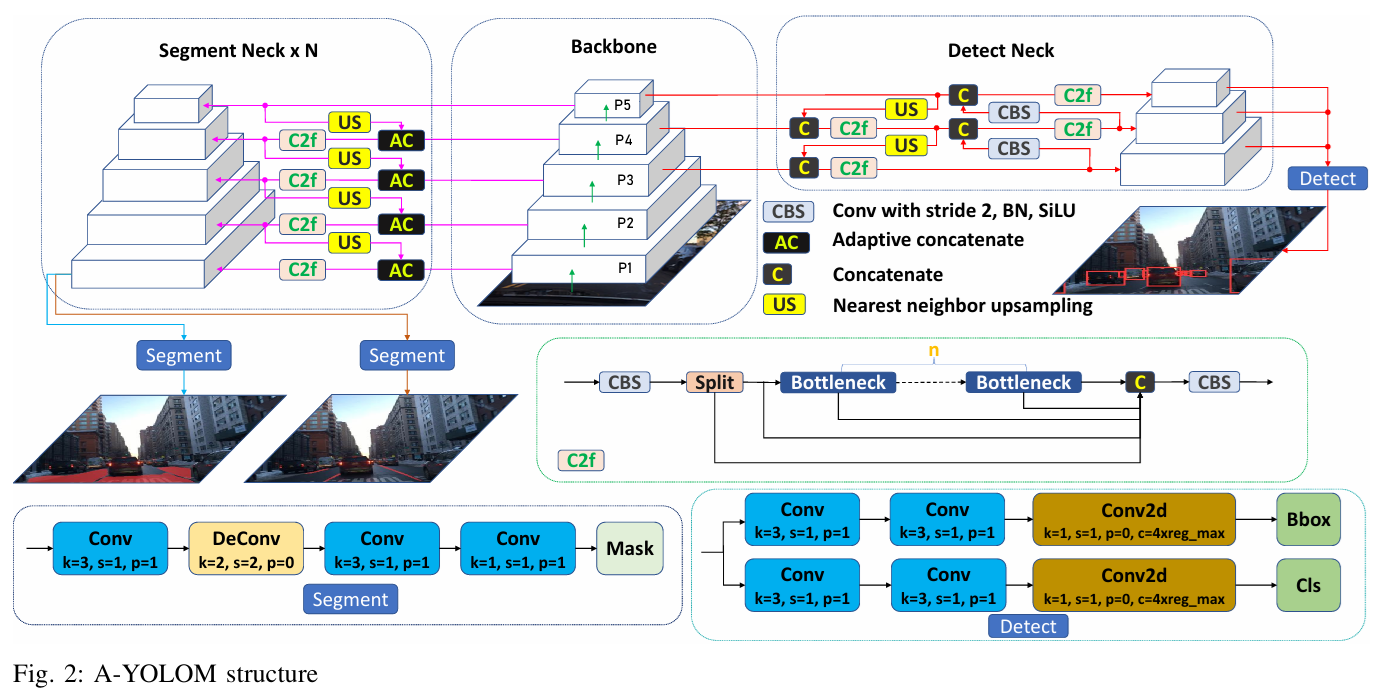
(N 값은 Neck의 수로 해당 논문에서는 2개를 의미한다.)
Encoder (Backbone_Neck)
Backbone
기존 YOLOv5에서 사용되던 Backbone인 SCP-Darknet53을 개선.
YOLOv8의 기초 Backbone과 동일하다.
Neck
3개의 Neck을 활용 { lane lines, drivable areas, object detection }
Neck의 구조는 동일하게 사용하나(그림의 N이 2) 각 목적이 다르게 사용되여 가중치의 값들은 상당히 다르게 진행.
Object Detection 작업의 경우 차량을 감지하여야 하므로 low-level feature보다는 high-level feature의 특징을 조합하여야 하므로 Backbone에서 P3~P5까지의 mid-level과 high-level들을 조합하여 사용하였고 이 과정에서 FPN을 포함하는 PAN구조를 채택하였다. PAN 구조를 사용함으로서 작은 객체와 큰 객체에 대한 정확도를 향상시킨다.
Image Segmentation 작업의 경우 low-level feature과 high-level feature정보를 모두 포함하도록 P1~P5까지의 특징들을 Backbone에서 불러온다. 하지만 lane line에서 high-level feature이 크게 의미가 없는 특징맵의 경우 Adaptive Concatenation Module(AC)을 통해 해당 Feature은 연결하지 않는 등의 작업으로 연산량을 줄이고 정확도를 향상시킨다.
Adaptive Concatenation Module의 알고리즘
 X라는 텐서에 대해 x[0]는 neck에서 Upsampling과정을 통해 확장된 특성맵을 의미하며 x[1]은 Backbone에서 확장된 특성맵과 동일 해상도의 특성맵을 Input으로 사용한다.
X라는 텐서에 대해 x[0]는 neck에서 Upsampling과정을 통해 확장된 특성맵을 의미하며 x[1]은 Backbone에서 확장된 특성맵과 동일 해상도의 특성맵을 Input으로 사용한다.
Output과정은 초기값 weight(5.0)을 기반으로 특성맵을 연결할지 말지에 대한 여부를 결정한다.
weight값은 sigmoid함수의 파라미터로 사용되어 해당 값이 0.5를 초과하게되면 두 특성맵을 결합하고 1*1 Convolution layer를 통과시켜 채널 수(차원)를 줄이는 과정을 수행한다. 0.5 이하의 값이 나오면 Neck 특성맵만을 C2f 에 통과시킨다.
5번 라인을 간단히 살펴보면 Conv는 Ultralytics에서 제공하는 함수를 의미하며 내부 파라미터는 차례대로 [입력 채널 크기, 출력 채널 크기, kernel size, stride]이다.
학습이 진행되며 weight값이 커져 sigmoid함수를 통과시킬 때 0.5가 넘게 되면 해당 특성맵을 연결하는 과정을 통해 lane line에서는 연결되지 않은 특성맵이 drivable area에서는 연결되는 등의 작업이 이루어질 수 있다.
해당 과정에서 Segmentaion의 Neck를 분리시킨 이유가 나온다. (하나이면 해당 과정에 의미가 약해진다.)
위 과정은 각 작업의 Neck과정에서 불필요한 연산을 줄이며 정확도를 높이게 된다.
- Detection과 Segmentation의 Neck 구조에서 가장 다른 점은 FPN에서 끝나는 Segmentation Neck과는 다르게 Detection Neck에서는 이를 포함하는 PAN network를 사용한다는 것인데 이유는 차량 객체의 경우 멀리 있을 때와 가까이 있을 때의 객체 크기에 상당한 차이를 보이는 반면 lane lines, drivable areas의 경우 멀리 있을 때와 가까이 있을 때의 차이가 크지 않아 민감하게 반응할 이유가 없기 때문에 연산량을 보존하고자 FPN에서 끝낸다. (개인적 의견 첨가)-
Decoder (head)
Backbone과 Neck에서의 작업을 처리하여 예측을 수행 2개의 Segment Head와 1개의 Detect Head를 사용
Head
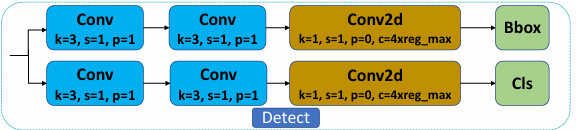 Detect Head는 YOLOv8의 기본 Head와 동일하다.
Detect Head는 YOLOv8의 기본 Head와 동일하다.
 Segmentation Head는 Conv레이어와 DeConv레이어로 이루어져 있는데 DeConv레이어는 Upsampling과 같은 역할로 해상도를 높이나 알고리즘 측면에서 다르다. Upsampling은 하나의 픽셀의 값을 복사하여 넓히거나 사이값을 넣어서 해상도 자체를 늘리는데 집중한다면 Deconv는 가중치를 포함하여 특성맵의 정보들을 파악하며 원본의 해상도와 객체의 경계면 정보들을 확보한다.
Segmentation Head는 Conv레이어와 DeConv레이어로 이루어져 있는데 DeConv레이어는 Upsampling과 같은 역할로 해상도를 높이나 알고리즘 측면에서 다르다. Upsampling은 하나의 픽셀의 값을 복사하여 넓히거나 사이값을 넣어서 해상도 자체를 늘리는데 집중한다면 Deconv는 가중치를 포함하여 특성맵의 정보들을 파악하며 원본의 해상도와 객체의 경계면 정보들을 확보한다.
 Segment Head의 알고리즘으로 특성맵을 받아 처음 출력 채널 수 32로 하여 중간 레이어의 채널 수를 고정한다.
Segment Head의 알고리즘으로 특성맵을 받아 처음 출력 채널 수 32로 하여 중간 레이어의 채널 수를 고정한다.
cv3(cv2(upsample(cv1(x)))을 거치면 해상도가 입력 특성맵의 최종적으로 2배 증가하게 된다.
- 입력 특성맵으로 사용하는 P1의 해상도 크기 기준 2배.
Loss Function
해당 모델에서 손실함수는 다음과 같이 정의된다.
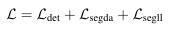
순서대로 Detect, Seg draivable area, Seg lane line 에 대한 손실이다.
객체 탐지(L_det)에서는 DFL loss(Distribution Focal Loss), BCE loss(Binary Cross Entropy), CIoU loss를 조합하여 계산하는데 각각 class, Bbox, Bbox를 계산하는데 사용된다. 위 방식은 YOLOv8의 일반적인 객체 탐지 방법과 동일한 방식이다.
Seg loss에 대해서는 아래와 같이 정의된다.
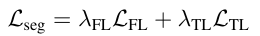 두 작업에 대한 공식은 동일하며 λ은 가중치로 바로 뒤에 나오는 L_FL과 L_TL에 대한 중요도를 가중치로 나타낸다. 해당 값은 하이퍼 파라미터로 지정하는 방식과 학습 도중 조정하는 방법이 있다.
두 작업에 대한 공식은 동일하며 λ은 가중치로 바로 뒤에 나오는 L_FL과 L_TL에 대한 중요도를 가중치로 나타낸다. 해당 값은 하이퍼 파라미터로 지정하는 방식과 학습 도중 조정하는 방법이 있다.
L_FL은 Focal loss를 의미하고 L_TL은 Tversky loss를 의미한다. ( Tversky loss는 Segmentation에서만 쓰이는 손실 함수로 명확히 설명되어있는 사이트를 찾지 못함.)
각 손실함수에 대한 역할에 대해서 간단히 집고 넘어가자면 Focal loss는 데이터 불균형과 데이터의 난이도에 따른 학습 정도(어느정도로 가중치를 민감하게 수정할지)를 조정하며 Tversky loss는 객체에 대한 경계면을 세세하게 구분하기 위한 손실함수이다.
Experiment
사용한 데이터셋 : BDD100K (자동차, 버스, 트럭 등의 객체들을 Vehicle로 통합)
평가 방식 : mAP50(객체 탐지), mIoU(Drivable area), IoU + Acc(lane line)
사용 장비 : Train 과정 RTX 4090 3개 - Val과정 GTX 1080 Ti GPU 1개로 명시
데이터 증식 기법 : Ultralytics 기본 데이터 증식 기법 사용.
실험 방식 : SGD optimizer, learning rate : 0.01, momentum : 0.937, weight decay : 0.0005, NMS : 0.6
- 3 Epoch까지는 워밍업으로 learning rate값등이 올라간 상태로 시작함. 이미지 사이즈 640*640
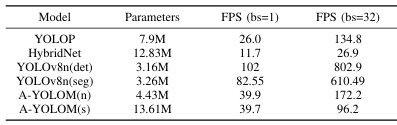
평가에 관련하여 multi-task관련 모델(평가를 비교할)들이 부족하여 객체 검출 모델과 영상 분할 모델들을 같이 사용하여 테스트하였다.