가장 빠르게 도달하는 방법
최단 경로 알고리즘은 말 그대로 가장 짧은 경로를 찾는 알고리즘입니다.
그래서 '길 찾기' 문제라고도 불립니다.
최단 경로는 '한 지점에서 다른 특정 지점까지의 최단 경로를 구해야 하는 경우', '모든 지점에서 다른 모든 지점까지의 최단 경로를 모두 구해야 하는 경우'등의 다양한 예시가 있습니다.
보통 그래프를 이용해 표현하는데 각 지점은 그래프에서 '노드'로 표현되고 지점간 연결된 도로는 그래프에서 '간선'으로 표현됩니다.
그리디 알고리즘과 다이나믹 프로그래밍 알고리즘이 최단 경로 알고리즘에 그대로 적용된다는 특징이 있습니다. 다시 말해 최단 경로 알고리즘은 그리디 알고리즘 및 다이나믹 프로그래밍 알고리즘 한 유형으로 볼 수 있습니다.
다익스트라 최단 경로 알고리즘
다익스트라 최단 경로 알고리즘은 그래프에서 여러 개의 노드가 있을 때, 특정한 노드에서 출발하여 다른 노드로 가는 각각의 최단 경로를 구해주는 알고리즘입니다. 다익스트라 최단 경로 알고리즘은 '음의 간선'이 없을 때 정상적으로 동작합니다. 만약 음의 간선이 존재한다면 벨만 포드 알고리즘으로 문제를 풀이할 수 있는데, 벨만 포드 알고리즘은 링크에서 확인할 수 있습니다.
다익스트라 최단 경로 알고리즘은 기본적으로 그리디 알고리즘으로 분류됩니다. 매번 '가장 비용이 적은 노드'를 선택해서 임의의 과정을 반복하기 떄문입니다. 알고리즘의 원리는 다음과 같습니다.
-
출발 노드를 설정합니다.
-
최단 거리 테이블을 초기화합니다.(1차원 리스트로 표현)
-
방문하지 않은 노드 중에서 최단 거리가 가장 짧은 노드를 선택합니다.
-
해당 노드를 거쳐 다른 노드로 가는 비용을 계산하여 최단 거리 테이블을 갱신합니다.
-
위 과겅에서 3과 4번을 반복합니다.
다익스트라 알고리즘은 최단 경로를 구하는 과정에서 '각 노드에 대한 현재까지의 최단 거리' 정보를 항상 1차원 리스트에 저장하며 리스트를 계속 갱신합니다. 매번 현재 처리하고 있는 노드를 기준으로 주변 간선을 확인합니다. 따라서 '방문하지 않은 노늗 중에서 현재 최단 거리가 가장 짧은 노드를 확인'해 그 노드에 대해 4번 과정을 수행한다는 점에서 그리디 알고리즘으로 볼 수 있습니다.
구현하기
다익스트라 알고리즘은 두 개로 구현하는데 하나는 시간 복잡도가 O(V*V)이고 다른 하나는 최악의 경우에도 O(ElogV)를 보장합니다.(E는 간선의 개수, V는 노드의 개수)
최악의 경우에도 O(ElogV)를 보장하는 다익스트라 알고리즘을 구현할 것인데 힙 자료구조를 사용하여 구현합니다.
힙
힙 자료구조는 우선순위 큐를 구현하기 위하여 사용하는 자료구조 중 하나입니다.
우선순위 큐는 우선 순위가 가장 높은 데이터를 가장 먼저 삭제한다는 점이 특징입니다.
스택, 큐, 우선순위 큐 자료구조를 비교하면 다음과 같습니다.
| 자료구조 | 추출되는 데이터 |
|---|---|
| 스택(Stack) | 가장 나중에 삽입된 데이터 |
| 큐(Queue) | 가장 먼저 삽입된 데이터 |
| 우선순위 큐(Priority Queue) | 가장 우선순위가 높은 데이터 |
이런 우선순위 큐는 데이터를 우선순위에 따라 처리하고 싶을 때 유용합니다. 예를 들어 여러 개의 물건 데이터를 자료구조에 넣었다가 가치가 높은 물건 데이터부터 꺼내서 확인하는 경우 우선순위 큐 자료구조를 이용하면 효과적입니다. 우선순위 큐 라이브러이에 데이터의 묶음을 넣으면, 첫 번째 원소를 기준으로 우선순위를 설정합니다. 그 후 우선순위 큐에서 데이터를 꺼내면, 항상 가치가 높은 물건이 먼저 나오게 됩니다.
파이썬에서는 우선순위 큐가 필요할 때 PriorityQueue 혹은 heapq를 사용하는데 heapq가 일반적으로 더 빠르게 동작하기 때문에 heapq를 많이 사용합니다.
우선순위 큐를 구현할 때는 내부적으로 최소 힙 혹은 최대 힙을 이용합니다. 최소 힙을 이용하는 경우 '값이 낮은 데이터가 먼저 삭제'되며, 최대 힙을 이용하는 경우 '값이 큰 데이터가 먼저 삭제'됩니다. 파이썬 라이브러리에서는 기본적으로 최소 힙 구조를 이용하는데 다익스트라 최단 알고리즘에서는 비용이 적은 노드를 우선하여 방문하므로 최소 힙 구조를 기반으로 하는 파이썬의 우선순위 큐 라이브러리를 그대로 사용하면 적합합니다.
참조(최대 힙)
또한 최소 힙을 최대 힙처럼 사용하기 위해서 일부러 우선순위에 해당하는 값에 음수 부호(-)를 붙여서 넣었다가, 나중에 우선순위 큐에서 꺼낸 다음에 다시 음수 부호를 붙여서 원래의 값으로 돌리는 방식을 사용할 수 있습니다.
우선순위 큐를 구현하는 방식은 힙 말고도 다양합니다. 다만 리스트를 이용하는 것과 힙을 이용하는 경우의 삽입과 삭제의 시간 복잡도가 다릅니다. 데이터의 개수가 N개일 때, 리스트릴 이용하는 것과 힙을 이용하는 것의 시간복잡도는 아래와 같습니다.
| 우선순위 큐 구현 방식 | 삽입 시간 | 삭제 시간 |
|---|---|---|
| 리스트 | O(1) | O(N) |
| 힙 | O(logN) | O(logN) |
리스트를 이용한다면 삭제할 때 최악의 경우 O(N) 시간이 소요됩니다. 그렇기에 힙 자료구조를 이용해 우선순위 큐를 구현하여 최악의 경우에도 O(logN)을 보장할 수 있도록 합니다.
구현 예시
현재 가장 가까운 노드를 저장하기 위한 목적으로만 우선순위 큐를 추가로 이용합니다.
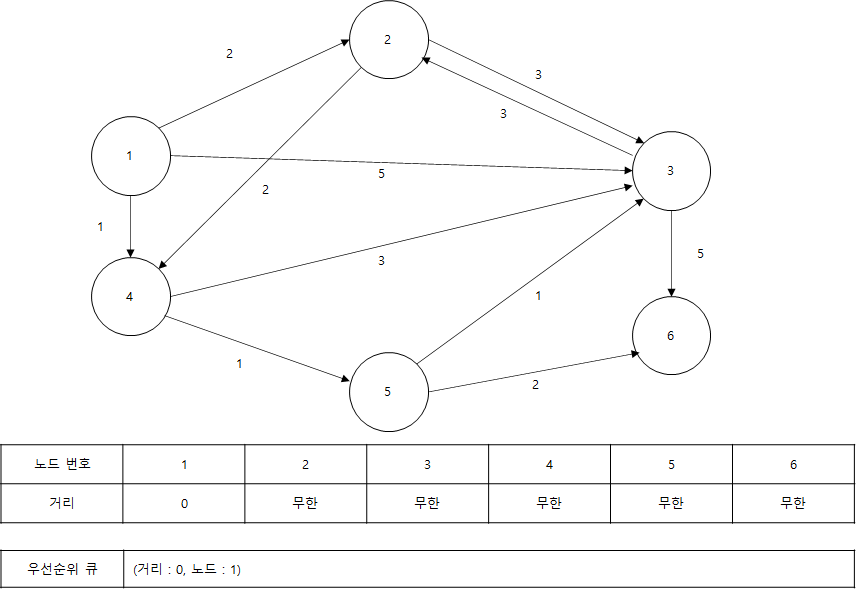
- 1번 노드가 출발 노드인 경우입니다. 여기서 다음과 같이 출발 노드를 제외한 모든 노드의 최단 거리를 무한으로 설정합니다. 이후 우선순위 큐에 1번 노드를 넣습니다. 이때 1번 노드로 가는 거리는 자기 자신까지 도달하는 거리기에 0이므로 (거리: 0, 노드: 1)의 정보를 가지는 객체를 우선순위 큐에 넣으면 됩니다.
파이썬에서는 간단히 튜플(0, 1)을 우선순위 큐에 넣습니다. 파이썬의 heapq 라이브러리는 원소로 튜플을 입력받으면 튜플의 첫 번째 원소를 기준으로 우선순위 큐를 구성합니다. 따라서 (거리, 노드번호) 순서대로 튜플 데이터를 구성해 우선순위 큐에 넣으면 거리순으로 정렬됩니다.
- 기본적으로 거리가 짧은 원소가 우선순위 큐의 최상위 원소로 위치해 있기에 거리가 가장 짧은 노드를 선택하기 위해서 그냥 노드를 꺼내면 됩니다. 따라서 우선순위 큐에서 노드를 꺼낸 뒤에 해당 노드를 이미 처리한 적 있다면 무시하면 되고, 아직 처리하지 않은 노드에 대해서만 처리하면 됩니다.
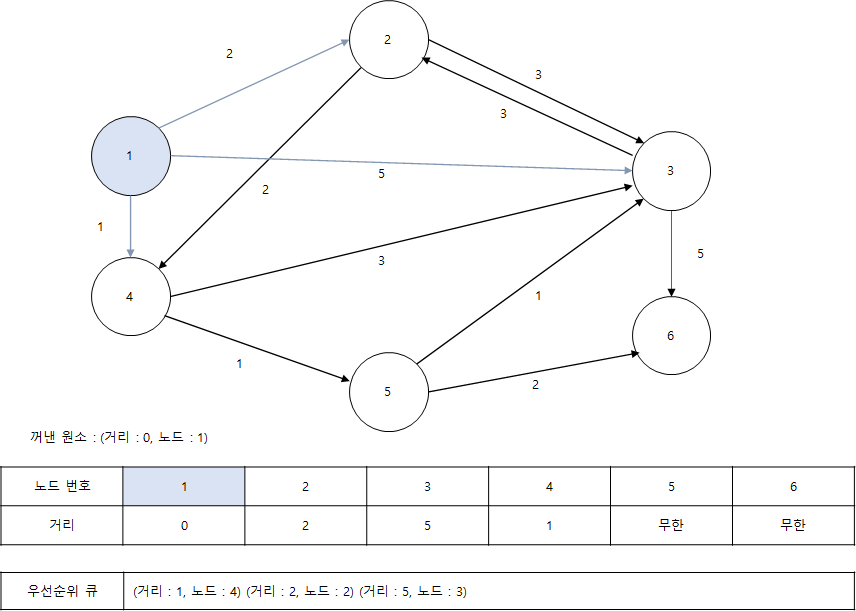
이제 우선순위 큐에서 노드를 꺼내면 (0, 1)이 나오는데, 이는 1번 노드까지 가는 최단 거리가 0이라는 의미로 1번 노드를 거쳐서 2번, 3번, 4번 노드로 가는 최소 비용을 계산합니다.
차례대로 2(0 + 2), 5(0 + 5), 1(0 + 1) 입니다. 현재 2번, 3번, 4번 노드로 가는 비용이 '무한'으로 설정되어 있는데, 거리가 더 짧은 경로를 찾았으므로 각각 갱신하면 됩니다. 이렇게 더 짧은 경로를 찾은 노드 정보들은 다시 우선순위 큐에 넣습니다. 현재 처리 중인 노드와 간선은 하늘색으로, 이전 단계에서 처리한 노드와 간선은 회색입니다.
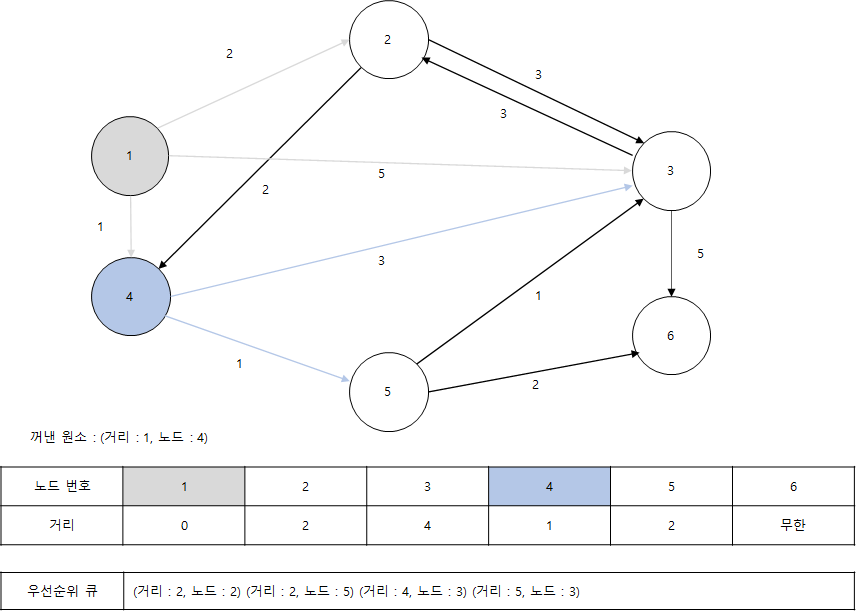
- 이어서 다시 우선순위 큐에서 원소를 꺼내서 동일한 과정을 반복합니다. 이번에는 (1, 4)의 값을 갖는 원소가 추출됩니다. 아직 노드 4를 방문하지 않았으며, 현재 최단 거리가 가장 짧은 노드가 4입니다. 따라서 노드 4를 기준으로 노드 4와 연결된 간선을 확인합니다. 이때 4번 노드까지의 최단거리는 1이므로 4번 노드를 거쳐서 3번과 5번 노드로 가는 최소 비용은 차례대로 4(1 + 3)과 2(1 + 1)입니다. 이는 기존의 리스트에 담겨 있던 값들 보다 작기 때문에 리스트가 갱신되고, 우선순위 큐에는 (4, 3), (2, 5)라는 두 원소가 추가로 들어갑니다. 우선순위 큐에는 원소(거리)가 작은 순서대로 왼쪽부터 기록합니다.
- 이어서 원소를 추출하여 노드 2에 대해 처리합니다. 2번과 5번 노드까지의 최단 거리가 같으므로 어떤 원소부터 처리해도 상관없지만, 우선순위 큐에서 2번 노드가 꺼내졌다고 가정하겠습니다. 마찬가지로 2번 노드를 거쳐서 도달할 수 있는 노드 중에서 더 거리가 짧은 경우가 있는지 확인합니다. 이번 단계에서는 2번 노드를 거쳐서 가는 경우 중 현재의 최단 거리를 더 짧게 갱신할 수 있는 방법이 없습니다. 따라서 우선순위 큐에 어떠한 원소도 들어가지 않습니다.
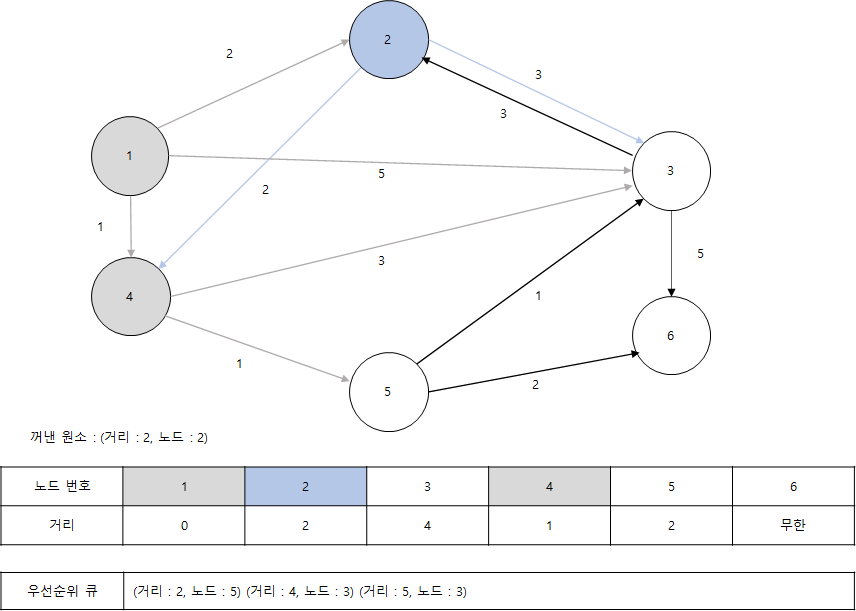
- 이어서 원소를 추출하여 노드 5에 대해 처리합니다. 5번 노드를 거쳐서 3번과 6번 노드로 갈 수 있습니다. 현재 5번 노드까지 가는 최단 거리가 2이므로 5번 노드에서 3번 노드로 가는 거리인 1을 더한 3이 기존의 값인 4보다 작습니다. 따라서 새로운 값인 3으로 갱신합니다. 또한 6번 노드로 가는 최단 거리 역시 마찬가지로 갱신됩니다. 그래서 이번에는 (3, 3)과 (4, 6)이 우선순위 큐에 들어갑니다.
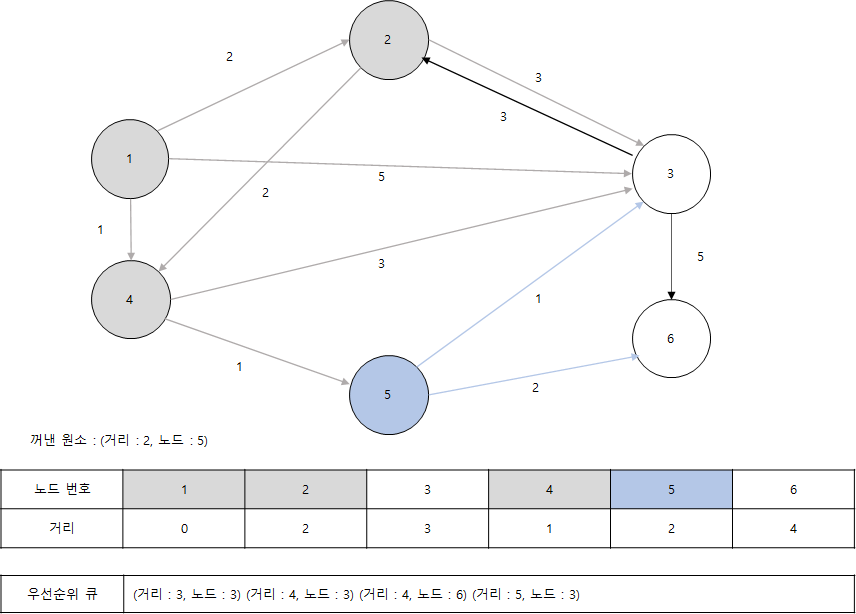
- 이어서 원소 (3, 3)을 꺼내서 3번 노드를 기준으로 알고리즘을 수행합니다. 최단 거리 테이블이 갱신되지 않으며 결과는 다음과 같습니다.
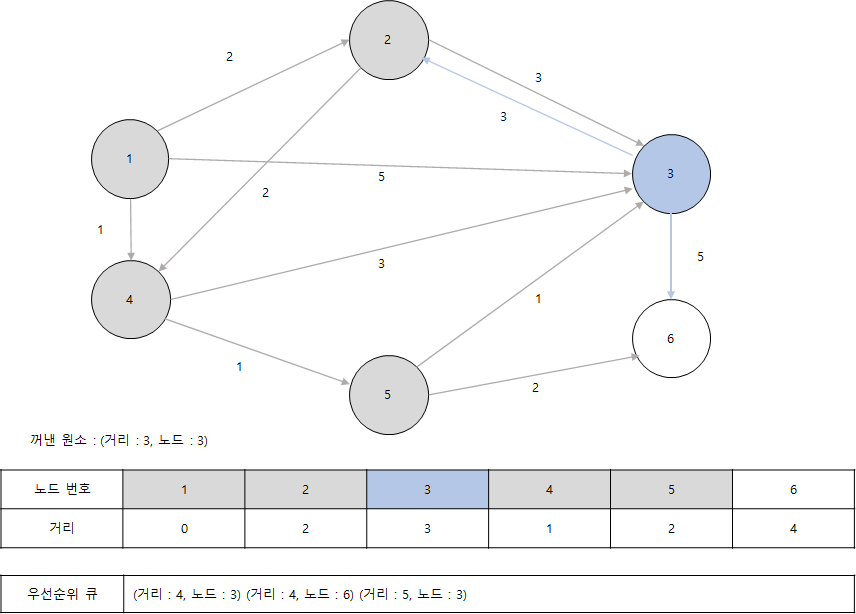
- 이어서 원소 (4, 3)을 꺼내서 3번 노드를 기준으로 알고리즘을 수행합니다. 다만, 3번 노드는 앞서 처리된 적이 있습니다. 우선선위 큐에서 꺼낸 원소에는 3번 노드까지 가는 최단 거리가 4입니다. 하지만 현재 최단 거리 테이블에서 3번 노드까지의 최단 거리는 3입니다. 따라서 현재 노드인 3번에 대해서는 이미 처리된 것으로 볼 수 있으므로 현재 우선순위 큐에서 꺼낸 4, 3 이라는 원소는 무시하면 됩니다.
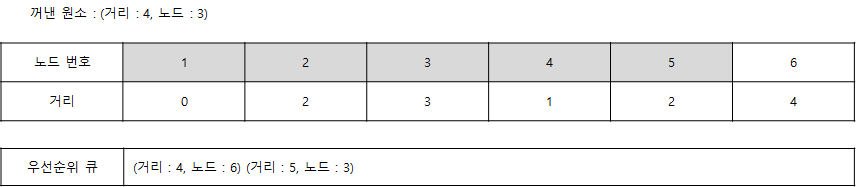
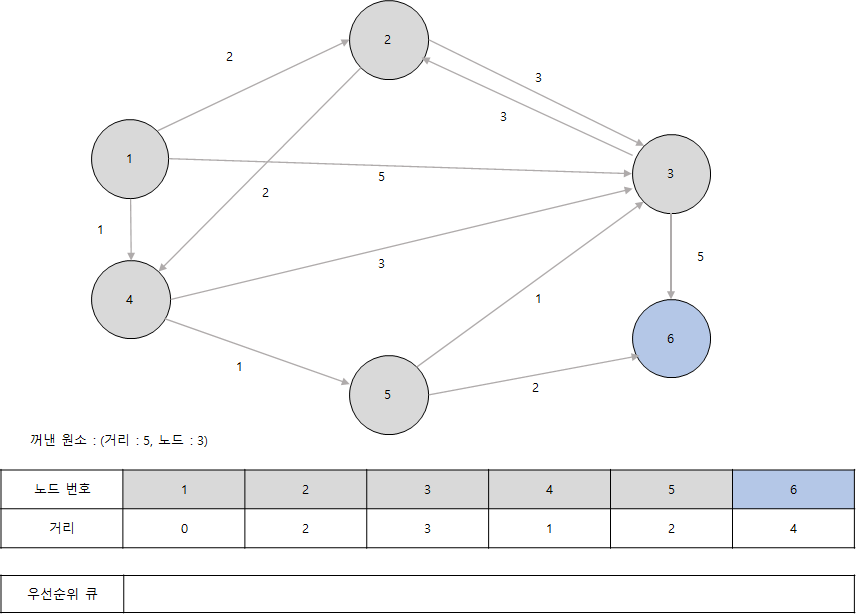
- 이어서 원소 (4, 6)을 꺼냅니다. 따라서 6번 노드에 대해서 처리하면 다음과 같습니다. 그 후 마지막 노드(5, 3)를 꺼내면 노드 3은 이미 처리된 노드이므로 무시합니다.
구현 코드
import heapq
import sys
input = sys.stdin.readline
INF = int(1e9) # 무한을 의미하는 값으로 10억으로 설정
# 노드의 개수, 간선의 개수 입력 받기
n, m = map(int, input().split())
# 시작 노드 번호 입력받기
start = int(input())
# 각 노드에 연결되어 있는 노드에 대한 정보를 담는 리스트를 만들기
graph = [[] for _ in range(n + 1)]
# 최단 거리 테이블을 모두 무한으로 초기화
distance = [INF] * (n + 1)
# 모든 간선의 정보를 입력받기
for _ in range(m):
a, b, c = map(int, input().split())
# a번 노드에서 b번 노드로 가는 비용이 c
graph[a].append((b, c))
def dijkstra(start):
q = []
# 시작 노드로 가기 위한 최단 경로는 0으로 설정하여, 큐에 삽입
heapq.heappush(q, (0, start))
distance[start] = 0
while q: # 큐가 비어있지 않다면
# 가장 최단 거리가 짧은 노드에 대한 정보 꺼내기
dist, now = heapq.heappop(q)
# 현재 노드가 이미 처리된 적이 있는 노드라면 무시
if dist < distance[now]:
continue
# 현재 노드와 연결된 다른 인접한 노드들을 확인
for i in graph[now]:
cost = dist + i[1]
# 현재 노드를 거쳐서, 다른 노드로 이동하는 거리가 더 짧은 경우
if cost < distance[i]:
distance[i[0]] = cost
heapq.heappush(q, (cost, i[0]))
# 다익스트라 알고리즘 수행
dijkstra(start)
# 모든 노드로 가기 위한 최단 거리를 출력
for i in range(1, n + 1):
# 도달할 수 없는 경우 무한이라고 출력
if distance[i] == INF:
print("INFINITY")
# 도달할 수 있는 경우 거리를 출력
else:
print(distance[i])시간 복잡도
위의 다익스트라 알고리즘의 시간 복잡도는 O(ElogV) 입니다.
(E는 간선의 개수, V는 노드의 개수)
다익스트라 알고리즘 정리
다익스트라 최단 경로 알고리즘은 우선순위 큐를 이용한다는 점에서 우선순위 큐를 필요로 하는 다른 문제 유형과도 흡사하다는 특징이 있습니다. 그래서 최단 경로를 찾는 문제를 제외하고도 다른 문제에도 두루 적용되는 소스코드 형태라고 이해할 수 있습니다. 예를 들어 그래프 문제로 유명한 최소 신장 트리 문제를 풀 때에도 일부 알고리즘(Prim 알고리즘)의 구현이 다익스트라 알고리즘의 구현과 흡사하다는 특징이 있습니다.
참조
취업을 위한 코딩테스트다 with 파이썬
벨만-포드
틀린 부분은 댓글로 남겨주시면 수정하겠습니다..!!
