[파이썬 텍스트 마이닝 완벽 가이드] 교재 3장을 기반으로 작성되었습니다.
한국어 문서에 대한 그래프
konlpy에서 대한민국 헌법을 읽어와 테스트 해보자.
from konlpy.corpus import kolaw
const_doc = kolaw.open('constitution.txt').read()
print(type(const_doc))
print(len(const_doc))
print(const_doc[:600])>>> <class 'str'>
>>> 18884
>>> 대한민국헌법
유구한 역사와 전통에 빛나는 우리 대한국민은 3·1운동으로 건립된 대한민국임시정부의 법통과 불의에 항거한 4·19민주이념을 계승하고, 조국의 민주개혁과 평화적 통일의 사명에 입각하여 정의·인도와 동포애로써 민족의 단결을 공고히 하고, 모든 사회적 폐습과 불의를 타파하며, 자율과 조화를 바탕으로 자유민주적 기본질서를 더욱 확고히 하여 정치·경제·사회·문화의 모든 영역에 있어서 각인의 기회를 균등히 하고, 능력을 최고도로 발휘하게 하며, 자유와 권리에 따르는 책임과 의무를 완수하게 하여, 안으로는 국민생활의 균등한 향상을 기하고 밖으로는 항구적인 세계평화와 인류공영에 이바지함으로써 우리들과 우리들의 자손의 안전과 자유와 행복을 영원히 확보할 것을 다짐하면서 1948년 7월 12일에 제정되고 8차에 걸쳐 개정된 헌법을 이제 국회의 의결을 거쳐 국민투표에 의하여 개정한다.
제1장 총강
제1조 ① 대한민국은 민주공화국이다.
②대한민국의 주권은 국민에게 있고, 모든 권력은 국민으로부터 나온다.
제2조 ① 대한민국의 국민이 되는 요건은 법률로 정한다.
②국가는 법률이 정하는 바에 의하여 재외국민을 보호할 의무를 진다.
제3조 대한민형태소 분석
from konlpy.tag import Okt
t = Okt()
tokens_const = t.morphs(const_doc)
print('#토큰의 수:', len(tokens_const))
print(tokens_const[:100])>>> ['대한민국', '헌법', '\n\n', '유구', '한', '역사', '와', '전통', '에', '빛나는', '우리', '대', '한', '국민', '은', '3', '·', '1', '운동', '으로', '건립', '된', '대한민국', '임시정부', '의', '법', '통과', '불의', '에', '항거', '한', '4', '·', '19', '민주', '이념', '을', '계승', '하고', ',', '조국', '의', '민주', '개혁', '과', '평화', '적', '통일', '의', '사명', '에', '입', '각하', '여', '정의', '·', '인도', '와', '동포', '애', '로써', '민족', '의', '단결', '을', '공고', '히', '하고', ',', '모든', '사회', '적', '폐습', '과', '불의', '를', '타파', '하며', ',', '자율', '과', '조화', '를', '바탕', '으로', '자유민주', '적', '기', '본', '질서', '를', '더욱', '확고히', '하여', '정치', '·', '경제', '·', '사회', '·']한 글자 초과의 명사만 처리
tokens_const = t.nouns(const_doc)
print('#토큰의 수:', len(tokens_const))
print(tokens_const[:100])>>> #토큰의 수: 3882
>>> ['대한민국', '헌법', '유구', '역사', '전통', '우리', '국민', '운동', '건립', '대한민국', '임시정부', '법', '통과', '불의', '항거', '민주', '이념', '계승', '조국', '민주', '개혁', '평화', '통일', '사명', '입', '각하', '정의', '인도', '동포', '애', '로써', '민족', '단결', '공고', '모든', '사회', '폐습', '불의', '타파', '자율', '조화', '바탕', '자유민주', '질서', '더욱', '정치', '경제', '사회', '문화', '모든', '영역', '각인', '기회', '능력', '최고', '도로', '발휘', '자유', '권리', '책임', '의무', '완수', '안', '국민', '생활', '향상', '기하', '밖', '항구', '세계', '평화', '인류', '공영', '이바지', '함', '우리', '우리', '자손', '안전', '자유', '행복', '확보', '것', '다짐', '제정', '차', '개정', '헌법', '이제', '국회', '의결', '국민투표', '개정', '제', '장', '강', '제', '대한민국', '민주공화국', '대한민국']
글자가 1개인 명사는 삭제하고 결과를 살펴본다.
# 한 글자 초과만 남김
tokens_const = [token for token in tokens_const if len(token) > 1]
print('#토큰의 수:', len(tokens_const))
print(tokens_const[:100])>>> #토큰의 수: 3013
>>> ['대한민국', '헌법', '유구', '역사', '전통', '우리', '국민', '운동', '건립', '대한민국', '임시정부', '통과', '불의', '항거', '민주', '이념', '계승', '조국', '민주', '개혁', '평화', '통일', '사명', '각하', '정의', '인도', '동포', '로써', '민족', '단결', '공고', '모든', '사회', '폐습', '불의', '타파', '자율', '조화', '바탕', '자유민주', '질서', '더욱', '정치', '경제', '사회', '문화', '모든', '영역', '각인', '기회', '능력', '최고', '도로', '발휘', '자유', '권리', '책임', '의무', '완수', '국민', '생활', '향상', '기하', '항구', '세계', '평화', '인류', '공영', '이바지', '우리', '우리', '자손', '안전', '자유', '행복', '확보', '다짐', '제정', '개정', '헌법', '이제', '국회', '의결', '국민투표', '개정', '대한민국', '민주공화국', '대한민국', '주권', '국민', '모든', '권력', '국민', '대한민국', '국민', '요건', '법률', '국가', '법률', '재외국민']
단어 빈도수 그래프
from matplotlib import font_manager, rc
import platform
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
const_cnt = {}
for word in tokens_const:
const_cnt[word] = const_cnt.get(word, 0) + 1
def word_graph(cnt, max_words=10):
sorted_w = sorted(cnt.items(), key=lambda kv: kv[1])
print(sorted_w[-max_words:])
n, w = zip(*sorted_w[-max_words:])
plt.barh(range(len(n)),w,tick_label=n)
plt.show()
word_graph(const_cnt, max_words=20)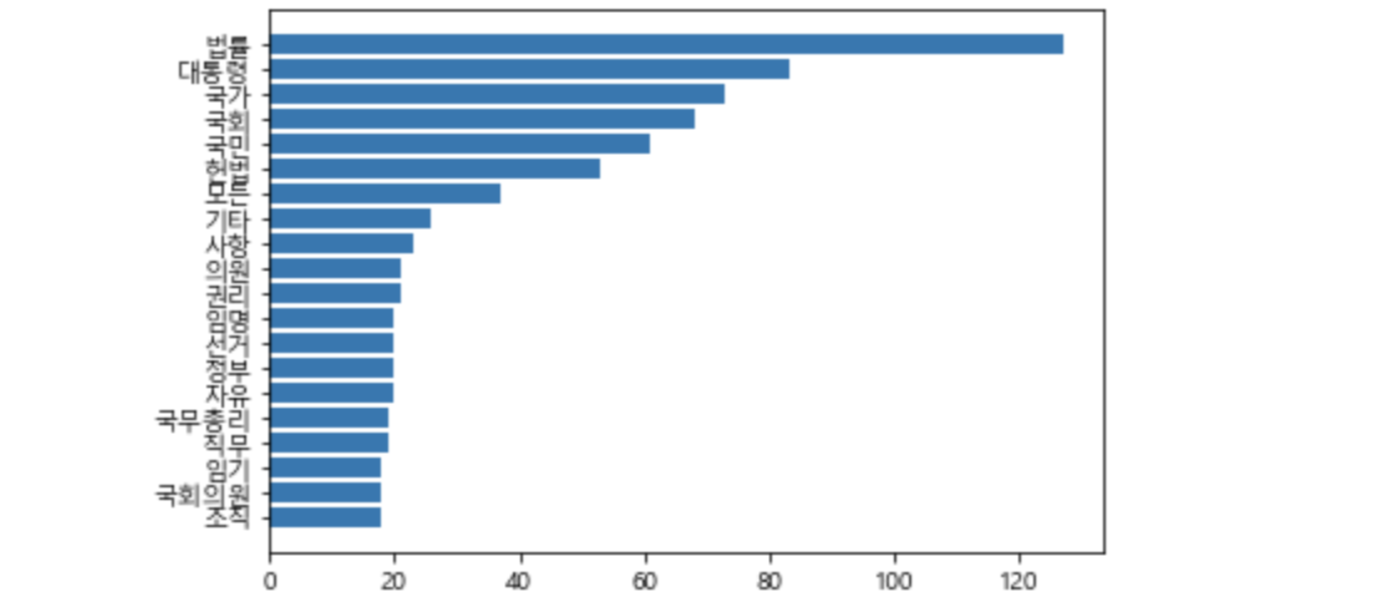
지프의 법칙
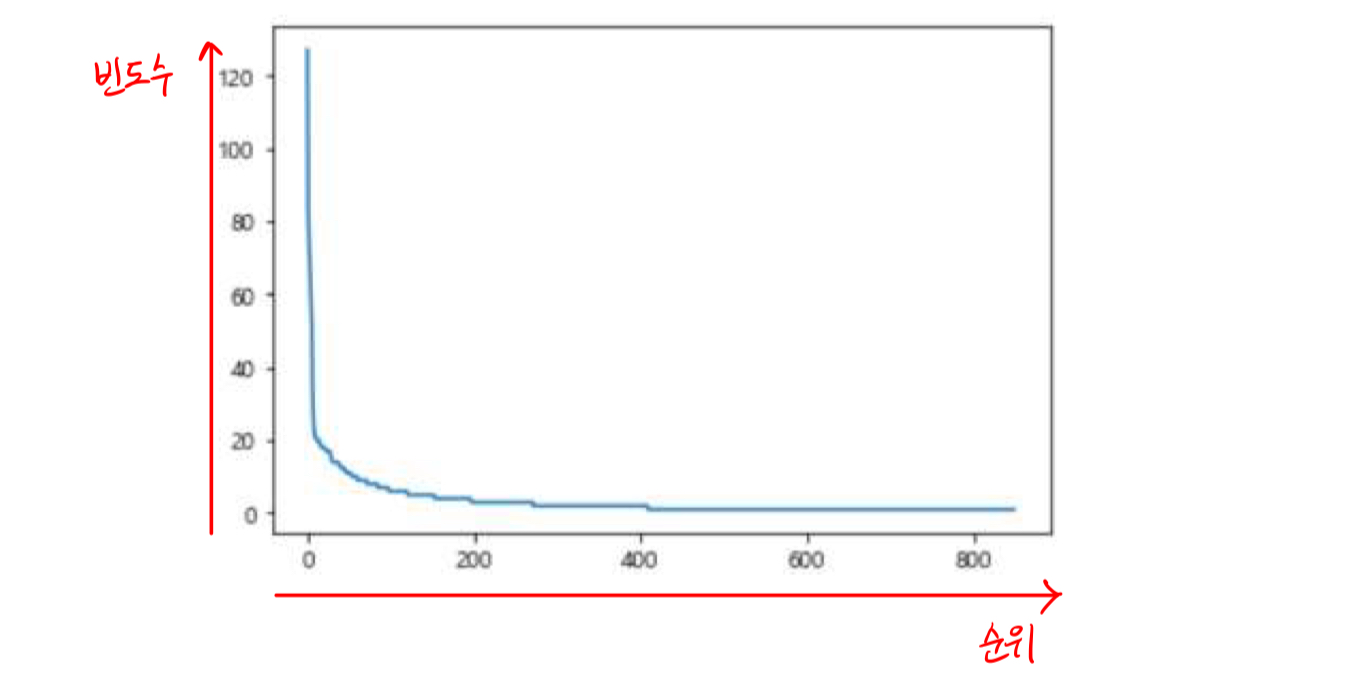
지프의 법칙은 이것을 최초로 제안한 하버드대학교의 언어학자, 조지 킹슬리 지프의 이름을 따서 만들어졌다. 지프는 말뭉치(코퍼스)의 단어들을 사용 빈도가 높은 순서대로 나열하면 단어의 사용 빈도는 단어의 순위에 반비례한다는 것을 알아냈다. 예를 들어 'the'가 가장 높은 7%의 빈도를 보인다면 그다음으로 높은 빈도의 단어인 'of'는 대략 3.5%의 빈도를 보인다는 것으로, 전체 단어에 대해 그래프를 그리면 위에서 확인한 것과 같은 반비례 모양이 나온다.

Shoot for the moon!