database
1.Mysql
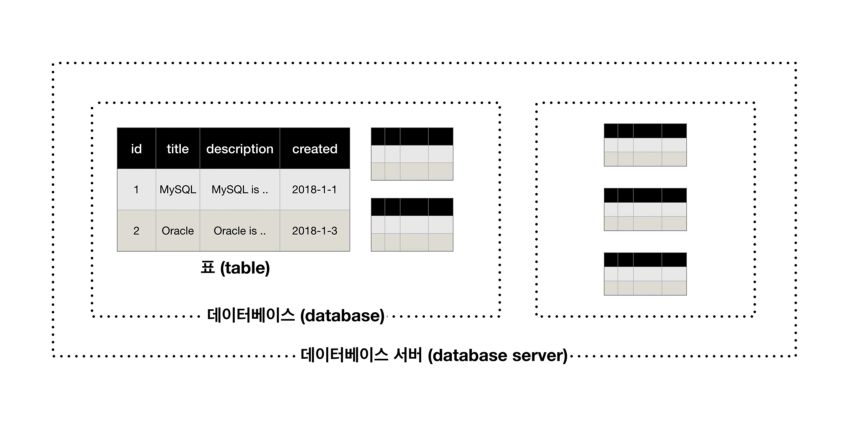
같은 종류의 여러 데이터를 table로 grouping 할 수 있고 여러 table을 database(schema)로 grouping할 수 있다. 이 때 서로 연관된 database들을 database server로 grouping 할 수 있다. mysql은 이러한 d
2.SQL

S: 데이터베이스는 표로 데이터를 정리하는데 그것을 '구조화'라고 하고Q: 데이터베이스에게 데이터를 입력, 조회, 삭제 등등의 명령을 요청하는 것을 쿼리라고 하고L: 쿼리문의 언어
3.table 생성

CREATE TABLE로 table 하나를 정의할 수 있고, topic() 인자 안에 컬럼 정보를 입력하여 사용할 컬럼도 미리 정의할 수 있다.차례로 칼럼 명, datatype(길이 제한), null값 제한, 데이터를 추가할 때 자동으로 데이터 값을 1로 증가시켜 행을
4.INSERT, SELECT, UPDATE, DELETE
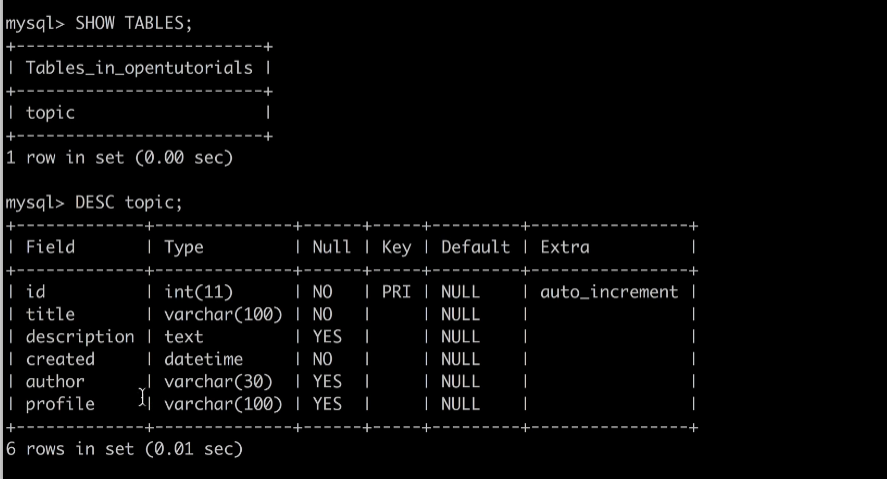
tables 조회와 특정 table 읽기INSERT는 데이터를 입력하는 쿼리문으로 다음과 같이 사용한다.SELECT는 데이터를 읽는 쿼리문으로 \*은 테이블 전체를 의미한다.where를 통해 조건문을 사용하여 필요한 정보를 조회 할 수도 있다.ORDER BY 칼럼 조건
5.관계형 데이터베이스
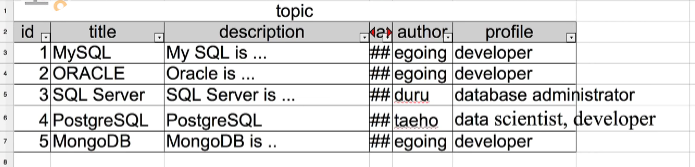
이 테이블만 보면 egoing이라는 한명의 author가 여러번 topic을 추가한 것인지, egoing이라는 이름을 가진 3명의 서로 다른 author가 한번씩 글을 추가한 것인지 알 수 없다. 하지만 author라는 테이블을 생성하고 그 안에 id로 분류되는 aut
6.JOIN

SELET \* FROM 테이블명 LEFT JOIN 칼럼명 ON 테이블명.칼럼명 = 다른테이블명.칼럼명; 으로 다른 테이블에 존재하는 칼럼의 관계를 확인하고 조회할 수 있다. 여기서 id가 중복되서 조회되므로조회하는 칼럼명을 지정해주면 지정한 id값만 나오는 걸 확인할