Model's Capacity : 현실 세계의 복잡성을 모델이 얼마나 잘 포함하고 있는가
-
학습 : 실제 정답과 예측 결과 사이의 오차 (loss, cost, error)를 줄여자가는 최적화 과정
-
overfitting : 너무 complex하게 딱 맞음
x-data에 의해 결정되는 y data
-
x - data : 독립 변수 : feature(x데이터를 부르는 말), attribute, dimension, column
-
y - data : 종속 변수 : label(분류),taret data (회귀, 분류)
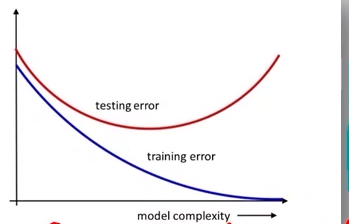
- x축 : model을 복잡하게 만드는 것 : capacity / 차수 / layer 개수 / 학습시간
- y축 : error / loss / cost
오버피팅이 나기 시작했다 : training data의 error는 점점 줄어드는 반면, 처음엔 새로운 data에 대하여 error가 많다가, 학습을 할 수록 점점 떨어지다가 계속 학습을 진행하면 오히려 높아짐

generalization 일반화 error : 새로운 data에 대한 error
일반화 성능 : over-fitting이 나지 않을 수록 높게 평가되는 성능

Kyunghee univ. IE 21