[밑바닥부터 시작하는 딥러닝1] 교재 1장을 기반으로 작성되었습니다.
파이썬 인터프리터
리스트
여러 데이터를 리스트로 정리할 수 있다.
>>> a = [1, 2, 3, 4, 5] # 리스트 생성
>>> print(a) # 리스트의 내용 출력
[1, 2, 3, 4, 5]
>>> len(a) # 리스트의 길이 출력
5
>>> a[0] # 첫 원소에 접근
1
>>> a[4] # 다섯 번째 원소에 접근
5
>>> a[4] = 99 # 값 대입
>>> print(a)
[1, 2, 3, 4, 99]딕셔너리
리스트는 인덱스 번호로 0,1,2, ... 순으로 값을 저장하는 반면,
딕셔너리는 키(key)와 값(value)를 한 쌍으로 저장한다.
>>> me = {'height':180} # 딕셔너리 생성
>>> me['height'] # 원소에 접근
180
>>> me['weight'] = 70 # 새 원소 추가
>>> print(me)
{'weight': 70, 'height': 180}클래스
개발자가 직접 클래스를 정의하면 독자적인 자료형을 만들 수 있다.
또한, 클래스에는 그 클래스만의 전용 함수(메서드)와 속성을 정의할 수도 있다.
class 클래스 이름:
def __init__(self, 인수, ...): # 생성자
...
def 메서드 이름 1(self, 인수, ...): # 메서드 1
...
def 메서드 이름 2(self, 인수, ...): # 메서드 2
...클래스 정의에는 __init__이라는 특별한 메서드가 필요한데, 클래스를 초기화하는 방법을 정의하고, 클래스의 인스턴스(객체)가 만들어질 때 한번만 불린다. 이 초기화용 메서드를 생성자라고도한다.
또, 파이썬의 클래스는 메서드의 첫번째 인수로 self를 명시적으로 사용한다.
class Man:
def __init__(self, name):
self.name = name
print("Initialized!")
def hello(self):
print("Hello " + self.name + "!")
def goodbye(self):
print("Good-bye " + self.name + "!")
m = Man("David")
m.hello()
m.goodbye()$ python man.py
Initialized!
Hello David!
Good-bye David!Man 클래스에서 m이라는 인스턴스(객체)를 생성한다.
Man의 생성자는 name이라는 인수를 받고, 인스턴수 변수인 self.name을 초기화한다.
(인스턴스 변수: 인스턴스 별로 저장되는 변수)
파이썬에서는 self.name처럼 self 다음에 속성 이름을 써서 인스턴스 변수에 접근한다.
넘파이
넘파이 가져오기
>>> import numpy as np넘파이 배열 생성하기
넘파이 배열을 만들 때는 np.array() 메서드를 이용한다.
>>> x = np.array([1.0, 2.0, 3.0])
>>> print(x)
[1. 2. 3.]
>>> type(x)
<class 'numpy.ndarray'>넘파이의 산술 연산
>>> x = np.array([1.0, 2.0, 3.0])
>>> y = np.array([2.0, 4.0, 6.0])
>>> x + y # 원소별 덧셈
array([ 3., 6., 9.])
>>> x - y
array([ -1., -2., -3.])
>>> x * y # 원소별 곱셈
array([ 2., 8., 18.])
>>> x / y
array([ 0.5, 0.5, 0.5])배열의 원소 수가 다르면 오류가 발생하니 원소 수를 맞추어야한다.
>>> x = np.array([1.0, 2.0, 3.0])
>>> x / 2.0
array([ 0.5, 1., 1.5])넘파이 배열과 수치 하나(스칼라값)의 조합으로 된 산술 연산도 수행할 수 있는데,
스칼라값과의 계산이 넘파이 배열의 원소별로 한 번씩 수행된다. 이 기능을 브로드캐스트라고한다.
넘파이의 N차원 배열
넘파이는 다차원 배열도 작성할 수 있다.
행렬의 형상은 shape으로, 행렬에 담긴 원소의 자료형은 dtype으로 확인할 수 있다.
>>> A = np.array([[1, 2], [3, 4]])
>>> print(A)
[[1 2]
[3 4]]
>>> A.shape
(2, 2)
>>> A.dtype
dtype('int64')형상이 같은 행렬끼리면 산술 연산도 가능하고, 브로드캐스트도 작동된다.
# 산술 연산
>>> B = np.array([[3, 0], [0, 6]])
>>> A + B
array([[ 4, 2],
[ 3, 10]])
>>> A * B
array([[ 3, 0],
[ 0, 24]])# 브로드캐스트
>>> print(A)
[[1 2]
[3 4]]
>>> A * 10
array([[ 10, 20],
[ 30, 40]])브로드캐스트
브로드캐스트에 대해 더 자세히 알아보자.
>>> print(A)
[[1 2]
[3 4]]
>>> A * 10
array([[ 10, 20],
[ 30, 40]])
위의 예시를 보면 2x2 행렬 A에 스칼라값 10을 곱했는데,
이때 10 이라는 스칼라값이 2x2 행렬로 확대된 후 연산이 이루어진다.
>>> X = np.array([[51, 55], [14, 19], [0, 4]])
>>> print(X)
[[51 55]
[14 19]
[ 0 4]]
>>> X[0] # 0행
array([51, 55])
>>> X[0][1] # (0, 1) 위치의 원소
55
위의 예시를 보면 2x2 행렬 A에 1차원 배열 B를 곱했는데,
이때 배열 B를 행렬 A와 똑같은 형상으로 변형한 후 연산한 것을 볼 수 있다.
원소 접근
>>> X = np.array([[51, 55], [14, 19], [0, 4]])
>>> print(X)
[[51 55]
[14 19]
[ 0 4]]
>>> X[0] # 0행
array([51, 55])
>>> X[0][1] # (0, 1) 위치의 원소
55# for문으로 원소에 접근
>>> for row in X:
... print(row)
...
[51 55]
[14 19]
[0 4]위의 방법 외에도, 인덱스를 배열로 지정해 한 번에 여러 원소에 접근할 수도 있다.
리턴값은 배열 타입으로 얻게된다!
>>> X = X.flatten() # X를 1차원 배열로 변환(평탄화)
>>> print(X)
[51 55 14 19 0 4]
>>> X[np.array([0, 2, 4])] # 인덱스가 0, 2, 4인 원소 얻기
array([51, 14, 0])>>> X > 15
array([ True, True, False, True, False, False], dtype = bool)
>>> X[X>15]
array([51, 55, 19])matplotlib
딥러닝 실험에서는 그래프와 데이터 시각화가 중요한데, matplotlib은 그래프를 그려주는 라이브러리이다.
단순한 그래프 그리기
그래프를 그리기 위해 matplotlib의 pyplot 모듈을 이용한다.
import numpy as np
import matplotlib.pyplot as plt
# 데이터 준비
x = np.arange(0, 6, 0.1) # 0에서 6까지 0.1 간격으로 생성
y = np.sin(x)
# 그래프 그리기
plt.plot(x, y)
plt.show()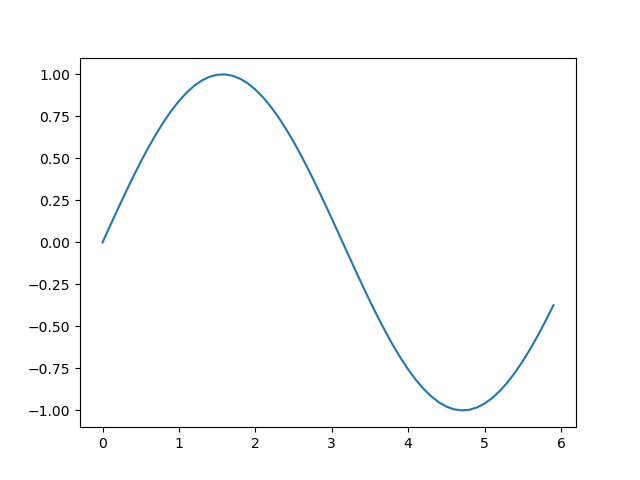
pyplot의 기능
import numpy as np
import matplotlib.pyplot as plt
# 데이터 준비
x = np.arange(0, 6, 0.1) # 0에서 6까지 0.1 간격으로 생성
y1 = np.sin(x)
y2 = np.cos(x)
# 그래프 그리기
plt.plot(x, y1, label="sin")
plt.plot(x, y2, linestyle = "--", label="cos") # cos 함수는 점선으로 그리기
plt.xlabel("x") # x축 이름
plt.ylabel("y") # y축 이름
plt.title('sin & cos') # 제목
plt.legend()
plt.show()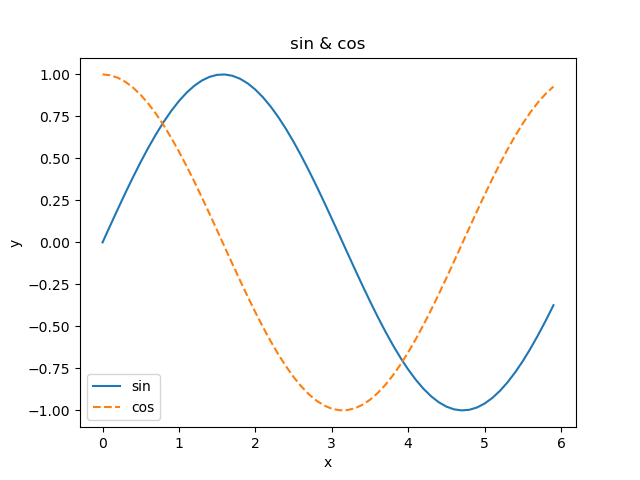
이미지 표시하기
plplot에는 이미지를 표시해주는 메서드인 ìmshow() 도 준비되어 있다.
이미지를 읽어들일 때는 matplotlib.image 모듈의 ìmread() 메서드를 이용한다.
import matplotlib.pyplot as plt
from matplotlib.image import imread
img = imread('오구리.jpg') # 이미지 읽어오기(적절한 경로를 설정하세요!)
plt.imshow(img)
plt.show()