데이터 시각화가 필요한 이유 1
- 시각화는 인간의 뇌에 가장 높은 인상을 전달하는 수단
- 빅데이터들은 차트로 다루기 어렵기 때문에 시각화 필요
- 동일한 수치라도 다양한 시각화 방법을 통해 그려지고 해석될 수 있다.
데이터 시각화가 필요한 이유 2
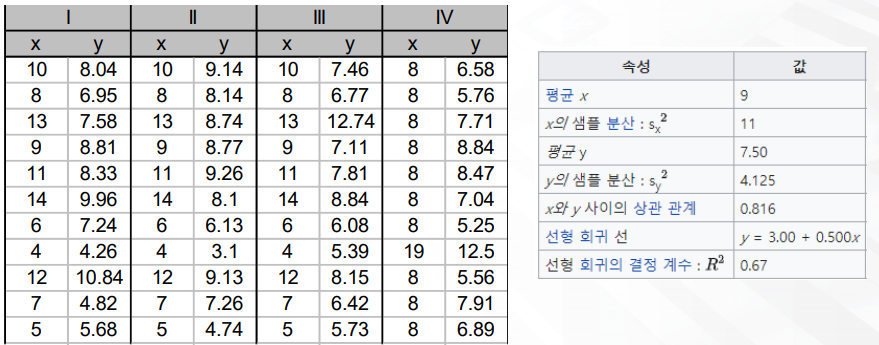
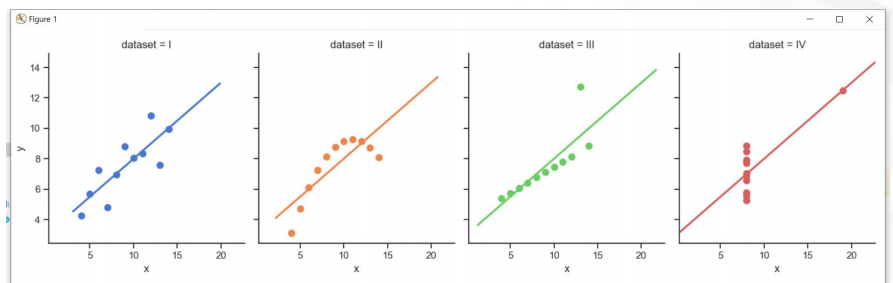
- 차트를 보게되면 1,2,3,4의 통계적 수치는 동일하게 나온다.
- 하지만 실제 각 1,2,3,4의 그룹 데이터를 시각화 해보면 위와 같은 형태를 가진다.
- 여기서 말하는 요지는 "수치적 데이터는 동일할 수 있지만, 시각화를 해보면 전혀 다른 해석이 나올 수 있다" 라고 말할 수 있다.
파이썬 시각화 라이브러리
- matplotlib
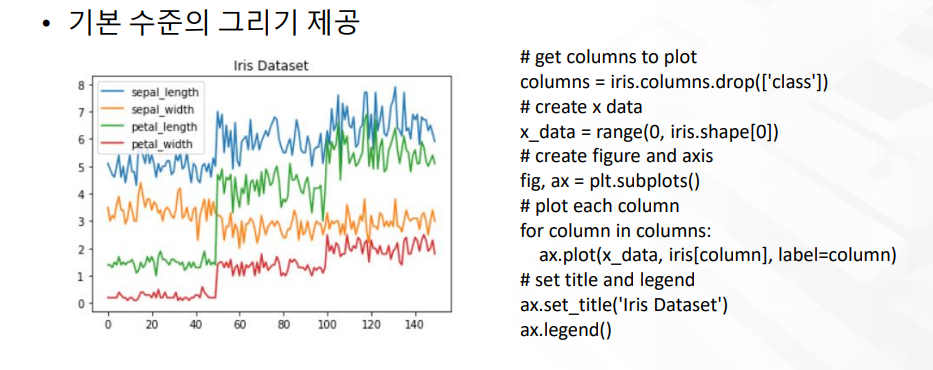
- 기본 수준의 plot(차트) 그리기 기능 제공
파이썬 시각화 라이브러리
- pandas
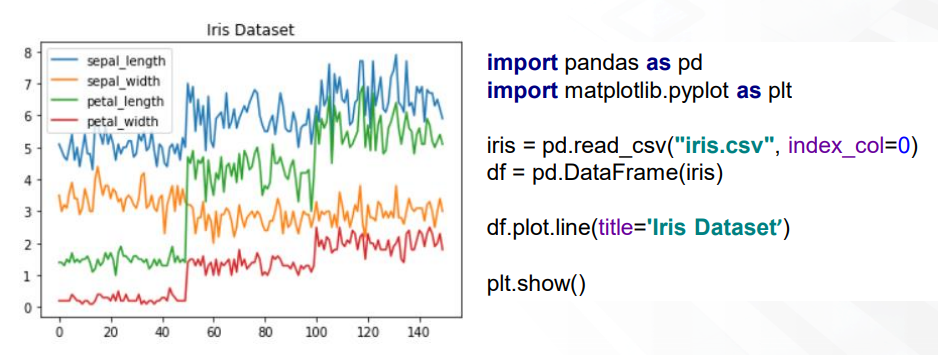
- matplotlib에 기반하여 쉬운 인터페이스 제공
파이썬 시각화 라이브러리
- seaborn
- Matplotlib을 기반으로 다양한 색상 테마와 통계용 차트 등의 기능을 추가한 시각화 패키지
시각화 실습
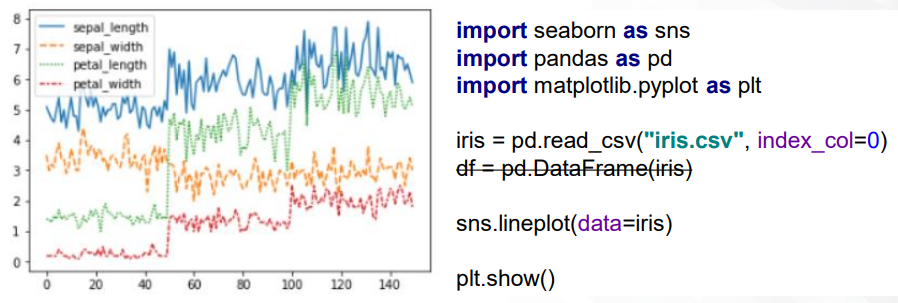
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt # sns build in 예제 (iris) iris = sns.load_dataset('iris') # iris 데이터 로드 df = pd.DataFrame(iris) # iris 데이터 to DataFrame df.plot(kind='kde') # kde : 커널 밀도 추정 plt.show()
시각화 실습
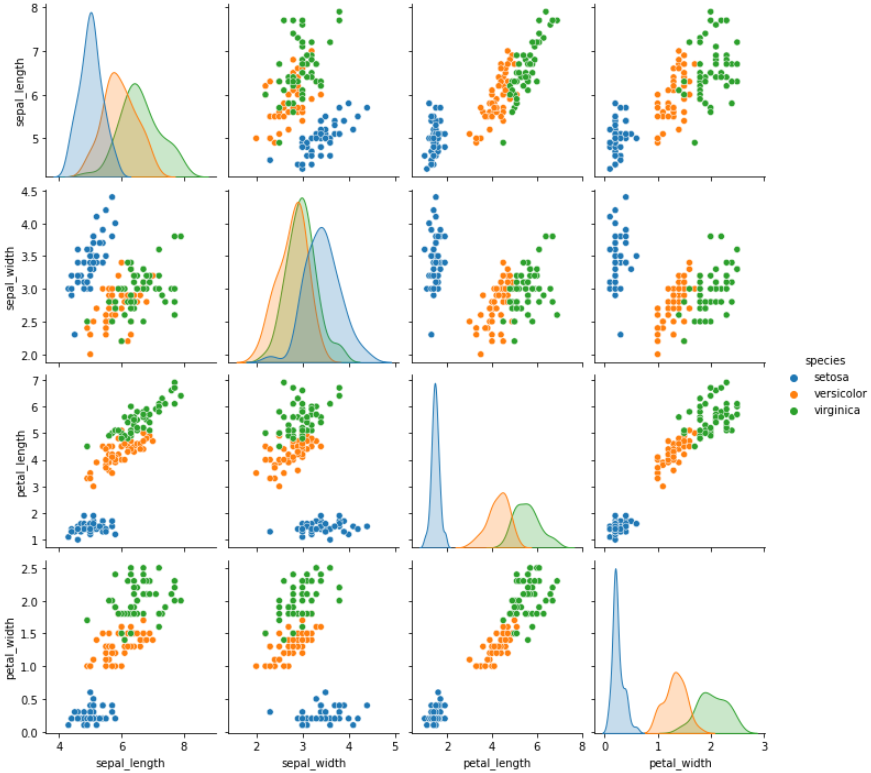
Seaborn 활용 - 3가지 붗꽃 품종을 시각화로 구분하기

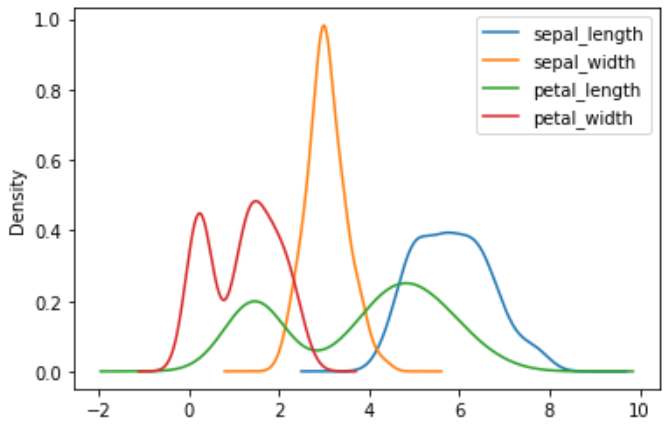
iris = sns.load_dataset('iris') print(iris) > sepal_length sepal_width petal_length petal_width species 0 5.1 3.5 1.4 0.2 setosa 1 4.9 3.0 1.4 0.2 setosa 2 4.7 3.2 1.3 0.2 setosa 3 4.6 3.1 1.5 0.2 setosa 4 5.0 3.6 1.4 0.2 setosa .. ... ... ... ... ... 145 6.7 3.0 5.2 2.3 virginica 146 6.3 2.5 5.0 1.9 virginica 147 6.5 3.0 5.2 2.0 virginica 148 6.2 3.4 5.4 2.3 virginica 149 5.9 3.0 5.1 1.8 virginica # 두 변수간의 산점도(Scatterplots) : 직교 좌표계를 이용해 좌표상의 점들을 표시 sns.jointplot(x='sepal_length',y='sepal_width',data=iris) plt.show()
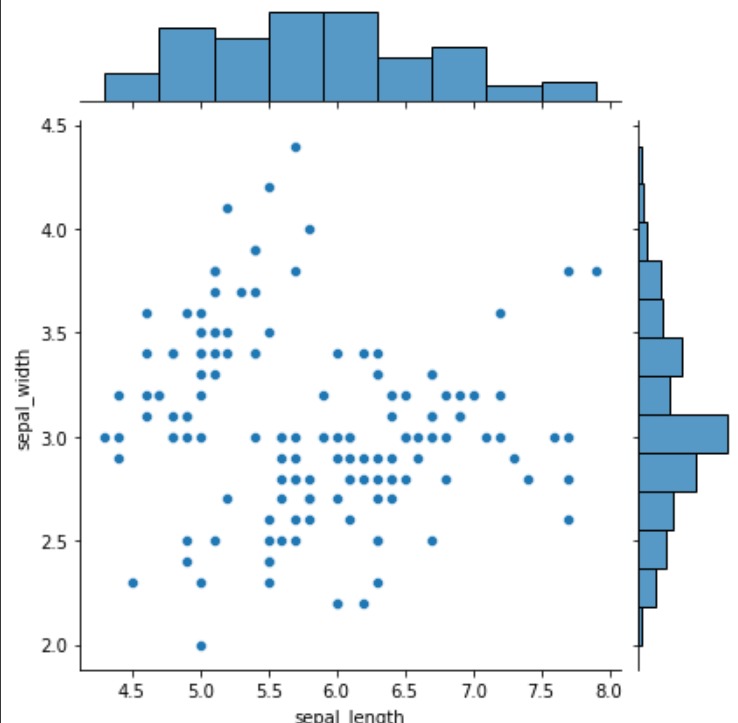
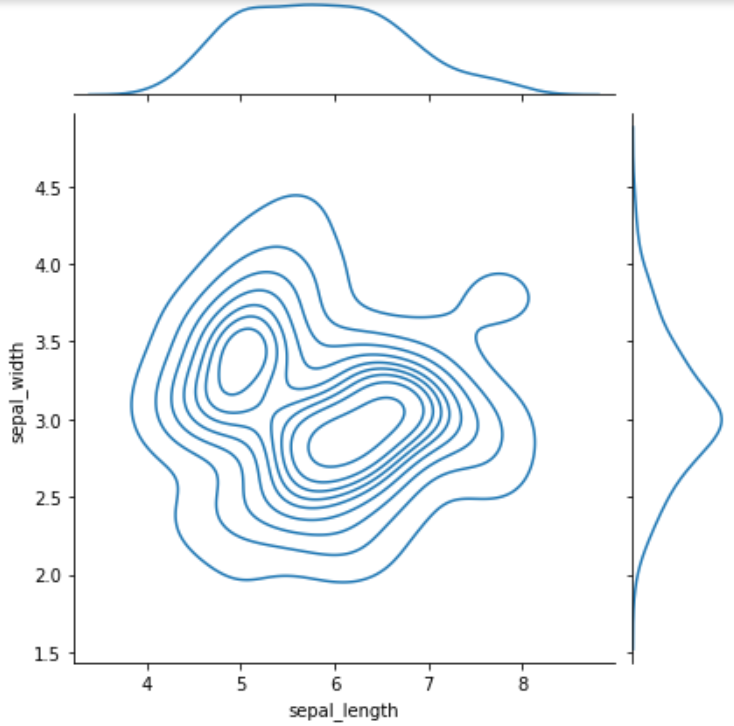
sns.jointplot( x='sepal_length', y='sepal_width', data=iris, kind='kde' # 커널 밀도 추정 ) plt.show()
# 품종별 시각화로 구분하기 sns.pairplot(iris,hue='species') plt.show()
시각화 실습
Seaborn 활용 - heatmap (연도별 비행기 탑승자 수)
import matplotlib.pyplot as plt flights = sns.load_dataset('flights') print(flights) > year month passengers 0 1949 Jan 112 1 1949 Feb 118 2 1949 Mar 132 3 1949 Apr 129 4 1949 May 121 .. ... ... ... 139 1960 Aug 606 140 1960 Sep 508 141 1960 Oct 461 142 1960 Nov 390 143 1960 Dec 432 [144 rows x 3 columns] # row = month, col = year flights_passengers = flights.pivot('month','year','passengers') # 데이터 Table 재배치 print(flights_passengers) > year 1949 1950 1951 1952 1953 1954 1955 1956 1957 1958 1959 1960 month Jan 112 115 145 171 196 204 242 284 315 340 360 417 Feb 118 126 150 180 196 188 233 277 301 318 342 391 Mar 132 141 178 193 236 235 267 317 356 362 406 419 Apr 129 135 163 181 235 227 269 313 348 348 396 461 May 121 125 172 183 229 234 270 318 355 363 420 472 Jun 135 149 178 218 243 264 315 374 422 435 472 535 Jul 148 170 199 230 264 302 364 413 465 491 548 622 Aug 148 170 199 242 272 293 347 405 467 505 559 606 Sep 136 158 184 209 237 259 312 355 404 404 463 508 Oct 119 133 162 191 211 229 274 306 347 359 407 461 Nov 104 114 146 172 180 203 237 271 305 310 362 390 Dec 118 140 166 194 201 229 278 306 336 337 405 432 sns.heatmap(flights_passengers, annot=True, fmt='d') # annot = 숫자 표시할 지, fmt = 숫자 형태 plt.show()

시각화 실습
Seaborn 활용 - boxplot (tips 데이터 활용)
tips = sns.load_dataset('tips') print(tips) > total_bill tip sex smoker day time size 0 16.99 1.01 Female No Sun Dinner 2 1 10.34 1.66 Male No Sun Dinner 3 2 21.01 3.50 Male No Sun Dinner 3 3 23.68 3.31 Male No Sun Dinner 2 4 24.59 3.61 Female No Sun Dinner 4 .. ... ... ... ... ... ... ... 239 29.03 5.92 Male No Sat Dinner 3 240 27.18 2.00 Female Yes Sat Dinner 2 241 22.67 2.00 Male Yes Sat Dinner 2 242 17.82 1.75 Male No Sat Dinner 2 243 18.78 3.00 Female No Thur Dinner 2 [244 rows x 7 columns] # x축 = 성별, y = 전체 금액, hue => 색깔로 구분하여 비교 sns.boxplot(x='sex',y='total_bill',hue='day',data=tips) plt.show()
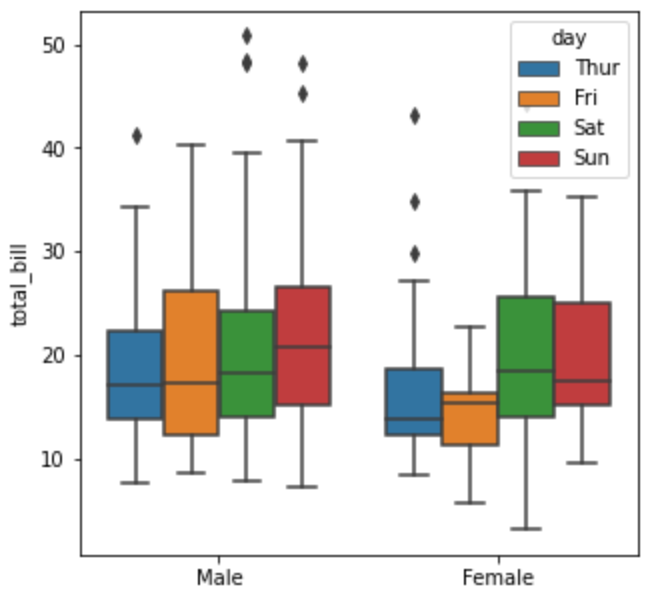
- 여성의 경우 토요일과 일요일에 가장 돈을 많이 쓴다.
- 남성의 경우 금액의 표준편차가 여성보다 더 크다.
# 돈을 많이 지출하는 사람(남성, 여성)을 요일별로 분석 sns.boxplot(x='day',y='total_bill',hue='sex',data=tips) plt.show()
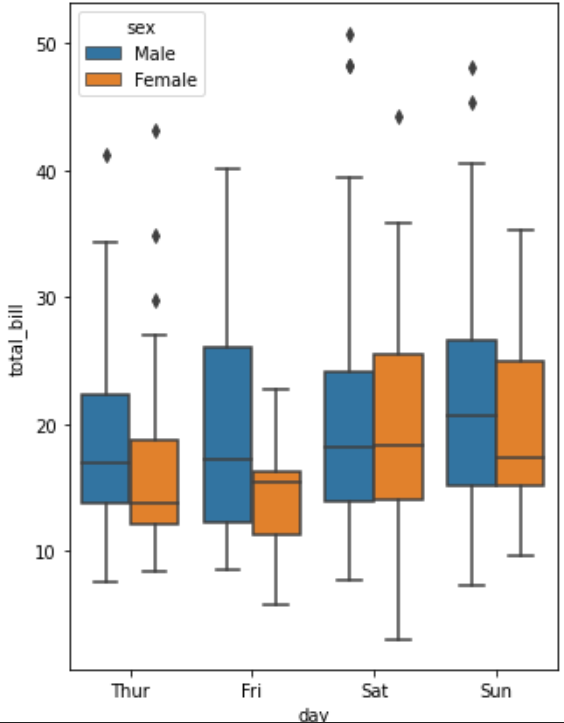
- 남성의 경우 대체적으로 여성보다 돈을 더 많이 사용한다.
- 남성의 경우 사용한 전체 금액의 표준편차가 더 크다.
타이타닉 승선 명단 분석

분석 내용 요약
- 목표 : 승객 변수를 분석하여 생존율과의 상관관계 확인
- 주요개념 이해 : 상관 분석, 상관 계수(피어슨 상관 계수), 히트맵
- 데이터 수집 : 탑승자 명단은 seaborn 빌트인 예제 활용
- 데이터 준비 : 결측치 확인 및 치환(중앙값, 최빈값)
- 데이터 탐색 : 정보 확인, 차트 확인
- 데이터 모델링 : 모든 변수 간 상관 계수, 두 변수 간 상관계수
- 변수 간의 상관 관계 시각화 : 전체 산점도, 변수 간 상관관계, 히트맵
핵심 개념
- 상관 분석
- 두 변수가 어떤 선형적 관계가 있는지 분석하는 방법론
- 단순 상관 분석
- 두 변수가 어느 정도 강한 관계에 있는지 측정
- 다중 상관 분석
- 세 개 이상의 변수 간 관계의 강도를 측정

데이터 분석 유튜버 "거친코딩"입니다.