[혼자 공부하는 머신러닝+딥러닝] 교재 5장을 기반으로 작성되었습니다.
지금까지 여러가지 머신러닝 알고리즘을 배웠지만,
대체적으로 가장 성능이 좋은 알고리즘은 무엇일까?
+) 물론, 문제마다 각 알고리즘의 성능이 다르다. "대체적으로" 의 얘기이다.정형 데이터와 비정형 데이터
지금까지 우리가 사용한 CSV파일과 같이,
어떤 구조로 가지런히 정리되어 있는 형태의 데이터를 정형 데이터라고 한다.
이와 반대로 사진, 음악 등 정갈한 데이터베이스로 표현하기 어려운 데이터를 비정형 데이터라고 한다.
위의 정형 데이터를 다루는 데 가장 뛰어난 성과를 내는 알고리즘이 앙상블 학습이다.
앙상블 학습 (Ensemble Learning)
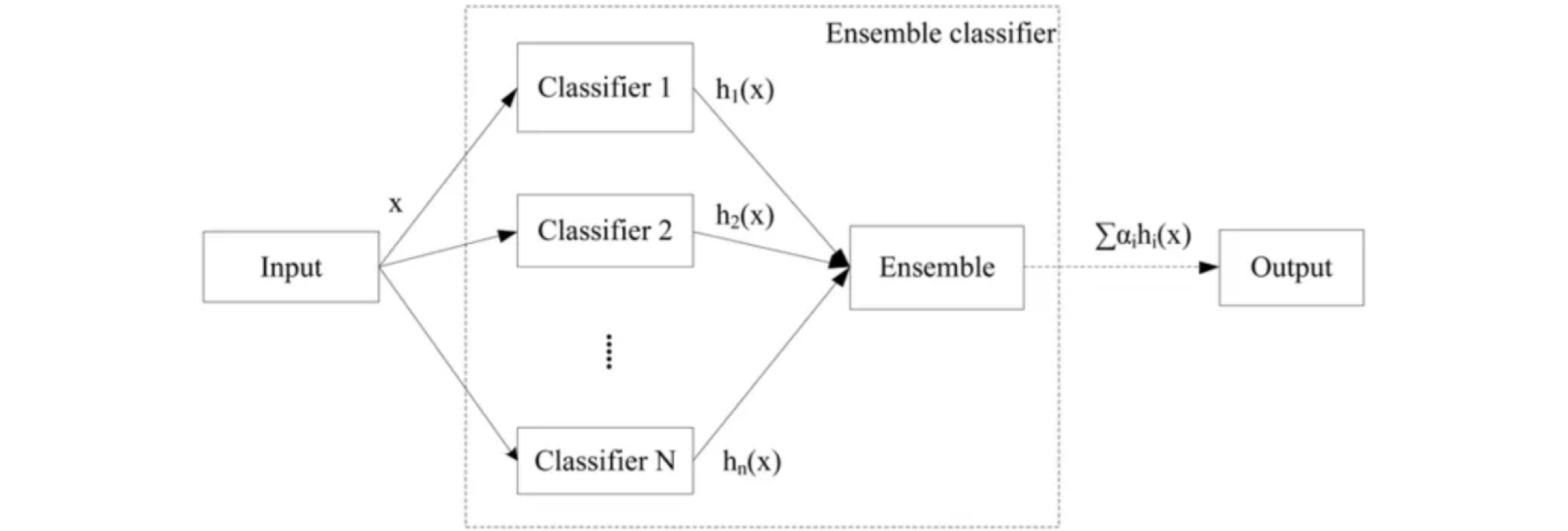
앙상블 학습은 여러 개의 개별 모델을 조합하여 최적의 모델로 일반화하는 방법이다.
위의 사진은 회귀문제의 예시인데, weak classifier들을 결합하여 strong classifier을 만든다.
결정트리에서 과대적합되는 문제를 감소시킨다는 장점이 있다.
그럼 비정형 데이터는 어떤 알고리즘을 사용해야할까?
==> 신경망 알고리즘 (7장에서 배울것)
랜덤 포레스트
랜덤 포레스트는 앙상블 학습의 대표 주자 중 하나로, 안정적인 성능을 갖는다.
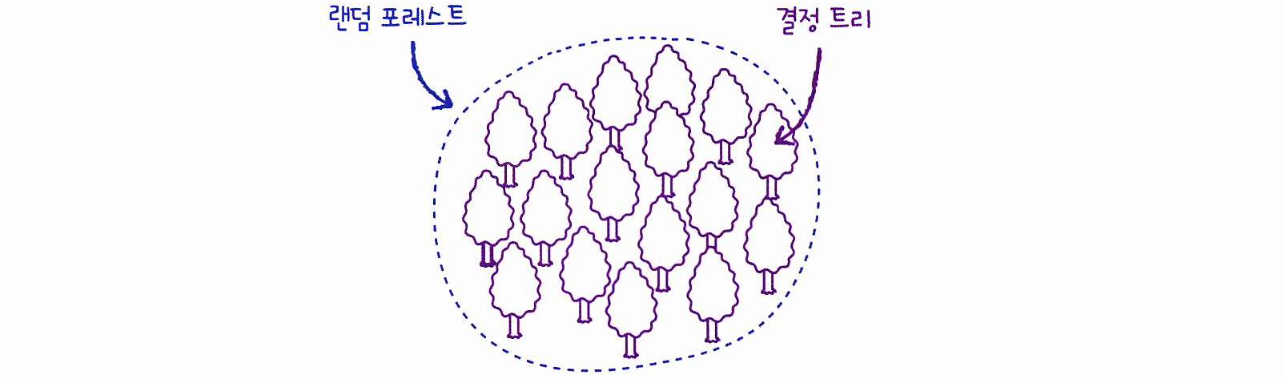
이름에서 알 수 있듯이, 랜덤 포레스트는 결정 트리를 랜덤하게 만들어 결정 트리의 숲을 만든다.
그리고 각 결정 트리의 예측을 사용해 최종 예측을 만든다.
여기서 각 트리를 훈련하기 위한 데이터를 랜덤하게 만드는데, 부트스트랩 방식을 사용한다.
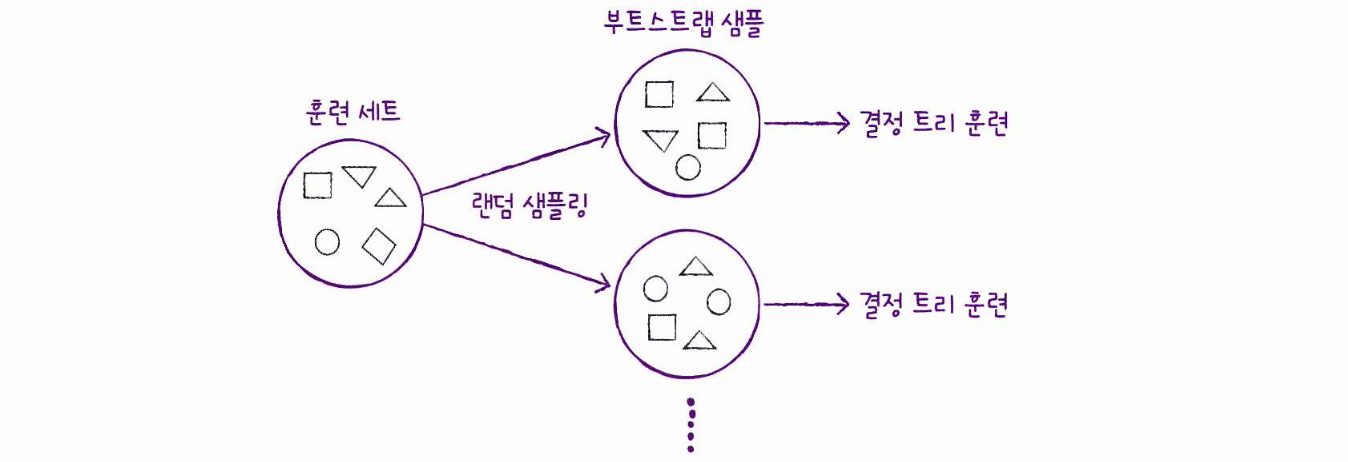
부트스트랩
데이터 세트에서 중복을 허용하여 데이터를 샘플링하는 방식. (복원 추출)
ex) 1,000개의 샘플이 들어있는 가방에서 100개의 샘플을 뽑는다면,
먼저 1개를 뽑고, 뽑았던 1개를 다시 가방에 넣는다. 이 과정을 100번 반복.
이렇게 만들어진 샘플을 부트스트랩 샘플이라 한다.
또한 각 노드를 분할할 때 전체 특성 중에서 일부 특성을 무작위로 고른 다음,
이 중에서 최선의 분할을 찾는다.
분류 모델인 RandomForestClassifier 는 (전체 특성 개수의 제곱근)만큼 특성을 선택하고,
회귀 모델인 RandomForestRegressor 는 전체 특성을 모두 사용한다.
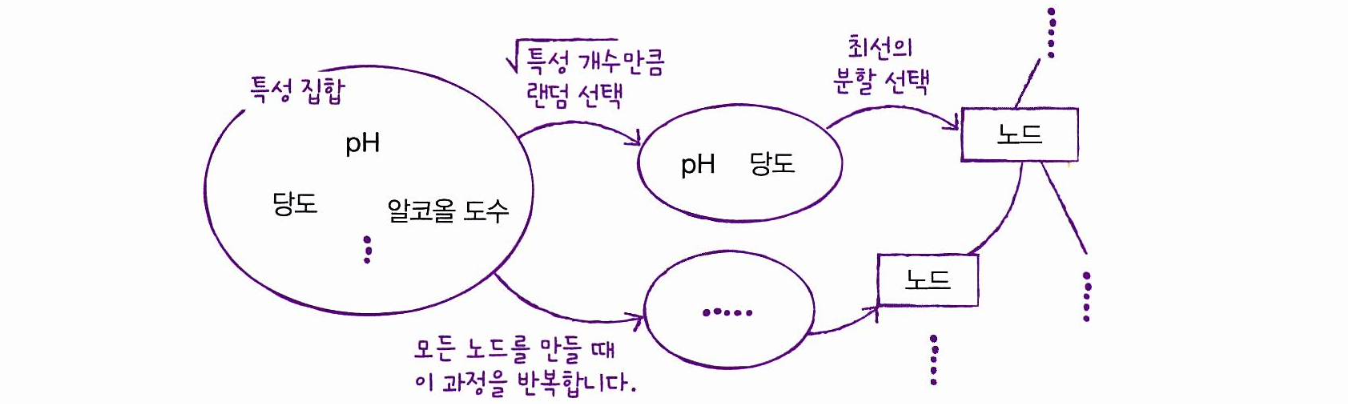
사이킷런의 랜덤 포레스트는 기본적으로 이런 방식으로 100개의 결정 트리를 훈련하는데,
분류일 때는 각 트리의 클래스별 확률을 평균하여 가장 높은 확률을 가진 클래스를 예측으로 삼고,
회귀일 때는 단순히 각 트리의 예측을 평균한다.
이제 RandomForestClassifier 클래스를 화이트 와인을 분류하는 문제에 적용해보자.
# 📌 데이터 준비
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
wine = pd.read_csv('https://bit.ly/wine_csv_data')
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
# 📌 랜덤 포레스트의 교차검증 점수
from sklearn.model_selection import cross_validate
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(rf, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
# >>> 0.9973541965122431 0.8905151032797809# 📌 특성 중요도 출력
'''랜덤 포레스트의 특성 중요도 = 각 결정트리의 특성 중요도의 취합'''
rf.fit(train_input, train_target)
print(rf.feature_importances_)>>> [0.23167441 0.50039841 0.26792718]결정트리에서 얻은 특성 중요도는
[0.12345626 0.86862934 0.26792718] 였는데,
랜덤 포레스트가 특성의 일부를 랜덤하게 선택하여 결정트리를 훈련하기 때문에
하나의 특성에 과도하게 집중하지 않고 좀 더 많은 특성이 훈련에 기여하는 걸 볼 수 있다.
이는 *과대적합을 줄이고 일반화 성능을 높인다.*# 📌 OOB 점수 출력
'''OOB(Out_Of_Bag)샘플: 부트스트랩 샘플에 포함되지 않고 남는 샘플 '''
'''OOB점수는 교차검증과 비슷한 역할을 할 수 있다!'''
rf = RandomForestClassifier(oob_score=True, n_jobs=-1, random_state=42)
rf.fit(train_input, train_target)
print(rf.oob_score_)
# >>> 0.8934000384837406
# 교차검증에서 얻은 점수와 비슷한 결과!엑스트라 트리
엑스트라 트리도 앙상블 기법 중 하나로, 랜덤 포레스트와 매우 비슷하게 동작한다.
랜덤 포레스트와 엑스트라 트리의 차이점은 아래와 같다.
부트스트랩 샘플을 사용하지 않는다. 즉, 각 결정 트리를 만들 때 전체 훈련 세트를 사용한다.
또한, 노드를 분할할 때 가장 좋은 분할을 찾지 않고 무작위로 분할한다.
# 📌 엑스트라 트리의 교차검증 점수
from sklearn.ensemble import ExtraTreesClassifier
et = ExtraTreesClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(et, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
# >>> 0.9974503966084433 0.8887848893166506
# 램덤 포레스트와 비슷한 결과결정 트리는 최적의 분할을 찾는데 시간을 많이 소모한다. (고려할 특성의 개수가 많을 땐 더욱)
그렇기에 랜덤하게 노드를 분할하는 엑스트라 트리는 빠른 계산 속도가 장점이다.
# 📌 특성 중요도 출력
et.fit(train_input, train_target)
print(et.feature_importances_)>>> [0.20183568 0.52242907 0.27573525]
결정트리보다 당도(두번째 클래스)에 대한 의존성이 작다.그레이디언트 부스팅
그레이디언트 부스팅은 부스팅(boosting)에 속하는 앙상블 기법 중 하나로,
깊이가 얕은 결정 트리를 사용하여 이전 트리의 오차를 보완하는 방식이다.
bagging에서 각각의 모델이 독립적으로 학습하는 반면, boosting은 이전 모델의 학습 결과가 다음 모델에 영향을 미치며 순차적으로 보완된다.
경사하강법을 사용하여 트리를 앙상블에 추가한다.
결정트리를 계속 추가하면서 가장 낮은 곳을 찾아 이동하는데, 그렇기 때문에 깊이가 얕은 트리를 사용한다.
# 📌 그레이디언트 부스팅 의 교차검증 점수
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(random_state=42)
scores = cross_validate(gb, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
# >>> 0.8881086892152563 0.8720430147331015
"""----------------------------------------------
과대적합이 거의 되지 않는다!
학습률을 증가시키고 트리의 개수를 늘려 성능을 향상시켜보자.
----------------------------------------------"""
gb = GradientBoostingClassifier(n_estimators=500, learning_rate=0.2, random_state=42)
scores = cross_validate(gb, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
# >>> 0.9464595437171814 0.8780082549788999# 📌 특성 중요도 출력
gb.fit(train_input, train_target)
print(gb.feature_importances_)>>> [0.15887763 0.6799705 0.16115187]
랜덤 포레스트보다 일부 특성에 더 집중한다.일반적으로 그레이디언트 부스팅이 랜덤 포레스트보다 조금 더 높은 성능을 보인다.
하지만 순차적으로 트리를 추가해 보완하기 때문에 훈련 속도가 느리다.
이런 그레이디언트 부스팅의 속도와 성능을 더욱 개선한 것이
히스토그램 기반 그레이디언트 부스팅이다.
히스토그램 기반 그레이디언트 부스팅
정형 데이터를 다루는 머신러닝 알고리즘 중에 가장 인기가 높은 알고리즘이다.
히스토그램 기반 그레이디언트 부스팅은 먼저, 입력 특성을 256개의 구간으로 나눈다.
따라서 노드를 분할할 때 최적의 분할을 매우 빠르게 찾을 수 있다.
from sklearn.ensemble import HistGradientBoostingClassifier
hgb = HistGradientBoostingClassifier(random_state=42)
scores = cross_validate(hgb, train_input, train_target, return_train_score=True)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))>>> 0.9321723946453317 0.8801241948619236
과대적합을 잘 억제하며 그레이디언트 부스팅보다 좀 더 높은 성능을 보인다.히스토그램 기반 그레이디언트 부스팅의 특성 중요도를 계산하기 위해 permutation_importance() 함수를 사용한다.
이 함수는 특성을 하나씩 랜덤하게 섞어서 모델의 성능이 변화하는지를 관찰하여 어떤 특성이 중요한지를 계산한다.
# 📌 훈련세트에서의 특성 중요도
from sklearn.inspection import permutation_importance
hgb.fit(train_input, train_target)
result = permutation_importance(hgb, train_input, train_target, n_repeats=10, random_state=42, n_jobs=-1)
print(result.importances_mean)
# >>> [0.08876275 0.23438522 0.08027708]# 📌 테스트세트에서의 특성 중요도
from sklearn.inspection import permutation_importance
hgb.fit(train_input, train_target)
result = permutation_importance(hgb, test_input, test_target, n_repeats=10, random_state=42, n_jobs=-1)
print(result.importances_mean)
# >>> [0.05969231 0.20238462 0.049 ]그레이디언트 부스팅과 비슷하게 조금 더 당도에 집중하고 있는 것을 볼 수 있다.그러면, 이제 HistGradientBoostingClassifier 를 사용해 테스트 세트에서의 성능을 최종적으로 확인해보자.
hgb.score(test_input, test_target)
# >>> 0.8723076923076923이전 5-2장에서 랜덤 서치에서 최종 테스트 정화도로 86%를 얻은 것을 기억해보면,
확실히 앙상블 모델은 단일 결정트리보다 더 좋은 결과를 얻을 수 있다는 걸 확인할 수 있다!
사이킷런 외에도, 그레이디언트 부스팅 알고리즘을 구현한 라이브러리가 여럿 있는데,
대표적으로 XGBoost가 있다.
"""tree_method 매개변수를 hist로 지정하면 히스토그램 기반 그레이디언트 부스팅을 사용할 수 있다."""
from xgboost import XGBClassifier
xgb = XGBClassifier(tree_method='hist', random_state=42)
scores = cross_validate(xgb, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
# >>> 0.9558403027491312 0.8782000074035686
또한, 히스토그램 기반 그레이디언트 부스팅 라이브러리는 LightGBM이 있다.
from lightgbm import LGBMClassifier
lgb = LGBMClassifier(random_state=42)
scores = cross_validate(lgb, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
# >>> 0.935828414851749 0.8801251203079884앙상블 기법에는 보팅voting, 배깅bagging, 부스팅boosting, 스태킹stacking이 있다.
bagging엔 랜덤 포레스트가 대표적인데, bootstrap aggregation 의 약자이다.
-bootstrap으로 데이터를 추출하고, 각 모델의 예측 결과를 평균 내서 종합(aggregate)해서 판단boosting엔 대표적으로 Gradient Boosting이 있고, XGBoost, LightGBM, AdaBoost가 있다.
