
📌목차
1. Vision Transformer 개요
2. 구조 및 이해✔️ 기억할용어
- Patch Embedding
📕 Vision Transformer 개요
논문명 : 2021 ICLR - An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
이미지 클래스 분류를 위해, 이미지를 여러 Patch로 나누어 Transformer에 넣는 방법론
📕 구조 및 이해
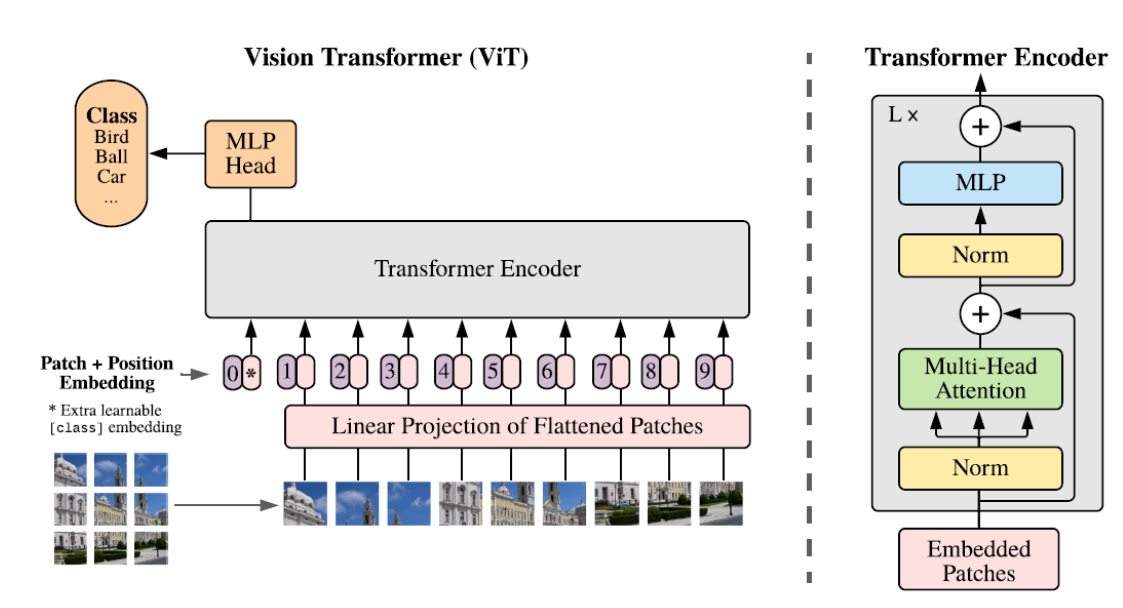
📖 전체 구조
📖 Patch Embedding
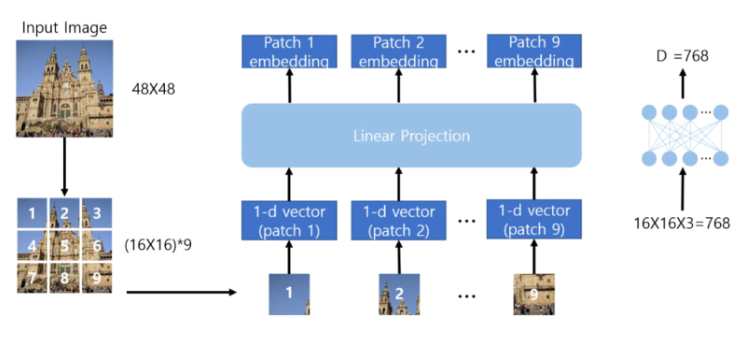
- 이미지를 16 x 16 크기의 patch로 나눔
- 각 이미지 patch를 token으로 취급
- 이미지 크기가 48 x 48 라면 총 9개의 patch가 생김
- 각 patch를 1차원 Vector로 풀어냄
- 각 patch는 16 x 16 x 3(RGB) = 768 차원의 크기를 가짐
- Linear Projection 을 통과하여 Embedding vector를 얻음
- 학습가능한 Layer 이다.
- Linear Projection 명명이유는 Hidden layer지만, 활성화함수가 없기 때문
📖 Classification Token / Position Embedding
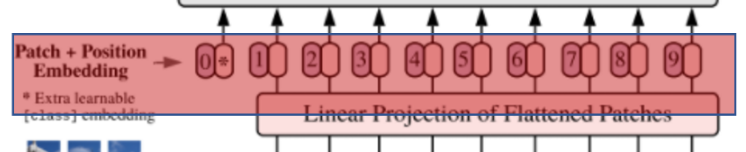
- 0,1,2..,8,9 : positional encoding
*: CLS (Classification을 위해 사용되는 token)
📖 Transformer Encoder (12개 사용함)
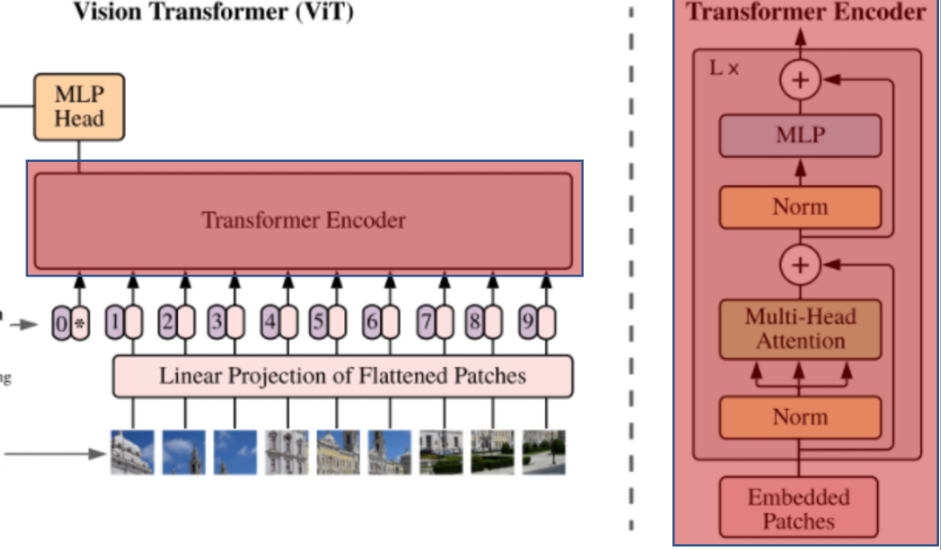
1. Layer Normalization 수행
- 각 instance에 대해 Normalization 진행
- 즉 각 Patch에 대해 Normalization 진행 하는 것
- 평균 0, 표준편차 1인 분포로 변환이 된다.
- 아래 그림에서 Z의 좌측(레이어 Number) 우측(Seq Number) 의미
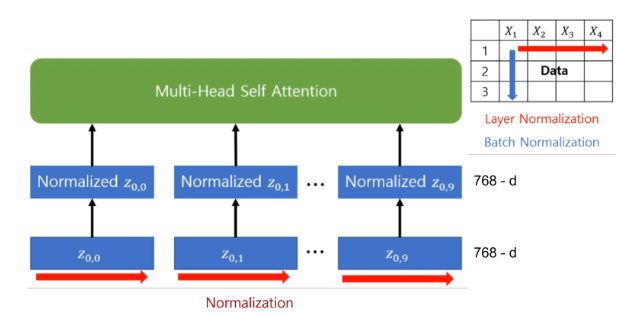
2. Multi-Head Self-Attention 수행
- 각 패치에 대해 query, key, value 구함
- 768 = 64 차원 x 12번
- 각 query, key, value는 64차원을 가짐 - Softmax(Query, Key^T) 로 Attention Weight 구함
- value와 가중합 함으로써 Attention Value 구함
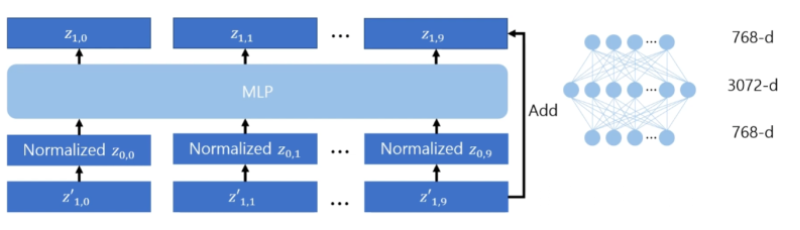
3. MLP 수행
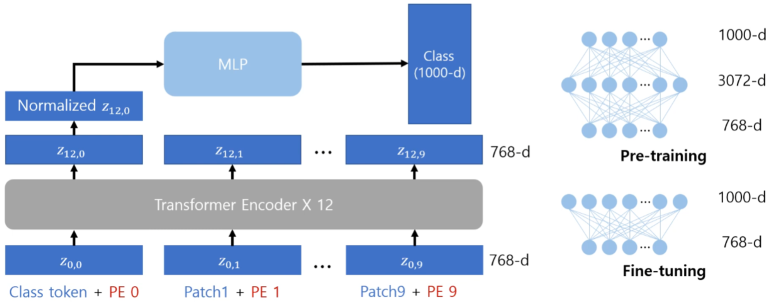
📖 Classification Head
Transformer Encoder 12개의 층을 지남
그 후 얻어진 임베딩 벡터는 다음처럼 (Z12,0~Z12,9)로 10개이다.
각각의 임베딩은 이미지의 각 패치에 대한 임베딩 결과임
- 전체 이미지를 대표하는 임베딩 벡터가 필요
- 첫번째 (Classification token + PE0)의 최종결과가 전체 이미지를 대표하는 임베딩벡터이다. (BERT에서 처음제시한 방법)
📚 Reference
https://greeksharifa.github.io/computer%20vision/2022/03/01/EfficientNet/

인공지능 4년차 개발자입니다.