[딥 러닝을 이용한 자연어 처리 입문] 교재 2장을 기반으로 작성되었습니다.
머신 러닝 워크플로우
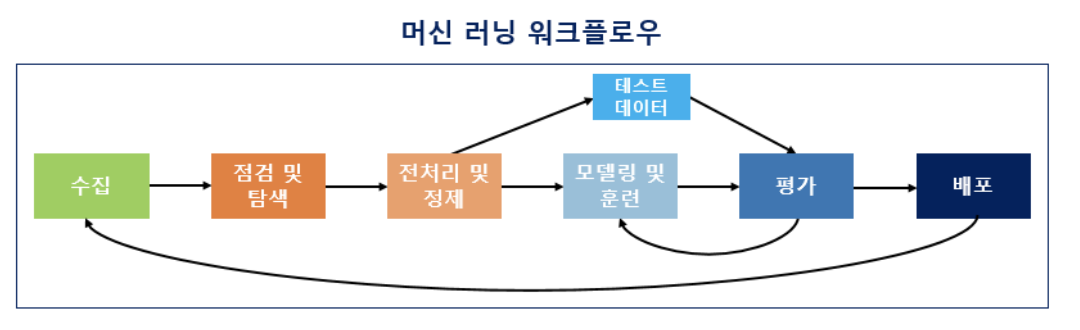
머신 러닝 워크플로우: 데이터를 수집하고 머신 러닝을 하는 과정
수집 단계에서 수집된 텍스트 집합을 코퍼스(말뭉치)라고 부른다.
텍스트 전처리
코퍼스 데이터가 필요에 맞게 전처리되지 않은 상태라면 토큰화, 정제, 정규화하는 일을 한다.
이번에는 그 중에서도 토큰화에 대해 배울것
토큰화
의미있는 단위(단어 또는 문장)으로 문장들을 분리하는 것
단어 토큰화
- 문장을 단어 또는 의미있는 문자열로 구분하는 것
- 구두점(. , ? ! ; 등의 기호)를 포함하는 것이 좋음
- 영어의 경우 apostrophe가 있는 부분을 처리하는 방식이 경우에 따라 달라질 수 있음
입력: "It doesn't have a food restaurant."
결과: ['It', 'does', "n't", 'have', 'a', 'food', 'restaurant', '.']문장 토큰화
텍스트를 문장별로 나누는 것
한국어에서의 토큰화의 어려움
-
교착어이기에 조사라는것이 존재하여 한국어 NLP에서는 조사를 분리해줄 필요가 있다.
이렇게 조사를 분리해준 결과가 '형태소'이다. (뜻을 가진 가장 작은 말의 단위) -
한국어는 띄어쓰기가 영어보다 잘 지켜지지 않는다.
KoNLPy를 이용한 형태소 분석
KoNLPy는 형태소 분석기를 모은 패키지로, Okt, Komoran, Hannanum, Kkma, Mecab 등이 지원된다.
각 분석기에서 morphs, pos, nouns 함수들이 지원되는데, 각각 아래와 같은 기능을 한다.
morphs : 품사를 표시하지 않고 형태소 별로 분리
pos : 품사를 표시하며 형태소 별로 분리
nouns : 명사 추출
from konlpy.tag import Kkma
kkma=Kkma ( )
print (kkma.morphs ("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))>>> ['열심히, 코딩, 하, 'L, 당신, , 연휴, '에, '는', 여행, '을, '가보' '아요']
print(kkma.pos("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))>>> [('열심히', 'MAG'), ('코딩', 'NNG'), ('하', 'XSV'), ('ㄴ', 'ETD'), ('당신', 'NP'), (',', 'SP'), ('연휴', 'NNG'), ('에', 'JKM'), ('는', 'JX'), ('여행', 'NNG'), ('을', 'JKO'), ('가보', 'VV'), ('아요', 'EFN')]print(kkma.nouns("열심히 코딩한 당신, 연휴에는 여행을 가봐요"))>>> ['코딩', '당신', '연휴', '여행']불용어(stopword)
사용 빈도와 관계없이 문서의 의미 전달 측면에서는 큰 의미가 없는 단어들
영어의 경우 nltk에서 불용어 리스트를 제공하고 있다.
from nltk.corpus import stopwords
stopwords.words('english')[:10]>>> ['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're"]한글 불용어
한글의 경우 불용어를 처리하는 패키지는 없고 공통적인 리스트를 제공하는 사이트들이 있다.
예시: https://www.ranks.nl/stopwords/korean
한글에서는 불용어 리스트를 파일에 만들어 놓고 사용하는 것이 바람직하다.
정규 표현식
정규 표현식은 특정한 패턴을 찾기 위한 방식이다.
한글 처리에서는 많이 쓰지 않음.
파이썬의 re 모듈에서 함수들이 지원되고 있는데, search 함수에 의해 text 내에 pattern이 존재하는지 알려준다.
< 코드 예시 >
import re
re.search(*pattern*, *text*)패턴이 존재하면 message가 나오고, 존재하지 않으면 응답이 없다.
import re
re.search("at", "string data")>>> < re.Match object; span=(8, 10), match='at' >import re
re.search("at", "this is anouther string")>>> 응답 없음compile 함수의 기능
compile을 사용하면 패턴을 저장할 수 있다.
import re
r1 = re.compile("at")
r1.search("strin data")>>> < re.Match object; span=(8, 10), match='at' >정수 인코딩
컴퓨터로 텍스트를 처리하는 프로그램을 만들 때, 각 단어에 고유한 정수를 대응시키는 것이 필요하다.
텍스트에 단어가 10,000개가 있으면 단어 각각에 1 ~ 10,000 까지의 인덱스를 할당하게 된다.
인덱스를 부여하는 랜덤하게 부여하기도 하지만, 보통은 단어 등장 빈도수를 기준으로 정렬한 뒤에 부여한다.
원-핫 인코딩(One-hot encoding)
단어 집합의 크기를 벡터의 차원으로 하고, 단어별로 한 개의 인덱스만 1, 나머지는 0이 되도록 표현하는 방식이다.
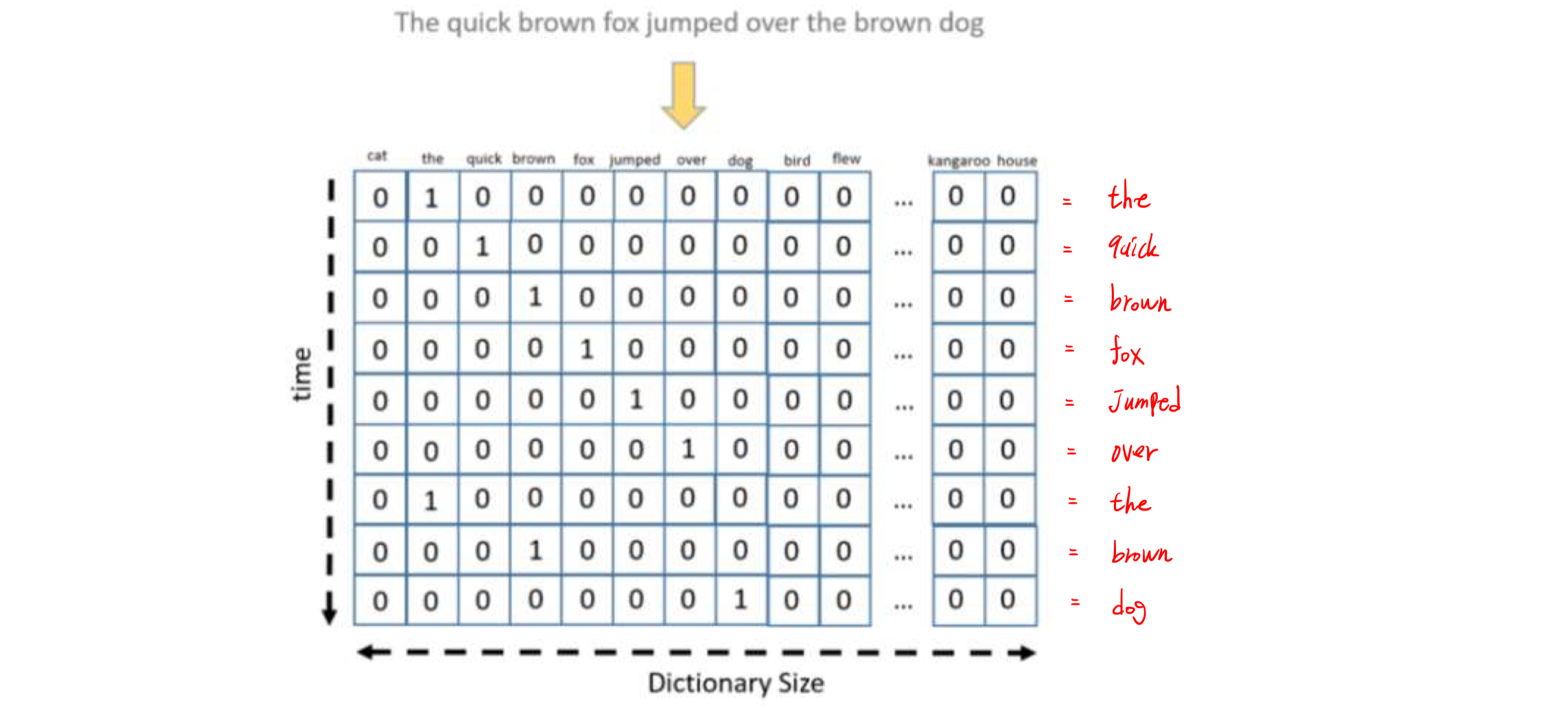
단어의 수가 10개이고 '나'라는 단어의 고유 숫자가 3이라면 '나'는
[0,0,0,1,0,0,0,0,0,0] 로 코딩된다.
단점
- 단어의 개수가 많으면 벡터의 차원이 커짐
- 단어간의 유사성을 표현하지 못함
단어의 잠재 의미를 반영하여 다차원 공간에 벡터화하는 방식은 워드 임베딩이며, 머신 러닝 기법을 이용하여 벡터 데이터를 구축한다.
