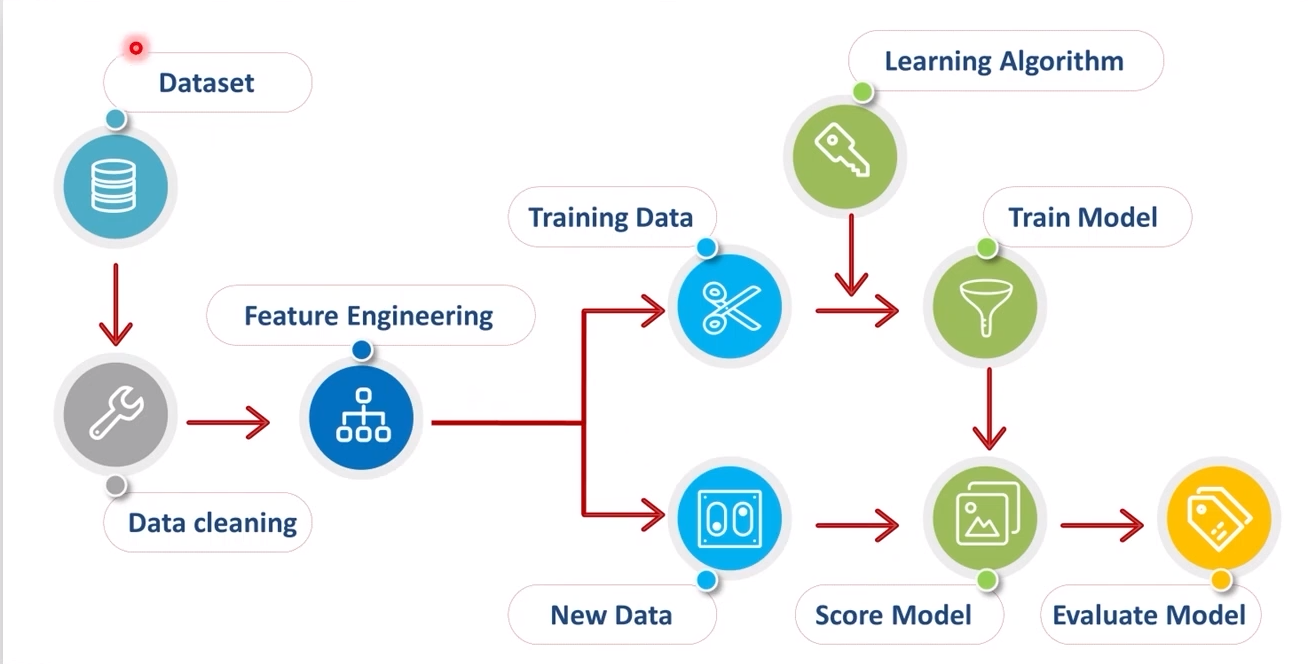
Feature Engineering
- 넓은 의미의 feature : 데이터 자체의 특징
- 좁은 의미의 feature : data의 하나의 column
- feature selection / extraction
- one/hot encoding, min-max scaling...
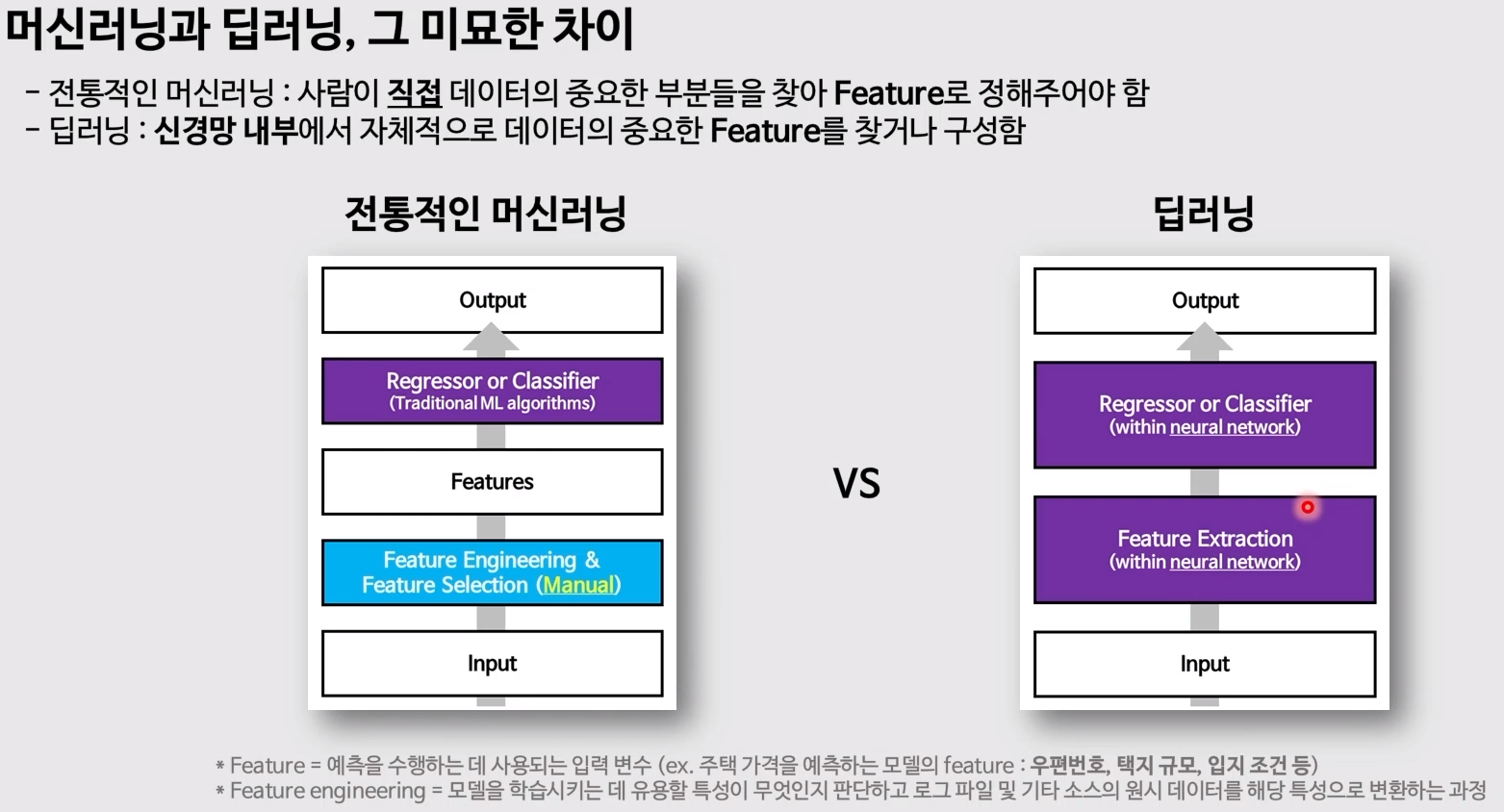
- 딥러닝에서는 컴퓨터가 대신 전처리를 해줌
- 결측치 처리, 이상치 제거... 정도는 인간이 해주어야 함
전통적인 머신러닝 : hyper parameter 설정이 필요, 여러 실험을 통해 hyper parameter 수정이 가능, feature importance를 통해서도 수정 가능
딥러닝 : 코드에 data를 넣어주면 됨, model tuning 시 문제가 되는 부분이 확실하지 않음
장점
- 선입견이 배제된다.
- 손이 덜 들어간다.
단점
- data가 많이 필요하다. => 정답까지 있는 data가 많이 필요하다.
- 데이터의 양을 뻥튀기 가능 => data augmentation 데이터 증강
- 왜 그런 예측을 했는가에 대한 투명한 이해, 설명이 어려움
- 머신러닝 : permutation importance (열을 1개 뒤섞었을 때 정확도의 차이)
permutation : 순열- 딥러닝 : Lime
- 딥러닝 모델이 본래 정형 data였던 data를 대상으로는 전통적인 머신러닝 보다는 성능이 떨어짐 => 정형 데이터를 위한 TabNet

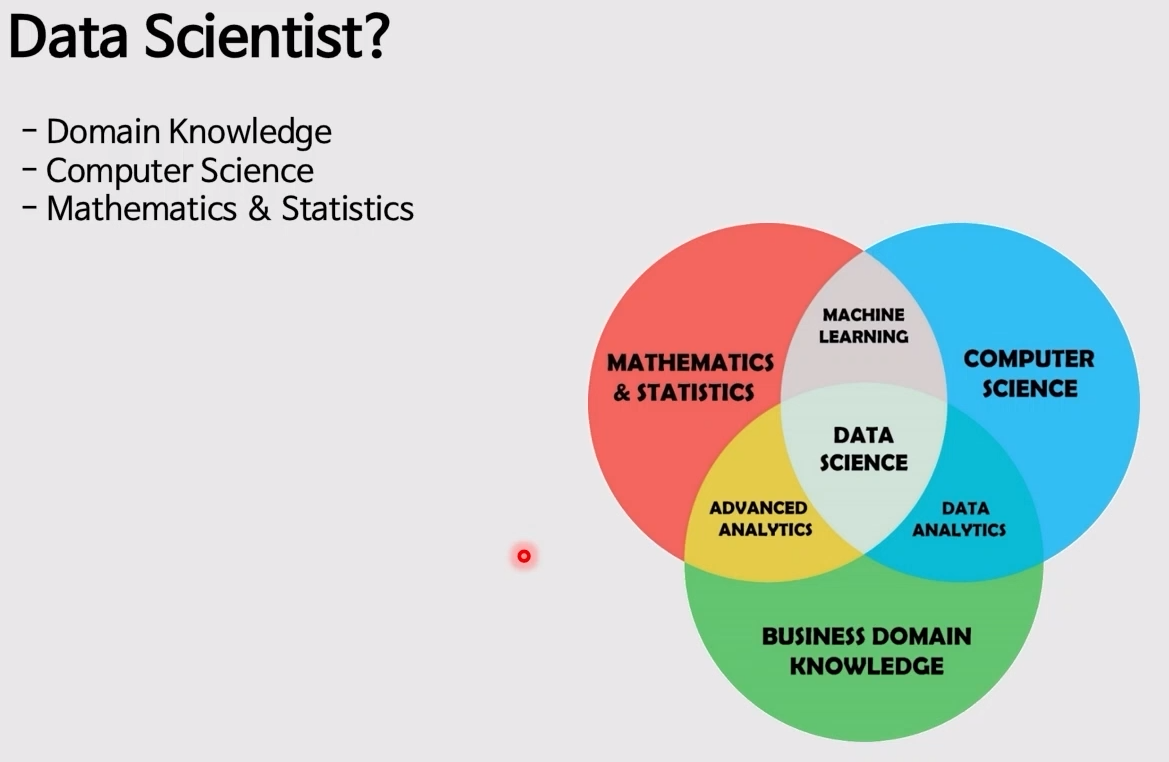
- 다양한 가설을 세우고, 통계 기법을 활용해 현상을 설명하거나, 머신러닝 / 딥러닝 기법을 활용해 분석을 진행하는 직군
data scientist : Communication 능력이 가장 중요! => 혼자서 하는 일에는 한계가 있음
Computer Science : python => 자료구조 or 알고리즘, 코딩 테스트 준비
선형대수학, 미분적분학 강의


- tf / idf => embedding
- statistic 110 : 확률에 관해!
- 3BlueBrown - 영어로 보는 것을 추천!!
Data Engineer
- 분석 전의 데이터를 준비해주는 모든 과정에 참여하는 직군
- Database에 관한 지식이 중요, Sql
- Data 보관!
면접에 관한 책!

Tableau
- BI 중 Tableau : data 기반의 자동 시각화
- Power BI
Machine learning Researcher
- 논문 읽고 쓰는 능력이 중요
논문에 관한 링크 1,3 번째 중요!

추천 강의


=> 짧은 강의

Kyunghee univ. IE 21