
다수의 데이터프레임(dataframe) 또는 시리즈(Series)를 결합하거나 key값을 활용해 매칭하는 방법
1. DataFrame 붙이기 pd.concat()
pd.concat()함수는 데이터프레임을 말그대로 물리적으로 이어 붙여주는 함수로, pd.concat(데이터프레임리스트)로 사용한다.
import pandas as pd
df1 = pd.DataFrame({'a':['a0','a1','a2','a3'],
'b':['b0','b1','b2','b3'],
'c':['c0','c1','c2','c3']},
index = [0,1,2,3])
df2 = pd.DataFrame({'a':['a2','a3','a4','a5'],
'b':['b2','b3','b4','b5'],
'c':['c2','c3','c4','c5'],
'd':['d2','d3','d4','d5']},
index = [2,3,4,5])
print(df1, '\n')
print(df2)
'''
[Output]
a b c
0 a0 b0 c0
1 a1 b1 c1
2 a2 b2 c2
3 a3 b3 c3
a b c d
2 a2 b2 c2 d2
3 a3 b3 c3 d3
4 a4 b4 c4 d4
5 a5 b5 c5 d5
'''pd.concat()의 옵션
두 데이터프레임은 행인덱스와 열인덱스가 다르다.
result1 = pd.concat([df1,df2])
print(result1)
[Output]
a b c d
0 a0 b0 c0 NaN
1 a1 b1 c1 NaN
2 a2 b2 c2 NaN
3 a3 b3 c3 NaN
2 a2 b2 c2 d2
3 a3 b3 c3 d3
4 a4 b4 c4 d4
5 a5 b5 c5 d5defalut값으로 axis=0이 적용되기 때문에 행방향(위아래)으로 데이터프레임을 이어붙인다. 그런데 df1에는 d열이 없으므로 NaN값이 채워진 것을 알 수 있다.
그냥 이어붙이니 행 인덱스번호도 그대로 가져왔기때문에, ignore_index=True을 줘서 인덱스를 재배열 할 수 있다.
result2 = pd.concat([df1,df2], ignore_index=True)
print(result2)
[Output]
a b c d
0 a0 b0 c0 NaN
1 a1 b1 c1 NaN
2 a2 b2 c2 NaN
3 a3 b3 c3 NaN
4 a2 b2 c2 d2
5 a3 b3 c3 d3
6 a4 b4 c4 d4
7 a5 b5 c5 d5 열방향axis=1(좌우)으로 이어붙이기
result3 = pd.concat([df1,df2],axis=1)
print(result3)
[Output]
a b c a b c d
0 a0 b0 c0 NaN NaN NaN NaN
1 a1 b1 c1 NaN NaN NaN NaN
2 a2 b2 c2 a2 b2 c2 d2
3 a3 b3 c3 a3 b3 c3 d3
4 NaN NaN NaN a4 b4 c4 d4
5 NaN NaN NaN a5 b5 c5 d5 pd.concat()함수는 또한 default로 outer를 가진다.
이어붙이는 방식을 outer는 합집합, inner는 교집합을 의미한다.
그러면 이번에는 inner옵션을 줘서 이어붙일 두 데이터에 모두 존재하는 행인덱스만 가져와보자.
result3_in = pd.concat([df1,df2],axis=1, join='inner') #열방향(axis=1), 교집합(inner)
print(result3_in)
[Output]
a b c a b c d
2 a2 b2 c2 a2 b2 c2 d2
3 a3 b3 c3 a3 b3 c3 d3 시리즈를 데이터프레임에 붙이기
시리즈 객체도 마찬가지로 이어붙이기가 가능하다.
시리즈 객체를 생성할때 주는 옵션 name이, 시리즈가 데이터프레임에 결합되었을 떄의 열이름이 된다.
sr1 = pd.Series(['e0','e1','e2','e3'], name = 'e')
sr2 = pd.Series(['f0','f1','f2'], name = 'f', index = [3,4,5])
sr3 = pd.Series(['g0','g1','g2','g3'], name = 'g')
result4 = pd.concat([df1,sr1], axis=1)
print(result4, '\n')
result5 = pd.concat([df2,sr2], axis=1)
print(result5, '\n')
[Output]
a b c e
0 a0 b0 c0 e0
1 a1 b1 c1 e1
2 a2 b2 c2 e2
3 a3 b3 c3 e3
a b c d f
2 a2 b2 c2 d2 NaN
3 a3 b3 c3 d3 f0
4 a4 b4 c4 d4 f1
5 a5 b5 c5 d5 f2 sr2의 name은 f, index는 3,4,5로 지정해줬으므로, 해당 행인덱스에 맞춰 이어붙여졌음을 볼 수 있다.
시리즈 끼리 붙이기
result6 = pd.concat([sr1, sr3], axis = 1) #열방향 연결, 데이터프레임
print(result6)
print(type(result6), '\n')
result7 = pd.concat([sr1, sr3], axis = 0) #행방향 연결, 시리즈
print(result7)
print(type(result7), '\n')
[Output]
e g
0 e0 g0
1 e1 g1
2 e2 g2
3 e3 g3
<class 'pandas.core.frame.DataFrame'>
0 e0
1 e1
2 e2
3 e3
0 g0
1 g1
2 g2
3 g3
dtype: object
<class 'pandas.core.series.Series'> sr1에는 인덱스를 지정해주지 않았으므로 자동으로 0,1,2,3이 들어갔을 것이다. 그래서 바로 열방향 concat이 되었고,
두 시리즈를 행방향(axis=0)연결을 하게되면 여전히 시리즈객체로 반환됨을 알 수 있다.
2. 데이터프레임 병합 : pd.merge()
merge()함수는 두 데이터프레임을 각 데이터에 존재하는 고유값(key)을 기준으로 병합할때 사용한다.
pd.merge(df_left, df_right, how='inner', on=None)이 default이다.
아무 옵션을 적용하지 않으면, on=None이므로 두 데이터의 공통 열이름(id)을 기준으로 inner(교집합) 조인을 하게 된다.
merge_inner = pd.merge(df1, df2)
merge_inner이번엔 outer옵션을 줘서 id를 기준으로 합치되, 어느한쪽에라도 없는 데이터가 있는 경우 NaN값이 지정된다.
merge_outer = pd.merge(df1,df2, how='outer',on='id')
merge_outer왼쪽에 입력한 데이터프레임 기준(how='left')으로, 각각의 key값에 해당하는 열을 지정해주자.
merge_left = pd.merge(df1,df2, how='left', left_on='stock_name', right_on='name')
merge_left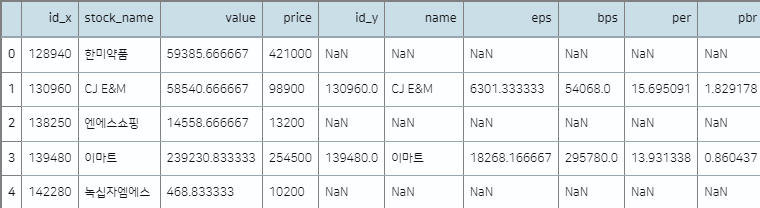
위의 결과는 how='left'옵션을 주었기 때문에, df1데이터의 고유값을 기준으로 한다.
3 .데이터프레임 결합 : join()
join함수는 merge()함수를 기반으로 만들어졌기 때문에 기본 작동방식이 비슷하다. 하지만 join()은 행 인덱스를 기준으로 결합한다는 점에서 차이가 있다. 그래도 이 함수도 on=keys 옵션이 존재한다.
Dataframe1.join(Dataframe2. how='left')이 default값이다.
join()함수 적용을 위해 각 데이터의 id열을 행인덱스로 지정해주자. default값이 how=’left’, 이므로 df1의 행 인덱스(id)를 기준으로 결합된다.
df1.set_index('id', inplace=True)
df2.set_index('id', inplace=True)
df1.join(df2)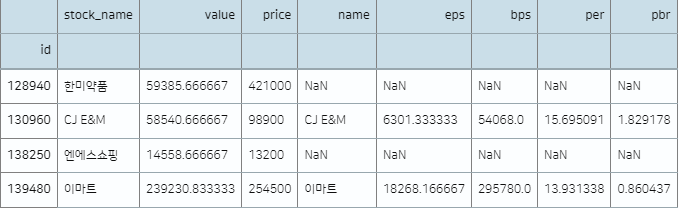
how='inner'옵션도 마찬가지다. merge함수와 별 차이가 없어서, 둘중 하나만 사용해도 무방하다.
df1.join(df2, how='inner')