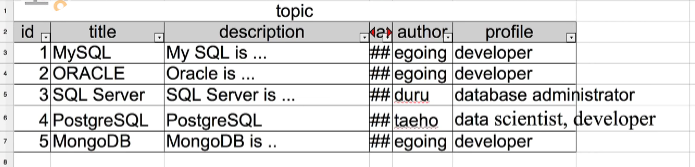
이 테이블만 보면 egoing이라는 한명의 author가 여러번 topic을 추가한 것인지, egoing이라는 이름을 가진 3명의 서로 다른 author가 한번씩 글을 추가한 것인지 알 수 없다.

하지만 author라는 테이블을 생성하고 그 안에 id로 분류되는 author의 이름을 추가하고 topic의 author를 author 테이블의 id로 구분지으면 같은 사람이 쓴 글인지 아닌지를 명확히 구분할 수 있다.
이렇게 참조값만을 적어놓으면 위와 같은 장점이 있지만 id 마다 구분되는 작가의 이름과 profile을 topic 테이블만을 보고서 확인할 수 없다는 단점도 있다.
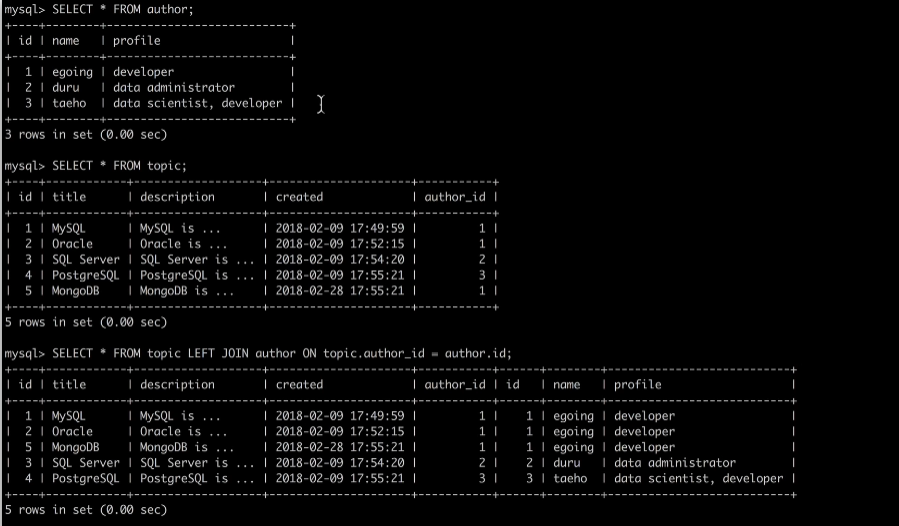
database 안에서 위와 같은 별도의 table이 있다고 했을 때 위에서 언급한 단점을 제거하려면 JOIN이라는 문법을 이용하여 다른 테이블들의 관계를 알아서 확인하고 가시성있게 표현할 수 있다.
=> 이것이 관계형 데이터베이스의 의미이다.
관계형 데이터베이스의 필요성
데이터가 중복 되고 있다 -> 개선할 것이 있다
장점: 별도의 참조 데이터 테이블을 만들어 중복이 없는 뛰어난 퍼포먼스와 쉬운 유지 보수
단점: 별도의 표를 열어 비교해가며 봐야하기 때문에 직관적이지 않다
그럼 어떻게 해야될까? => 저장은 분산해서, 보여줄땐 합쳐서 => MySQL은 가능!

공부 리마인드