[혼자 공부하는 머신러닝+딥러닝] 교재 5장을 기반으로 작성되었습니다.
이전 챕터에서의 결정트리 모델의 매개변수 max_depth를 3말고 다른 값으로 하면 성능이 달라진다.
매개변수 값을 바꿔가며 테스트를 많이 하며 적절한 값을 찾으면 될 것이다.
하지만, 이런저런 값으로 모델을 많이 만들어서 '테스트 세트'로 평가하면 결국 테스트 세트에 잘 맞는 모델이 만들어지는 것 아닐까?
맞다. 그러므로 우린 모델을 개발하는 과정에선 테스트세트를 사용해선 안 된다.
검증 세트
테스트 세트를 사용하지 않으면 모델이 적절히 학습됐는지 판단하기 어렵다.
테스트 세트를 사용하지 않고 이를 측정하는 간단한 방법은 훈련 세트를 또 나누는 것이다!
이렇게 나눈 데이터를 검증 세트라고 한다.

5-1에서 전체 데이터 중 20%를 테스트 세트, 80%를 훈련 세트로 만들었다.
이 훈련 세트 중에서 다시 20%를 떼어 내어 검증 세트로 만들자.
# 📌 데이터 준비
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine_csv_data')
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()# 📌 훈련 세트, 테스트 세트 분할
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
# 20%만 테스트 세트로 나눠준다. (test_size=0.2)# 📌 훈련 세트, 검증 세트 분할
sub_input, val_input, sub_target, val_target = train_test_split(train_input, train_target, test_size=0.2, random_state=42)
# input은 data 대신에 train_input,
# target은 target 대신에 train_target 을 사용해준다.
# 20%만 검증 세트로 나눠준다. (test_size=0.2)
print(sub_input.shape, val_input.shape) # 훈련 세트, 검증 세트의 크기 확인>>> (4157, 3) (1040, 3)
# 원래 훈련 세트: 5,197개 --> 4,157개
# 검증 세트: 1,040개# 📌 검증 세트를 사용해 모델 훈련+평가
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(sub_input, sub_target)
print(dt.score(sub_input, sub_target))
print(dt.score(val_input, val_target))>>> 0.9971133028626413
0.864423076923077
결과를 보니 과대적합되어있다. 매개변수를 바꿔 더 좋은 모델을 찾아야하는데, 어떻게?
교차 검증
== Cross Validation
교차 검증은 검증 세트를 떼어 내어 평가하는 과정을 여러 번 반복한다.
그 다음 이 점수를 평균하여 최종 검증 점수를 얻어낸다.
아래는 3-폴드 교차 검증의 그림이다.
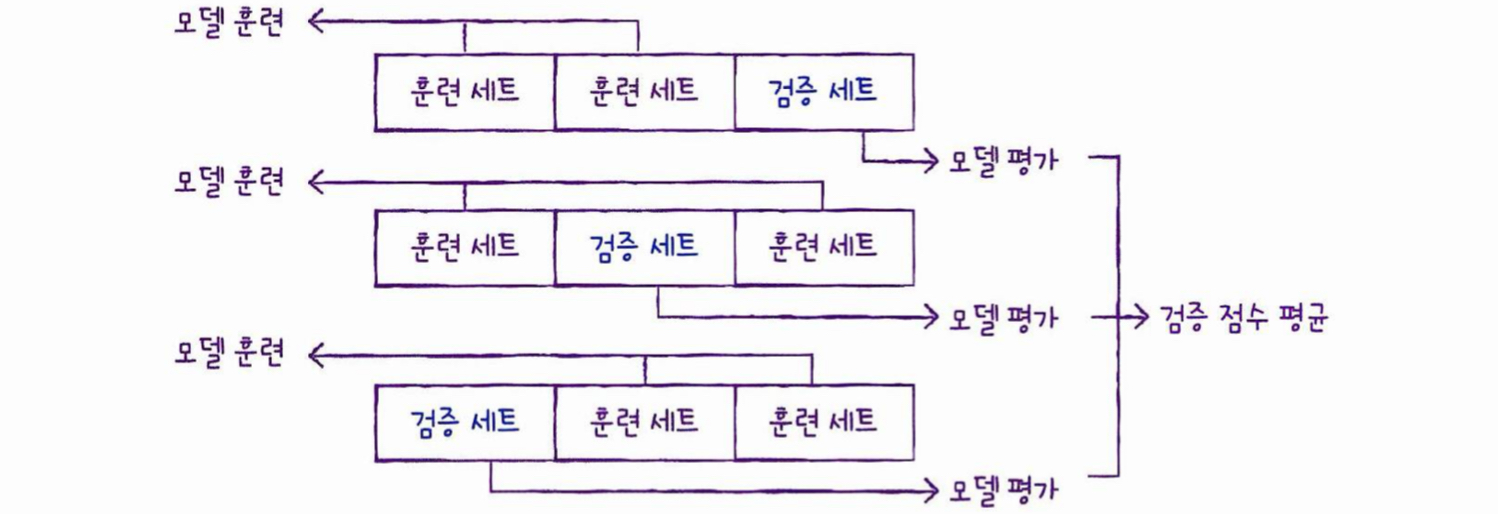
K-폴드 교차 검증 (K-fold cross validation)
훈련 세트를 k 부분으로 나눠서 교차 검증을 수행하는 것을 k-폴드 교차 검증이라 부른다.
사이킷런에서cross_validate()함수로 제공된다.
cross_validate()
교차 검증을 수행하는 함수이다.
첫번째 매개변수에 교차 검증을 수행할 모델 객체를, 두번째와 세번째 매개변수에 특성과 타깃 데이터를 전달한다.
scoring매개변수는 검증에 사용할 평가 지표를 지정할 수 있다.
(분류 모델의 기본값 = 정확도를 의미하는 'accuracy')
(회귀 모델의 기본값 = 결정계수를 의미하는 'r2')
cv매개변수는 교차 검증의 폴드 수(k)를 지정할 수 있다. (기본값 = 5)
n_jobs매개변수는 교차 검증을 수행할 때 사용할 CPU 코어 수를 지정한다. (기본값 = 1)
(-1로 지정하면 시스템의 모든 코어 사용)
return_train_score매개변수를 True로 지정하면 훈련 세트의 점수도 반환한다.
(기본값 = False)
from sklearn.model_selection import cross_validate
scores = cross_validate(dt, train_input, train_target)
print(scores)>>> {'fit_time': array([0.01341891, 0.02167416, 0.02525187, 0.04882073, 0.03598666]),
'score_time': array([0.0027864 , 0.0019815 , 0.00886154, 0.01437068, 0.02624893]),
'test_score': array([0.86923077, 0.84615385, 0.87680462, 0.84889317, 0.83541867])}
# 3개의 키를 가진 딕셔너리를 반환한다.
# 기본적으로 5-폴드 교차 검증을 수행한 것을 볼 수 있다.교차 검증의 최종 점수는 test_score 키에 담긴 5개의 점수를 평균하여 얻을 수 있다.
import numpy as np
print(np.mean(scores['test_score']))>>> 0.855300214703487+) 주의
분류 모델은 훈련 세트를 섞어 폴드를 나누어주어야 하는데,
cross_validation() 함수는 기본적으로 훈련 세트를 섞어 폴드를 나누지 않는다.
교차 검증을 할때 훈련 세트를 섞으려면 분할기(splitter)를 지정해야한다.
분류 모델일 경우엔 StratifiedKFold 사용.
# 앞서 수행한 교차검증과 같은 내용을 수행
from sklearn.model_selection import StratifiedKFold
scores = cross_validate(dt, train_input, train_target, cv=StratifiedKFold())
print(np.mean(scores['test_score']))
# >>> 0.855300214703487만약 훈련 세트를 섞은 후 10-폴드 교차 검증을 수행하려면 아래와 같이 작성한다.
# 몇(k)폴드 교차 검증을 할지 지정
splitter = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)
scores = cross_validate(dt, train_input, train_target, cv=StratifiedKFold())
print(np.mean(scores['test_score']))
# >>> 0.855300214703487이제 교차 검증에 대해 이해했으니, 결정 트리의 매개변수 값을 바꿔가며 가장 좋은 성능이 나오는 모델을 찾아보자. (테스트 세트를 사용하지 않고 교차 검증을 통해서 좋은 모델을 고른다)
하이퍼파라미터 튜닝
하이퍼파리미터는 사용자가 지정해야만 하는 파라미터이다.
성능이 좋아지는 파라미터를 찾는 하이퍼파라미터 튜닝은 어떻게 하는걸까?
그리드 서치
여러 매개변수의 최적의 값을 찾는건 여러 반복문을 통해 이뤄지는데, 이미 만들어진 도구가 있다.
그 중 하나가 그리드 서치인데, 사이킷런에서 GridSearchCV 클래스를 제공한다.
이 클래스는 친절하게도 하이퍼파라미터 탐색과 교차 검증을 한 번에 수행해준다.
GridSearchCV()
교차 검증으로 하이퍼파라미터 탐색을 수행한다.
최상의 모델을 찾은 후 훈련 세트 전체를 사용해 최종 모델을 훈련한다.
첫번째 매개변수로 그리드 서치를 수행할 모델 객체를, 두번째 매개변수에는 탐색할 모델의 매개변수와 값을 전달한다.
scoring,cv,n_jobs,return_train_score매개변수는 cross_validate() 함수와 동일
탐색할 매개변수 값 모두에 대해 교차검증을 수행한다!
결정 트리 모델에서 min_impurity_decrease 매개변수의 최적값을 찾아보자.
# 📌 먼저, 탐색할 매개변수, 탐색할 값의 리스트(우선 임의로 지정)를 딕셔너리로 만든다.
from sklearn.model_selection import GridSearchCV
params = {'min_impurity_decrease': [0.0001, 0.0002, 0.0003, 0.0004, 0.0005]}
# 📌 GridSearchCV 클래스에 탐색 대상 모델과 params 변수를 전달하여 객체 생성
gs = GridSearchCV(DecisionTreeClassifier(random_state=42),params, n_jobs=1)
# 📌 그리드 서치 수행
gs.fit(train_input, train_target)
# --> cv매개변수의 기본값은 5이므로 5*5=25개의 모델을 훈련하게 된다.그리드 서치는 훈련이 끝나면 여러가지의 모델 중에서 검증 점수가 가장 높은 모델의 매개변수 조합으로 전체 훈련 세트에서 자동으로 다시 모델을 훈련한다!
# 📌 가장 높은 점수의 모델은 gs 객체의 best_estimator_ 속성에 저장된다.
dt = gs.best_estimator_
print(dt.score(train_input, train_target))
# >>> 0.9615162593804117
# 📌 그리드 서치로 찾은 최적의 매개변수는 best_params_ 속성에 저장된다.
print(gs.best_params_)
# >>> {'min_impurity_decrease': 0.0001}
# 📌 각 매개변수에서 수행한 교차 검증의 평균 점수는 cv_results 속성의 'mean_test_score' 키에 저장된다.
print(gs.cv_results_['mean_test_score'])
# >>> [0.86819297 0.86453617 0.86492226 0.86780891 0.86761605]
# 📌 직접 구한 매개변수 조합이 gs.best_params_와 동일한지 확인해보자.
best_index = np.argmax(gs.cv_results_['mean_test_score'])
print(gs.cv_results_['params'][best_index])
# >>> {'min_impurity_decrease': 0.0001}이제 조금 더 복잡한 매개변수 조합을 탐색해보자.
아까는 'min_impurity_decrease' 매개변수 하나만을
[0.0001, 0.0002, 0.0003, 0.0004, 0.0005]의 리스트 내에서만 탐색했지만,
이번엔 여러 매개변수에서 arange, range함수를 사용해 매개변수 값 리스트를 만들어 탐색할 것이다.
# 📌 탐색할 매개변수, 탐색할 값의 리스트를 딕셔너리로 만든다.
params = {'min_impurity_decrease': np.arange(0.0001, 0.001, 0.0001),
'max_depth': range(5, 20, 1),
'min_samples_split': range(2, 100, 10)
}
# arange 함수: 첫번째 매개변수 값에서 두번째 매개변수에 도달할 때까지 세번째 매개변수를 계속 더한 배열을 만듬
# range 함수: arange함수와 동일하나, 정수에서만 사용 가능
# 📌 그리드 서치 수행 # 만들어지는 모델의 수가 많으므로 최대 CPU 사용
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
# 📌 최상의 매개변수 조합 확인
print(gs.best_params_)
# >>> {'max_depth': 14, 'min_impurity_decrease': 0.0004, 'min_samples_split': 12}
# 📌 최상의 교차 검증 점수 확인
print(np.max(gs.cv_results_['mean_test_score']))
# >>> 0.8683865773302731좋은 결과가 나왔다! 하지만,
탐색할 매개변수의 간격을 0.0001 혹은 1로 임의로 설정했는데,
이를 미리 정하기가 어려운거 같다. 어떻게 해야할까?
랜덤 서치
랜덤 서치란, 하이퍼파라미터 값들을 일정횟수 만큼 무작위로 샘플링하여 탐색하는 방법이다.
사이킷런에서 RandomizedSearchCV 클래스로 제공된다.
randint() 과 uniform()
둘 다 주어진 범위에서 고르게 값을 뽑는다. (균등 분포에서 샘플링한다)
randint는 정숫값을, uniform은 실숫값을 뽑는다.from scipy.stats import uniform, randint # 📌 0~10 범위에서 randint로 10개의 정수 샘플링 rgen = randint(0, 10) rgen.rvs(10) # >>> array([1, 3, 9, 4, 4, 5, 6, 7, 9, 2]) # 📌 0~1 범위에서 uniform으로 10개의 실수 샘플링 ugen = uniform(0, 1) ugen.rvs(10) # >>> array([0.98190469, 0.21027677, 0.55010361, 0.68042272, 0.84064129, 0.95906507, 0.29501035, 0.22313601, 0.77810409, 0.14792308])
RandomizedSearchCV()
교차 검증으로 랜덤한 하이퍼파라미터 탐색을 수행한다.
최상의 모델을 찾은 후 훈련 세트 전체를 사용해 최종 모델을 훈련한다.
첫번째 매개변수로 그리드 서치를 수행할 모델 객체를, 두번째 매개변수에는 탐색할 모델의 매개변수와 값을 전달한다.
scoring,cv,n_jobs,return_train_score매개변수는 cross_validate() 함수와 동일
n_iter매개변수는 랜덤으로 몇번 샘플링하여 교차검증을 수행할지 지정한다.(기본값=10)
랜덤 서치로 탐색해보자.
# 📌 탐색할 값의 리스트를 randint, uniform 을 사용해 랜덤하게 만든다.
from scipy.stats import uniform, randint
params = {'min_impurity_decrease': uniform(0.0001, 0.001),
'max_depth': randint(20, 50),
'min_samples_split': randint(2, 25),
'min_samples_leaf': randint(1, 25),
} # 리프 노드가 되기 위한 최소 샘플의 개수 (min_samples_leaf) 매개변수 추가
# 📌 랜덤 서치 수행
from sklearn.model_selection import RandomizedSearchCV
gs = RandomizedSearchCV(DecisionTreeClassifier(random_state=42), params, n_iter=100, n_jobs=-1, random_state=42)
# 총 100번을 (n_iter=100) 샘플링하여 교차검증 수행
gs.fit(train_input, train_target)
# 📌 최상의 매개변수 조합 확인
print(gs.best_params_)
# >>> {'max_depth': 39, 'min_impurity_decrease': 0.00034102546602601173, 'min_samples_leaf': 7, 'min_samples_split': 13}
# 📌 최상의 교차 검증 점수 확인
print(np.max(gs.cv_results_['mean_test_score']))
# >>> 0.8695428296438884
# 📌 최상의 모델 best_estimator을 최종 모델로 결정하고, 테스트 세트의 성능을 확인해보자.
dt = gs.best_estimator_
print(dt.score(test_input, test_target))
# >>> 0.86테스트 세트 점수는 검증 세트에 대한 점수보다 약간 작은 것이 일반적이다.
나름 만족스러운 점수가 나온듯 하다!
