데이터를 볼 수록 성능이 향상되는 인공지능 : 머신 러닝
인공신경망 기술을 활용한 머신러닝 : 딥러닝
1.데이터
2.이상치, 결측치 처리
3.feature : x 데이터의 열들 engineering
4. 최적 모델 찾기
- 컴퓨터에게 명시적으로 프로그래밍하지 않고도, 데이터로부터 학습할 수 있게 한다.
명시적으로 프로그래밍한다? : 룰 기반으로 분류
머신러닝에서는 룰을 따로 표기하지 않고도 컴퓨터가 스스로 룰을 만들어가는 것!
learn from exprience E
some class of tasks T
performance measure P
작업 t에 대해 기준 p로 측정한 성능이 경험 e로 인해 향상되었다면 그 프로그램은 작업 t에 대해 기준p의 관점에서 경험 e로부터 배웠다고 말할 수 있다.
1. 어떠한 과제를 해결하는 과정에서
2.특정한 평가 기준을 바탕으로
3.학습의 경험을 쌓아나가는 프로그램
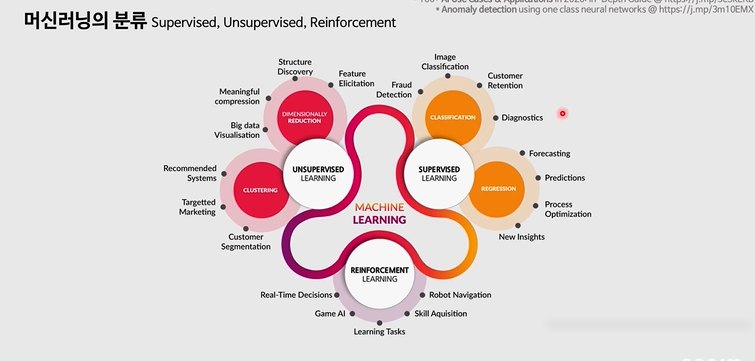
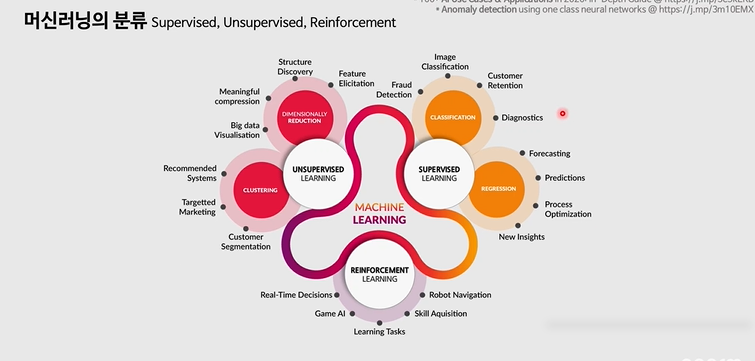
머신러닝의 3가지 분류
Supervised learning -> 데이터의 정답이 있는 경우 <지도 학습>
1-1. 연속형 값 numerical 나이 온도 가격 -> regression 회기 모델들
1-2. classification 정답이 categorical value인 경우
Unsupervised learning -> 정답이 없는 경우의 학습
2-1. 군집화 clustering
2-2. 차원축소 dementionally reduction
Reinforcement learning -> 강화 학습
계열별 사용해야 하는 모델
99%가 이상이 없고 1%만 이상이 있다면... 분류력이 안 좋음.. 이럴때는 군집 분석이 필요함!! --> anomally detection
supervised (지도 학습, 교사 학습) -> 답을 정함 => 1. numerical(by 회귀 regression, 수치 자체적으로 의미가 있음), 2. categorical -> classification
unsupervised (비지도 학습) -> 1. 군집화 clustering, 2. 차원 축소
UNSUPERVISED LEARNING : Input data 속에 숨어있는 규칙성을 찾기 위해 학습
모델을 복잡하게 만드는 요인 : capacity, 차수, layer(인공신경망), 학습 시간
capacity의 극대화 => overfitting 발생 => generalization 증가 => 새로운 데이터에 잘 대응하지 못함


https://3months.tistory.com/414?category=756964 : 딥러닝에서 클래스 불균형을 다루는 방법
https://www.tensorflow.org/tutorials/structured_data/imbalanced_data?hl=ko#oversample_the_minority_class : 불균형 데이터 분류
