[딥 러닝을 이용한 자연어 처리 입문] 교재 3장을 기반으로 작성되었습니다.
언어 모델(Language Model)이란?
언어 모델(LM)은 언어라는 현상을 모델링하고자 단어 시퀀스(문장)에 확률을 할당하는 일을 하는 모델이다.
언어 모델을 만드는 방법은 크게 통계를 이용한 방법과 인공 신경망을 이용한 방법으로 구분된다. 최근에는 후자의 방법이 더 좋은 성능을 보이며, GPT나 BERT가 그 예시이다.
하지만 이번 챕터에서는 언어 모델의 개념과 전통적 접근 방식인 통계적 언어 모델에 대해서 배울 것이다.
언어 모델(LM)
= 가장 자연스러운 단어 시퀀스를 찾아내는 모델
= 문장에서의 단어 시퀀스에 확률을 할당하는 일을 하는 모델
언어 모델링
= 이전 단어들이 주어졌을 때 언어 모델이 다음 단어를 예측하도록 하는 일
= 단어 시퀀스에 확률을 할당하기 위해 가장 보편적으로 사용되는 방법
단어 시퀀스의 확률 할당
아래는 확률 할당의 예시이다.



단어 시퀀스를 확률로 나타내기
하나의 단어를 w, 단어 시퀀스를 대문자 W라고 한다면, n개의 단어가 등장하는 단어 시퀀스 W의 확률은 아래와 같다.
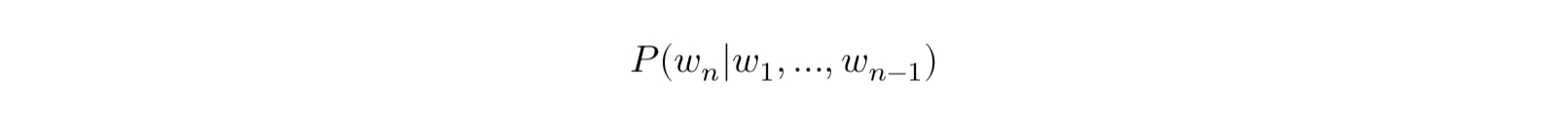
다음 단어 등장 확률은 조건부 확률로 표시한다.
n-1개의 단어가 나열된 상태에서 n번째 단어의 확률은 아래와 같다.
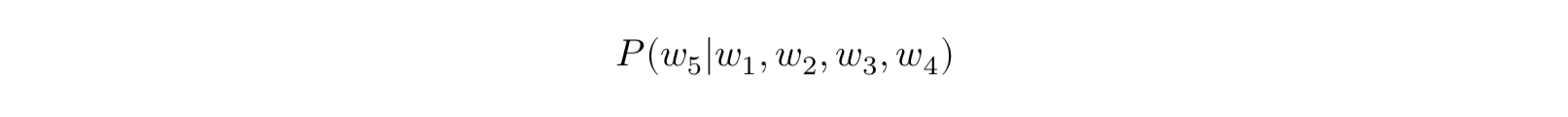
전체 단어 시퀀스 W의 확률은 아래와 같이 표시한다.
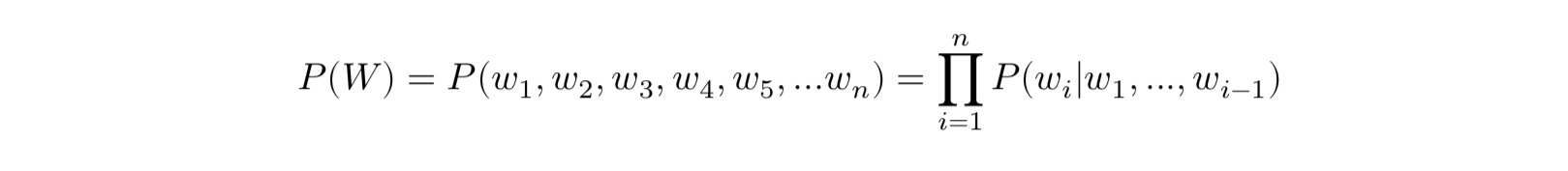
통계적 언어 모델(Statistical Language Model)
조건부 확률
통계적 언어 모델(SLM)에서는 조건부 확률 관계식을 이용한다.
조건부 확률은 두 확률 P(A), P(B)에 대해서 아래와 같은 관계를 갖는다.
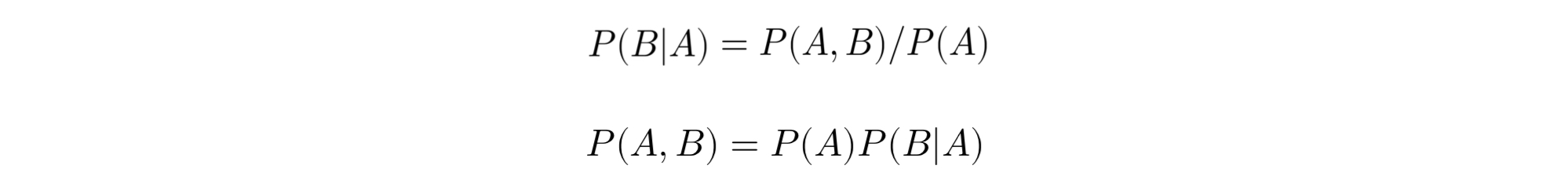
조건부 확률의 연쇄 법칙(chain rule)에 의해 아래와 같이 표현할 수 있다.

문장에 대한 확률
문장의 확률은 각 단어에 대한 예측 확률들의 곱으로 구성된다.
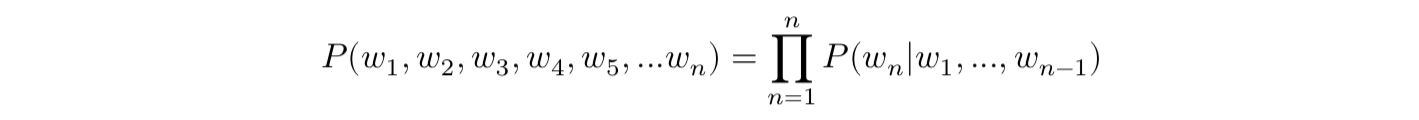
문장 'An adorable little boy is spreading smiles'의 확률을 구해보면 아래와 같이 표현된다.
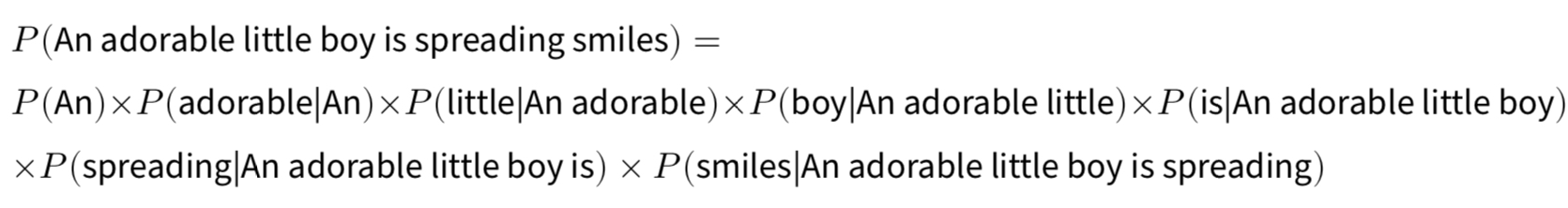
카운트 기반의 접근과 한계
문장의 확률을 구하기 위해 다음 단어에 대한 예측 확률을 모두 곱한다는 것은 알겠으나,
SLM은 이전 단어로부터 다음 단어에 대한 확률은 어떻게 구할까?
정답은, 카운트에 기반하여 확률을 계산한다.
An adorable little boy가 나왔을 때, is가 나올 확률인 P(is|An andorable little boy)는 아래와 같이 구할 수 있다.
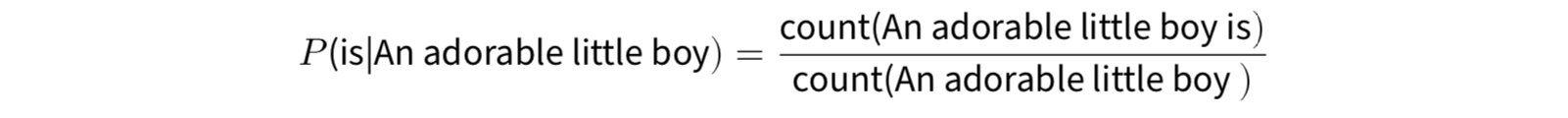
하지만, 카운트 기반으로 접근하려고 한다면 방대한 양의 코퍼스, 즉 훈련하는 데이터가 필요하다.
코퍼스에 'An adorable little boy is' 시퀀스가 존재하지 않으면 이 확률은 0이 되고,
'An adorable little boy' 시퀀스가 존재하지 않으면 분모가 0이 되어 확률이 정의되지 않는다.
이와 같이 충분한 데이터를 관측하지 못하여 언어를 정확히 모델링하지 못하는 문제를
희소 문제(Sparsity problem)라고 한다.
이러한 한계로 인해 언어 모델 기법은 SLM에서 인공 신경망 언어 모델로 넘어가게 된다.
N-gram 언어 모델
여전히 카운트에 기반한 통계적 접근을 사용하고 있어 SLM의 일종이다.
하지만, 모든 단어를 고려하는 것이 아니라 일부 단어만 고려하여 근사하는 접근 방법을 사용한다.
N-gram 언어 모델에서는 앞의 n-1 개의 단어만 고려한다!

고려하는 단어들을 줄이면 단어의 시퀀스를 카운트 할 수 있을 가능성이 높아진다!

문장 확률의 근사 계산
문장 확률은 아래와 같이 근사적으로 계산할 수 있다.
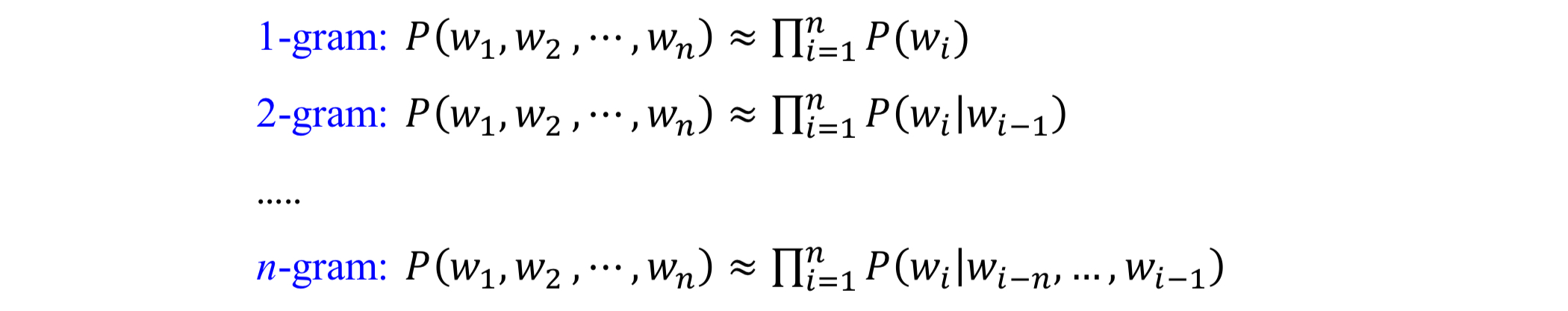
N-gram 언어 모델의 한계
- 전체 문장을 고려한 언어 모델 보다는 정확도가 떨어질 수 밖에 없다.
- 희소 문제: 카운트할 수 있는 확률을 높일 수는 있었지만, N-gram 언어 모델도 여전히 시퀀스가 등장하지 않을 가능성이 있다.
- n을 선택하는 것은 trade-off 문제: n을 크게 선택하면 예측 정확도는 올라가지만, 희소문제가 심각해진다. 그렇기에 n은 최대 5를 넘지 않도록 권장된다.
한국어에서의 언어 모델
한국어 자연어처리는 영어보다 훨씬 어려운데, 그 이유는 아래와 같다.
- 한국어는 어순이 중요하지 않다: 확률 기반 모델이 다음 단어를 예측하기 어려움
- 한국어는 교착어이다:조사가 붙으므로 이를 분리하는 것이 중요함
- 한국어는 띄어쓰기가 제대로 지켜지지 않는다: 토큰이 제대로 분리되지 않으면 언어 모델이 제대로 동작하지 않음
한국어 문장의 발생 확률
아래의 자료는 네이버 영화 말뭉치의 표현별 등장 횟수이다.
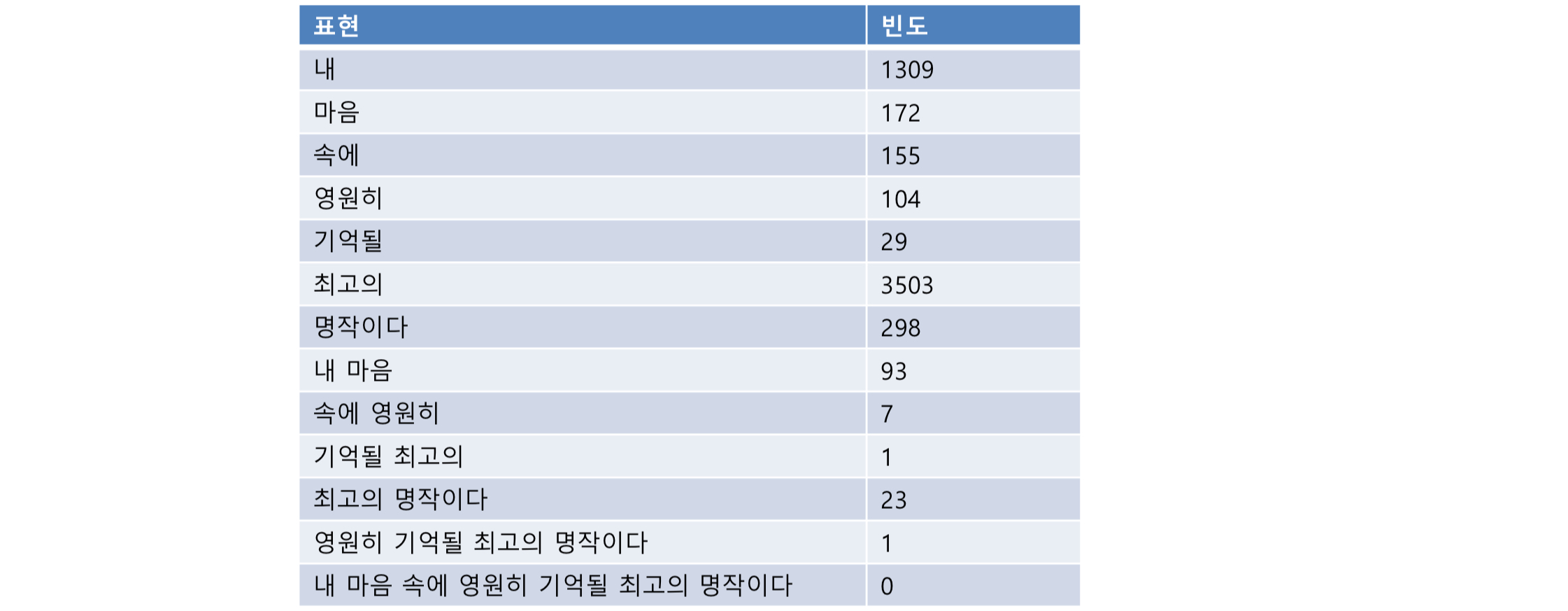
말뭉치에 있는 문장은 등장 횟수를 이용하여 확률을 구할 수 있다.
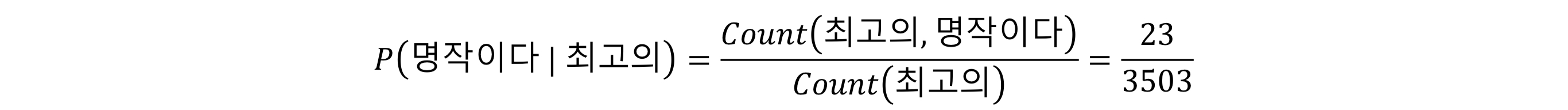
하지만, 말뭉치에 없는 문장은 발생 확률이 0이다.
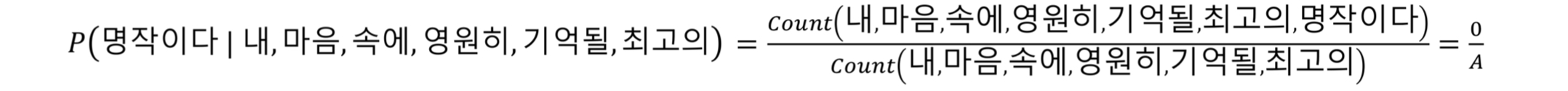
발생 확률의 근사적 처리
말뭉치에 없는 문장에 대해서 작은 확률값을 배정하기 위해 Back-off 와 Smoothing 방식을 사용한다.
Back-off 기법이란? <-- 추가 예정
Smoothing 기법이란? <-- 추가 예정
펄플렉서티(Perplexity)
언어 모델의 성능 평가 방법: PPL
perplexity(PPL)은 언어 모델을 평가하기 위한 평가 지표이다. "헷갈리는 정도" 라고 이해해두면 좋다.
PPL이 낮을수록 언어 모델의 성능이 좋은 것이다.
PPL은 테스트 데이터에서 확률의 역수로 정의되는데, 문장 W의 길이가 N이라고 할때 PPL은 아래와 같다.
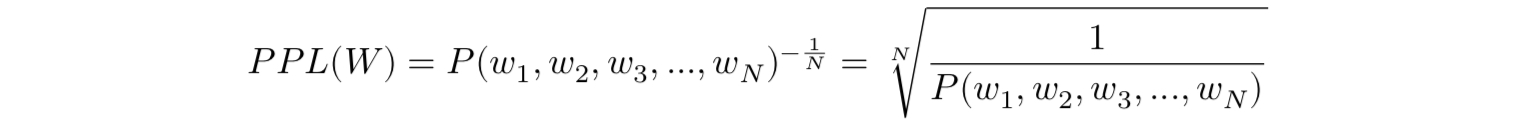
문장의 확률에 체인룰(chain rule)을 적용하면 아래와 같다
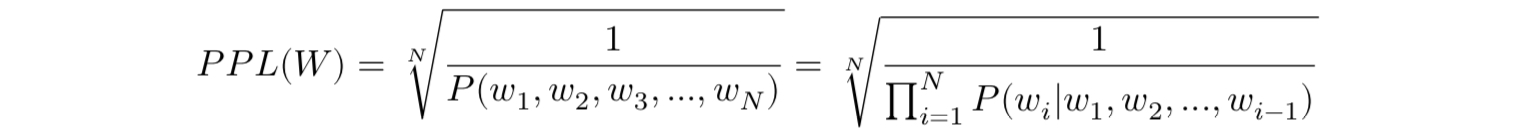
분기 계수(Branching factor)
perplexity(PPL)은 선택할 수 있는 가능한 가지의 개수, 즉 분기 계수를 의미한다.
그러므로 이 숫자가 크면 불확실성이 높다고 할 수 있다.
같은 테스트 데이터에 대해서 두 언어 모델의 PPL을 각각 계산한 후에 값을 비교하면,
두 언어 모델 중 PPL이 더 낮은 언어 모델의 성능이 더 좋다고 볼 수 있다.
사례 1)
주사위를 던질 때 나오는 수열의 PPL은 아래와 같음.
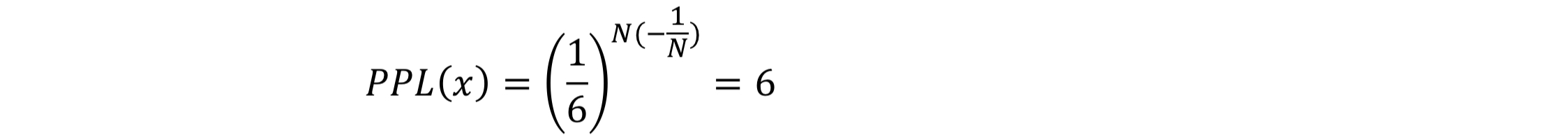
사례 2)
20,000개의 어휘로 이루어진 기사에서 단어의 출현 확률이 모두 같다면 PPL은 20,000이 됨(불확실성이 높음). 3-gram을 사용한 언어 모델을 적용했을 때 PPL이 30이면 불확실성이 매우 줄어든 것임.
월스트리트 저널에서 3,800만 개의 단어 토큰에 대해 n-gram 모델의 PPL은 아래와 같이 나왔다고 함.

