Very Deep Convolutional Networks for Large-Scale Image Recognition 논문을 기반으로 작성되었습니다.
[Background Info]
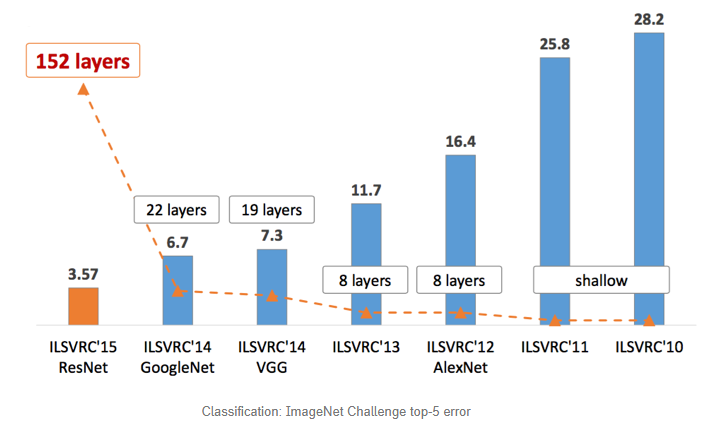
ILSVRC란?
ILSVRC는 “ImageNet Large Scale Visual Recognition Challenge”의 약자로, 매년 ImageNet 데이터셋을 활용해 물체 분류(classification), 검출(detection), 위치(localization) 등의 성능을 겨루는 대표적인 컴퓨터 비전 경진 대회를 말함.
AlexNet
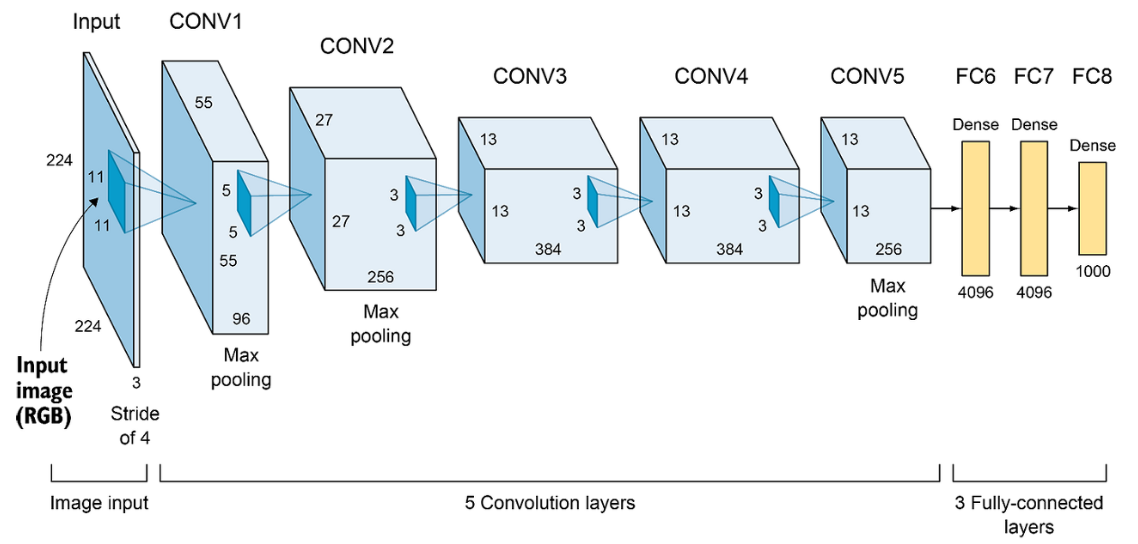
- ILSVRC 2012에서 우승을 차지한 AlexNet은 총 8개의 얕은 layer 수를 가지고, 각 layer 마다 11x11, 5x5, 3x3의 필터들을 혼용하며 사용함
- LRN(Local Response Normalization)을 사용함
1. Introduction
- 2012년의 AlexNet 이후, 2013년에 AlexNet의 모델 구조는 동일하되 필터 사이즈와 스트라이드를 줄인 ZFNet이 등장
- 이 논문에선, 필터 사이즈 뿐만 아닌 "layer의 개수"에 집중하여 "깊이"를 늘려봄.
- 위가 가능한 이유는, 모든 Conv층에서 3x3의 작은 필터만을 사용했기에 깊이를 늘려도 파라미터수,연산량이 과하게 증가하지 않았기 때문.
- 이렇게 깊어진 VGGNet 모델은 ILSVRC의 분류와 위치추정에서 SOTA를 달성함
2. ConvNet Configurations
2.1 Architecture
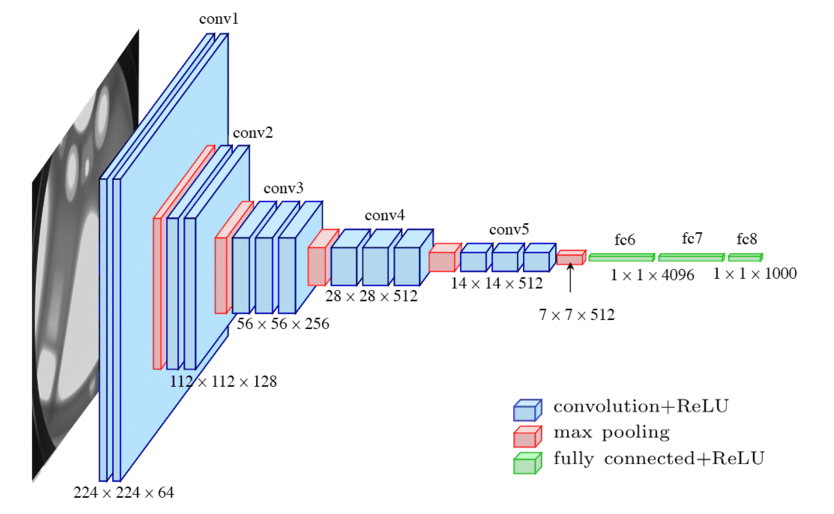
Input image
- 224 X 224 RGB
- 전처리는 RGB 평균값 빼주는것만 적용
Conv layer
- 3 x 3 Conv filter 사용 (이때, 3 x 3 사이즈가 이미지 요소의 left, right, up, down 등을 파악할 수 있는 최소한의 receptive field이기 때문에 3 x 3 사이즈를 사용한다.)
- 추가로, 1 x 1 Conv filter도 사용하는데, 이는 뒤에서 더 자세히 설명하겠지만, 차원을 줄이고 non-linearity를 증가시키기 위함이다.
- stride는 1, padding 또한 1로 설정
Pooling layer
- Conv layer 다음에 적용되고, 총 5개의 max pooling layer로 구성된다.
- 2 x 2 사이즈, stride는 2
FC layer
- 처음 두 FC layer는 4,096 채널
- 마지막 FC layer는 1,000 채널
마지막으로, soft-max layer를 적용해준다.
그 외 모든 layer에는 ReLU를 사용하며, AlexNet에서 사용한 LRN 기법은 성능 개선은 없고 메모리 사용량 및 연산 시간만 늘어났기에 사용을 하지 않는다.
(LRN이 적용된 구조는 A-LRN인데 뒤에서 성능 비교표가 나온다.)
출처: [philBaek (백광록) 개발 일기장:티스토리]
2.2 Configurations
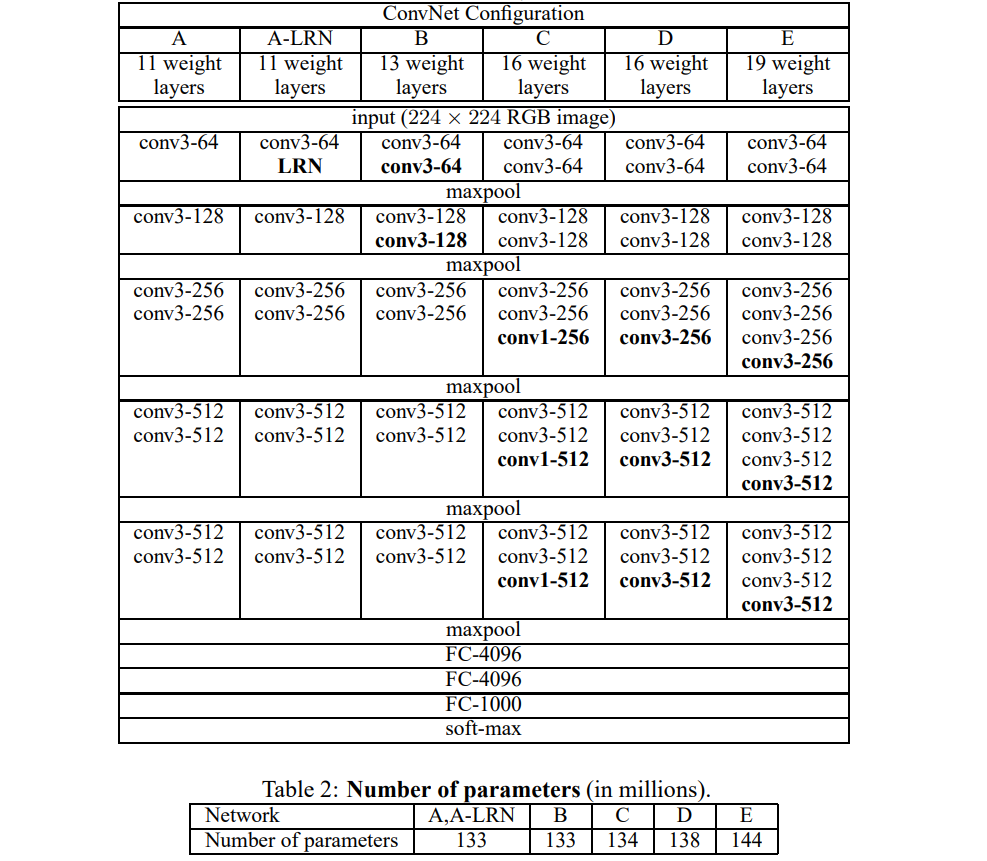
모델은 깊이에 따라 A(11depth)부터 E(19depth)까지 조금씩 구조가 달라지며, conv layer의 채널 수는 64로 시작해 각 max-pooling을 거칠 때마다 2배씩 늘어나 최대 512에 이르게됨.
+) depth를 늘리면서도 개별 conv의 필터 크기를 작게 유지해(3x3) 큰 conv 필터를 가지며 얕은 depth를 갖는 네트워크보다 파라미터 수를 줄였음
2.3 Discussion
3개의 3x3 conv는 1개의 7x7 conv와 같은 효과를 주는데, 7x7 대신 3x3를 쓰는 이유는?
- ReLU 단계가 더 많아 비선형적 의사결정을 더 잘하게 됨
- 파라미터 수를 줄여줌. (파라미터 수 = 필터크기 * 입력 채널수 * 출력 채널수)
채널 수 = C 라고 할때,
3(3*3*C*C) < 7*7*C*C
C 모델의 1x1 conv는?
- 1x1 필터를 쓰면 수용 영역은 그대로 유지하면서 ReLU를 통해 비선형성을 주입할 수 있음
- 하지만, 픽셀 주변의 공간 정보를 추출할 수 없어 성능 낮아짐
다른 연구와의 차별점?
- GoogLeNet은 22개의 layer에서 1x1, 3x3, 5x5의 복합 필터를 쓰되 구조가 더 복잡하고 공간 해상도를 급격히 줄여 계산량을 관리한 반면, VGGNet은 더 단순한 반복 구조만으로 우수한 정확도를 달성함.
3. Classification Framework
3.1 Training
다중회귀(Softmax+CrossEntropy)를 미니배치 경사하강법과 모멘텀을 사용해 최적화함
하이퍼파라미터
- 배치 크기(batch size): 256
- 가중치 감쇠(weight decay, L2 정규화): 5 × 10⁻⁴
- 드롭아웃(dropout): 처음 두 개의 FC 층에 각 0.5 비율 적용
- 학습률(learning rate): 초기 10⁻²에서 출발해, 검증 정확도가 정체될 때마다 10분의 1씩 세 차례 감소
- 총 반복(iteration): 370,000번 (약 74 에폭)
가중치 초기화
- 가장 얕은 모델(A 구성)을 랜덤 initialization으로 먼저 학습
- 이후 더 깊은 모델 학습 시, A 구성의 “첫 4개 합성곱층 + 마지막 3개 FC층” 파라미터를 가져와서 초기값으로 사용 (나머지는 랜덤)
(네트워크의 깊이가 깊어질수록 기울기(gradient)가 불안정해져 학습이 제대로 진행되지 않는 문제가 발생할 수 있기 때문) - 랜덤 초기화 분포: 평균 0, 분산 10⁻², 편향은 0
데이터 증강(data augmentation)
- 학습 이미지를 임의의 크기 스케일 S에서 224×224 크롭
- 랜덤 수평 뒤집기(horizontal flip)
- RGB 색상 편차(random colour shift) 적용
스케일 설정
- 단일-스케일 학습: S = 256 또는 S = 384 두 가지로 학습
- 다중-스케일 학습: S를 256~512 범위에서 무작위 선택해 크롭 (스케일 지터링) 후 S = 384 단일-스케일 모델을 미세조정(fine-tune)
3.2 Testing
-
스케일 Q: 테스트 이미지를 가장 짧은 변이 Q로 등비 축소(rescale)
-
Dense 평가
1. FC 층을 7×7, 1×1 합성곱으로 변환해 “완전-합성곱(conv-only)” 네트워크로 바꿈
2. 이미지를 크롭 없이 한 번에 순전파하여 클래스 점수 맵(score map)을 얻음
3. 공간 축소(sum-pooling)로 고정 길이 벡터 생성 -
테스트 증강
- 원본과 뒤집은 이미지의 소프트맥스 점수를 평균 -
Multi-crop vs Dense
- 여러 크롭을 쓰면 정확도는 소폭 오르지만, 네트워크를 반복 실행해야 해 비효율적
- Dense 평가 시 패딩이 실제 이웃 픽셀로 채워지기 때문에 더 넓은 문맥(context)을 포착
왜 테스트 시에 FC 레이어를 Conv 레이어로 변환하는지?
FC 레이어의 역할 (훈련 시):
훈련 시에 ConvNet은 입력 이미지(이 논문에서는 224x224 크기)로부터 계층적인 특징을 추출하고, 마지막 Conv 레이어의 출력은 3차원 특징 맵이 됩니다.
이 특징 맵은 1차원 벡터로 펼쳐져(flatten) 첫 번째 FC 레이어의 입력으로 들어갑니다.
FC 레이어는 이 입력 벡터에 가중치 행렬을 곱하고 bias를 더하는 연산을 수행하여, 추출된 모든 특징들을 종합적으로 판단하여 최종 클래스를 분류하기 위한 점수를 계산합니다. 즉, FC 레이어는 고정된 크기의 입력에 대해 동작하는 "분류기" 역할을 합니다.문제점 (테스트 시):
훈련 시에는 입력 이미지가 224x224로 고정되어 있기 때문에 FC 레이어를 그대로 사용할 수 있습니다.
하지만 테스트 시에는 다양한 크기의 이미지가 입력될 수 있습니다. 또한, 이 논문에서는 전체 이미지([Multi-scale training]된 이미지의 다양한 크기)에 대해 조밀하게(densely) 네트워크를 적용하여 평가하고 싶어합니다.
표준 FC 레이어는 입력 크기가 고정되어야 하므로, 다양한 크기의 전체 이미지에 직접 적용하기 어렵습니다. 이미지를 224x224로 잘라내야만 FC 레이어를 통과시킬 수 있게 됩니다.FC 레이어를 Conv 레이어로 변환하는 이유 (테스트 시):
동일 계산의 활용: 놀랍게도, 특정 조건 하에서 Conv 레이어는 FC 레이어와 수학적으로 동일한 계산을 수행할 수 있습니다. 예를 들어, 마지막 Conv 레이어의 출력 크기가 W x H이고 채널 수가 C일 때, 이 특징 맵을 1차원으로 펼쳐 (WHC 차원의 벡터) N개의 뉴런을 가진 FC 레이어에 입력하는 연산은, 특징 맵에 (W x H) 크기의 커널(kernel)을 가지고 N개의 출력 채널을 갖는 Conv 레이어를 Stride 1, Padding 0으로 적용하는 연산과 동일하게 만들 수 있습니다. FC 레이어의 가중치 행렬을 적절히 재배열하면 Conv 레이어의 커널이 됩니다.
입력 크기의 유연성 확보: 이렇게 FC 레이어를 '동일한 계산을 수행하는' Conv 레이어 형태로 변환하면, 네트워크 전체가 Convolutional 레이어들로만 구성된 Fully-Convolutional Network가 됩니다. Fully-Convolutional Network는 입력 이미지의 크기에 상관없이 적용될 수 있습니다.
3.3 Implementation Details
-
프레임워크: Caffe(C++ 기반)를 포크하여 사용
-
다중 GPU 학습
- 데이터 병렬 처리(data parallelism): 배치를 GPU 개수만큼 쪼개서 병렬화
- 각 GPU에서 계산한 기울기를 동기화(synchronous) 후 평균
- 4 GPU 시스템에서 단일 GPU 대비 약 3.75배 속도 향상 -
학습 소요 시간: NVIDIA Titan Black GPU 4장 기준, 모델당 2~3주 소요
4. Classification Experiments
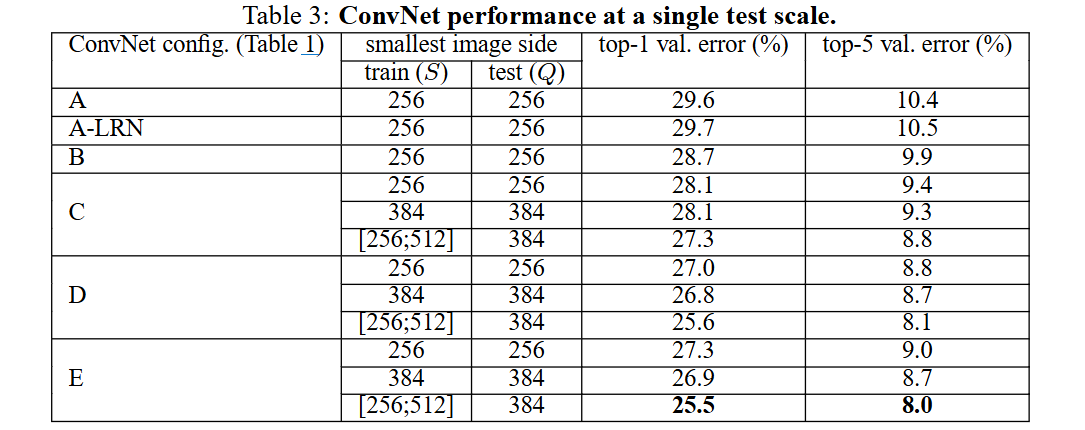
4.1 Single Scale Evaluation
[설정]
학습·테스트 모두 하나의 스케일 S에서 진행 (예: S=256→Q=256).
[결과]
- 깊이가 11→19로 증가함에 따라 top-1/5 오류율이 지속 감소 (A:29.6/10.4 → E:25.5/8.0).
- Local Response Normalisation은 오히려 성능을 떨어뜨려 제외.
- 1×1 conv를 추가한 C보다, 3×3만 쓴 D가 더 우수해 “공간 컨텍스트” 포착의 중요성 확인.
- 학습 시 스케일 지터링(S∈[256,512])을 도입하면 단일-스케일 학습 대비 top-1 오류가 27.3→25.5 등 유의미하게 개선.
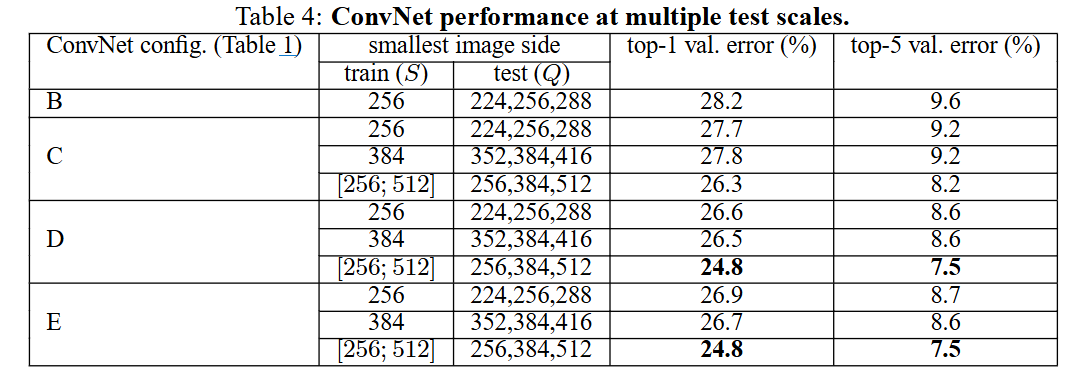
4.2 Multi-Scale Evaluation
[설정]
테스트 시 Q를 {S–32,S,S+32} 또는 학습 지터링 모델은 Q∈{256,384,512}로 여러 크기에서 예측 후 평균.
[결과]
- D, E configuration에서 best 성능: 24.8% top-1 / 7.5% top-5
- 단일-스케일 테스트보다 1% 정도 오류율 감소.
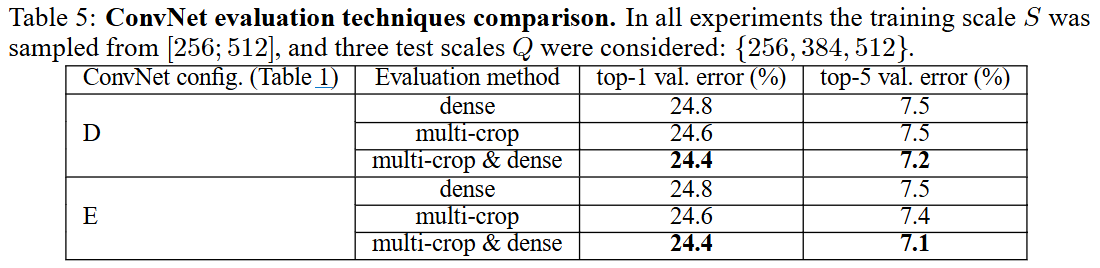
4.3 Multi-crop Evaluation
[설정]
-
여러 크롭 생성
원본 이미지를 224×224 크기의 여러 부분(모서리 4곳, 중앙 등)으로 잘라내고, 수평 뒤집기까지 적용해 스케일별로 총 50개의 크롭을 만듬 -
각 크롭별 추론
만들어진 각 크롭을 개별적으로 ConvNet에 입력해 클래스별 확률(Softmax)을 얻음 -
결과 결합
모든 크롭의 확률 분포를 평균해, 원본 이미지에 대한 최종 예측을 도출
[결과]
- Multi-crop만 쓰면 Dense 대비 소폭 향상(24.8→24.6 top-1),
- 둘을 결합하면 24.4% top-1 / 7.2% top-5까지 추가 개선.
4.4 ConvNet Fusion
[설정]
여러 모델 Configuration의 softmax 출력을 평균함
[결과]
- ILSVRC 제출 시(7개 모델) 7.3% test-5 error.
- 이후 최적의 두 모델(D/E, multi-scale)로만 앙상블:
- Dense eval: 7.0%,
- Dense eval+Multi-crop: 6.8% test-5 error.
- (둘의 softmax 평균으로 결과 산출)

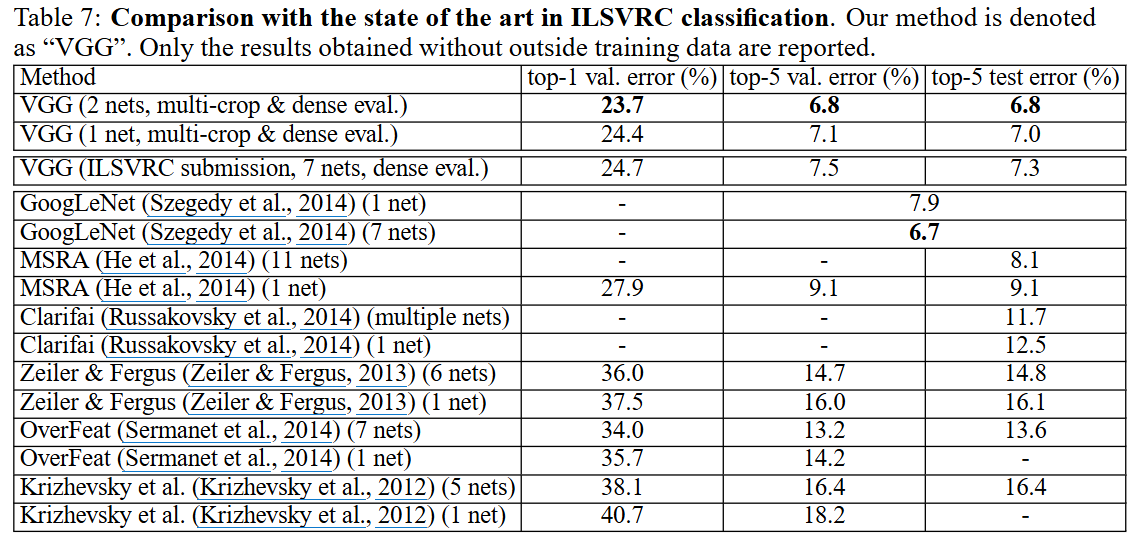
4.5 Comparison with the State of The Art
[결과]
- VGG(2-net ensemble, multi-crop+dense): 23.7% top-1 / 6.8% top-5 (검증), 6.8% test-5.
- 단일-넷(1-net): 24.4%/7.1% (검증), 7.0% (test-5)로 GoogLeNet(6.7%)에 근접하거나, 단일-넷 기준으로는 0.9%p 앞서는 성과를 냈습니다.
- ILSVRC-2012/13 우승 모델들(Clarifai, AlexNet, Zeiler&Fergus 등)을 크게 뛰어넘는 결과입니다.
5. Conclusion
- 네트워크 깊이를 최대 19층까지 확장함으로써 깊이의 중요성을 강조함.
- 전통적인 ConvNet 아키텍처에 깊이만 추가해도 ImageNet 챌린지에서 최첨단 성능을 달성하며, 깊이가 깊어질수록 이미지 분류 정확도가 크게 향상됨을 명확히 확인함.
- 다양한 데이터셋과 과제에서도 깊은 표현이 복잡한 파이프라인에 견줄 만큼 뛰어난 일반화 능력을 발휘함.
